
Rumah >Peranti teknologi >AI >Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan
Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-07-13 22:01:051398semak imbas
Untuk memproses data, alat AI yang satu ini sudah memadai!
Bergantung pada model bahasa besar (LLM) di belakangnya, anda hanya perlu menghuraikandata yang ingin anda lihat dalam satu ayat, dan serahkan yang lain!
Pemprosesan, analisis, dan juga visualisasi semuanya boleh dilakukan dengan mudah, Anda tidak perlu membuat koleksi sendiri.
 Pictures
Pictures
Pembantu data AI berasaskan LLM ini dipanggil Data-Copilot dan dibangunkan oleh pasukan Universiti Zhejiang.
Pracetak kertas berkaitan telah dikeluarkan.
Kandungan berikut disediakan oleh penyumbang
Pelbagai industri seperti kewangan, meteorologi dan tenaga menjana sejumlah besar data heterogen setiap hari. Terdapat keperluan mendesak untuk alat untuk mengurus, memproses dan memaparkan data ini dengan berkesan.
DataCopilot mengurus dan memproses data besar-besaran secara autonomi dengan menggunakan model bahasa yang besar untuk memenuhi pelbagai pertanyaan pengguna, pengiraan, ramalan, visualisasi dan keperluan lain.
Anda hanya perlu memasukkan teks untuk memberitahu DataCopilot data yang anda ingin lihat, tanpa operasi yang membosankan, Tidak perlu menulis kod anda sendiri, DataCopilot menukar data asal secara autonomi kepada hasil visualisasi yang paling sesuai dengan hasrat pengguna.
Untuk mencapai rangka kerja universal yang meliputi pelbagai bentuk tugas berkaitan data, pasukan penyelidik mencadangkan Data-Copilot.
Model ini menyelesaikan masalah risiko kebocoran data, kuasa pengkomputeran yang lemah dan ketidakupayaan untuk mengendalikan tugas rumit yang disebabkan oleh hanya menggunakan LLM.
 Gambar
Gambar
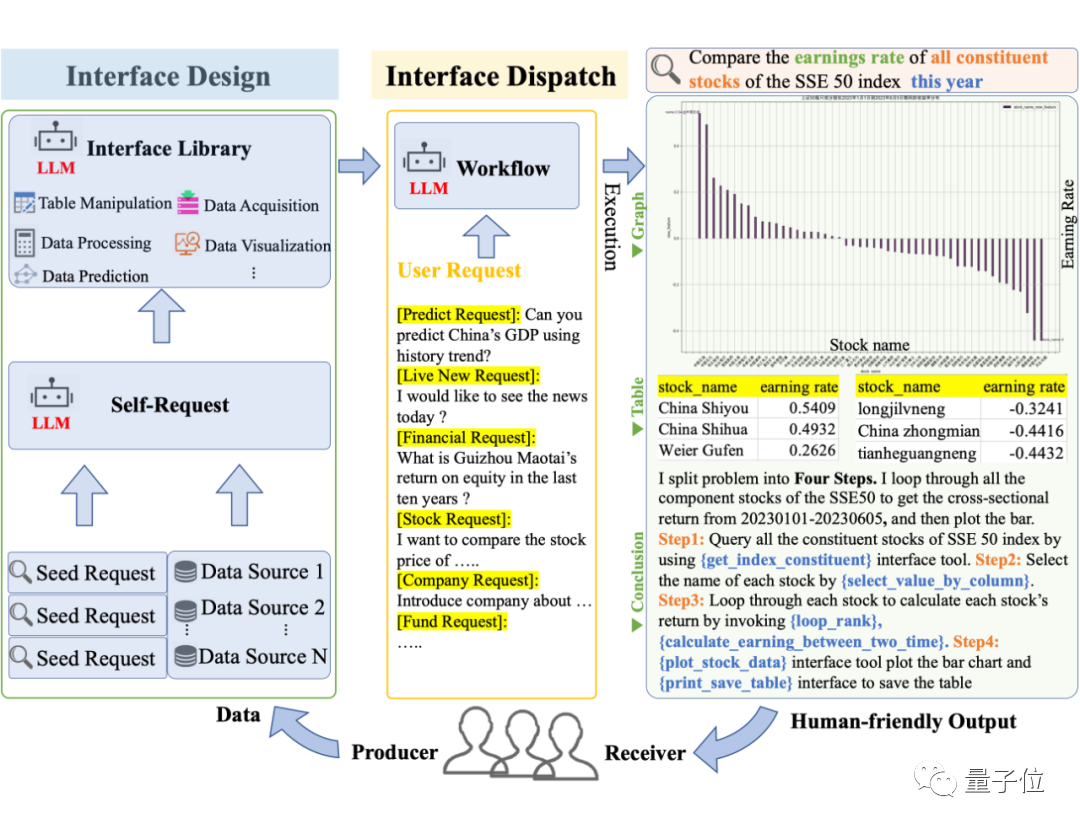
Apabila menerima permintaan yang kompleks, Data-Copilot akan mereka bentuk dan menjadualkansecara bebas antara muka bebas untuk membina aliran kerja bagi memenuhi hasrat pengguna.
Tanpa bantuan manusia, ia boleh dengan mahir mengubah data mentah daripada sumber yang berbeza dan dalam format yang berbeza kepada output yang dimanusiakan seperti grafik, jadual dan teks.
 Gambar
Gambar
Sumbangan utama projek Data-Copilot termasuk:
- Menghubungkan sumber data dalam pelbagai bidang dan keperluan pengguna yang pelbagai, mengurangkan tenaga kerja yang membosankan dan pengetahuan profesional.
- Mencapai pengurusan autonomi, pemprosesan, analisis, ramalan dan visualisasi data, dan boleh mengubah data mentah kepada hasil bermaklumat yang paling sesuai dengan niat pengguna.
- Alat mempunyai dwi identiti pereka dan penjadual, termasuk dua proses: proses reka bentuk alat antara muka (pereka bentuk) dan proses penjadualan (penjadual).
- Data-Copilot Demo dibina berdasarkan data pasaran kewangan China.
Reka bentuk dan laksanakan aliran kerja secara bebas
Anda juga boleh mengambil contoh berikut untuk melihat prestasi Data-Copilot:
Apakah kadar pertumbuhan tahun ke tahun keuntungan bersih semua saham konstituen Shanghai Stock Exchange 50 Index pada suku pertama tahun ini
Data-Copilot Kami mereka bentuk aliran kerja sedemikian secara bebas:
 Pictures
Pictures
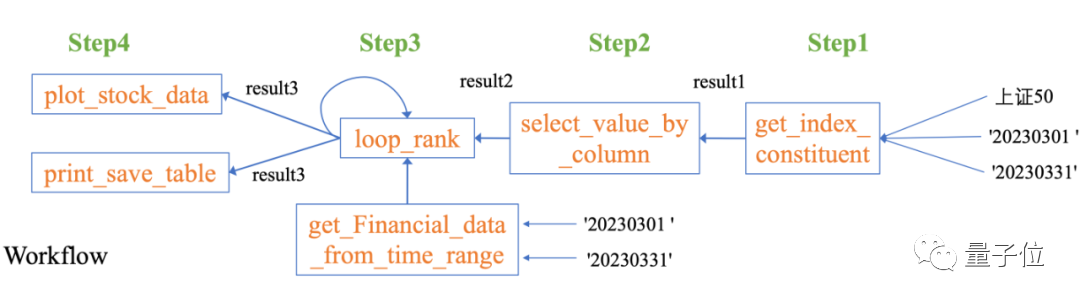
Untuk menangani masalah kompleks ini, Data-Copilot menggunakan antara muka loop_rank untuk melaksanakan pertanyaan gelung berbilang .
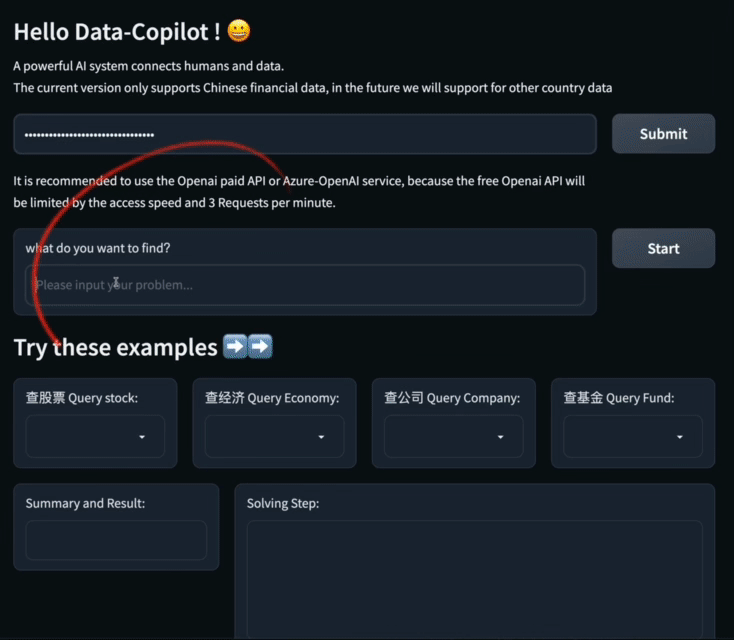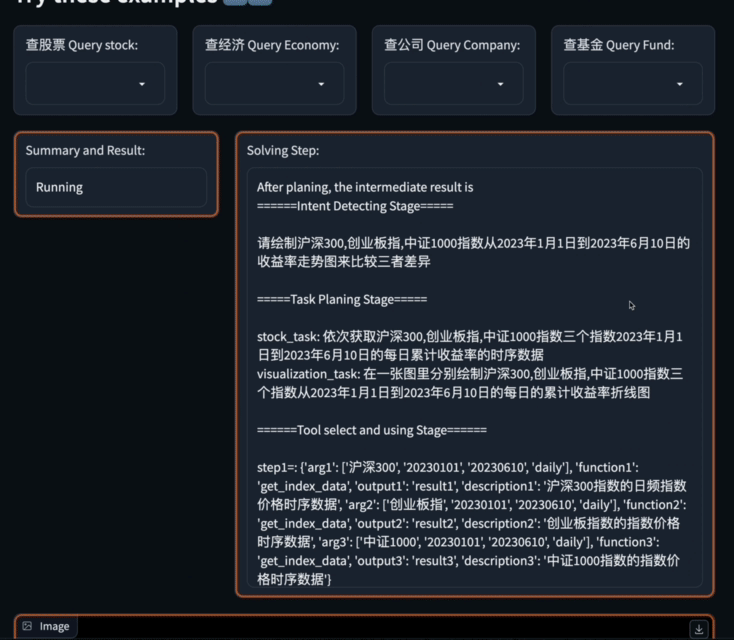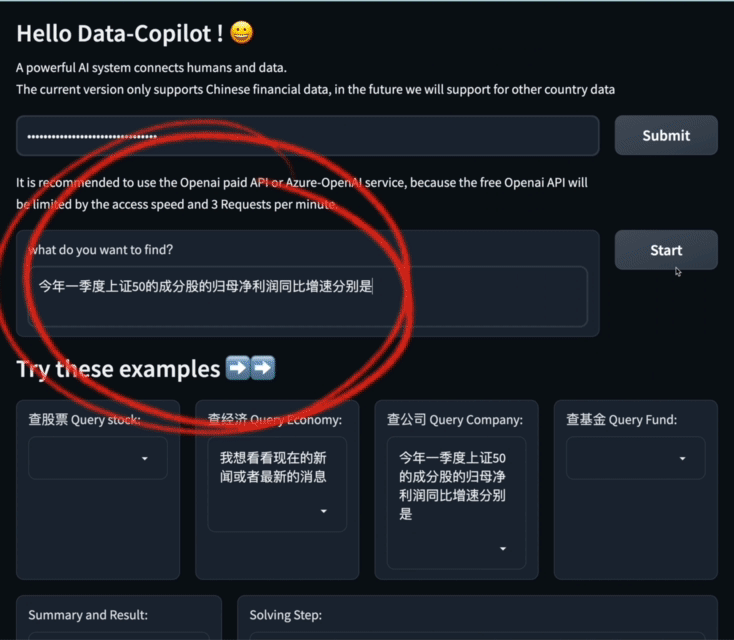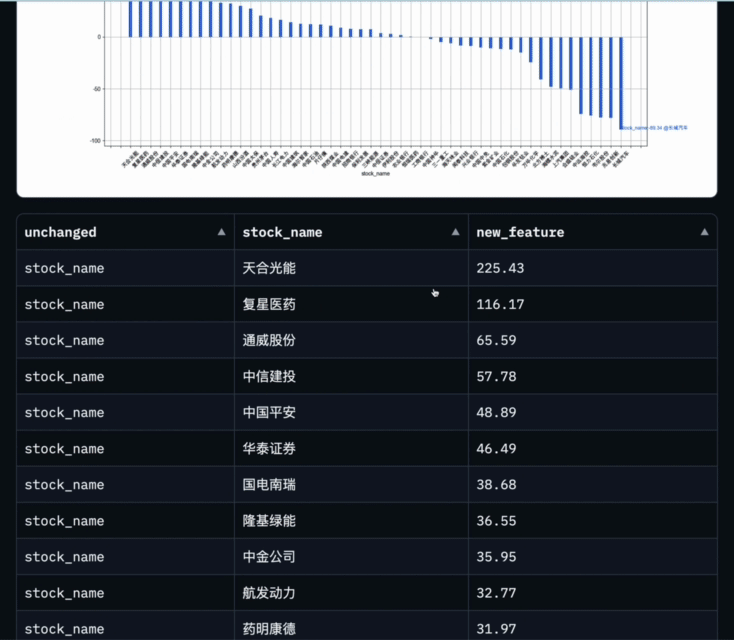
Data-Copilot mendapat keputusan ini selepas melaksanakan aliran kerja ini:
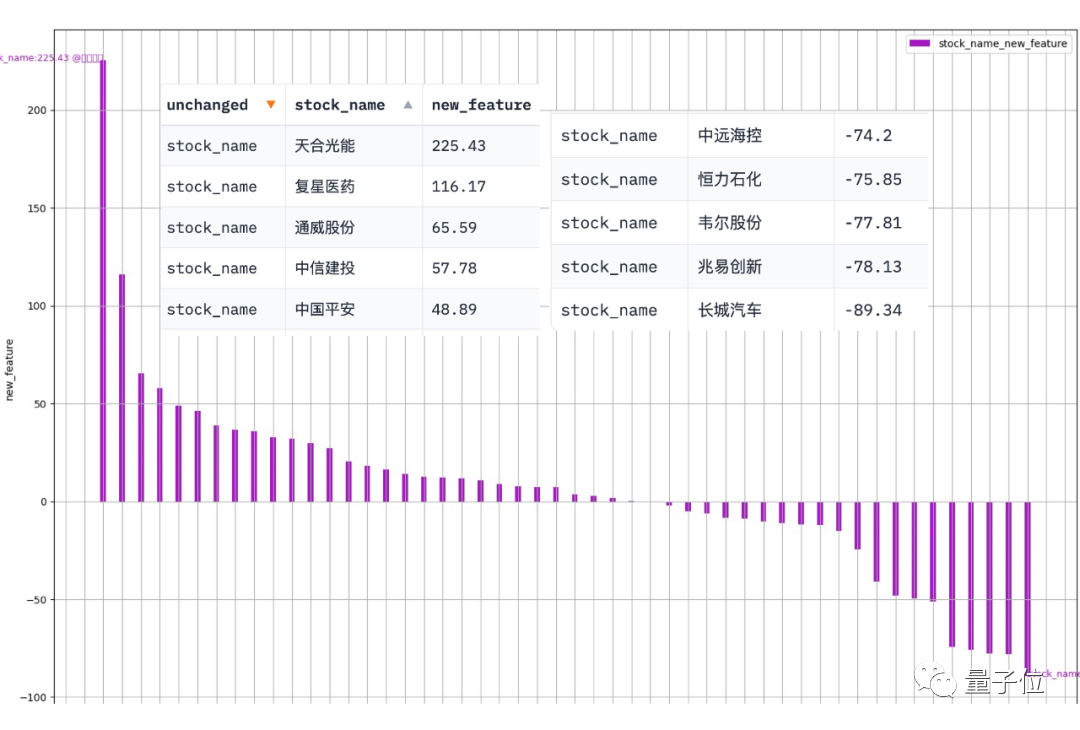
Abcissa ialah nama setiap stok komponen, dan ordinat ialah kadar pertumbuhan tahun ke tahun untung bersih pada suku pertama
 Gambar
Gambar
Sebagai tambahan kepada umum Selain proses pemprosesan data, Data-Copilot juga boleh menjana pelbagai jenis aliran kerja.
Pasukan penyelidik menguji Data-Copilot dalam dua mod aliran kerja: ramalan dan selari.
Meramalkan aliran kerja
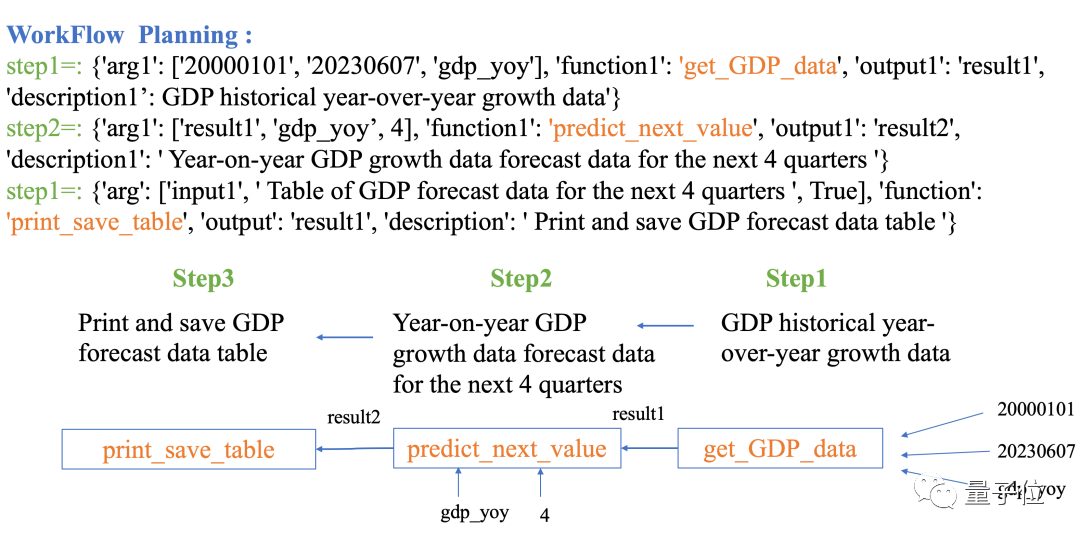
Data-Copilot juga boleh meramalkan bahagian selain daripada data yang diketahui Contohnya, masukkan soalan berikut:
Ramalkan KDNK suku tahunan China dalam empat suku berikut
Data-Copilot menggunakan sejarah Aliran Kerja
ini:Data KDNK → Gunakan model regresi linear untuk meramal masa depan → Jadual output
 gambar
gambar
Keputusan selepas pelaksanaan adalah seperti berikut:
. Hasilkan carta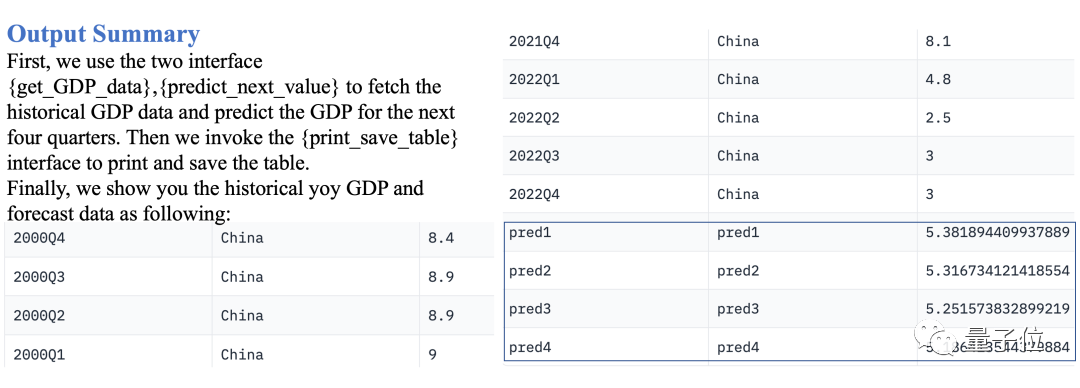 Gambar
Gambar
Kaedah umum Dopi-Main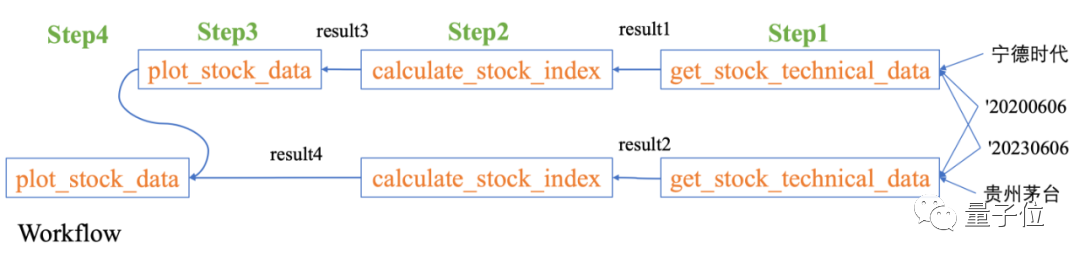 sistem model bahasa besar dengan reka bentuk antara muka dan Terdapat dua peringkat utama penjadualan antara muka.
sistem model bahasa besar dengan reka bentuk antara muka dan Terdapat dua peringkat utama penjadualan antara muka.
Reka bentuk antara muka: Pasukan penyelidik mereka bentuk proses permintaan sendiri untuk membolehkan LLM menjana permintaan yang mencukupi secara autonomi daripada sebilangan kecil permintaan benih. Kemudian, LLM secara berulang mereka bentuk dan mengoptimumkan antara muka berdasarkan permintaan yang dijana. Antara muka ini diterangkan menggunakan bahasa semula jadi, menjadikannya mudah untuk dilanjutkan dan dipindahkan antara platform yang berbeza.
Penjadualan antara muka: Selepas menerima permintaan pengguna, LLM merancang dan memanggil alat antara muka berdasarkan penerangan antara muka rekaan sendiri dan dalam demonstrasi konteks, menggunakan aliran kerja yang memenuhi keperluan pengguna dan membentangkan hasil kepada pengguna dalam pelbagai bentuk. 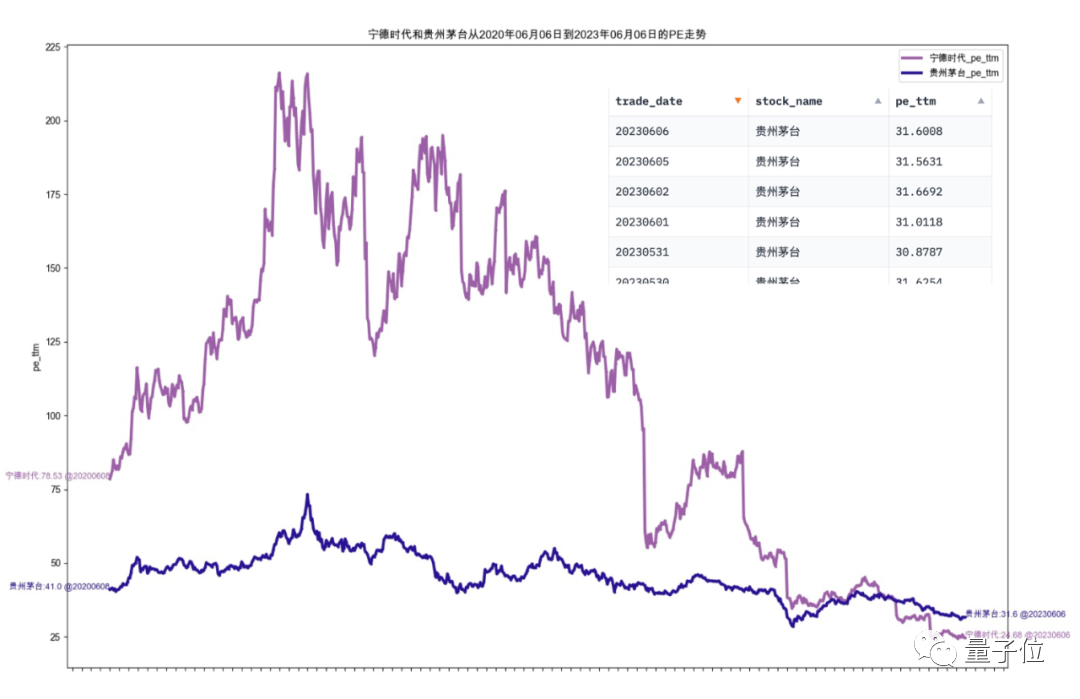 Data-Copilot mencapai pemprosesan dan visualisasi data yang sangat automatik dengan menjana permintaan secara automatik dan mereka bentuk antara muka secara bebas untuk memenuhi keperluan pengguna dan memaparkan hasil kepada pengguna dalam pelbagai bentuk.
Data-Copilot mencapai pemprosesan dan visualisasi data yang sangat automatik dengan menjana permintaan secara automatik dan mereka bentuk antara muka secara bebas untuk memenuhi keperluan pengguna dan memaparkan hasil kepada pengguna dalam pelbagai bentuk.
Gambar
- Reka bentuk antara muka
- Seperti yang ditunjukkan dalam gambar di atas, pengurusan data mesti dilaksanakan terlebih dahulu, dan langkah pertama memerlukan alat antara muka.
Pertama sekali, LLM menggunakan sebilangan kecil permintaan benih dan secara bebas menjana sejumlah besar permintaan (meneroka data mengikut permintaan diri) untuk merangkumi pelbagai senario aplikasi sebanyak mungkin.  Kemudian, LLM mereka bentuk antara muka yang sepadan untuk permintaan ini (takrifan antara muka: hanya termasuk perihalan dan parameter), dan secara beransur-ansur mengoptimumkan reka bentuk antara muka (gabungan antara muka) dalam setiap lelaran.
Kemudian, LLM mereka bentuk antara muka yang sepadan untuk permintaan ini (takrifan antara muka: hanya termasuk perihalan dan parameter), dan secara beransur-ansur mengoptimumkan reka bentuk antara muka (gabungan antara muka) dalam setiap lelaran.
Seperti yang ditunjukkan di bawah: Alat antara muka Data-Copilot yang direka bentuk sendiri untuk pemprosesan data
- gambar
- Penjadualan antara muka
- Pada peringkat sebelumnya, penyelidik memperoleh pelbagai alatan untuk pemerolehan data dan alat pemprosesan antara muka. Setiap antara muka mempunyai penerangan fungsi yang jelas dan eksplisit. Seperti yang ditunjukkan dalam rajah di atas untuk dua pertanyaan, Data-Copilot membentuk aliran kerja daripada data untuk menghasilkan berbilang bentuk melalui perancangan dan panggilan antara muka yang berbeza dalam permintaan masa nyata.
Data-Copilot terlebih dahulu melakukan analisis niat untuk memahami permintaan pengguna dengan tepat.
Setelah niat pengguna difahami dengan tepat, Data-Copilot akan merancang aliran kerja yang munasabah untuk mengendalikan permintaan pengguna. Data-Copilot akan menjana JSON format tetap yang mewakili setiap langkah penjadualan, seperti step={“arg”:””, “function”:””, “output”:””,”description”:””} .  Berpandukan penerangan dan contoh antara muka, Data-Copilot mengatur penjadualan antara muka dalam setiap langkah, sama ada secara berurutan atau selari.
Berpandukan penerangan dan contoh antara muka, Data-Copilot mengatur penjadualan antara muka dalam setiap langkah, sama ada secara berurutan atau selari.
Data-Copilot dengan ketara mengurangkan pergantungan pada tenaga kerja dan kepakaran yang membosankan dengan menyepadukan LLM ke dalam setiap peringkat tugas berkaitan data, secara automatik mengubah data mentah kepada hasil visualisasi mesra pengguna berdasarkan permintaan pengguna.
Halaman projek GitHub: https://github.com/zwq2018/Data-Copilot- Alamat kertas: https://arxiv.org/abs/2306.07209
.co/spaces/zwq2018/Data-Copilot
Atas ialah kandungan terperinci Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI