Selaras Tinggi dan Tindak balas pantas sepadan dengan dua petunjuk teras pengoptimuman prestasi: Throughput dan Latensi
🎜🎜Gambar dari: www.ctq6.cn
Beban aplikasiSudut: secara langsung mempengaruhi pengalaman pengguna terminal produk
le: penggunaan sumber, ketepuan Intipati masalah prestasi ialah sumber sistem telah mencapai kesesakan, tetapi pemprosesan permintaan tidak cukup pantas untuk menyokong lebih banyak permintaan. Analisis prestasi sebenarnya adalah untuk mencari kesesakan aplikasi atau sistem dan cuba mengelakkan atau mengurangkannya.
Pilih metrik untuk menilai prestasi aplikasi dan sistem
Tetapkan matlamat prestasi untuk aplikasi dan sistem
Lakukan penanda aras prestasi
cate bottlenecks
Pemantauan dan amaran prestasi
Untuk masalah prestasi yang berbeza, alat analisis prestasi yang berbeza harus dipilih. Berikut ialah Alat Prestasi Linux yang biasa digunakan dan jenis masalah prestasi yang sepadan dianalisis.
. nombor masa unit, iaitu purata bilangan proses aktif. Ia tidak berkaitan secara langsung dengan penggunaan CPU seperti yang kita fahami secara tradisional. Proses tidak terganggu ialah proses yang berada dalam proses kritikal dalam keadaan kernel (seperti tindak balas I/O biasa yang menunggu peranti). Keadaan tidak terganggu sebenarnya adalah mekanisme perlindungan sistem untuk proses dan peranti perkakasan.
Apakah purata beban yang munasabah?
Dalam persekitaran pengeluaran sebenar, pantau purata beban sistem dan nilaikan aliran perubahan beban berdasarkan data sejarah. Apabila terdapat aliran menaik yang jelas dalam beban, jalankan analisis dan penyiasatan tepat pada masanya. Sudah tentu, anda juga boleh menetapkan ambang (seperti apabila beban purata lebih tinggi daripada 70% daripada bilangan CPU)
Dalam kerja sebenar, kita sering mengelirukan konsep beban purata dan penggunaan CPU. kedua-duanya tidak setara sepenuhnya:
Proses intensif CPU, penggunaan CPU yang banyak akan menyebabkan beban purata meningkat, pada masa ini kedua-duanya konsisten
Proses intensif I/O, menunggu I/O juga akan menyebabkan beban purata meningkat, ini Penggunaan CPU tidak semestinya tinggi
Sebilangan besar proses menunggu penjadualan CPU akan menyebabkan beban purata meningkat pada masa ini, penggunaan CPU juga agak tinggi
Apabila purata beban CPU tinggi, mungkin CPU Disebabkan oleh proses intensif atau I/O yang sibuk. Semasa analisis khusus, anda boleh menggabungkan alat mpstat/pidstat untuk membantu dalam menganalisis sumber beban
2CPU
Pensuisan konteks CPU (Bahagian 1)
Pensuisan konteks CPU adalah untuk menyimpan konteks CPU (daftar CPU dan PC yang baru) konteks ke daftar ini dan pembilang program, dan akhirnya melompat ke lokasi yang ditunjukkan oleh pembilang program untuk menjalankan tugas baharu. Antaranya, konteks yang disimpan akan disimpan dalam kernel sistem dan dimuatkan semula apabila tugasan dijadualkan semula untuk memastikan status tugas asal tidak terjejas.
Mengikut jenis tugas, penukaran konteks CPU dibahagikan kepada:
Proses suis konteks Proses Linux mengikut Keizinan Tahap membahagikan ruang proses sesuatu proses ke dalam ruang kernel dan ruang pengguna. Peralihan daripada mod pengguna kepada mod kernel perlu diselesaikan melalui panggilan sistem.
Proses panggilan sistem sebenarnya melaksanakan dua suis konteks CPU:
Lokasi arahan mod pengguna dalam daftar CPU disimpan dahulu, daftar CPU dikemas kini ke lokasi arahan mod kernel, dan melompat ke keadaan kernel untuk menjalankan tugas kernel; Selepas panggilan sistem tamat, daftar CPU kembali ke keadaan asalnya Simpan data mod pengguna dan kemudian beralih ke ruang pengguna untuk terus berjalan.
Proses panggilan sistem tidak melibatkan proses sumber mod pengguna seperti memori maya, dan juga tidak menukar proses. Ia berbeza daripada penukaran konteks proses dalam erti kata tradisional. Oleh itu panggilan sistem sering dipanggil suis mod istimewa
.
Proses diurus dan dijadualkan oleh kernel, dan penukaran konteks proses hanya boleh berlaku dalam keadaan kernel. Oleh itu, berbanding dengan panggilan sistem, sebelum menyimpan keadaan kernel dan daftar CPU proses semasa, memori maya dan timbunan proses perlu disimpan terlebih dahulu. Selepas memuatkan keadaan kernel proses baharu, memori maya dan timbunan pengguna proses tersebut mesti dimuat semula.
Proses hanya perlu menukar konteks apabila ia dijadualkan untuk dijalankan pada CPU Terdapat senario berikut: Potongan masa CPU diperuntukkan secara bergilir-gilir, sumber sistem yang tidak mencukupi menyebabkan proses hang, proses secara aktif melepasi. fungsi tidur, dan proses keutamaan tinggi Potongan masa preemption, apabila perkakasan terganggu, proses pada CPU digantung dan sebaliknya melaksanakan perkhidmatan gangguan dalam kernel.
Penukaran konteks benang
Penukaran konteks benang terbahagi kepada dua jenis:
Benang depan dan belakang tergolong dalam proses yang sama, sumber memori maya kekal tidak berubah semasa suis data, daftar, dsb. perlu ditukar;
Penukaran benang dalam proses yang sama menggunakan lebih sedikit sumber, yang juga merupakan kelebihan multi-benang.
Pensuisan konteks interrupt
Penukaran konteks interrupt tidak melibatkan keadaan pengguna proses, jadi konteks interrupt hanya termasuk keadaan yang diperlukan untuk pelaksanaan program perkhidmatan interrupt state kernel (daftar CPU, tindanan kernel, gangguan perkakasan parameter, dsb.).
Keutamaan pemprosesan gangguan adalah lebih tinggi daripada proses, jadi penukaran konteks gangguan dan penukaran konteks proses tidak akan berlaku pada masa yang sama
Maklumat video komprehensif teknologi arus perdana Docker+K8s+Jenkins
Penukaran konteks CPU (Bahagian 2)
Anda boleh menyemak situasi penukaran konteks keseluruhan sistem melalui vmstat
Apakah yang perlu saya lakukan jika terdapat sejumlah besar proses tidak terganggu dan proses zombi dalam sistem?
Proses status
R Running/Runnable, menunjukkan bahawa proses itu berada dalam baris gilir sedia CPU, berjalan atau menunggu untuk dijalankan
Dalam keadaan tidur, tidak terganggu secara amnya; proses Ia berinteraksi dengan perkakasan dan tidak dibenarkan diganggu oleh proses lain semasa interaksi
Z Zombie, proses zombi, bermakna proses itu sebenarnya telah tamat, tetapi proses induk belum dituntut semula; sumbernya;
S Interruptible Sleep, yang boleh mengganggu keadaan tidur, bermakna proses itu ditangguhkan oleh sistem kerana ia sedang menunggu untuk acara menunggu, ia akan dikejutkan dan memasuki Keadaan R;
I Melahu, keadaan melahu, digunakan dalam Pada benang inti tidur yang tidak terganggu.该状态不会导致平均负载升高;
T Stop/Traced,表示进程处于暂停或跟踪状态(SIGSTOP/SIGCONT, GDB调试);
Selepas pengoptimuman di atas, iowait telah menurun dengan ketara, tetapi bilangan proses zombi masih meningkat. Mula-mula, cari proses induk proses zombi Gunakan pstree -aps XXX untuk mencetak pepohon panggilan proses zombi dan mendapati bahawa proses induk ialah proses aplikasi.
Semak kod apl untuk melihat sama ada penghujung proses anak dikendalikan dengan betul (sama ada wait()/waitpid() dipanggil, sama ada terdapat fungsi pemprosesan isyarat SIGCHILD didaftarkan, dsb.).
Apabila menghadapi peningkatan dalam iowait, mula-mula gunakan alat seperti dstat dan pidstat untuk mengesahkan sama ada terdapat masalah I/O cakera, dan kemudian ketahui proses yang menyebabkan I/O jika anda tidak boleh menggunakan strace untuk menganalisis secara langsung panggilan proses, anda boleh menggunakan alat perf untuk menganalisisnya.
Untuk masalah zombi, gunakan pstree untuk mencari proses induk, dan kemudian lihat kod sumber untuk menyemak logik pemprosesan untuk akhir proses anak.
Metrik Prestasi CPU
Penggunaan CPU
. , CPU ialah Peratusan masa mod kernel sedang berjalan (tidak termasuk gangguan Penunjuk tinggi menunjukkan bahawa kernel agak sibuk
Penggunaan CPU menunggu I/O, iowait, penunjuk tinggi menunjukkan I. Masa interaksi /O antara sistem dan peranti perkakasan Agak panjang.
Penggunaan CPU gangguan lembut/keras, penunjuk yang tinggi menunjukkan bilangan gangguan yang besar dalam sistem.
mencuri CPU / tetamu CPU, menunjukkan peratusan CPU yang diduduki oleh mesin maya.
Purata beban
Sebaik-baiknya, beban purata adalah sama dengan bilangan CPU logik yang digunakan sepenuhnya. Jika lebih besar, bermakna beban sistem lebih berat.
Proses Suis Konteks
Termasuk pensuisan sukarela apabila sumber tidak dapat diperoleh dan pensuisan secara sukarela apabila sistem memaksa pensuisan konteks itu sendiri adalah fungsi teras untuk memastikan operasi normal Linux Pensuisan yang berlebihan akan memakan masa CPU proses berjalan asal dalam daftar. Inti dan memori maya dan penjimatan dan pemulihan data lain. Di samping itu, cari pengaturcara akaun awam Xiaole di belakang pentas untuk membalas "soalan temu bual" dan dapatkan pakej hadiah kejutan.
CPU Cache Hit Rate
cpu Cache digunakan semula, semakin tinggi kadar hit, lebih baik prestasi. -teras
Alat prestasi dan pid selepas menilai beban masing-masing CPU dan penggunaan CPU bagi setiap proses. Gunakan pidstat untuk memerhatikan penukaran konteks proses secara sukarela dan tidak sukarela
Akhir sekali, perhatikan penukaran konteks utas melalui pidstat
Kes penggunaan CPU proses tinggi
penggunaan pertama dan proses sistem untuk melihat penggunaan CPU dan proses pertama proses
Kemudian gunakan perf top untuk memerhati rantaian panggilan proses dan cari fungsi tertentu
kes penggunaan CPU sistem tinggi
penggunaan sistem dan proses, atas/ Malah pidstat tidak dapat mencari proses dengan penggunaan CPU yang tinggi
Periksa semula output teratas
🎜🎜🎜🎜Mulakan dengan proses yang mempunyai penggunaan CPU yang rendah tetapi dalam keadaan Berjalan 🎜🎜🎜
rekod/laporan perf menemui proses jangka pendek (alat execsnoop)
Kes proses tanpa gangguan dan zombi
yang ditemui untuk meningkatkan jumlah yang besar, memerhatikan dan memerhatikan bahagian atas proses tidak terganggu dan zombie Proses
strace tidak dapat mengesan panggilan sistem proses
rantai panggilan analisis perf mendapati punca punca datang dari cakera langsung I/O
pemerhatian atas Penggunaan CPU gangguan lembut sistem adalah tinggi
Semak /proc/softirqs untuk mencari beberapa gangguan lembut dengan kadar perubahan pantas yang ditemui
🎜🎜🎜🎜🎜🎜 masalah paket rangkaian🎜🎜🎜
tcpdump mengetahui jenis dan sumber bingkai rangkaian, dan menentukan punca serangan SYN FLOOD
Cari alat yang betul berdasarkan penunjuk prestasi berbeza:
dari www. ctq6.cn
Dalam persekitaran pengeluaran, pembangun selalunya tidak mempunyai kebenaran untuk memasang pakej alat baharu dan hanya boleh memaksimumkan penggunaan alatan yang telah dipasang dalam sistem Oleh itu, adalah perlu untuk memahami analisis penunjuk beberapa arus perdana alatan boleh sediakan.
🎜Gambar daripada: www.ctq6.cn
Mula-mula jalankan beberapa alatan yang menyokong lebih banyak penunjuk, seperti atas/vmstat/pidstat Berdasarkan outputnya, anda boleh menentukan jenis masalah prestasi itu. Selepas mengesan proses, gunakan strace/perf untuk menganalisis situasi panggilan untuk analisis lanjut Jika ia disebabkan oleh gangguan lembut, gunakan /proc/softirqs
Gambar daripada: www.ctq6.cn
CPU pengoptimuman
Pengoptimuman aplikasi
.
Gunakan cache dengan baik: Percepatkan pemprosesan program
Pengoptimuman sistem
CPU mengikat: Ikat proses kepada 1/berbilang CPU, tingkatkan kadar hit cache CPU dan kurangkan pensuisan konteks yang disebabkan oleh penjadualan CPU
CPU eksklusif: kepada CPU allocate Mekanisme
Pelarasan keutamaan: gunakan yang bagus untuk mengurangkan keutamaan aplikasi bukan teras dengan sewajarnya
Tetapkan paparan sumber untuk proses: cgroups menetapkan had atas penggunaan untuk mengelakkan keletihan akibat masalah aplikasi itu sendiri
numa Pengoptimuman: CPU mengakses memori tempatan sebanyak mungkin
imbalan beban pengimbangan: irpbalance, beban secara automatik mengimbangi proses pemprosesan interupsi untuk setiap cpu
tps, perbezaan dan pemahaman tentang QPS dan throughput sistem
QPS(TPS)
.
Pelayan permintaan pengguna
Pemprosesan dalaman pelayan
Pelayan mengembalikannya kepada klien
QPS serupa dengan TPS, tetapi lawatan ke halaman membentuk TPS, tetapi permintaan halaman mungkin termasuk permintaan berbilang ke pelayan, yang mungkin dikira Masukkan berbilang QPS
QPS (Queries Per Second) kadar pertanyaan sesaat, bilangan pertanyaan pelayan boleh membalas sesaat.
TPS (Transaksi Sesaat), hasil ujian perisian
Hasil sistem, termasuk beberapa parameter penting:
.
3memory
how Linux Memory Works Works
Memory
Memori utama yang digunakan oleh kebanyakan komputer adalah memori akses rawak dinamik (DRAM). akses terus memori fizikal. Kernel Linux menyediakan ruang alamat maya bebas untuk setiap proses, dan ruang alamat ini berterusan. Dengan cara ini, proses tersebut boleh mengakses memori (memori maya) dengan mudah.
Bahagian dalam ruang alamat maya dibahagikan kepada dua bahagian: ruang kernel dan ruang pengguna Julat ruang alamat pemproses dengan panjang perkataan yang berbeza adalah berbeza. Ruang kernel sistem 32-bit menduduki 1G dan ruang pengguna menduduki 3G. Ruang kernel dan ruang pengguna sistem 64-bit adalah kedua-duanya 128T, masing-masing menduduki bahagian tertinggi dan terendah ruang ingatan, dan bahagian tengah tidak ditentukan.
Tidak semua memori maya akan diperuntukkan memori fizikal, hanya memori yang digunakan sebenar. Memori fizikal yang diperuntukkan diuruskan melalui pemetaan memori. Untuk melengkapkan pemetaan memori, kernel mengekalkan jadual halaman untuk setiap proses untuk merekodkan hubungan pemetaan antara alamat maya dan alamat fizikal. Jadual halaman sebenarnya disimpan dalam unit pengurusan memori CPU MMU, dan pemproses boleh terus mengetahui memori untuk diakses melalui perkakasan.
Apabila alamat maya yang diakses oleh proses tidak ditemui dalam jadual halaman, sistem akan menjana pengecualian kesalahan halaman, masukkan ruang kernel untuk memperuntukkan memori fizikal, mengemas kini jadual halaman proses, dan kemudian kembali ke ruang pengguna untuk meneruskan operasi proses.
MMU menguruskan memori dalam unit halaman, dengan saiz halaman 4KB. Untuk menyelesaikan masalah terlalu banyak entri jadual halaman, Linux menyediakan mekanisme jadual halaman berbilang peringkat dan HugePage.
Pengagihan ruang memori maya
Memori ruang pengguna dibahagikan kepada lima segmen memori berbeza dari rendah ke tinggi:
Segmen baca sahaja Kod dan pemalar, dsb.
Segmen data Pembolehubah global, dsb.
terhimpit memori , bermula dari alamat rendah dan berkembang ke atas
Pemetaan fail
Perpustakaan dinamik, memori dikongsi, dsb., bermula dari alamat tinggi dan berkembang ke bawah
memasukkan saiz panggilan dan lain-lain. daripada timbunan telah ditetapkan.Secara umumnya 8MB
Peruntukan memori dan kitar semula
peruntukan
malloc sepadan dengan panggilan sistem. Terdapat dua kaedah pelaksanaan:
brk() Untuk blok kecil ingatan (
**mmap()** Untuk blok memori yang besar (>128K), peruntukkan terus menggunakan pemetaan memori, iaitu, cari peruntukan memori percuma dalam segmen pemetaan fail.
Cache bekas boleh mengurangkan berlakunya pengecualian kesalahan halaman dan meningkatkan kecekapan capaian memori. Walau bagaimanapun, kerana memori tidak dikembalikan kepada sistem, peruntukan/pelepasan memori yang kerap akan menyebabkan pemecahan memori apabila memori sibuk.
Yang terakhir dikembalikan terus ke sistem apabila dikeluarkan, jadi pengecualian kesalahan halaman akan berlaku setiap kali mmap berlaku. Apabila kerja memori sibuk, peruntukan memori yang kerap akan menyebabkan sejumlah besar pengecualian kesalahan halaman, meningkatkan beban pengurusan kernel.
Dua panggilan di atas sebenarnya tidak memperuntukkan memori ini hanya memasuki kernel melalui pengecualian kesalahan halaman apabila ia diakses buat kali pertama dan diperuntukkan oleh kernel
.
Kitar Semula
Apabila ingatan sempit, sistem menuntut semula memori dengan cara berikut:
Cache kitar semula: Algoritma LRU menuntut semula halaman memori yang paling kurang digunakan baru-baru ini; Kitar semula adalah jarang Memori capaian: tulis memori yang jarang digunakan pada cakera melalui partition swap ia menduduki, lebih kecil oom_score anda boleh lulus /proc secara manual melaraskan oom_adj)
echo -16 > /proc/$(pidof XXX)/oom_adj
如何查看内存使用情况
free来查看整个系统的内存使用情况
top/ps来查看某个进程的内存使用情况
VIRT Saiz memori maya proses
RESSaiz memori pemastautin, iaitu saiz memori fizikal yang sebenarnya digunakan oleh proses, tidak termasuk memori swap dan kongsi
SHR Saiz memori dikongsi, memori dikongsi dengan proses lain, perpustakaan pautan dinamik yang dimuatkan dan segmen kod program
%MEM Peratusan kepada jumlah memori fizikal yang digunakan oleh sistem memori
Bagaimana untuk memahami Penimbal dan Cache dalam memori?
Buffer ialah cache data cakera, cache ialah cache data fail, ia digunakan dalam kedua-dua permintaan baca dan tulis
Cara menggunakan cache sistem untuk mengoptimumkan kecekapan operasi program
Kadar hit cache
Kadar hit cache merujuk kepada bilangan permintaan untuk mendapatkan data terus melalui cache, mengambil kira peratusan semua permintaan. Lebih tinggi kadar hit, lebih tinggi faedah yang dibawa oleh cache dan lebih baik prestasi aplikasi.
Selepas memasang pakej bcc, anda boleh memantau cache baca dan tulis hits melalui cachestat dan cachetop.
安装pcstat后可以查看文件在内存中的缓存大小以及缓存比例
#首先安装Go
export GOPATH=~/go
export PATH=~/go/bin:$PATH
go get golang.org/x/sys/unix
go ge github.com/tobert/pcstat/pcstat
Memori bocor, bagaimana untuk mencari dan menanganinya?
Untuk aplikasi, peruntukan memori dinamik dan kitar semula ialah modul fungsi logik teras dan kompleks. Pelbagai "kemalangan" akan berlaku dalam proses menguruskan ingatan:
Memori yang diperuntukkan tidak dituntut semula dengan betul, mengakibatkan kebocoran
Alamat di luar sempadan memori yang diperuntukkan telah diakses, menyebabkan program keluar secara tidak normal
memori
memori
🎜🎜🎜 🎜🎜 Pengagihan memori maya dari rendah ke tinggi ialah 🎜segmen baca sahaja, segmen data, timbunan, segmen pemetaan memori dan tindanan 🎜lima bahagian. Antaranya yang boleh menyebabkan kebocoran ingatan ialah: 🎜🎜
Timbunan: Diperuntukkan dan diuruskan oleh aplikasi itu sendiri tidak akan dikeluarkan secara automatik oleh sistem melainkan program keluar.
Segmen pemetaan memori: termasuk perpustakaan pautan dinamik dan memori kongsi, di mana memori dikongsi secara automatik diperuntukkan dan diuruskan oleh program
Kebocoran memori ini bukan sahaja digunakan oleh kenangan aplikasi Mereka tidak boleh mengaksesnya sendiri, dan sistem tidak boleh memperuntukkannya kepada aplikasi lain lagi. Kebocoran memori terkumpul dan juga memori sistem ekzos.
Cache/buffer, yang merupakan sumber yang boleh dikitar semula, biasanya dipanggil halaman fail dalam pengurusan fail
Halaman kotor disegerakkan ke cakera melalui fsync dalam aplikasi
ke sistem, benang kernel pdflush bertanggungjawab untuk menyegarkan halaman kotor ini
Data (halaman kotor) yang telah diubah suai oleh aplikasi dan belum ditulis ke cakera buat masa ini mesti ditulis ke cakera dahulu dan kemudian ingatan boleh dilepaskan
Halaman pemetaan fail yang diperolehi dengan pemetaan juga boleh dilepaskan dan dibaca semula daripada fail pada kali berikutnya ia diakses Untuk memori timbunan yang diperuntukkan secara automatik oleh program, ia adalah halaman tanpa nama kami dalam pengurusan memori Walaupun memori ini Ia tidak boleh dikeluarkan secara langsung, tetapi Linux menyediakan mekanisme Swap untuk menulis memori yang jarang diakses ke cakera untuk melepaskan memori, dan kemudian membaca memori dari cakera apabila diakses. sekali lagi.
Prinsip Swap tidak digunakan buat sementara waktu oleh proses Data disimpan ke cakera dan memori ini dikeluarkan
Bertukar masuk: Apabila proses mengakses memori sekali lagi, bacanya dari cakera ke dalam memori
Bagaimanakah Linux mengukur sama ada sumber ingatan ketat?
Tebus guna Memori Terus Peruntukan memori blok besar baharu diminta, tetapi baki memori tidak mencukupi. Pada masa ini, sistem akan menuntut semula sebahagian daripada memori; Untuk mengukur penggunaan memori, tiga ambang pages_min, pages_low dan pages_high ditakrifkan dan operasi kitar semula memori dilakukan berdasarkannya.
Apabila Nod kehabisan memori, sistem boleh mencari sumber percuma daripada Nod lain atau menuntut semula memori daripada memori tempatan. Laraskan melalui /proc/sys/vm/zone_raclaim_mode. . data kotor boleh dikembalikan untuk menuntut semula memori, 4 menunjukkan bahawa memori boleh dituntut semula menggunakan Swap.
swappiness
Semasa proses kitar semula sebenar, Linux melaraskan keaktifan menggunakan Swap mengikut pilihan /proc/sys/vm/swapiness, dari 0-100, semakin besar nilainya Swap digunakan, iaitu, lebih cenderung untuk menggunakan Swap Untuk mengitar semula halaman tanpa nama, lebih pasif Swap digunakan, iaitu, lebih besar kemungkinan untuk mengitar semula halaman fail.
Cara mencari masalah memori sistem dengan cepat dan tepat
Penunjuk prestasi memori
Penunjuk memori sistem
Memori terpakai/baki memori : fail baca cakera Cache halaman , bahagian yang boleh dituntut semula dalam pengalokasi papak
Penampan: penyimpanan sementara blok cakera mentah, cache data yang akan ditulis ke cakera
Penunjuk memori proses
Memori Maya: 5 Paling
Memori Penduduk: Memori fizikal yang sebenarnya digunakan oleh proses, tidak termasuk Swap dan Memori Dikongsi
dengan Memori yang dikongsi bersama: dan Perkongsian Kod yang lain segmen perpustakaan dan program pautan dinamik
Tukar memori: Tukar memori ke cakera melalui Swap. Ikuti komuniti Cina Linux
pengecualian halaman yang tiada
boleh diperuntukkan terus dari memori fizikal Pengecualian tiada halaman sekunder
memerlukan campur tangan IO cakera (seperti Swap), dan pengecualian tiada halaman utama. Pada masa ini, akses memori akan menjadi lebih perlahan
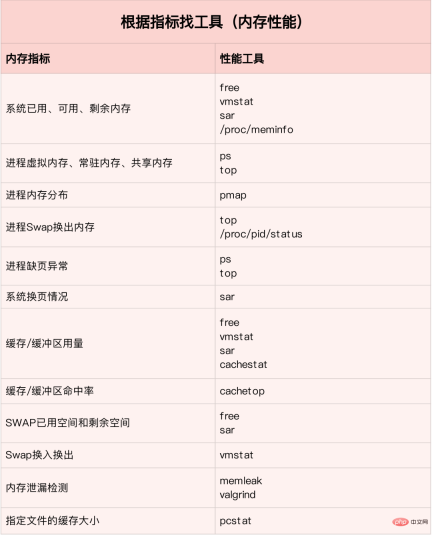
Alat prestasi memori
Cari alat yang betul berdasarkan penunjuk prestasi yang berbeza:
Gambar dari: www.ctq6.cn
Penunjuk prestasi disertakan dalam alat analisis ingatan:
Gambar dari:How. untuk menganalisis ingatan dengan cepat performance Bottleneck
Biasanya jalankan beberapa alatan prestasi dengan liputan yang agak besar dahulu, seperti percuma, atas, vmstat, pidstat, dll.
Mula-mula gunakan percuma dan atas untuk menyemak keseluruhan penggunaan memori sistem
Kemudian gunakan vmstat dan pidstat untuk menyemak trend dalam satu tempoh masa untuk menentukan jenis masalah ingatan Akhir sekali, jalankan analisis terperinci, Contohnya, analisis peruntukan memori, analisis cache/penampan, analisis penggunaan memori proses tertentu, dll.
Idea pengoptimuman biasa:
Sebaik-baiknya lumpuhkan Swap Jika anda mesti mendayakannya, cuba kurangkan nilai swappiness
Kurangkan peruntukan memori yang dinamik. Contohnya, anda boleh menggunakan kumpulan memori, HugePage .
Gunakan cache dan penimbal sebanyak mungkin untuk mengakses data. Contohnya, gunakan tindanan untuk mengisytiharkan ruang memori secara eksplisit untuk menyimpan data yang perlu dicache, atau gunakan komponen cache luaran Redis untuk mengoptimumkan akses data
ckumpulan dan kaedah lain untuk mengehadkan penggunaan memori bagi proses dan pastikan memori sistem tidak digunakan oleh proses yang tidak normal Cuba
/proc/pid/oom_adj melaraskan oom_score aplikasi teras untuk memastikan aplikasi teras tidak akan dimatikan oleh OOM. ingatan ketat
Penjelasan terperinci tentang penggunaan vmstat
Arahan vmstat adalah yang paling biasa Alat pemantauan Linux/Unix boleh memaparkan nilai status pelayan pada selang masa tertentu, termasuk penggunaan CPU pelayan , penggunaan memori, status pertukaran memori maya dan status baca dan tulis IO.可以看到整个机器的CPU,内存,IO的使用情况,而不是单单看到各个进程的CPU使用率和内存使用率(使用场景不一样)。
Atas ialah kandungan terperinci Ringkasan pengalaman penalaan menyeluruh prestasi Linux. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Kenyataan
Artikel ini dikembalikan pada:Linux中文社区. Jika ada pelanggaran, sila hubungi admin@php.cn Padam
Mod penyelenggaraan digunakan untuk penyelenggaraan sistem dan pembaikan, yang membolehkan pentadbir bekerja dalam persekitaran yang mudah. 1. Pembaikan Sistem: Pembaikan Sistem Fail Rasuah dan Loader Boot. 2. Reset Kata Laluan: Tetapkan semula kata laluan pengguna root. 3. Pengurusan Pakej: Pasang, Kemas kini atau Padam Pakej Perisian. Dengan mengubah suai konfigurasi grub atau memasuki mod penyelenggaraan dengan kunci tertentu, anda boleh keluar dengan selamat selepas melaksanakan tugas penyelenggaraan.
Konfigurasi rangkaian Linux boleh diselesaikan melalui langkah -langkah berikut: 1. Konfigurasi antara muka rangkaian, gunakan arahan IP untuk menetapkan atau mengedit tetapan ketekunan fail konfigurasi. 2. Sediakan IP statik, sesuai untuk peranti yang memerlukan IP tetap. 3. Menguruskan firewall dan gunakan alat -alat iptables atau firewalld untuk mengawal trafik rangkaian.
Mod penyelenggaraan memainkan peranan utama dalam pengurusan sistem Linux, membantu membaiki, menaik taraf dan perubahan konfigurasi. 1. Masukkan mod penyelenggaraan. Anda boleh memilihnya melalui menu grub atau menggunakan arahan "SudosystemCtlisolaterscue.target". 2. Dalam mod penyelenggaraan, anda boleh melakukan pembaikan sistem fail dan operasi kemas kini sistem. 3. Penggunaan lanjutan termasuk tugas -tugas seperti menetapkan semula kata laluan root. 4. Kesilapan umum seperti tidak dapat memasukkan mod penyelenggaraan atau memasang sistem fail, boleh diperbaiki dengan memeriksa konfigurasi grub dan menggunakan arahan FSCK.
Masa dan alasan untuk menggunakan mod penyelenggaraan Linux: 1) Apabila sistem bermula, 2) apabila melakukan kemas kini sistem utama atau peningkatan, 3) apabila melakukan penyelenggaraan sistem fail. Mod penyelenggaraan menyediakan persekitaran yang selamat dan terkawal, memastikan keselamatan dan kecekapan operasi, mengurangkan kesan kepada pengguna, dan meningkatkan keselamatan sistem.
Perintah yang tidak diperlukan di Linux termasuk: 1.LS: Kandungan Direktori Senarai; 2.CD: Tukar direktori kerja; 3.MKDIR: Buat direktori baru; 4.RM: Padam fail atau direktori; 5.CP: Salin fail atau direktori; 6.MV: Pindahkan atau menamakan semula fail atau direktori. Perintah ini membantu pengguna menguruskan fail dan sistem dengan cekap dengan berinteraksi dengan kernel.
Di Linux, pengurusan fail dan direktori menggunakan arahan LS, CD, MKDIR, RM, CP, MV, dan Pengurusan Kebenaran menggunakan arahan CHMOD, Chown, dan CHGRP. 1. Perintah pengurusan fail dan direktori seperti senarai terperinci LS-L, MKDIR-P membuat direktori secara rekursif. 2. Perintah Pengurusan Kebenaran seperti Kebenaran Fail Set Chmod755File, ChownUserFile mengubah pemilik fail, dan ChGRPGroupFile Change File Group. Perintah ini berdasarkan struktur sistem fail dan sistem pengguna dan kumpulan, dan mengendalikan dan mengawal melalui panggilan sistem dan metadata.
Komponen teras Linux termasuk kernel, sistem fail, shell, pengguna dan ruang kernel, pemandu peranti, dan pengoptimuman prestasi dan amalan terbaik. 1) Kernel adalah teras sistem, menguruskan perkakasan, memori dan proses. 2) Sistem fail menganjurkan data dan menyokong pelbagai jenis seperti Ext4, BTRFS dan XFS. 3) Shell adalah pusat arahan untuk pengguna untuk berinteraksi dengan sistem dan menyokong skrip. 4) Ruang pengguna berasingan dari ruang kernel untuk memastikan kestabilan sistem. 5) Pemandu peranti menghubungkan perkakasan ke sistem operasi. 6) Pengoptimuman prestasi termasuk konfigurasi sistem penalaan dan mengikuti amalan terbaik.
Damn Vulnerable Web App (DVWA) ialah aplikasi web PHP/MySQL yang sangat terdedah. Matlamat utamanya adalah untuk menjadi bantuan bagi profesional keselamatan untuk menguji kemahiran dan alatan mereka dalam persekitaran undang-undang, untuk membantu pembangun web lebih memahami proses mengamankan aplikasi web, dan untuk membantu guru/pelajar mengajar/belajar dalam persekitaran bilik darjah Aplikasi web keselamatan. Matlamat DVWA adalah untuk mempraktikkan beberapa kelemahan web yang paling biasa melalui antara muka yang mudah dan mudah, dengan pelbagai tahap kesukaran. Sila ambil perhatian bahawa perisian ini
SecLists ialah rakan penguji keselamatan muktamad. Ia ialah koleksi pelbagai jenis senarai yang kerap digunakan semasa penilaian keselamatan, semuanya di satu tempat. SecLists membantu menjadikan ujian keselamatan lebih cekap dan produktif dengan menyediakan semua senarai yang mungkin diperlukan oleh penguji keselamatan dengan mudah. Jenis senarai termasuk nama pengguna, kata laluan, URL, muatan kabur, corak data sensitif, cangkerang web dan banyak lagi. Penguji hanya boleh menarik repositori ini ke mesin ujian baharu dan dia akan mempunyai akses kepada setiap jenis senarai yang dia perlukan.


 Operasi dan penyelenggaraan
Operasi dan penyelenggaraan







 Mod Penyelenggaraan Linux: Memahami TujuannyaApr 28, 2025 am 12:01 AM
Mod Penyelenggaraan Linux: Memahami TujuannyaApr 28, 2025 am 12:01 AM Operasi Linux: Konfigurasi Rangkaian dan RangkaianApr 27, 2025 am 12:09 AM
Operasi Linux: Konfigurasi Rangkaian dan RangkaianApr 27, 2025 am 12:09 AM Mod Penyelenggaraan di Linux: Panduan Pentadbir SistemApr 26, 2025 am 12:20 AM
Mod Penyelenggaraan di Linux: Panduan Pentadbir SistemApr 26, 2025 am 12:20 AM Mod penyelenggaraan di linux: kapan dan mengapa menggunakannyaApr 25, 2025 am 12:15 AM
Mod penyelenggaraan di linux: kapan dan mengapa menggunakannyaApr 25, 2025 am 12:15 AM Linux: Perintah dan operasi pentingApr 24, 2025 am 12:20 AM
Linux: Perintah dan operasi pentingApr 24, 2025 am 12:20 AM Operasi Linux: Menguruskan Fail, Direktori, dan KebenaranApr 23, 2025 am 12:19 AM
Operasi Linux: Menguruskan Fail, Direktori, dan KebenaranApr 23, 2025 am 12:19 AM Apakah mod penyelenggaraan di Linux? DijelaskanApr 22, 2025 am 12:06 AM
Apakah mod penyelenggaraan di Linux? DijelaskanApr 22, 2025 am 12:06 AM Linux: menyelam yang mendalam ke bahagian asasnyaApr 21, 2025 am 12:03 AM
Linux: menyelam yang mendalam ke bahagian asasnyaApr 21, 2025 am 12:03 AM













