
Rumah >Peranti teknologi >AI >Bakat visual model bahasa besar: GPT juga boleh menyelesaikan tugasan visual melalui pembelajaran kontekstual
Bakat visual model bahasa besar: GPT juga boleh menyelesaikan tugasan visual melalui pembelajaran kontekstual

- 王林ke hadapan
- 2023-07-14 15:37:061680semak imbas
Pada masa ini, model bahasa besar (LLM) telah mencetuskan gelombang perubahan dalam bidang pemprosesan bahasa semula jadi (NLP). Kami melihat bahawa LLM mempunyai keupayaan kemunculan yang kuat dan berprestasi baik pada tugas pemahaman bahasa yang kompleks, tugas penjanaan dan juga tugas penaakulan. Ini memberi inspirasi kepada orang ramai untuk meneroka lebih lanjut potensi LLM dalam subbidang pembelajaran mesin yang lain - penglihatan komputer (CV).
Salah satu bakat hebat LLM ialah keupayaan mereka untuk belajar mengikut konteks. Pembelajaran kontekstual tidak mengemas kini sebarang parameter LLM, tetapi ia menunjukkan hasil yang menakjubkan dalam pelbagai tugasan NLP. Jadi, bolehkah GPT menyelesaikan tugasan visual melalui pembelajaran kontekstual?
Baru-baru ini, penyelidik dari Google dan Carnegie Mellon University (CMU) bersama-sama menerbitkan kertas kerja yang menunjukkan bahawa selagi kita boleh menukar imej (atau modaliti bukan linguistik lain) kepada bahasa yang LLM boleh faham, Ini nampaknya boleh dilaksanakan. . Pengekod Auto Piramid Semantik). Pendekatan baharu ini membolehkan LLM melaksanakan tugas penjanaan imej tanpa sebarang kemas kini parameter. Ini juga merupakan kaedah pertama yang berjaya menggunakan pembelajaran kontekstual untuk membolehkan LLM menjana kandungan imej.
 Mari kita lihat dahulu hasil percubaan LLM dalam menjana kandungan imej melalui pembelajaran konteks.
Mari kita lihat dahulu hasil percubaan LLM dalam menjana kandungan imej melalui pembelajaran konteks.
Sebagai contoh, dengan menyediakan 50 imej tulisan tangan dalam konteks tertentu, kertas itu meminta PaLM 2 menjawab pertanyaan kompleks yang memerlukan penjanaan imej digital sebagai output:
Gambar
juga dalam konteks imej Hasilkan imej kehidupan sebenar yang realistik tanpa input:
gambar
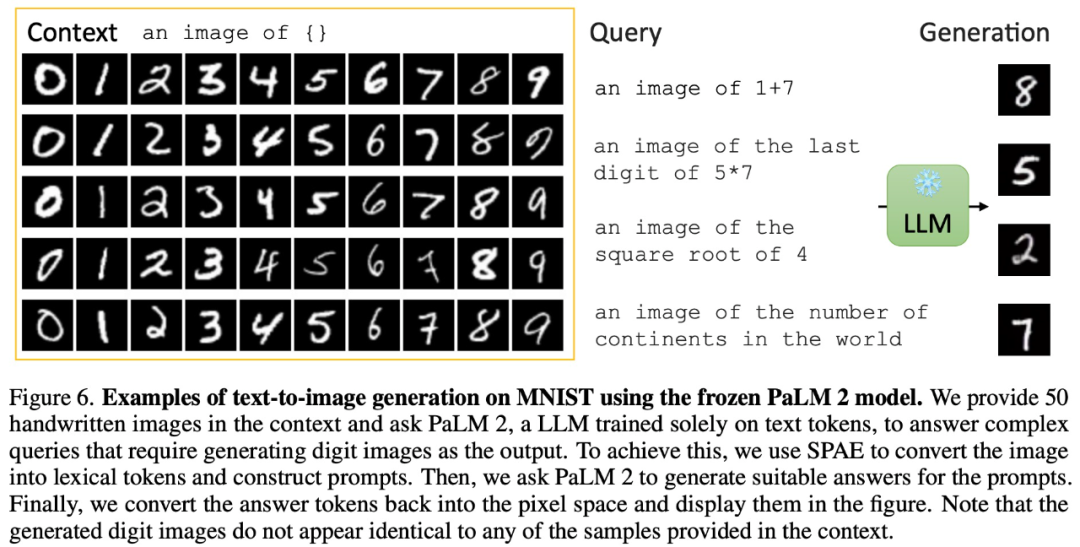 Selain menjana imej, melalui pembelajaran kontekstual, PaLM 2 juga boleh melaksanakan penerangan imej:
Selain menjana imej, melalui pembelajaran kontekstual, PaLM 2 juga boleh melaksanakan penerangan imej:
juga
 isu berkaitan Soal Jawab Visual:
isu berkaitan Soal Jawab Visual:
Gambar

Gambar
, menukar imej kepada bahasa yang LLM boleh faham adalah Masalah yang telah dikaji dalam kertas Transformer Visual (ViT). Dalam kertas kerja daripada Google dan CMU ini, mereka membawanya ke peringkat seterusnya — menggunakan perkataan sebenar untuk mewakili imej.
 Pendekatan ini seperti membina menara yang dipenuhi dengan teks, menangkap semantik dan butiran imej. Perwakilan penuh teks ini membolehkan penerangan imej dijana dengan mudah dan membolehkan LLM menjawab soalan berkaitan imej dan juga membina semula piksel imej.
Pendekatan ini seperti membina menara yang dipenuhi dengan teks, menangkap semantik dan butiran imej. Perwakilan penuh teks ini membolehkan penerangan imej dijana dengan mudah dan membolehkan LLM menjawab soalan berkaitan imej dan juga membina semula piksel imej.
Secara khusus, penyelidikan ini mencadangkan untuk menggunakan pengekod terlatih dan model CLIP untuk menukar imej menjadi ruang token, kemudian gunakan LLM untuk menjana token leksikal yang sesuai dan akhirnya menggunakan penyahkod terlatih untuk menukar token ini; ditukar kembali kepada ruang piksel. Proses pintar ini menukar imej kepada bahasa yang LLM boleh faham, membolehkan kami mengeksploitasi kuasa penjanaan LLM dalam tugas penglihatan.
Eksperimen dan keputusan
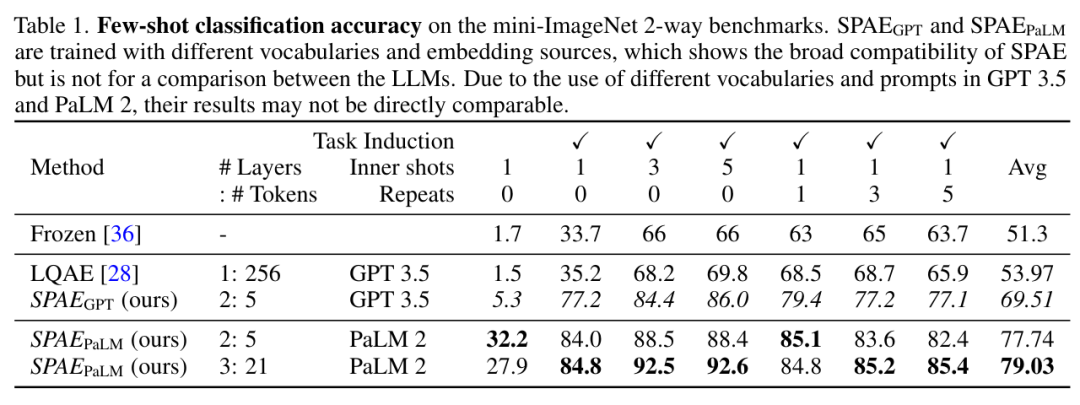
Kajian ini secara eksperimen membandingkan SPAE dengan kaedah SOTA Frozen dan LQAE, dan hasilnya ditunjukkan dalam Jadual 1 di bawah. SPAEGPT mengatasi LQAE pada semua tugas sambil menggunakan hanya 2% daripada token.
 Image
Image
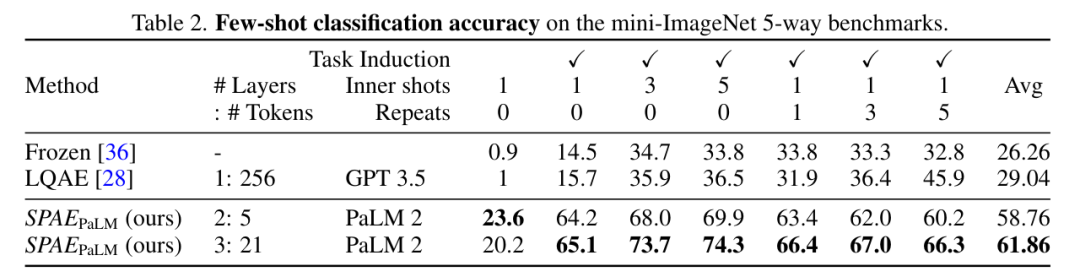
Secara keseluruhannya, ujian pada penanda aras mini-ImageNet menunjukkan bahawa kaedah SPAE meningkatkan prestasi sebanyak 25% berbanding kaedah SOTA sebelumnya.
 Gambar
Gambar
Untuk mengesahkan keberkesanan kaedah reka bentuk SPAE, kajian ini telah menjalankan eksperimen ablasi. Keputusan eksperimen ditunjukkan dalam Jadual 4 dan Rajah 10 di bawah:
Gambar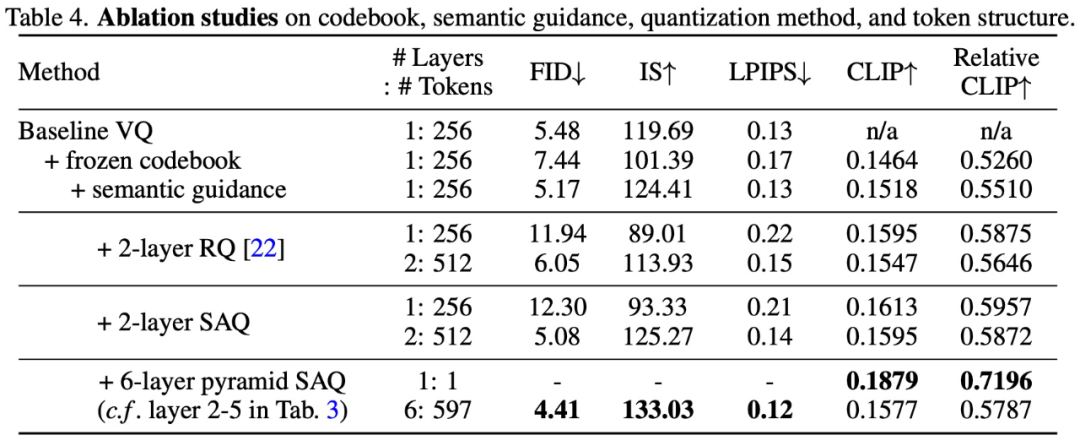

Atas ialah kandungan terperinci Bakat visual model bahasa besar: GPT juga boleh menyelesaikan tugasan visual melalui pembelajaran kontekstual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI