
Rumah >Peranti teknologi >AI >Panjangkan panjang konteks kepada 256k, adakah versi konteks tanpa had LongLLaMA akan datang?
Panjangkan panjang konteks kepada 256k, adakah versi konteks tanpa had LongLLaMA akan datang?

- PHPzke hadapan
- 2023-07-11 15:05:441352semak imbas
Pada Februari tahun ini, Meta mengeluarkan siri model bahasa berskala besar LLaMA, yang berjaya mempromosikan pembangunan robot sembang sumber terbuka. Oleh kerana LLaMA mempunyai parameter yang lebih sedikit daripada kebanyakan model besar yang dikeluarkan sebelum ini (bilangan parameter berjulat dari 7 bilion hingga 65 bilion), tetapi mempunyai prestasi yang lebih baik Contohnya, model LLaMA terbesar dengan 65 bilion parameter adalah setanding dengan Chinchilla-70B dan PaLM Google. -540B , begitu ramai penyelidik teruja sebaik sahaja ia dikeluarkan.
Walau bagaimanapun, LLaMA hanya dilesenkan untuk digunakan oleh penyelidik akademik, sekali gus mengehadkan aplikasi komersial model tersebut.
Oleh itu, penyelidik mula mencari LLaMA yang boleh digunakan untuk tujuan komersil Projek OpenLLaMA yang dimulakan oleh Hao Liu, seorang pelajar kedoktoran di UC Berkeley, adalah salah satu salinan sumber terbuka LLaMA yang lebih popular, yang menggunakan. LLaMA yang sama persis dengan LLaMA asal Untuk prapemprosesan dan hiperparameter latihan, boleh dikatakan OpenLLaMA mengikut sepenuhnya langkah latihan LLaMA. Paling penting, model itu boleh didapati secara komersial.
OpenLLaMA dilatih pada set data RedPajama yang dikeluarkan oleh Together Company Terdapat tiga versi model, iaitu 3B, 7B dan 13B. Keputusan menunjukkan bahawa prestasi OpenLLaMA adalah setanding atau bahkan melebihi prestasi LLaMA asal dalam pelbagai tugas.
Selain sentiasa mengeluarkan model baharu, penyelidik sentiasa meneroka keupayaan model untuk mengendalikan token.
Beberapa hari lalu, penyelidikan terbaharu oleh pasukan Tian Yuandong memanjangkan konteks LLaMA kepada 32K dengan kurang daripada 1000 langkah penalaan halus. Berbalik lebih jauh, GPT-4 menyokong 32k token (yang bersamaan dengan 50 halaman teks), Claude boleh mengendalikan 100k token (kira-kira bersamaan dengan meringkaskan bahagian pertama "Harry Potter" dalam satu klik) dan seterusnya.
Kini, model bahasa berskala besar baharu berdasarkan OpenLLaMA akan datang, yang memanjangkan panjang konteks kepada 256k token dan lebih banyak lagi. Penyelidikan ini telah disiapkan bersama oleh IDEAS NCBR, Akademi Sains Poland, Universiti Warsaw dan Google DeepMind.
 Pictures
Pictures
LongLLaMA adalah berdasarkan OpenLLaMA, dan kaedah penalaan halus menggunakan FOT (Focused Transformer). Makalah ini menunjukkan bahawa FOT boleh digunakan untuk memperhalusi model besar yang sedia ada untuk memanjangkan panjang konteksnya.
Kajian menggunakan model OpenLLaMA-3B dan OpenLLaMA-7B sebagai titik permulaan dan memperhalusinya menggunakan FOT. Model yang terhasil, yang dipanggil LONGLLAMA, dapat mengekstrapolasi melebihi tempoh konteks latihan mereka (malah sehingga 256K) dan mengekalkan prestasi pada tugas konteks pendek.
- Alamat projek: https://github.com/CStanKonrad/long_llama
- Alamat kertas: https://arxiv.org/pdf/2307.03170.pdf Seperti yang diterangkan oleh penyelidikan ini
Some versi konteks tanpa had OpenLLaMA, dengan FOT, model boleh diekstrapolasi dengan mudah kepada urutan yang lebih panjang Contohnya, model yang dilatih pada token 8K boleh diekstrapolasi dengan mudah kepada saiz tetingkap 256K.
 Gambar
Gambar
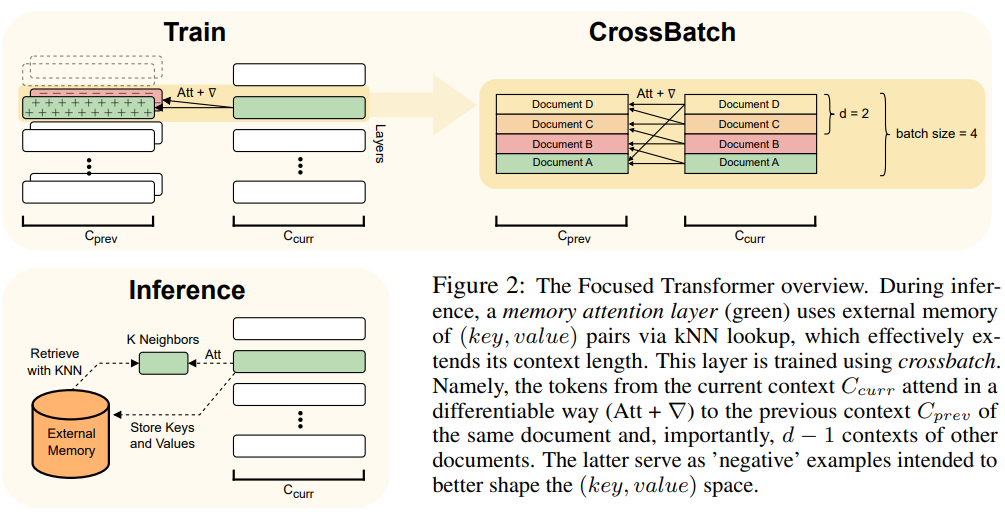
Artikel ini menggunakan kaedah FOT, yang merupakan sambungan plug-and-play model Transformer dan boleh digunakan untuk melatih model baharu atau memperhalusi model yang lebih besar sedia ada dengan konteks yang lebih panjang .
Untuk mencapai matlamat ini, FOT menggunakan lapisan perhatian memori dan proses latihan merentas kelompok:
- Lapisan perhatian memori membolehkan model mendapatkan maklumat daripada memori luaran pada masa inferens, dengan itu meluaskan konteks secara Berkesan;
- Proses latihan silang kelompok menjadikan model cenderung untuk mempelajari perwakilan (kunci, nilai) yang sangat mudah digunakan untuk menghafal lapisan perhatian.
Untuk gambaran keseluruhan seni bina FOT, lihat Rajah 2:
 Gambar
Gambar
Jadual berikut menunjukkan beberapa maklumat model untuk LongLLaMA:
 Pictures
Pictures
Gambar di bawah menunjukkan beberapa keputusan percubaan LongLLaMA Mengenai tugas mendapatkan kata laluan, LongLLaMA mencapai prestasi yang baik. Khususnya, model LongLLaMA 3B jauh melebihi panjang konteks latihannya iaitu 8K, mencapai ketepatan 94.5% untuk 100k token dan 73% ketepatan untuk 256k token. Jadual berikut menunjukkan keputusan model LongLLaMA 3B pada dua tugasan hiliran (klasifikasi soalan TREC dan menjawab soalan WebQS Keputusan menunjukkan prestasi LongLLaMA meningkat dengan ketara apabila menggunakan konteks yang panjang. Jadual di bawah menunjukkan cara LongLLaMA berprestasi baik walaupun pada tugasan yang tidak memerlukan konteks yang panjang. Percubaan membandingkan LongLLaMA dan OpenLLaMA dalam tetapan sampel sifar. Untuk butiran lanjut, sila rujuk kertas dan projek asal. 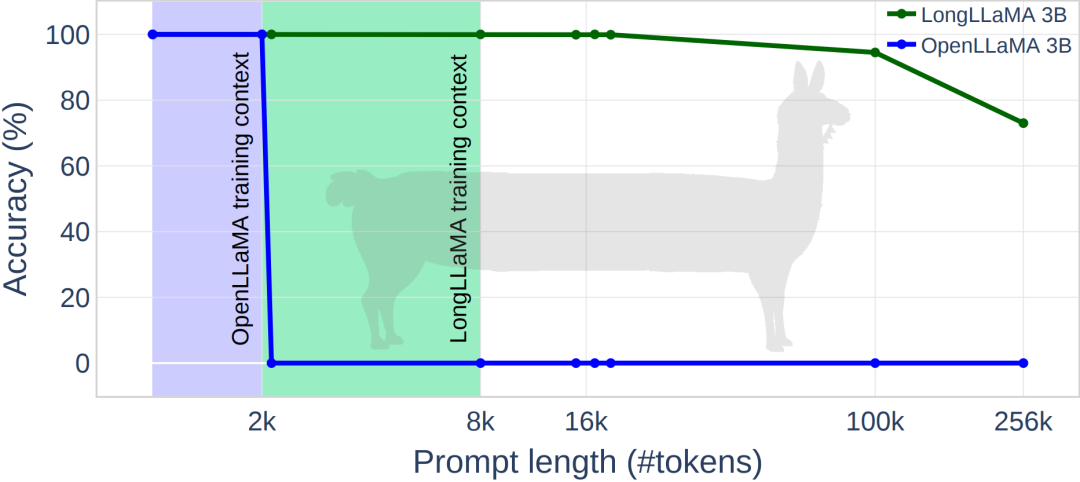 Pictures
Pictures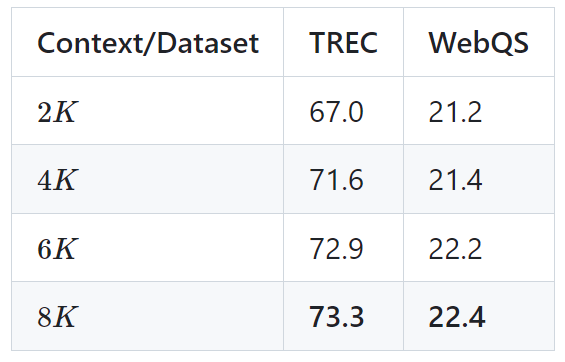 Imej
Imej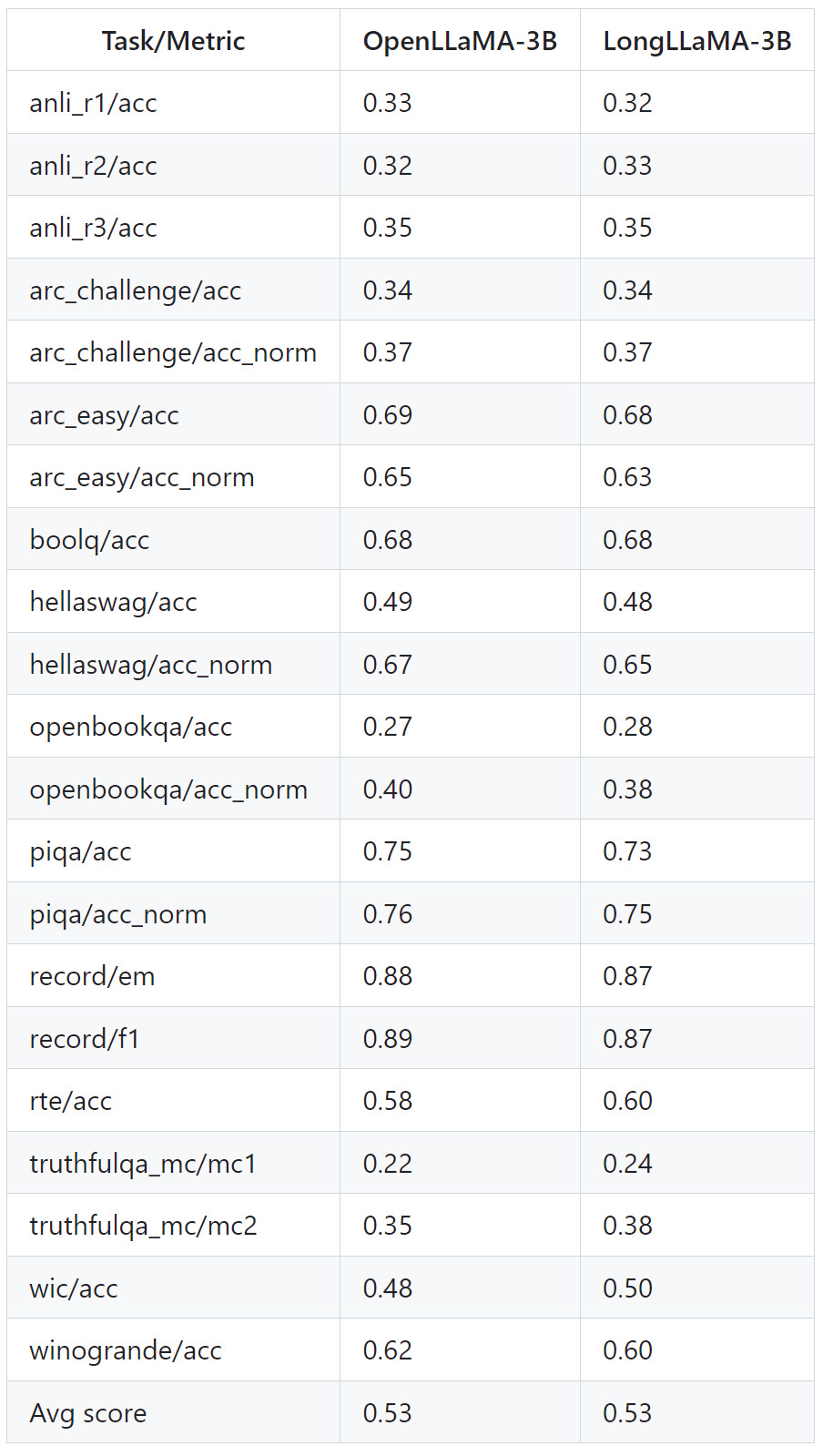 Gambar
Gambar
Atas ialah kandungan terperinci Panjangkan panjang konteks kepada 256k, adakah versi konteks tanpa had LongLLaMA akan datang?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI