
Rumah >hujung hadapan web >tutorial js >Ajar anda langkah demi langkah cara membuat JS terbalik untuk merangkak fon terbalik dan mendapatkan maklumat daripada tapak web pengambilan
Ajar anda langkah demi langkah cara membuat JS terbalik untuk merangkak fon terbalik dan mendapatkan maklumat daripada tapak web pengambilan

- Python当打之年ke hadapan
- 2023-08-09 17:56:531130semak imbas
Tapak web hari ini
Editor telah menyulitkan: aHR0cHM6Ly93d3cuc2hpeGlzZW5nLmNvbS8= Atas sebab keselamatan, kami mengekod URL melalui base64 dan anda boleh mendapatkan URL melalui penyahkodan base64.
Fon anti-merangkak
Fon anti-merangkak: Teknologi anti-merangkak biasa, ia ialah strategi anti-merangkak yang dilengkapkan dengan menggabungkan halaman web dan fail fon bahagian hadapan -teknologi merangkak ialah 58.com dan Autohome Tunggu, banyak tapak web atau APP arus perdana kini turut menggunakan teknologi anti-merangkak untuk menambahkan langkah anti-merangkak pada tapak web atau APP mereka.
Prinsip anti-merangkak fon: Gantikan data tertentu dalam halaman dengan fon tersuai Apabila kami tidak menggunakan kaedah penyahkodan yang betul, kami tidak boleh mendapatkan kandungan data yang betul.
Gunakan fon tersuai dalam HTML melalui @font-face, seperti yang ditunjukkan di bawah:

Format sintaks ialah:
@font-face{
font-family:"名字";
src:url('字体文件链接');
url('字体文件链接')format('文件类型')
}Fail fon biasanya jenis ttf, jenis eot dan jenis woff digunakan secara meluas, jadi semua orang biasanya menemui fail jenis woff.
Ambil fail jenis woff sebagai contoh, apakah kandungannya, dan apakah kaedah pengekodan yang digunakan untuk menjadikan data dan kod sepadan satu dengan satu?
Kami mengambil fail fon laman web pengambilan sebagai contoh Masukkan pengkompil fon Baidu dan buka fail fon, seperti yang ditunjukkan dalam rajah di bawah:

Buka fon secara rawak, seperti rajah di bawah:
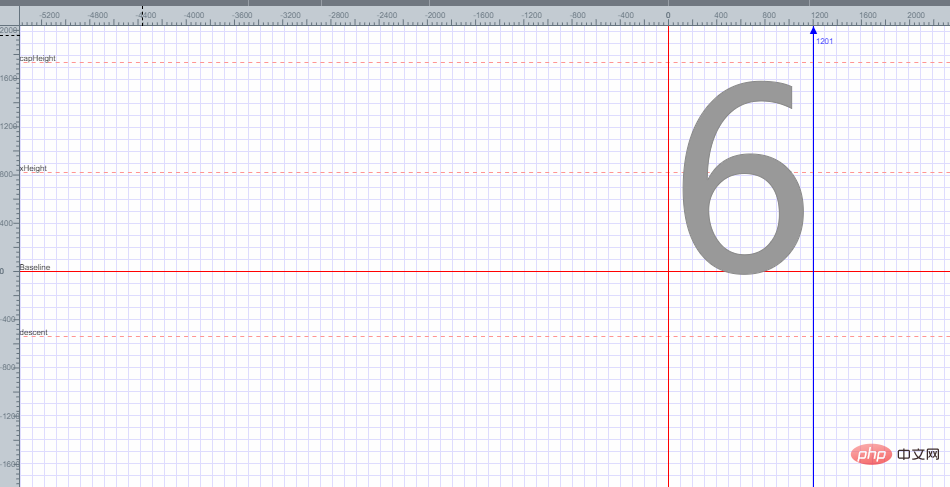
Anda boleh mencari Font 6 diletakkan dalam koordinat satah, dan pengekodan fon 6 diperoleh berdasarkan setiap titik koordinat satah Saya tidak akan menerangkan cara mendapatkan pengekodan fon 6 di sini.
Bagaimana untuk menyelesaikan masalah fon anti panjat?
Pertama sekali, hubungan pemetaan boleh dianggap sebagai kamus Terdapat kira-kira dua kaedah yang biasa digunakan:
Yang pertama: ekstrak secara manual hubungan yang sepadan antara satu set kod dan aksara dan memaparkannya dalam bentuk. kamus. Kodnya adalah seperti berikut:
replace_dict={
'0xf7ce':'1',
'0xf324':'2',
'0xf23e':'3',
.......
'0xfe43':'n',
}
for key in replace_dict:
数据=数据.replace(key,replace_dict[key])Mula-mula tentukan kamus yang sepadan dengan fon dan kod yang sepadan, dan kemudian gantikan data satu demi satu melalui gelung untuk.
Nota: Kaedah ini sesuai terutamanya untuk data dengan sedikit pemetaan fon.
Kaedah kedua: Mula-mula muat turun fail fon tapak web, kemudian tukar fail fon kepada fail XML, cari kod perhubungan pemetaan fon di dalam, nyahkodnya melalui fungsi penyahkod, dan kemudian gabungkan kod yang dinyahkod ke dalam kamus , dan kemudian mengikut kandungan kamus Gantikan data satu demi satu Memandangkan kodnya agak panjang, saya tidak akan menulis kod sampel di sini Kod untuk kaedah ini akan ditunjukkan kemudian dalam latihan pertempuran sebenar.
Baiklah, mari bercakap secara ringkas tentang anti-merangkak fon Seterusnya, kami akan merangkak secara rasmi tapak web pengambilan.
Latih tubi praktikal
Cari fail fon tersuai
Mula-mula masukkan tapak web pengambilan dan buka mod pembangun, seperti yang ditunjukkan dalam gambar di bawah:
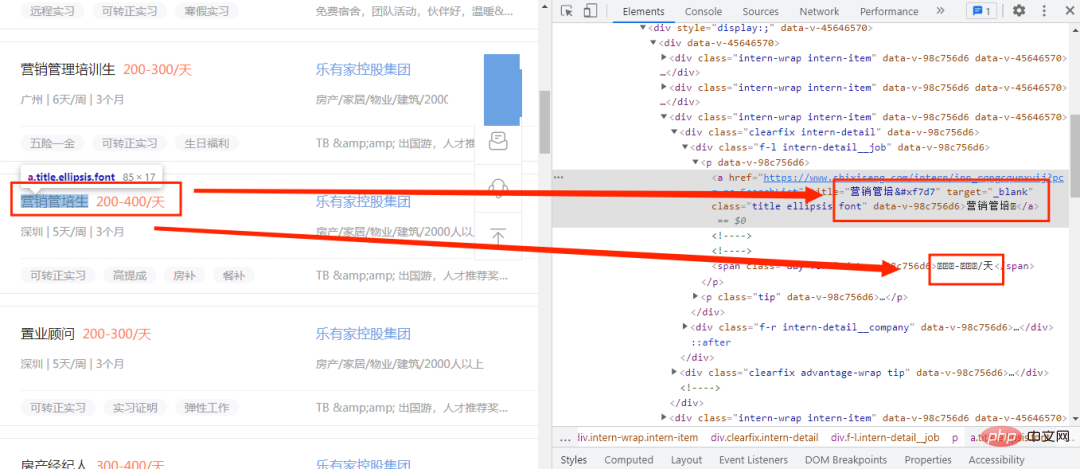
Di sini kita melihat bahawa hanya perkataan baharu dalam kod tidak boleh berfungsi secara normal, tetapi pada mulanya ditentukan bahawa fail fon tersuai digunakan pada masa ini, adalah perlu untuk mencari fail font. jadi di mana untuk mencari fail fon? Nah, mula-mula buka mod pembangun dan klik pilihan Rangkaian, seperti yang ditunjukkan dalam rajah di bawah:
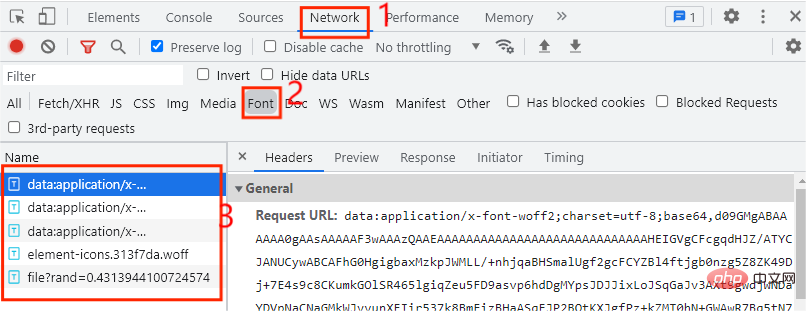
Secara amnya, fail fon diletakkan dalam tab Font Kami mendapati bahawa terdapat a jumlah 5 entri di sini, jadi yang mana satu adat Bagi entri fail fon, fail fon tersuai akan dilaksanakan sekali setiap kali kita klik pada halaman seterusnya, kita hanya perlu klik pada halaman seterusnya dalam halaman web, seperti yang ditunjukkan dalam rajah di bawah:
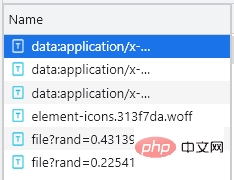
Anda dapat melihat bahawa terdapat entri tambahan bermula dengan fail Pada masa ini, anda pada mulanya boleh menentukan bahawa fail itu adalah fail fon tersuai ia. Kaedah muat turun adalah sangat mudah. Anda hanya perlu menyalin URL entri bermula dengan fail dan memasukkannya ke dalam Hanya buka di halaman web Selepas memuat turunnya, bukanya dalam pengkompil fon Baidu, seperti yang ditunjukkan di bawah:
Pada masa ini, saya mendapati bahawa ia tidak dapat dibuka Adakah saya menemui fail fon yang salah untuk membukanya, seperti yang ditunjukkan dalam gambar di bawah:

Ia berjaya dibuka pada masa ini.
Hubungan pemetaan fon
Fail fon tersuai ditemui, jadi bagaimana kita menggunakannya? Pada masa ini, kami mula-mula menyesuaikan kaedah get_fontfile() untuk memproses fail fon tersuai, dan kemudian memaparkan hubungan pemetaan dalam fail fon melalui kamus dalam dua langkah.
Muat turun dan penukaran fail fon; Penyahkodan perhubungan pemetaan fon.
Font Fail muat turun dan penukaran
🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 🎜🎜🎜🎜🎜🎜 fail fon tersuai sebelumnya daripada digunakan. Mengakibatkan pemerolehan data yang tidak tepat. Mula-mula perhatikan pautan url fail fon tersuai: 🎜
https://www.xxxxxx.com/interns/iconfonts/file?rand=0.2254193167485603 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.4313944100724574 https://www.xxxxxx.com/interns/iconfonts/file?rand=0.3615862774301839
可以发现自定义字体文件的URL只有rand这个参数发生变化,而且是随机的十六位小于1的浮点数,那么我们只需要构造rand参数即可,主要代码如下所示:
def get_fontfile():
rand=round(random.uniform(0,1),17)
url=f'https://www.xxxxxx.com/interns/iconfonts/file?rand={rand}'
response=requests.get(url,headers=headers).content
with open('file.woff','wb')as f:
f.write(response)
font = TTFont('file.woff')
font.saveXML('file.xml')首先通过random.uniform()方法来控制随机数的大小,再通过round()方法控制随机数的位数,这样就可以得到rand的值,再通过.content把URL响应内容转换为二进制并写入file.woff文件中,在通过TTFont()方法获取文件内容,通过saveXML方法把内容保存为xml文件。xml文件内容如下图所示:
字体解码及展现
该字体.xml文件一共有4589行那么多,哪个部分才是字体映射关系的代码部分呢?
首先我们看回在百度字体编码器的内容,如下图所示:

汉字人对应的代码为f0e2,那么我们就在字体.xml文件中查询人的代码,如下图所示:
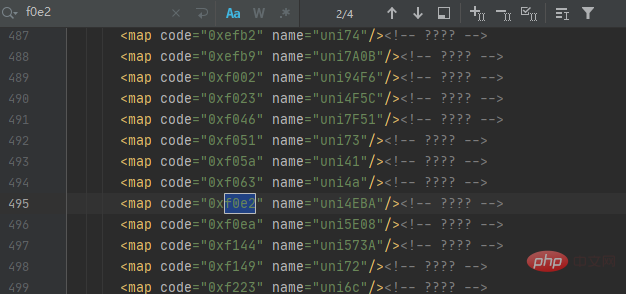
可以发现一共有4个结果,但仔细观察每个结果都相同,这时我们可以根据它们代码规律来获取映射关系,再通过解码来获取对应的数据值,最后以字典的形式展示,主要代码如下所示:
with open('file.xml') as f:
xml = f.read()
keys = re.findall('<map code="(0x.*?)" name="uni.*?"/>', xml)
values = re.findall('<map code="0x.*?" name="uni(.*?)"/>', xml)
for i in range(len(values)):
if len(values[i]) < 4:
values[i] = ('\\u00' + values[i]).encode('utf-8').decode('unicode_escape')
else:
values[i] = ('\\u' + values[i]).encode('utf-8').decode('unicode_escape')
word_dict = dict(zip(keys, values))首先读取file.xml文件内容,找出把代码中的code、name的值并分别设置为keys键,values值,再通过for循环把values的值解码为我们想要的数据,最后通过zip()方法合并为一个元组并通过dict()方法转换为字典数据,运行结果如图所示:

获取招聘数据
在上一步中,我们成功把字体映射关系转换为字典数据了,接下来开始发出网络请求来获取数据,主要代码如下所示:
def get_data(dict,url):
response=requests.get(url,headers=headers).text.replace('&#','0')
for key in dict:
response=response.replace(key,dict[key])
XPATH=parsel.Selector(response)
datas=XPATH.xpath('//*[@id="__layout"]/div/div[2]/div[2]/div[1]/div[1]/div[1]/div')
for i in datas:
data={
'workname':i.xpath('./div[1]/div[1]/p[1]/a/text()').extract_first(),
'link':i.xpath('./div[1]/div[1]/p[1]/a/@href').extract_first(),
'salary':i.xpath('./div[1]/div[1]/p[1]/span/text()').extract_first(),
'place':i.xpath('./div[1]/div[1]/p[2]/span[1]/text()').extract_first(),
'work_time':i.xpath('./div[1]/div[1]/p[2]/span[3]/text()').extract_first()+i.xpath('./div[1]/div[1]/p[2]/span[5]/text()').extract_first(),
'company_name':i.xpath('./div[1]/div[2]/p[1]/a/text()').extract_first(),
'Field_scale':i.xpath('./div[1]/div[2]/p[2]/span[1]/text()').extract_first()+i.xpath('./div[1]/div[2]/p[2]/span[3]/text()').extract_first(),
'advantage': ','.join(i.xpath('./div[2]/div[1]/span/text()').extract()),
'welfare':','.join(i.xpath('./div[2]/div[2]/span/text()').extract())
}
saving_data(list(data.values()))首先自定义方法get_data()并接收字体映射关系的字典数据,再通过for循环将字典内容与数据一一替换,最后通过xpath()来提取我们想要的数据,最后把数据传入我们自定义方法saving_data()中。
保存数据
数据已经获取下来了,接下来将保存数据,主要代码如下所示:
def saving_data(data):
db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='recruit')
cursor = db.cursor()
sql = 'insert into recruit_data(work_name, link, salary, place, work_time,company_name,Field_scale,advantage,welfare) values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'
try:
cursor.execute(sql,data)
db.commit()
except:
db.rollback()
db.close()启动程序
好了,程序已经写得差不多了,接下来将编写代码运行程序,主要代码如下所示:
if __name__ == '__main__':
create_db()
get_fontfile()
for i in range(1,3):
url=f'https://www.xxxxxx.com/interns?page={i}&type=intern&salary=-0&city=%E5%85%A8%E5%9B%BD'
get_data(get_dict(),url)结果展示
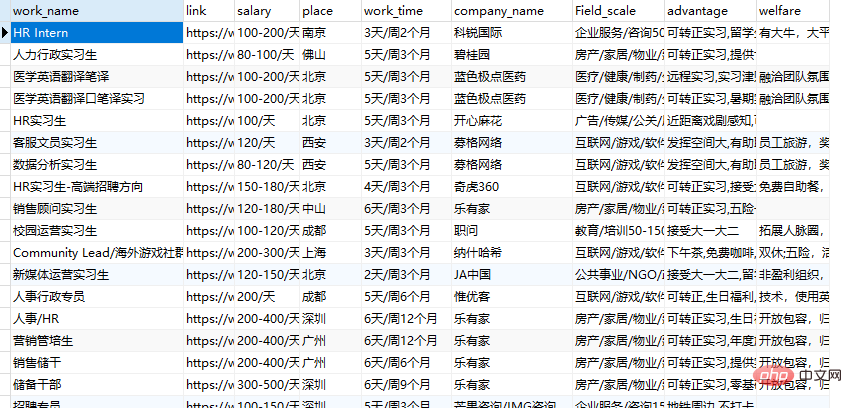
Atas ialah kandungan terperinci Ajar anda langkah demi langkah cara membuat JS terbalik untuk merangkak fon terbalik dan mendapatkan maklumat daripada tapak web pengambilan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!