
Rumah >Peranti teknologi >AI >Kertas hangat baharu Microsoft: Transformer berkembang kepada 1 bilion token
Kertas hangat baharu Microsoft: Transformer berkembang kepada 1 bilion token

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-07-22 15:34:011283semak imbas
Apabila semua orang terus menaik taraf dan mengulang model besar mereka sendiri, keupayaan LLM (Model Bahasa Besar) untuk memproses tetingkap konteks juga telah menjadi penunjuk penilaian yang penting.
Sebagai contoh, model besar selebriti GPT-4 menyokong 32k token, yang bersamaan dengan 50 halaman teks, yang diasaskan oleh bekas ahli OpenAI, telah meningkatkan keupayaan pemprosesan token Claude kepada 100k, kira-kira 75,000 perkataan; yang secara kasarnya bersamaan dengan ringkasan satu klik "Harry Potter" Bahagian Pertama.
Dalam penyelidikan terkini Microsoft, mereka terus mengembangkan Transformer kepada 1 bilion token kali ini. Ini membuka kemungkinan baharu untuk memodelkan jujukan yang sangat panjang, seperti menganggap keseluruhan korpus atau malah keseluruhan Internet sebagai satu jujukan.
Sebagai perbandingan, purata orang boleh membaca 100,000 token dalam masa kira-kira 5 jam, dan mungkin mengambil masa yang lebih lama untuk mencerna, menghafal dan menganalisis maklumat ini. Claude boleh melakukan ini dalam masa kurang daripada satu minit. Jika ditukar kepada penyelidikan ini oleh Microsoft, ia akan menjadi angka yang mengejutkan.
 Gambar
Gambar
- Alamat kertas: https://arxiv.org/pdf/2307.02486.pdf
- Alamat projek: https://github.com/unisoft
Secara khusus, penyelidikan mencadangkan LONGNET, varian Transformer yang boleh memanjangkan panjang jujukan kepada lebih 1 bilion token tanpa mengorbankan prestasi pada jujukan yang lebih pendek. Artikel itu juga mencadangkan perhatian yang meluas, yang boleh mengembangkan julat persepsi model secara eksponen.
longnet mempunyai kelebihan berikut:
1) Ia mempunyai kerumitan komputasi linear; digunakan tanpa Seam menggantikan perhatian standard dan boleh disepadukan dengan lancar dengan kaedah pengoptimuman berasaskan Transformer sedia ada.
Hasil eksperimen menunjukkan bahawa LONGNET mempamerkan prestasi yang kukuh dalam kedua-dua pemodelan jujukan panjang dan tugasan bahasa umum.
Dari segi motivasi penyelidikan, kertas kerja menyatakan bahawa dalam beberapa tahun kebelakangan ini, meluaskan rangkaian saraf telah menjadi trend, dan banyak rangkaian dengan prestasi yang baik telah dikaji. Antaranya, panjang jujukan, sebagai sebahagian daripada rangkaian saraf, sepatutnya tidak terhingga. Tetapi realitinya selalunya sebaliknya, jadi melanggar had panjang jujukan akan membawa kelebihan yang ketara:
Pertama, ia menyediakan model dengan memori berkapasiti besar dan medan penerimaan, membolehkannya berkomunikasi secara berkesan dengan manusia dan dunia.
Kedua, konteks yang lebih panjang mengandungi hubungan sebab akibat yang lebih kompleks dan laluan penaakulan yang boleh dieksploitasi oleh model dalam data latihan. Sebaliknya, kebergantungan yang lebih pendek akan memperkenalkan korelasi yang lebih palsu, yang tidak kondusif untuk generalisasi model.
- Ketiga, panjang jujukan yang lebih panjang boleh membantu model meneroka konteks yang lebih panjang, dan konteks yang sangat panjang juga boleh membantu model mengurangkan masalah lupa yang dahsyat.
- Walau bagaimanapun, cabaran utama dalam memanjangkan panjang jujukan ialah mencari keseimbangan yang tepat antara kerumitan pengiraan dan kuasa ekspresif model.
- Sebagai contoh, model gaya RNN digunakan terutamanya untuk meningkatkan panjang jujukan. Walau bagaimanapun, sifat urutannya mengehadkan keselarian semasa latihan, yang penting dalam pemodelan jujukan panjang.
Baru-baru ini, model ruang negeri telah menjadi sangat menarik untuk pemodelan jujukan, yang boleh dijalankan sebagai CNN semasa latihan dan ditukar kepada RNN yang cekap pada masa ujian. Walau bagaimanapun, model jenis ini tidak berfungsi sebaik Transformer pada panjang biasa.
Satu lagi cara untuk memanjangkan panjang jujukan ialah mengurangkan kerumitan Transformer, iaitu, kerumitan kuadratik perhatian diri. Pada peringkat ini, beberapa varian berasaskan Transformer yang cekap telah dicadangkan, termasuk perhatian peringkat rendah, kaedah berasaskan kernel, kaedah pensampelan turun, dan kaedah berasaskan pengambilan semula. Walau bagaimanapun, pendekatan ini masih belum menskalakan Transformer kepada skala 1 bilion token (lihat Rajah 1).
Gambar
Jadual berikut menunjukkan perbandingan kerumitan pengiraan kaedah pengiraan yang berbeza. N ialah panjang jujukan, dan d ialah dimensi tersembunyi.
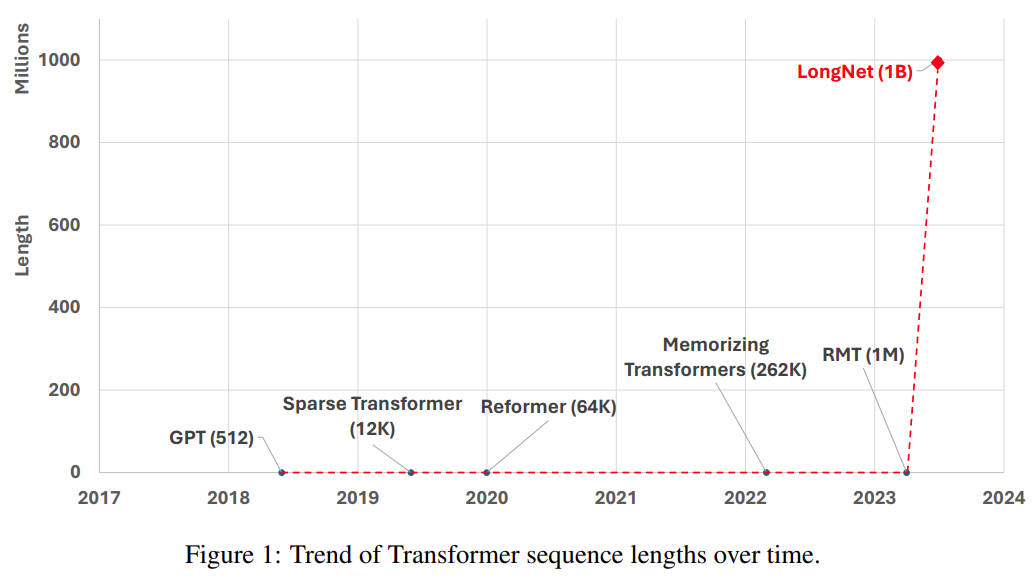 gambar
gambar
Kaedah
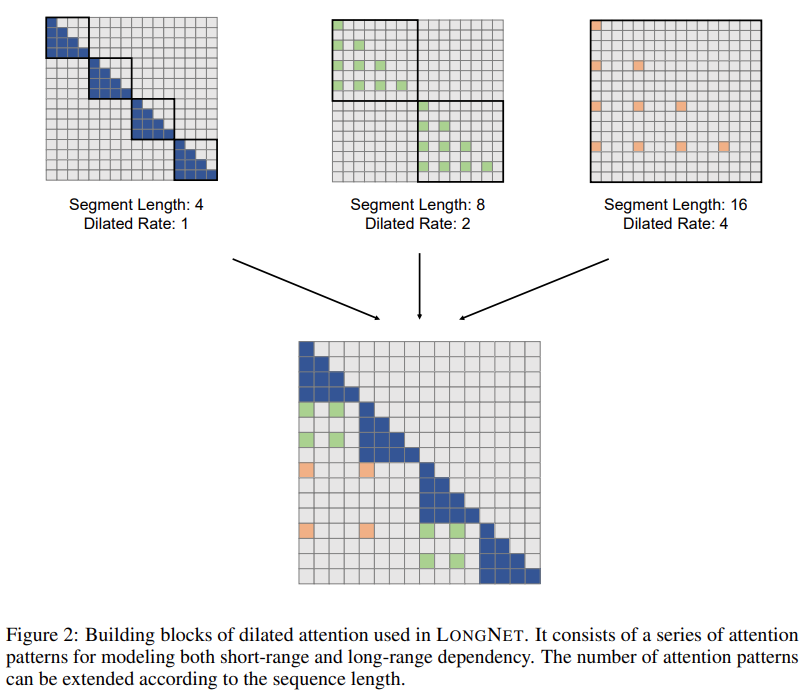
Penyelesaian penyelidikan LONGNET berjaya memanjangkan panjang jujukan kepada 1 bilion token. Secara khusus, penyelidikan ini mencadangkan komponen baru yang dipanggil perhatian diluaskan dan menggantikan mekanisme perhatian Transformer Vanila dengan perhatian diluaskan. Prinsip reka bentuk umum ialah peruntukan perhatian berkurangan secara eksponen apabila jarak antara token bertambah. Kajian menunjukkan bahawa pendekatan reka bentuk ini memperoleh kerumitan pengiraan linear dan pergantungan logaritma antara token. Ini menyelesaikan konflik antara sumber perhatian terhad dan akses kepada setiap token. . Mengambil kesempatan daripada kerumitan linear, LONGNET boleh dilatih secara selari merentas nod, menggunakan algoritma teragih untuk memecahkan kekangan pengkomputeran dan ingatan.
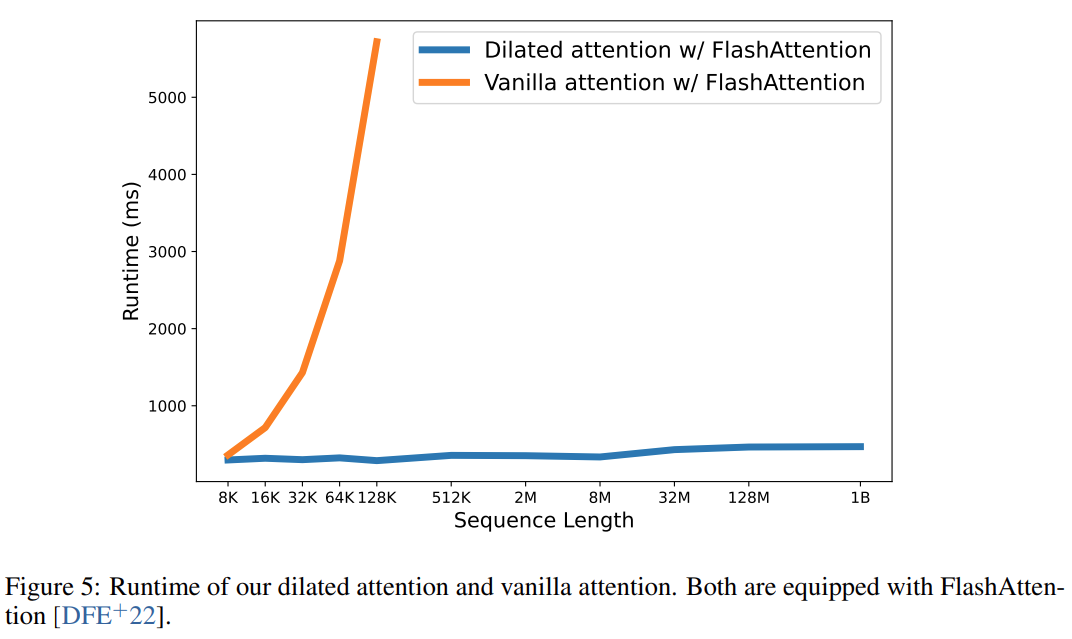
 Akhirnya, penyelidikan ini secara berkesan mengembangkan panjang jujukan kepada token 1B, dan masa jalannya hampir tetap, seperti yang ditunjukkan dalam rajah di bawah. Sebaliknya, masa jalan Transformer vanila mengalami kerumitan kuadratik.
Akhirnya, penyelidikan ini secara berkesan mengembangkan panjang jujukan kepada token 1B, dan masa jalannya hampir tetap, seperti yang ditunjukkan dalam rajah di bawah. Sebaliknya, masa jalan Transformer vanila mengalami kerumitan kuadratik.
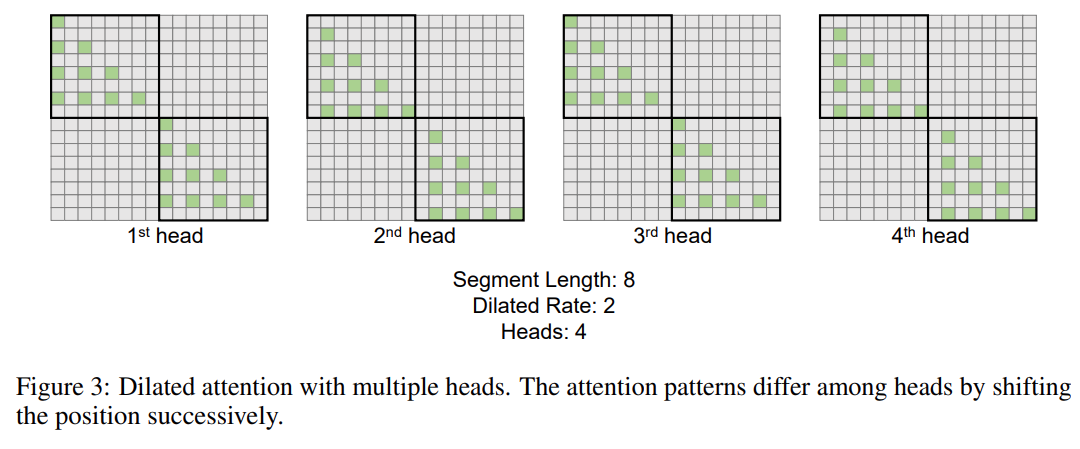
Penyelidikan ini memperkenalkan lagi mekanisme perhatian diluaskan berbilang kepala. Seperti yang ditunjukkan dalam Rajah 3 di bawah, kajian ini melakukan pengiraan yang berbeza merentas kepala yang berbeza dengan mengecilkan bahagian berlainan pasangan nilai kunci pertanyaan.
 Pictures
Pictures
Divibusi Latihan -walaupun kerumitan pengiraan perhatian diluaskan telah dikurangkan dengan ketara kepada
 , disebabkan oleh pengkomputeran dan batasan memori, ia akan mengukur panjang urutan ke berjuta-juta tidak boleh dilaksanakan. Terdapat beberapa algoritma latihan teragih untuk latihan model berskala besar, seperti selari model [SPP+19], selari jujukan [LXLY21, KCL+22] dan selari saluran paip [HCB+19]. . , terutamanya apabila dimensi jujukan adalah sangat besar.
, disebabkan oleh pengkomputeran dan batasan memori, ia akan mengukur panjang urutan ke berjuta-juta tidak boleh dilaksanakan. Terdapat beberapa algoritma latihan teragih untuk latihan model berskala besar, seperti selari model [SPP+19], selari jujukan [LXLY21, KCL+22] dan selari saluran paip [HCB+19]. . , terutamanya apabila dimensi jujukan adalah sangat besar.
Penyelidikan ini menggunakan kerumitan pengiraan linear LONGNET untuk latihan teragih bagi dimensi jujukan. Rajah 4 di bawah menunjukkan algoritma yang diedarkan pada dua GPU, yang boleh ditingkatkan lagi kepada sebarang bilangan peranti. Kajian ini membandingkan LONGNET dengan Transformer vanila dan Transformer jarang. Perbezaan antara seni bina adalah lapisan perhatian, manakala lapisan lain kekal tidak berubah. Para penyelidik mengembangkan panjang jujukan model ini daripada 2K kepada 32K, sambil mengurangkan saiz kelompok untuk memastikan bilangan token dalam setiap kelompok kekal tidak berubah. Jadual 2 meringkaskan keputusan model ini pada set data Tindanan. Penyelidikan menggunakan kerumitan sebagai metrik penilaian. Model telah diuji menggunakan panjang jujukan yang berbeza, antara 2k hingga 32k. Apabila panjang input melebihi panjang maksimum yang disokong oleh model, penyelidikan melaksanakan perhatian sebab akibat blok (BCA) [SDP+22], kaedah ekstrapolasi terkini untuk inferens model bahasa.
Selain itu, kajian itu mengalih keluar pengekodan kedudukan mutlak. Pertama, keputusan menunjukkan bahawa peningkatan panjang urutan semasa latihan umumnya menghasilkan model bahasa yang lebih baik. Kedua, kaedah ekstrapolasi panjang jujukan dalam inferens tidak terpakai apabila panjangnya jauh lebih besar daripada sokongan model. Akhir sekali, LONGNET secara konsisten mengatasi model garis dasar, menunjukkan keberkesanannya dalam pemodelan bahasa. 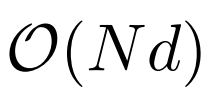
Lengkung pengembangan panjang jujukan
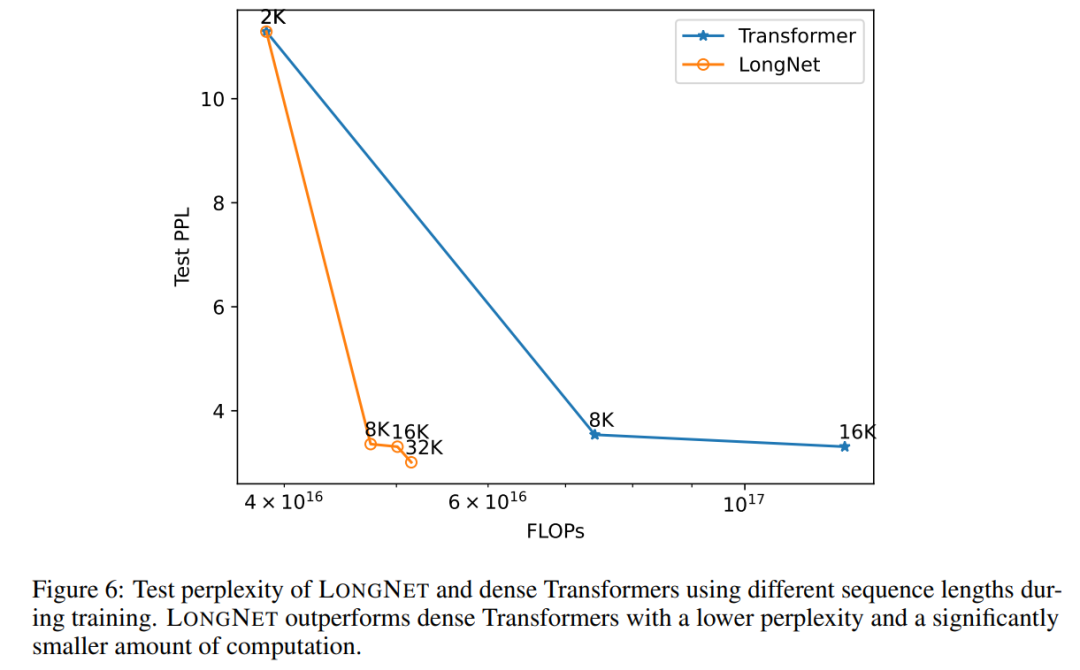
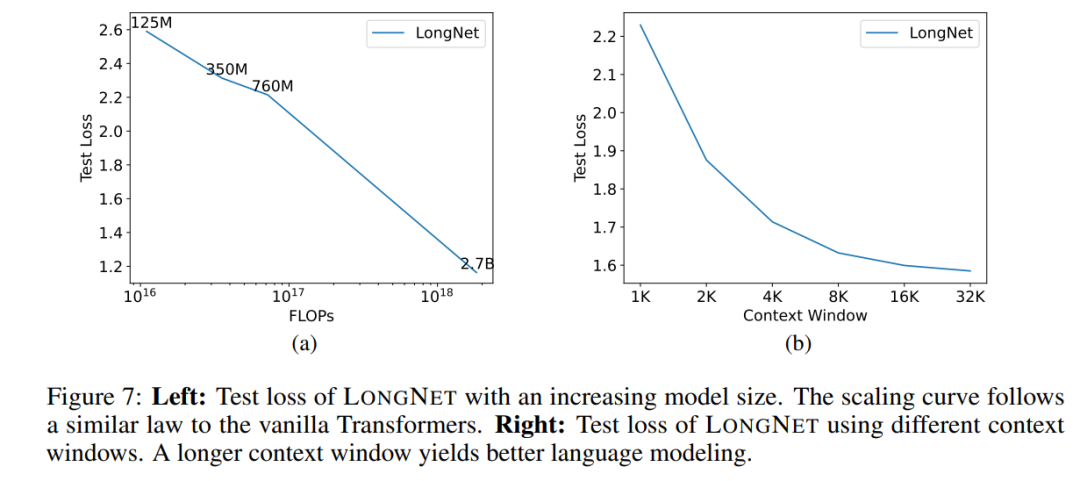
Rajah 6 memplotkan lengkung pengembangan panjang jujukan pengubah vanila dan LONGNET. Kajian ini menganggarkan usaha pengiraan dengan mengira jumlah flop pendaraban matriks. Keputusan menunjukkan bahawa kedua-dua pengubah vanila dan LONGNET mencapai panjang konteks yang lebih besar daripada latihan. Walau bagaimanapun, LONGNET boleh memanjangkan panjang konteks dengan lebih cekap, mencapai kehilangan ujian yang lebih rendah dengan kurang pengiraan. Ini menunjukkan kelebihan input latihan yang lebih lama berbanding ekstrapolasi. Eksperimen menunjukkan bahawa LONGNET ialah cara yang lebih cekap untuk memanjangkan panjang konteks dalam model bahasa. Ini kerana LONGNET boleh mempelajari kebergantungan yang lebih panjang dengan lebih cekap. . Untuk mengesahkan sama ada LONGNET masih mengikut peraturan penskalaan yang sama, kajian itu melatih satu siri model dengan saiz model yang berbeza (daripada 125 juta hingga 2.7 bilion parameter). 2.7 bilion model telah dilatih dengan token 300B, manakala model selebihnya menggunakan kira-kira 400B token. Rajah 7 (a) memplotkan lengkung penskalaan LONGNET berkenaan dengan pengiraan. Kajian itu mengira kerumitan pada set ujian yang sama. Ini membuktikan bahawa LONGNET masih boleh mengikut undang-undang kuasa. Ini juga bermakna Transformer padat bukanlah prasyarat untuk melanjutkan model bahasa. Selain itu, kebolehskalaan dan kecekapan diperoleh dengan LONGNET. Prompt konteks panjang Kajian ini mengekalkan awalan (awalan) sebagai gesaan dan menguji kebingungan imbuhannya (akhiran). Selain itu, semasa proses penyelidikan, gesaan telah dikembangkan secara beransur-ansur daripada 2K kepada 32K. Untuk membuat perbandingan yang saksama, panjang akhiran dikekalkan tetap manakala panjang awalan ditambah kepada panjang maksimum model. Rajah 7(b) melaporkan keputusan pada set ujian. Ia menunjukkan bahawa kehilangan ujian LONGNET secara beransur-ansur berkurangan apabila tetingkap konteks meningkat. Ini membuktikan keunggulan LONGNET dalam menggunakan sepenuhnya konteks panjang untuk menambah baik model bahasa. 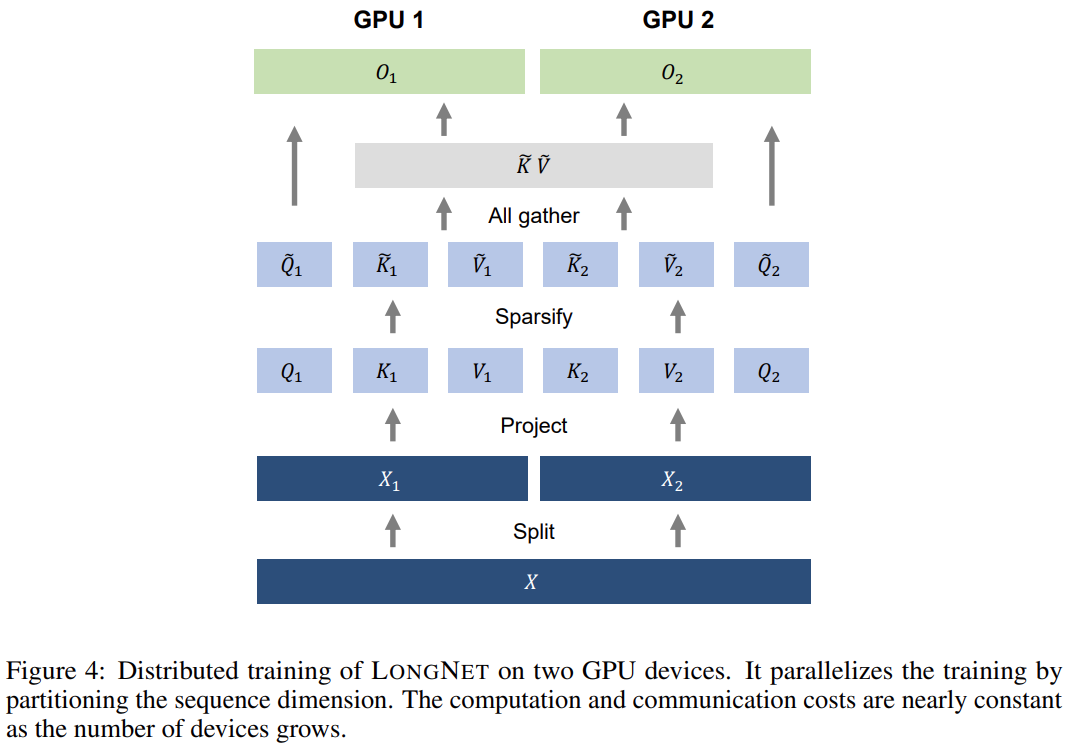
Atas ialah kandungan terperinci Kertas hangat baharu Microsoft: Transformer berkembang kepada 1 bilion token. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI