
Rumah >Peranti teknologi >AI >Kos melatih model besar telah dikurangkan hampir separuh! Pengoptimum terkini Universiti Nasional Singapura telah digunakan
Kos melatih model besar telah dikurangkan hampir separuh! Pengoptimum terkini Universiti Nasional Singapura telah digunakan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-07-17 22:13:171499semak imbas
Pengoptimum menduduki sejumlah besar sumber memori dalam latihan model bahasa yang besar.
Kini terdapat kaedah pengoptimuman baharu yang mengurangkan penggunaan memori sebanyak separuh sambil mengekalkan prestasi yang sama.
Keputusan ini dicipta oleh Universiti Nasional Singapura Ia memenangi Anugerah Kertas Cemerlang di persidangan ACL dan telah dimasukkan ke dalam aplikasi praktikal.
 Gambar
Gambar
Dengan peningkatan bilangan parameter model bahasa besar, masalah penggunaan ingatan semasa latihan menjadi lebih teruk.
Pasukan penyelidik mencadangkan pengoptimum CAME, yang mempunyai prestasi yang sama seperti Adam sambil mengurangkan penggunaan memori.
 Gambar
Gambar
Pengoptimum CAME telah mencapai prestasi latihan yang sama atau lebih baik daripada pengoptimum Adam dalam pra-latihan pelbagai model bahasa berskala besar yang biasa digunakan, dan menunjukkan keteguhan yang lebih besar kepada senario pra-latihan kelompok besar seks.
Selain itu, melatih model bahasa besar melalui pengoptimum CAME boleh mengurangkan kos latihan model besar dengan ketara.
Kaedah pelaksanaan
Pengoptimum CAME dipertingkatkan berdasarkan pengoptimum Adafactor, yang sering membawa kehilangan prestasi latihan dalam tugas pra-latihan model bahasa berskala besar.
Operasi pemfaktoran matriks bukan negatif dalam Adafactor pasti akan menghasilkan ralat dalam latihan rangkaian neural dalam, dan pembetulan ralat ini adalah punca kehilangan prestasi.
Dan melalui perbandingan, didapati apabila perbezaan antara nilai permulaan mt dan nilai semasa t adalah kecil, keyakinan mt adalah lebih tinggi.
 Gambar
Gambar
Diilhamkan oleh ini, pasukan mencadangkan algoritma pengoptimuman baharu.
Bahagian biru dalam gambar di bawah adalah bahagian CAME yang meningkat berbanding dengan Adafactor.
 Picture
Picture
CAME optimizer melakukan pembetulan jumlah kemas kini berdasarkan keyakinan kemas kini model, dan juga melakukan operasi penguraian matriks bukan negatif pada matriks keyakinan yang diperkenalkan.
Akhirnya CAME berjaya mendapatkan kesan Adam dengan pengambilan Adafactor.
Kesan yang sama hanya menggunakan separuh daripada sumber
Pasukan menggunakan CAME untuk melatih model BERT, GPT-2 dan T5 masing-masing.
Adam yang biasa digunakan sebelum ini (kesan lebih baik) dan Adafactor (penggunaan lebih rendah) adalah rujukan untuk mengukur prestasi CAME.
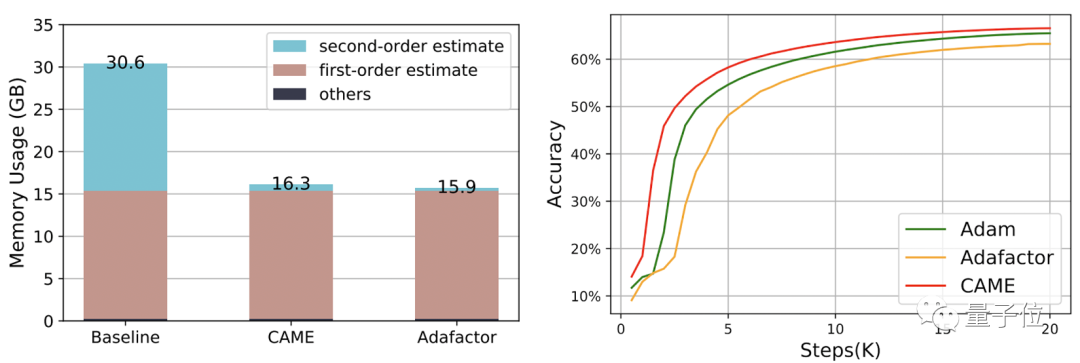
Antaranya, dalam proses latihan BERT, CAME mencapai ketepatan yang sama seperti Adafaactor hanya dalam separuh bilangan langkah.
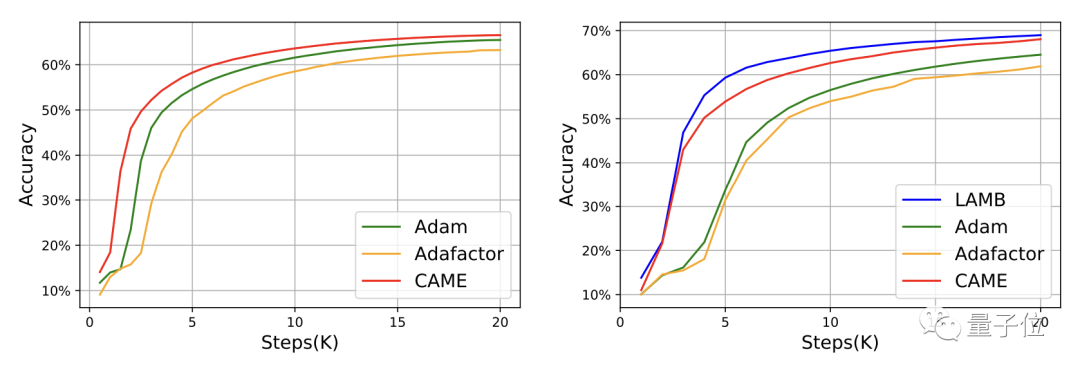 △Sebelah kiri skala 8K, sebelah kanan skala 32K
△Sebelah kiri skala 8K, sebelah kanan skala 32K
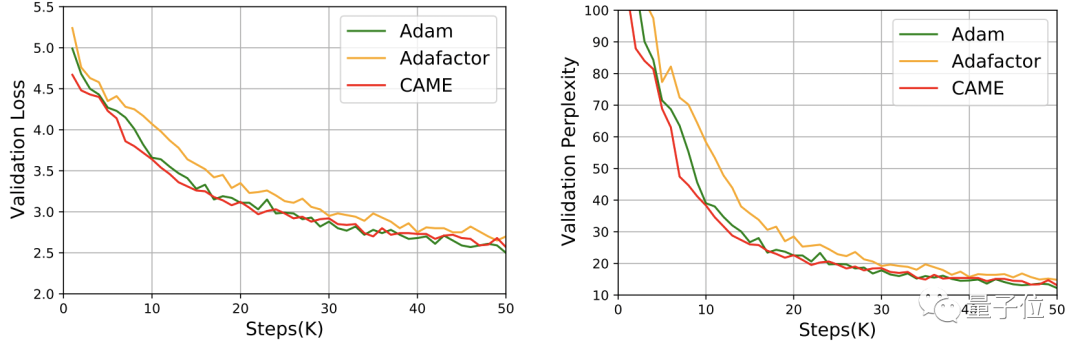
Untuk GPT-2, dari perspektif kerugian dan kekeliruan, prestasi CAME sangat dekat dengan Adam.

Dalam latihan model T5, CAME juga menunjukkan hasil yang sama.
Bagi penalaan halus model, prestasi CAME dalam ketepatan tidak kalah dengan penanda aras.
Dari segi penggunaan sumber, apabila menggunakan PyTorch untuk melatih BERT dengan volum data 4B, sumber memori yang digunakan oleh CAME dikurangkan hampir separuh berbanding dengan garis dasar.
Profil Pasukan
Makmal HPC-AI Universiti Nasional Singapura ialah makmal pengkomputeran dan kecerdasan buatan berprestasi tinggi yang diketuai oleh Profesor You Yang.
Makmal komited terhadap penyelidikan dan inovasi pengkomputeran berprestasi tinggi, sistem pembelajaran mesin dan pengkomputeran selari teragih, dan mempromosikan aplikasi dalam bidang seperti model bahasa berskala besar.
Ketua makmal, You Yang, ialah Presiden Profesor Muda(Profesor Muda Presiden) Jabatan Sains Komputer di Universiti Nasional Singapura.
You Yang telah dipilih ke dalam Senarai Elit Bawah 30 Tahun (Asia) Forbes pada tahun 2021 dan memenangi Anugerah Pendatang Baru Cemerlang Pengkomputeran Super IEEE-CS semasa beliau adalah pada pengoptimuman yang diedarkan bagi algoritma latihan pembelajaran mendalam berskala besar.
Luo Yang, pengarang pertama artikel ini, ialah pelajar sarjana di makmal fokus penyelidikannya sekarang adalah pada kestabilan dan latihan yang cekap bagi latihan model besar.
Alamat kertas: https://arxiv.org/abs/2307.02047
Halaman projek GitHub: https://github.com/huawei-noah/Ptrained-Language-Model/tree/master/CAME
Atas ialah kandungan terperinci Kos melatih model besar telah dikurangkan hampir separuh! Pengoptimum terkini Universiti Nasional Singapura telah digunakan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI