
Rumah >Peranti teknologi >AI >Pasukan Byte mencadangkan model Lynx: pemahaman LLM berbilang modal dan senarai penjanaan kognitif SoTA
Pasukan Byte mencadangkan model Lynx: pemahaman LLM berbilang modal dan senarai penjanaan kognitif SoTA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-07-17 21:57:301480semak imbas
Model Bahasa Besar (LLM) semasa seperti GPT4 telah menunjukkan keupayaan pelbagai mod yang sangat baik dalam mengikuti arahan terbuka yang diberikan imej. Walau bagaimanapun, prestasi model ini sangat bergantung pada pilihan struktur rangkaian, data latihan, dan strategi latihan, tetapi pilihan ini tidak dibincangkan secara meluas dalam literatur sebelumnya. Di samping itu, pada masa ini terdapat kekurangan penanda aras yang sesuai untuk menilai dan membandingkan model ini, yang mengehadkan pembangunan LLM multimodal.
 Gambar
Gambar
- Kertas: https://arxiv.org/abs/2307.02469
- Laman web: https://lynx-llm : //github.com/bytedance/lynx-llm
- Dalam artikel ini, penulis menjalankan kajian yang sistematik dan komprehensif tentang latihan model tersebut dari aspek kuantitatif dan kualitatif. Lebih daripada 20 varian telah disediakan Untuk struktur rangkaian, tulang belakang LLM yang berbeza dan reka bentuk model telah dibandingkan untuk data latihan, kesan data dan strategi pensampelan telah dikaji dari segi arahan, kesan gesaan yang pelbagai pada model Kebolehan mengikut arahan telah diterokai. Untuk penanda aras, artikel itu mencadangkan buat kali pertama Open-VQA, set penilaian menjawab soalan visual terbuka termasuk tugasan imej dan video.
Berdasarkan kesimpulan eksperimen, penulis mencadangkan Lynx, yang menunjukkan pemahaman multi-modal yang paling tepat sambil mengekalkan multi-modaliti terbaik berbanding model gaya GPT4 sumber terbuka yang sedia ada Keupayaan Generatif.
Skema penilaian
Berbeza daripada tugas bahasa visual biasa, cabaran utama dalam menilai model gaya GPT4 adalah untuk mengimbangi prestasi keupayaan penjanaan teks dan
pemahaman ketepatanmultimodal Untuk menyelesaikan masalah ini, penulis mencadangkan Open-VQA penanda aras baharu termasuk data video dan imej, dan menjalankan penilaian menyeluruh terhadap model sumber terbuka semasa. Secara khusus, dua skim penilaian kuantitatif diguna pakai:
Kumpul set ujian Menjawab Soalan Visual Terbuka (Open-VQA), yang mengandungi maklumat tentang objek, OCR, pengiraan, penaakulan, pengecaman masa dan tindakan. . dan lain-lain kategori soalan. Tidak seperti set data VQA yang mempunyai jawapan standard, jawapan Open-VQA adalah
open-ended- . Untuk menilai prestasi pada Open-VQA, GPT4 digunakan sebagai diskriminasi, dan hasilnya 95% konsisten dengan penilaian manusia. Selain itu, penulis menggunakan set data OwlEval yang disediakan oleh mPLUG-owl [1] untuk menilai keupayaan penjanaan teks model Walaupun ia hanya mengandungi 50 gambar dan 82 soalan, ia meliputi penjanaan cerita, penjanaan iklan, penjanaan kod, dsb. Pelbagai soalan, dan rekrut pengotor manusia untuk menjaringkan prestasi model yang berbeza.
- Kesimpulan
Untuk mengkaji strategi latihan LLM pelbagai mod secara mendalam, penulis terutamanya bermula dari struktur rangkaian (penalaan halus awalan/perhatian silang), data latihan (pemilihan data dan nisbah gabungan), arahan (arahan tunggal/ Lebih daripada dua puluh varian telah ditetapkan dalam pelbagai aspek seperti petunjuk terpelbagai), model LLM (LLaMA [5]/Vicuna [6]), piksel imej (420/224), dsb., dan kesimpulan utama berikut telah dibuat melalui eksperimen:
-
Arahan mengikut keupayaan LLM multimodal tidaklah sebaik LLM. Sebagai contoh, InstructBLIP [2] cenderung untuk menjana balasan pendek tanpa mengira arahan input, manakala model lain cenderung menjana ayat yang panjang tanpa mengira arahan, yang penulis percaya adalah disebabkan oleh kekurangan multi-kualiti tinggi dan pelbagai. modaliti yang disebabkan oleh data arahan.
-
Kualiti data latihan adalah penting untuk prestasi model. Berdasarkan hasil percubaan pada data yang berbeza, didapati bahawa menggunakan sejumlah kecil data berkualiti tinggi berprestasi lebih baik daripada menggunakan data bising berskala besar. Penulis percaya bahawa ini adalah perbezaan antara latihan generatif dan latihan kontrastif, kerana latihan generatif secara langsung mempelajari pengedaran bersyarat perkataan dan bukannya persamaan antara teks dan imej. Oleh itu, untuk prestasi model yang lebih baik, dua perkara perlu dipenuhi dari segi data: 1) mengandungi teks licin berkualiti tinggi 2) kandungan teks dan imej diselaraskan dengan baik.
-
Pencarian dan gesaan adalah penting untuk keupayaan sifar pukulan. Menggunakan pelbagai tugas dan arahan boleh meningkatkan keupayaan penjanaan sifar tangkapan model pada tugas yang tidak diketahui, yang konsisten dengan pemerhatian dalam model teks biasa.
-
Adalah penting untuk mengimbangi ketepatan dengan keupayaan penjanaan bahasa. Jika model kurang latihan dalam tugas hiliran (seperti VQA), ia lebih berkemungkinan menghasilkan kandungan rekaan yang tidak sepadan dengan input visual dan jika model terlalu terlatih pada tugasan hiliran, ia akan cenderung untuk menghasilkan jawapan pendek dan tidak akan dapat mengikuti arahan Pengguna menjana jawapan yang lebih panjang.
-
Penalaan awalan (PT) kini merupakan penyelesaian terbaik untuk penyesuaian pelbagai mod LLM. Dalam eksperimen, model dengan struktur penalaan awalan boleh meningkatkan keupayaan untuk mengikut arahan yang pelbagai dengan lebih pantas dan lebih mudah untuk dilatih berbanding struktur model dengan perhatian silang (CA). (penalaan awalan dan perhatian silang ialah dua struktur model, lihat bahagian pengenalan model Lynx untuk butiran)
Model Lynx
Pengarang mencadangkan Lynx (猞猁) -model gaya dengan penalaan awalan. Pada peringkat pertama, kira-kira 120M pasangan teks imej digunakan untuk menyelaraskan pembenaman visual dan bahasa pada peringkat kedua, 20 imej atau video digunakan untuk tugasan berbilang modal dan data pemprosesan bahasa semula jadi (NLP) untuk melaraskan model; keupayaan mengikut arahan.
 Gambar
Gambar
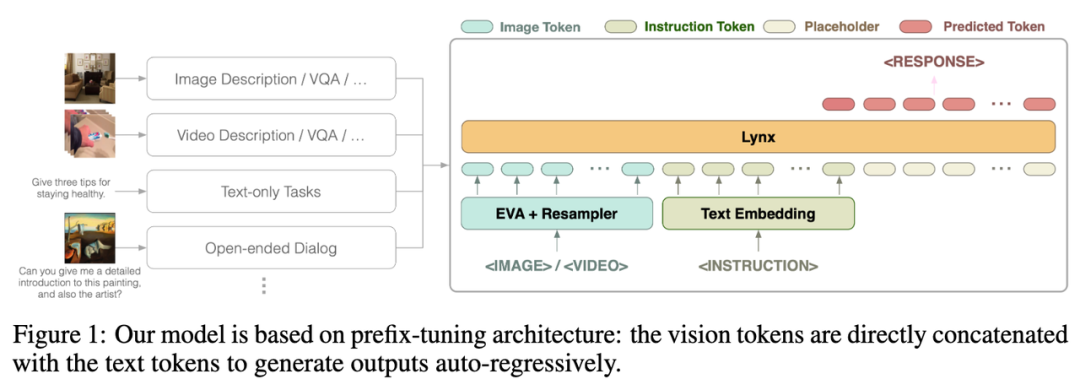
Struktur keseluruhan model Lynx ditunjukkan dalam Rajah 1 di atas.
Input visual diproses oleh pengekod visual untuk mendapatkan token visual (token) $$W_v$$ Selepas pemetaan, ia disambungkan dengan token arahan $$W_l$$ sebagai input LLM Ini struktur dipanggil dalam artikel ini Ia adalah "prefix-finetuning" untuk membezakannya daripada struktur cross-attention yang digunakan oleh Flamingo [3].
Selain itu, penulis mendapati bahawa kos latihan boleh dikurangkan lagi dengan menambah Adapter selepas lapisan tertentu LLM beku.
Kesan model
Pengarang menilai prestasi model LLM berbilang modal sumber terbuka sedia ada pada Penilaian manual Open-VQA, Mme [4] dan OwlEval (keputusan ditunjukkan dalam carta di bawah, dan penilaian butiran ada dalam kertas). Ia boleh dilihat bahawa model Lynx telah mencapai prestasi terbaik dalam tugas pemahaman imej dan video Open-VQA, penilaian manual OwlEval dan tugas Persepsi Mme. Antaranya, InstructBLIP juga mencapai prestasi tinggi dalam kebanyakan tugas, tetapi balasannya terlalu pendek Sebagai perbandingan, dalam kebanyakan kes, model Lynx memberikan alasan ringkas untuk menyokong jawapan berdasarkan memberikan jawapan yang betul. mesra (lihat bahagian paparan Kes di bawah untuk beberapa kes).
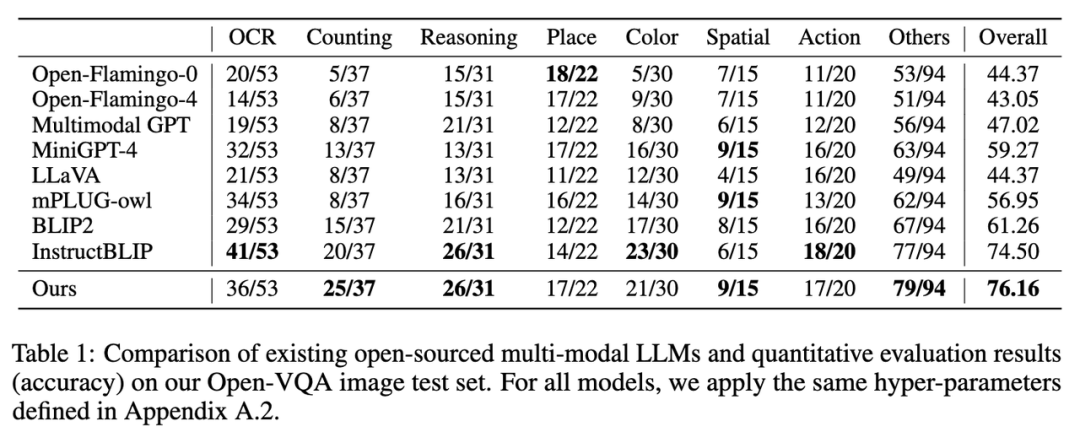
1. Keputusan penunjuk pada set ujian imej Open-VQA ditunjukkan dalam Jadual 1 di bawah:
 Gambar
Gambar
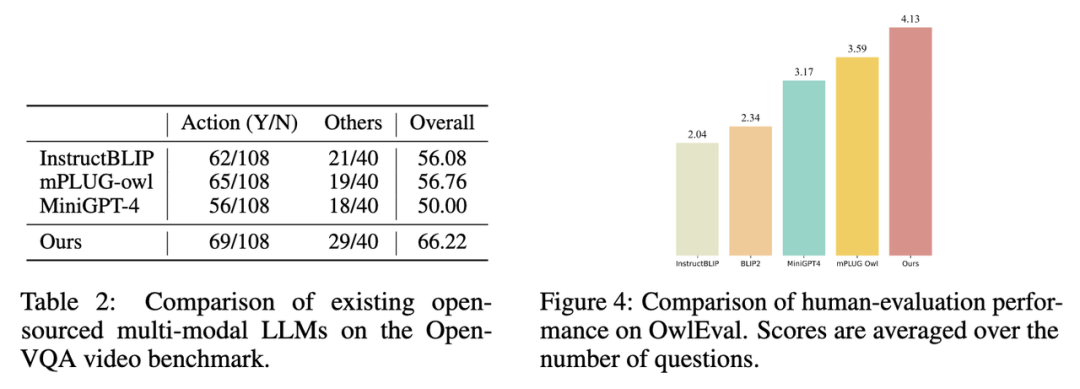
2 Keputusan penunjuk pada set ujian video Terbuka dalam Jadual 1 di bawah 2 ditunjukkan.
 gambar
gambar
3 Pilih model dengan skor tertinggi dalam Open-VQA untuk menjalankan penilaian kesan manual pada set penilaian OwlEval. Dapat dilihat daripada hasil penilaian manual bahawa model Lynx mempunyai prestasi penjanaan bahasa yang terbaik.
 Gambar
Gambar
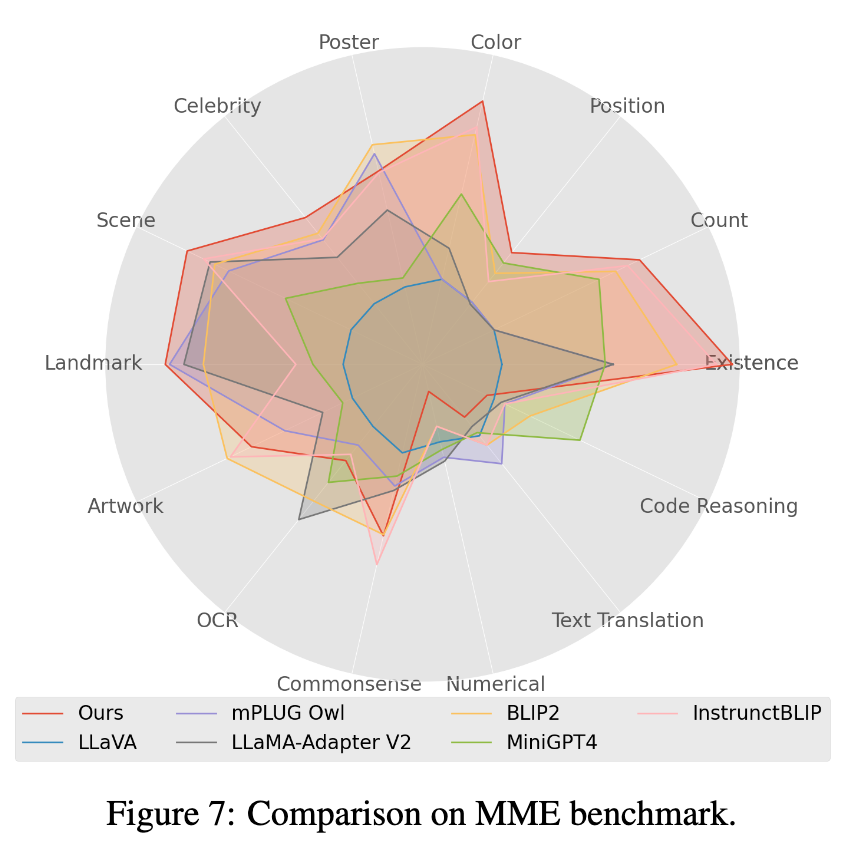
4. Dalam ujian penanda aras Mme, Tugas kelas persepsi mencapai prestasi terbaik, antaranya 7 daripada 14 subtugas kelas menunjukkan prestasi terbaik. (Lihat lampiran kertas untuk keputusan terperinci)
Kes menunjukkan
Kes gambar VQA terbuka



Kes video VQA terbuka
🎜 🎜🎜🎜🎜 🎜Ringkasan🎜🎜🎜🎜Dalam artikel ini, melalui eksperimen ke atas lebih daripada dua puluh varian LLM berbilang mod, penulis menentukan model Lynx dengan penalaan awalan sebagai struktur utama dan memberikan pelan penilaian Open-VQA dengan jawapan terbuka. Keputusan eksperimen menunjukkan bahawa model Lynx melakukan ketepatan pemahaman pelbagai mod yang paling tepat sambil mengekalkan keupayaan penjanaan pelbagai mod yang terbaik. 🎜🎜Atas ialah kandungan terperinci Pasukan Byte mencadangkan model Lynx: pemahaman LLM berbilang modal dan senarai penjanaan kognitif SoTA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI