
Rumah >Peranti teknologi >AI >Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari
Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-07-03 20:57:171536semak imbas
Ejen AI DeepMind mengusik dirinya sendiri lagi!
Lihat lelaki bernama BBF ini, dia menguasai 26 permainan Atari dalam masa 2 jam sahaja.
Anda mesti tahu bahawa ejen AI sentiasa berkesan dalam menyelesaikan masalah melalui pembelajaran pengukuhan, tetapi masalah terbesar ialah kaedah ini sangat tidak cekap dan memerlukan masa yang lama untuk diterokai.
 Gambar
Gambar
Kejayaan yang dibawakan oleh BBF adalah tepat dari segi kecekapan.
Tidak hairanlah nama penuhnya boleh dipanggil Bigger, Better, atau Faster.
Dan ia boleh melengkapkan latihan hanya pada satu kad, dan keperluan kuasa pengkomputeran juga jauh berkurangan.
BBF telah dicadangkan bersama oleh Google DeepMind dan Universiti Montreal Data dan kod ini adalah sumber terbuka.
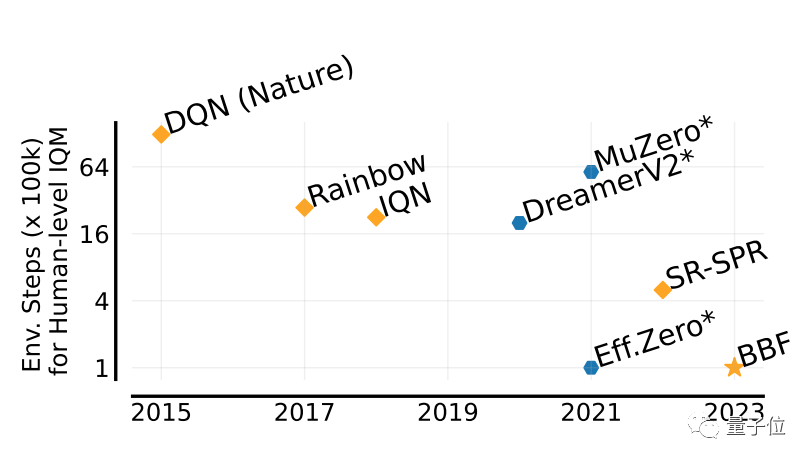
Boleh mencapai sehingga 5 kali ganda prestasi manusia
Nilai yang digunakan untuk menilai prestasi permainan BBF dipanggil IQM.
IQM ialah skor komprehensif bagi prestasi permainan pelbagai aspek Markah IQM dalam artikel ini dinormalkan berdasarkan manusia.
Berbanding dengan beberapa keputusan sebelumnya, BBF mencapai skor IQM tertinggi dalam set data ujian Atari 100K yang mengandungi 26 permainan Atari.
Dan, dalam 26 permainan yang telah dilatih, prestasi BBF telah melebihi prestasi manusia.
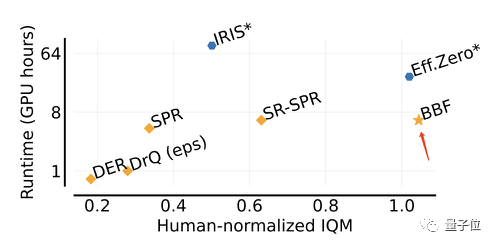
Berbanding dengan Eff.Zero, yang berprestasi serupa, BBF menggunakan hampir separuh masa GPU.
Bagi SPR dan SR-SPR, yang menggunakan masa GPU yang sama, prestasi mereka jauh di belakang BBF.
 Gambar
Gambar
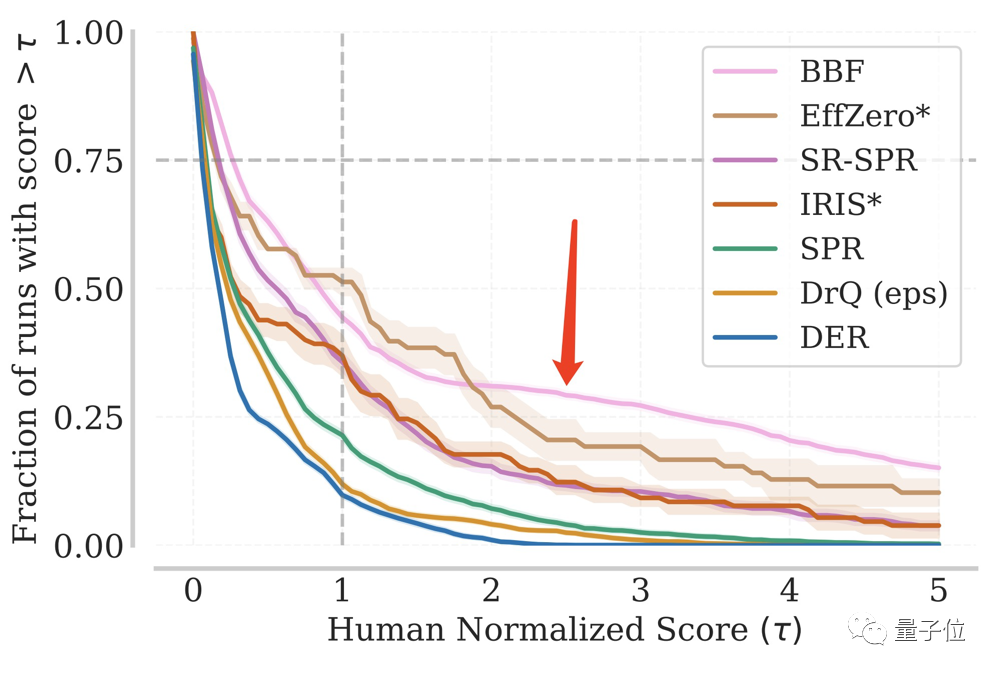
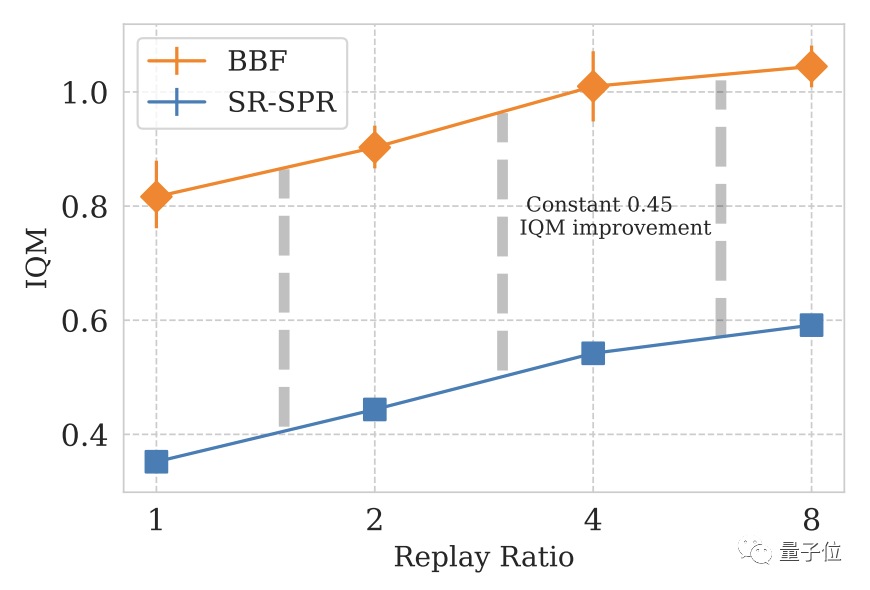
Dalam ujian berulang, bahagian BBF mencapai skor IQM tertentu sentiasa kekal pada tahap yang tinggi.
Walaupun dalam lebih 1/8 daripada jumlah ujian dijalankan, ia mencapai 5 kali ganda prestasi manusia.
 Gambar
Gambar
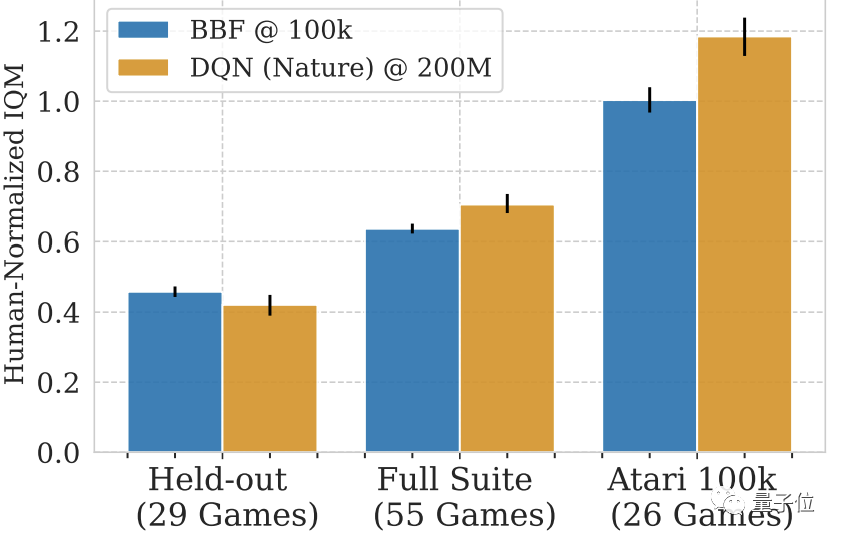
Walaupun dengan penambahan permainan Atari lain tanpa latihan, BBF boleh mencapai lebih daripada separuh skor IQM manusia.
Jika anda melihat 29 permainan yang tidak terlatih ini sahaja, markah BBF adalah 40 hingga 50% berbanding manusia.
 Gambar
Gambar
Diubah suai berdasarkan SR-SPR
Masalah yang mendorong penyelidikan BBF ialah bagaimana mengembangkan rangkaian pembelajaran pengukuhan yang mendalam apabila saiz sampel adalah jarang.
Untuk mengkaji masalah ini, DeepMind memfokuskan pada penanda aras Atari 100K.
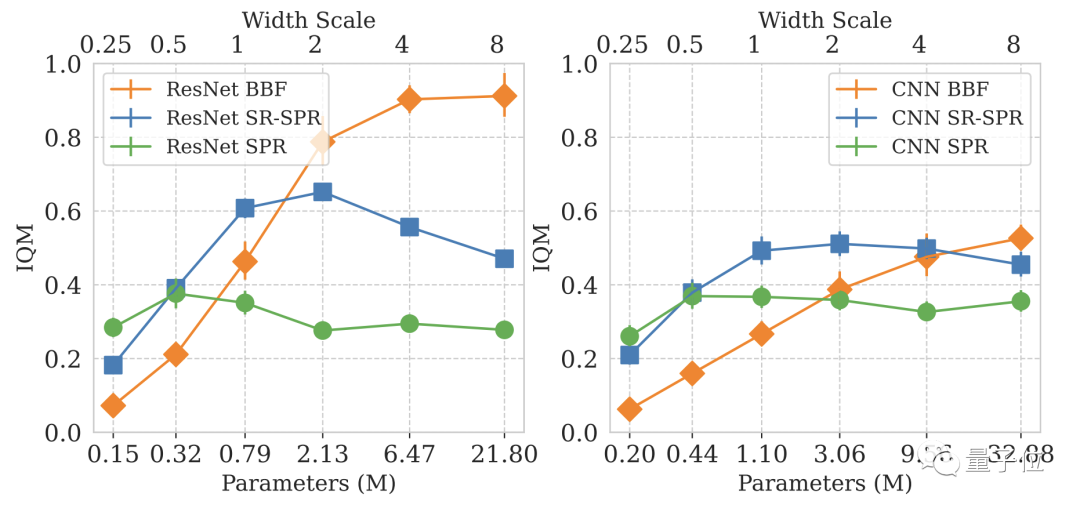
Tetapi DeepMind tidak lama kemudian mendapati bahawa hanya meningkatkan saiz model tidak meningkatkan prestasinya.
 Gambar
Gambar
Dalam reka bentuk model pembelajaran mendalam, bilangan kemas kini setiap langkah (Nisbah Main Semula, RR) ialah parameter penting.
Khusus untuk permainan Atari, lebih besar nilai RR, lebih tinggi prestasi model dalam permainan.
Akhir sekali, DeepMind menggunakan SR-SPR sebagai enjin asas, dan nilai RR SR-SPR boleh mencecah sehingga 16.
Selepas pertimbangan menyeluruh, DeepMind memilih 8 sebagai nilai RR BBF.
Memandangkan sesetengah pengguna tidak mahu membelanjakan kos pengkomputeran RR=8, DeepMind turut membangunkan versi RR=2 BBF
 Pictures
Pictures
Selepas DeepMind mengubah suai banyak kandungan dalam SR-SPR sendiri, ia menerima pakai sendiri. Latihan penyeliaan yang diperolehi oleh BBF terutamanya merangkumi aspek berikut:
- Kekuatan tetapan semula lapisan lilitan yang lebih tinggi: Meningkatkan kekuatan set semula lapisan lilitan boleh meningkatkan amplitud gangguan untuk sasaran rawak, membolehkan model berprestasi lebih baik dan mengurangkan kehilangan Selepas kekuatan set semula BBF ditingkatkan, amplitud gangguan berubah daripada SR kepada SR . -SPR meningkat daripada 20% kepada 50%
- Saiz rangkaian yang lebih besar: Tingkatkan bilangan lapisan rangkaian saraf daripada 3 kepada 15 lapisan, dan tingkatkan lebar sebanyak 4 kali ganda
- Pengurangan julat (n) kemas kini: Ingin menambah baik model Prestasi memerlukan penggunaan nilai tidak tetap n. BBF ditetapkan semula setiap 40,000 langkah kecerunan Dalam 10,000 langkah kecerunan pertama setiap tetapan semula, n berkurangan secara eksponen daripada 10 kepada 3. Fasa pereputan menyumbang 25% daripada proses latihan BBF
- Faktor pereputan yang lebih besar (γ): Sesetengah orang mempunyai didapati peningkatan nilai γ semasa proses pembelajaran boleh meningkatkan prestasi model Nilai γ BBF meningkat daripada 0.97 tradisional kepada 0.997
- Pengecilan berat badan: Untuk mengelakkan berlakunya overfitting, pengecilan BBF adalah lebih kurang 0.1
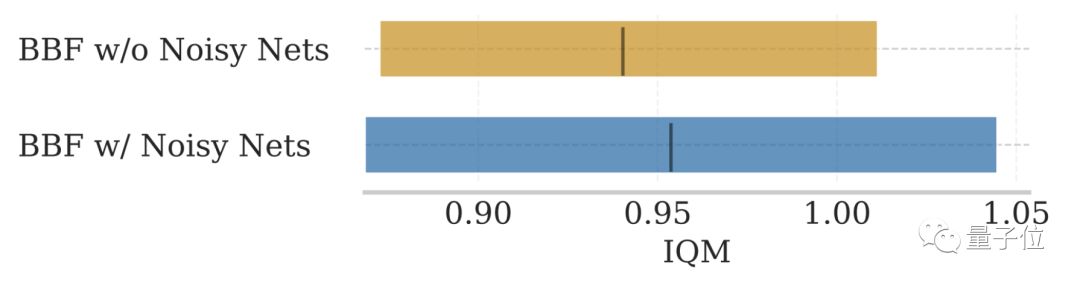
- Delete NoisyNet : NoisyNet yang disertakan dalam SR-SPR asal tidak dapat meningkatkan prestasi model
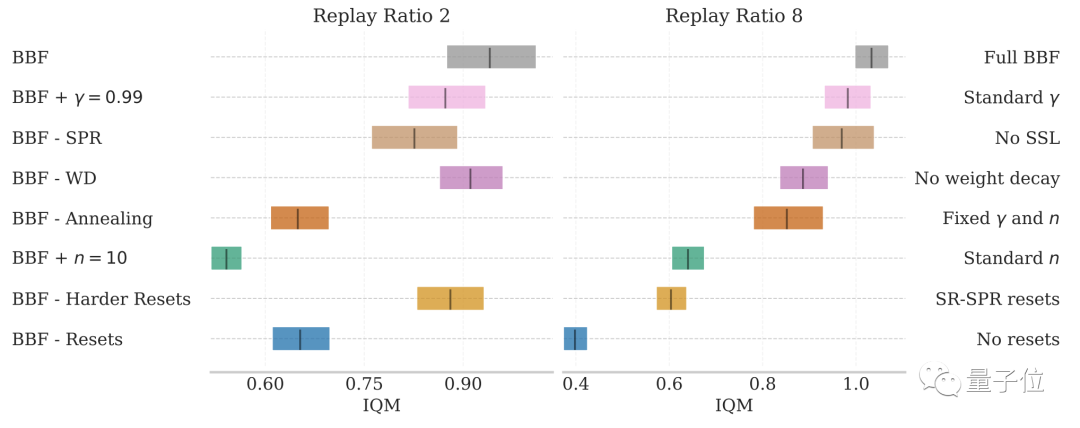
Hasil percubaan ablasi menunjukkan bahawa di bawah syarat 2 dan 8 kemas kini setiap langkah, faktor di atas mempunyai tahap kesan yang berbeza-beza terhadap prestasi BBF.
 Gambar
Gambar
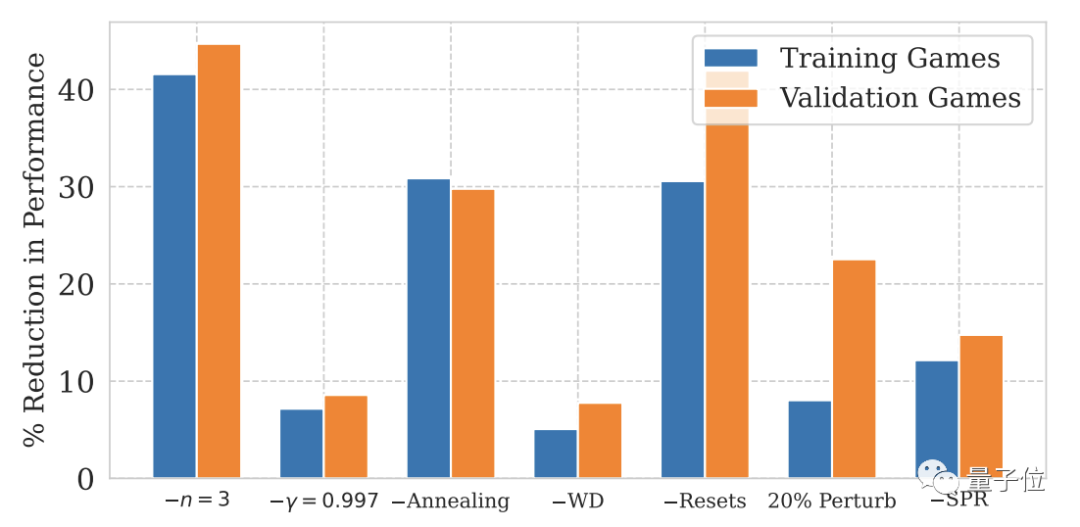
Antaranya, kesan tetapan semula keras dan pengurangan julat kemas kini adalah yang paling ketara.
 Pictures
Pictures
Untuk NoisyNet, yang tidak disebut dalam dua angka di atas, kesan ke atas prestasi model tidak ketara.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/abs/2305.19452Halaman projek GitHub: https://github.com/google-research/google-research/tree/master_faster_better Pautan rujukan: [1]
https://www.php.cn/link/69b4fa3be19bdf400df34e41b93636a4[2]https://www.marktechpost.com/2023/06/12/superhuman-the-performance -atari-100k-penanda aras-kuasa-bbf-ejen-rl-berasaskan-nilai-baru-dari-google-deepmind-mila-and-universite-de-montreal/
— Tamat —
Atas ialah kandungan terperinci Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI