
Rumah >Peranti teknologi >AI >Gambar dalam otak anda kini boleh dipulihkan dalam definisi tinggi
Gambar dalam otak anda kini boleh dipulihkan dalam definisi tinggi

- 王林ke hadapan
- 2023-07-06 19:17:231247semak imbas
Dalam beberapa tahun kebelakangan ini, kemajuan besar telah dicapai dalam bidang penjanaan imej, terutamanya dalam penjanaan teks ke imej: selagi kita menggunakan teks untuk menerangkan pemikiran kita, AI boleh menjana imej novel dan realistik.
Tetapi sebenarnya kita boleh melangkah lebih jauh - langkah menukar idea dalam minda kepada teks boleh ditinggalkan, dan penciptaan imej boleh dikawal terus melalui aktiviti otak (seperti rakaman EEG (electroencephalogram).
Kaedah penjanaan "thinking to image" ini mempunyai prospek aplikasi yang luas. Sebagai contoh, ia boleh meningkatkan kecekapan penciptaan artistik dan membantu orang menangkap ilham sekejap; ia juga mungkin untuk memvisualisasikan impian orang pada waktu malam, malah boleh digunakan dalam psikoterapi untuk membantu kanak-kanak autistik dan pesakit gangguan bahasa.
Baru-baru ini, penyelidik dari Tsinghua University Shenzhen International Graduate School, Tencent AI Lab dan Pengcheng Laboratory bersama-sama menerbitkan kertas penyelidikan tentang "Thinking to Image", menggunakan model teks-ke-imej yang telah terlatih (seperti Stable Diffusion)' keupayaan penjanaan berkuasa menjana imej berkualiti tinggi terus daripada isyarat EEG.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/pdf/2306.16934.pdf
Alamat projek: https://github. Gambaran keseluruhan kaedah
Beberapa penyelidikan berkaitan terkini (seperti MinD-Vis) cuba membina semula maklumat visual berdasarkan fMRI (isyarat pengimejan resonans magnetik berfungsi). Mereka telah menunjukkan kebolehlaksanaan menggunakan aktiviti otak untuk membina semula hasil yang berkualiti tinggi. Walau bagaimanapun, kaedah ini masih jauh daripada penggunaan isyarat otak yang ideal untuk penciptaan yang pantas dan cekap Ini terutamanya disebabkan oleh dua sebab:
Pertama, peralatan fMRI tidak mudah alih dan memerlukan profesional untuk beroperasi, jadi menangkap isyarat fMRI Sangat. sukar;
Kedua, kos pengumpulan data fMRI adalah tinggi, yang akan sangat menghalang penggunaan kaedah ini dalam penciptaan seni sebenar.
Sebaliknya, EEG ialah kaedah bukan invasif, kos rendah untuk merekod aktiviti elektrik otak, dan kini terdapat produk komersial mudah alih di pasaran yang boleh mendapatkan isyarat EEG.
Tetapi masih terdapat dua cabaran utama dalam mencapai penjanaan "thought-to-image":
1) Isyarat EEG ditangkap melalui kaedah bukan invasif, jadi ia sememangnya bising. Di samping itu, data EEG adalah terhad dan perbezaan individu tidak boleh diabaikan. Jadi, bagaimana untuk mendapatkan perwakilan semantik yang berkesan dan mantap daripada isyarat EEG di bawah banyak kekangan?
2) Ruang teks dan imej dalam Resapan Stabil dijajarkan dengan baik kerana menggunakan CLIP dan latihan pada sebilangan besar pasangan imej teks. Walau bagaimanapun, isyarat EEG mempunyai ciri tersendiri dan ruangnya agak berbeza daripada teks dan imej. Bagaimana untuk menyelaraskan EEG, teks dan ruang imej pada EEG terhad dan bising - pasangan imej?
Untuk menangani cabaran pertama, kajian ini mencadangkan untuk menggunakan sejumlah besar data EEG untuk melatih perwakilan EEG dan bukannya pasangan imej EEG yang jarang berlaku. Kajian ini menggunakan kaedah pemodelan isyarat bertopeng untuk meramalkan token yang hilang berdasarkan petunjuk kontekstual.
Tidak seperti MAE dan MinD-Vis, yang menganggap input sebagai imej dua dimensi dan menutup maklumat spatial, kajian ini mempertimbangkan ciri temporal isyarat EEG dan mendalami semantik di sebalik perubahan temporal dalam otak manusia. . Kajian ini menyekat sebahagian token secara rawak dan kemudian membina semula token yang disekat ini dalam domain masa. Dengan cara ini, pengekod pra-latihan dapat membangunkan pemahaman mendalam tentang data EEG daripada individu yang berbeza dan aktiviti otak yang berbeza.
Untuk cabaran kedua, penyelesaian sebelumnya biasanya memperhalusi model Stable Diffusion secara langsung, menggunakan sebilangan kecil pasangan data yang bising untuk latihan. Walau bagaimanapun, sukar untuk mempelajari penjajaran tepat antara isyarat otak (cth., EEG dan fMRI) dan ruang teks dengan hanya memperhalusi SD hujung ke hujung dengan kehilangan pembinaan semula imej akhir. Oleh itu, pasukan penyelidik mencadangkan penggunaan penyeliaan CLIP tambahan untuk membantu mencapai penjajaran ruang EEG, teks dan imej.
Secara khusus, SD sendiri menggunakan pengekod teks CLIP untuk menjana pembenaman teks, yang sangat berbeza daripada pembenaman EEG pra-latihan bertopeng pada peringkat sebelumnya. Manfaatkan pengekod imej CLIP untuk mengekstrak benam imej kaya yang sejajar dengan pembenaman teks CLIP. Pembenaman imej CLIP ini kemudiannya digunakan untuk memperhalusi lagi perwakilan pembenaman EEG. Oleh itu, benam ciri EEG yang dipertingkatkan boleh diselaraskan dengan baik dengan imej CLIP dan benam teks dan lebih sesuai untuk penjanaan imej SD, sekali gus meningkatkan kualiti imej yang dijana.
Berdasarkan dua penyelesaian yang direka dengan teliti di atas, penyelidikan ini mencadangkan kaedah baharu DreamDiffusion. DreamDiffusion menjana imej berkualiti tinggi dan realistik daripada isyarat electroencephalogram (EEG).
 Pictures
Pictures
specifically, DreamDiffusion terutamanya terdiri daripada tiga bahagian:
1) Isyarat topeng pra-latihan untuk mencapai encoder EEG yang berkesan dan mantap; Peresapan dan pasangan imej EEG terhad untuk penalaan halus;
3) Gunakan pengekod CLIP untuk menjajarkan ruang EEG, teks dan imej.
Pertama, penyelidik menggunakan data EEG dengan banyak bunyi dan menggunakan pemodelan isyarat topeng untuk melatih pengekod EEG dan mengekstrak pengetahuan kontekstual. Pengekod EEG yang terhasil kemudiannya digunakan untuk menyediakan ciri bersyarat untuk Resapan Stabil melalui mekanisme perhatian silang.
Pictures
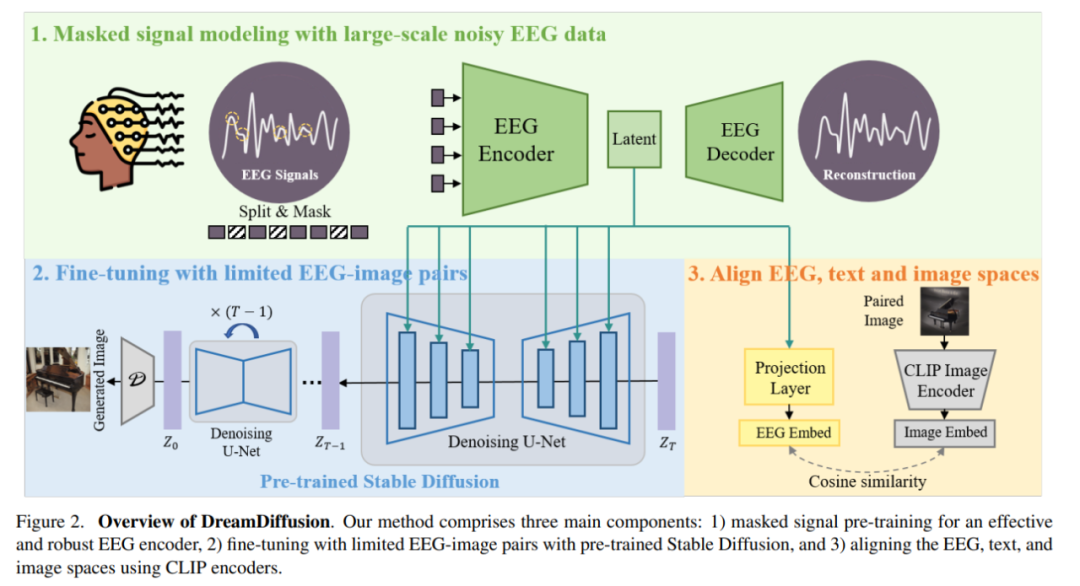 Untuk meningkatkan keserasian ciri EEG dengan Stable Diffusion, penyelidik menyelaraskan EEG, teks dan imej lagi dengan mengurangkan jarak antara benam EEG dan CLIP-imej embedding. proses.
Untuk meningkatkan keserasian ciri EEG dengan Stable Diffusion, penyelidik menyelaraskan EEG, teks dan imej lagi dengan mengurangkan jarak antara benam EEG dan CLIP-imej embedding. proses.
Eksperimen dan Analisis
Perbandingan dengan Brain2Image
Para penyelidik membandingkan kaedah dalam artikel ini dengan Brain2Image. Brain2Image menggunakan model generatif tradisional, iaitu pengekod auto variasi (VAE) dan rangkaian musuh generatif (GAN), untuk penukaran daripada EEG kepada imej. Walau bagaimanapun, Brain2Image hanya memberikan hasil untuk beberapa kategori dan tidak menyediakan pelaksanaan rujukan.
Dengan mengambil kira perkara ini, kajian ini melakukan perbandingan kualitatif bagi beberapa kategori yang dibentangkan dalam kertas Brain2Image (iaitu kapal terbang, jack-o-lantern dan panda). Untuk memastikan perbandingan yang adil, penyelidik menggunakan strategi penilaian yang sama seperti yang diterangkan dalam kertas Brain2Image dan menunjukkan keputusan yang dihasilkan oleh kaedah yang berbeza dalam Rajah 5 di bawah.
Baris pertama rajah di bawah menunjukkan hasil yang dijana oleh Brain2Image, dan baris terakhir dijana oleh DreamDiffusion, kaedah yang dicadangkan oleh penyelidik. Ia boleh dilihat bahawa kualiti imej yang dijana oleh DreamDiffusion adalah jauh lebih tinggi daripada yang dihasilkan oleh Brain2Image, yang juga mengesahkan keberkesanan kaedah ini.
Pictures
 bablation Experiment
bablation Experiment
Peranan pra-latihan
: Untuk menunjukkan keberkesanan data EEG berskala besar, kajian ini menggunakan pengekod yang tidak terlatih untuk melatih Sahkan berbilang model. Salah satu model adalah sama dengan model penuh, manakala model lain hanya mempunyai dua lapisan pengekodan EEG untuk mengelak daripada overfitting data. Semasa proses latihan, kedua-dua model telah dilatih dengan/tanpa penyeliaan CLIP, dan hasilnya ditunjukkan dalam lajur 1 hingga 4 Model dalam Jadual 1. Ia dapat dilihat bahawa ketepatan model tanpa pra-latihan dikurangkan.
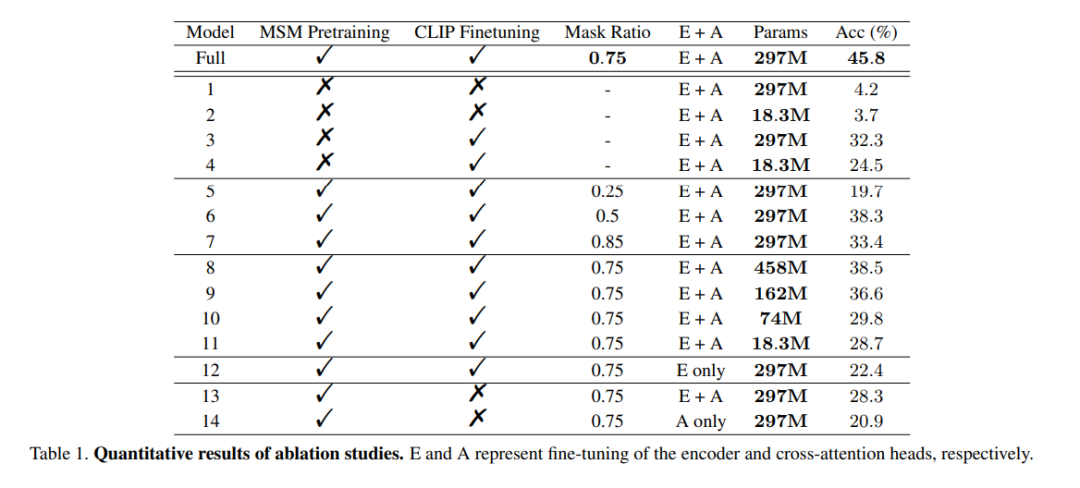 nisbah topeng
nisbah topeng
: Kertas kerja ini juga menyiasat penggunaan data EEG untuk menentukan nisbah topeng optimum untuk pra-latihan MSM. Seperti yang ditunjukkan dalam lajur 5 hingga 7 Model dalam Jadual 1, nisbah topeng yang terlalu tinggi atau terlalu rendah boleh menjejaskan prestasi model. Ketepatan keseluruhan tertinggi dicapai apabila nisbah topeng ialah 0.75. Penemuan ini penting kerana ia menunjukkan bahawa, tidak seperti pemprosesan bahasa semula jadi, yang biasanya menggunakan nisbah topeng rendah, nisbah topeng tinggi adalah pilihan yang lebih baik apabila melakukan MSM pada EEG. Penjajaran KLIP
: Salah satu kunci kepada kaedah ini ialah menjajarkan perwakilan EEG kepada imej melalui pengekod CLIP. Kajian ini menjalankan eksperimen untuk mengesahkan keberkesanan kaedah ini, dan hasilnya ditunjukkan dalam Jadual 1. Dapat diperhatikan bahawa prestasi model menurun dengan ketara apabila penyeliaan CLIP tidak digunakan. Malah, seperti yang ditunjukkan di sudut kanan bawah Rajah 6, menggunakan CLIP untuk menyelaraskan ciri EEG masih boleh menghasilkan hasil yang munasabah walaupun tanpa pra-latihan, yang menyerlahkan kepentingan penyeliaan CLIP dalam kaedah ini. Gambar
Atas ialah kandungan terperinci Gambar dalam otak anda kini boleh dipulihkan dalam definisi tinggi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI