
Rumah >Peranti teknologi >AI >Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K
Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-30 15:26:132080semak imbas
Memandangkan semua orang terus menaik taraf dan mengulang model besar mereka sendiri, keupayaan LLM (Model Bahasa Besar) untuk memproses tetingkap konteks juga telah menjadi penunjuk penilaian yang penting.
Sebagai contoh, gpt-3.5-turbo OpenAI menyediakan pilihan tetingkap konteks 16k token, dan AnthropicAI telah meningkatkan keupayaan pemprosesan token Claude kepada 100k. Apakah konsep tetingkap konteks pemprosesan model besar Sebagai contoh, GPT-4 menyokong 32k token, yang bersamaan dengan 50 halaman teks, yang bermaksud bahawa GPT-4 boleh mengingati sehingga kira-kira 50 halaman kandungan semasa bercakap atau menjana teks.
Secara umumnya, keupayaan model bahasa yang besar untuk mengendalikan saiz tetingkap konteks telah ditentukan terlebih dahulu. Sebagai contoh, untuk model LLaMA yang dikeluarkan oleh Meta AI, saiz token inputnya mestilah kurang daripada 2048.
Walau bagaimanapun, dalam aplikasi seperti menjalankan perbualan panjang, meringkaskan dokumen panjang atau melaksanakan rancangan jangka panjang, had tetingkap konteks pratetap selalunya melebihi, dan oleh itu, LLM yang boleh mengendalikan tetingkap konteks yang lebih panjang adalah lebih popular.
Tetapi ini menghadapi masalah baharu Melatih LLM dengan tetingkap konteks yang panjang dari awal memerlukan banyak pelaburan. Ini secara semula jadi membawa kepada persoalan: bolehkah kita memanjangkan tetingkap konteks LLM pra-latihan sedia ada?
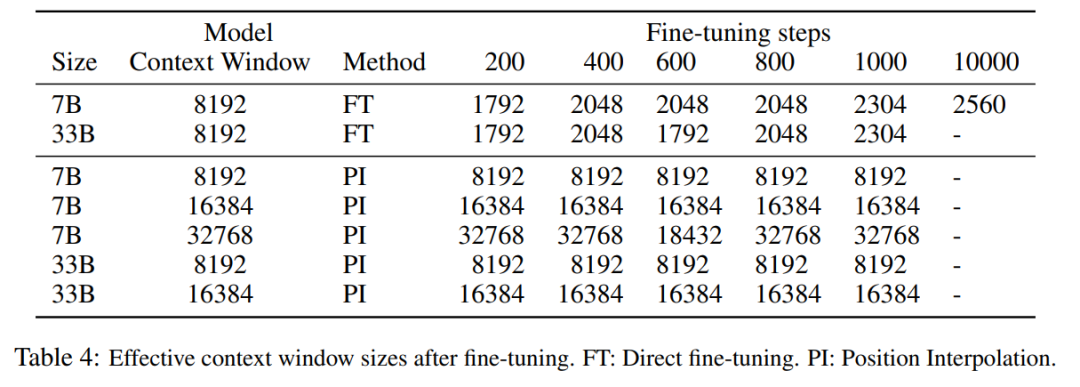
Pendekatan mudah adalah untuk memperhalusi Transformer sedia ada yang telah terlatih untuk mendapatkan tetingkap konteks yang lebih panjang. Walau bagaimanapun, keputusan empirikal menunjukkan bahawa model yang dilatih dengan cara ini menyesuaikan diri dengan sangat perlahan kepada tetingkap konteks yang panjang. Selepas 10000 kelompok latihan, peningkatan dalam tetingkap konteks berkesan masih sangat kecil, hanya dari 2048 hingga 2560 (seperti yang boleh dilihat dalam Jadual 4 dalam bahagian eksperimen). Ini menunjukkan bahawa pendekatan ini tidak cekap untuk menskalakan kepada tetingkap konteks yang lebih panjang.
Dalam artikel ini, penyelidik dari Meta memperkenalkan Position Interpolation (PI) untuk melanjutkan tetingkap konteks beberapa LLM pra-latihan sedia ada (termasuk LLaMA). Keputusan menunjukkan bahawa tetingkap konteks LLaMA berskala daripada 2k kepada 32k dengan kurang daripada 1000 langkah penalaan halus.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/pdf/2306.15595.pdf
Idea utama penyelidikan ini, bukan untuk melakukan ekstrapolasi secara langsung indeks, Jadikan indeks kedudukan maksimum sepadan dengan had tetingkap konteks peringkat pra-latihan. Dalam erti kata lain, untuk menampung lebih banyak token input, kajian ini menginterpolasi pengekodan kedudukan pada kedudukan integer bersebelahan, mengambil kesempatan daripada fakta bahawa pengekodan kedudukan boleh digunakan pada kedudukan bukan integer, berbanding dengan mengekstrapolasi di luar kedudukan terlatih. yang terakhir boleh membawa kepada nilai bencana.
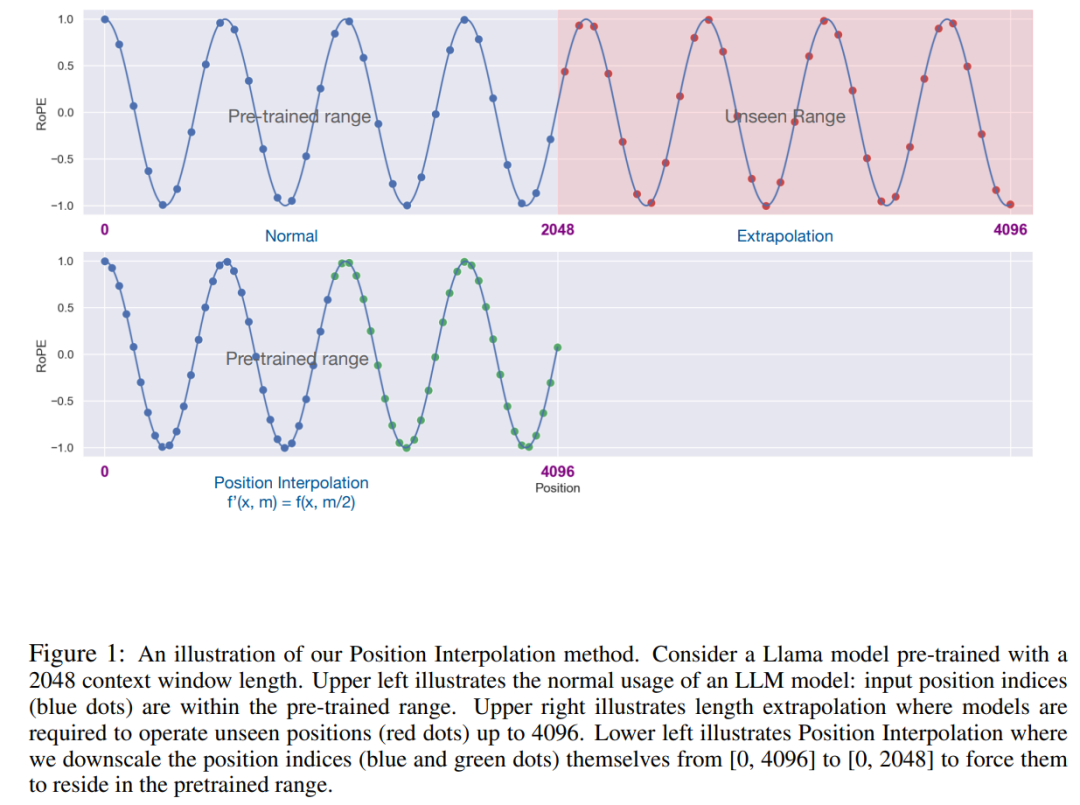
Kaedah PI memanjangkan saiz tetingkap konteks RoPE (pengekodan kedudukan diputar) berasaskan LLM pra-latihan seperti LLaMA kepada sehingga 32768 dengan penalaan halus yang minimum (dalam 1000 langkah), dengan baik pada pelbagai tugas yang memerlukan konteks yang panjang, termasuk pengambilan semula, pemodelan bahasa dan ringkasan dokumen yang panjang daripada LLaMA 7B hingga 65B. Pada masa yang sama, model yang dilanjutkan oleh PI mengekalkan kualiti yang agak baik dalam tetingkap konteks asalnya.
Method
rope hadir dalam model bahasa yang besar seperti Llama, Chatglm-6b, dan Palm yang kita kenal. pengekodan.
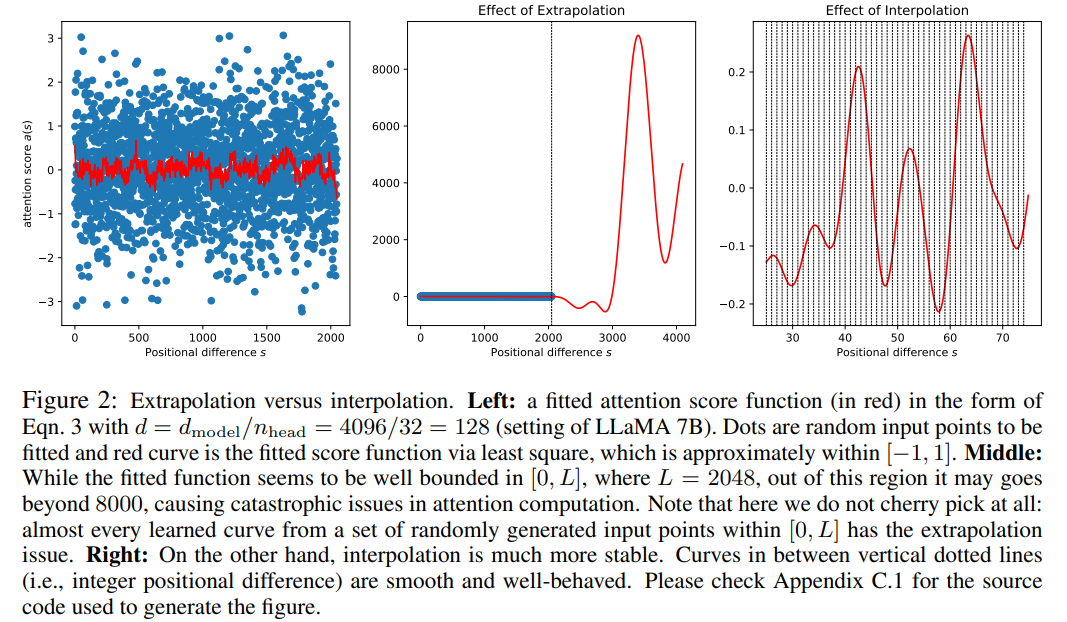
Walaupun skor perhatian dalam RoPE hanya bergantung pada kedudukan relatif, prestasi ekstrapolasinya tidak baik. Khususnya, apabila menskalakan terus ke tetingkap konteks yang lebih besar, kebingungan boleh meningkat kepada angka yang sangat tinggi (iaitu > 10^3).
Artikel ini menggunakan kaedah interpolasi kedudukan, dan perbandingannya dengan kaedah ekstrapolasi adalah seperti berikut. Oleh kerana kelancaran fungsi asas ϕ_j, interpolasi lebih stabil dan tidak membawa kepada outlier.
 Gambar
Gambar
Kajian ini menggantikan RoPE f dengan f ′ dan mendapat formula berikut
 Gambar
Gambar
Kajian ini memanggil penukaran pada interpolasi kedudukan pengekodan kedudukan. Langkah ini mengurangkan indeks kedudukan daripada [0, L′ ) kepada [0, L) untuk memadankan julat indeks asal sebelum mengira RoPE. Oleh itu, sebagai input kepada RoPE, jarak relatif maksimum antara mana-mana dua token telah dikurangkan daripada L 'ke L . Dengan menjajarkan julat indeks kedudukan dan jarak relatif sebelum dan selepas pengembangan, kesan ke atas pengiraan skor perhatian disebabkan pengembangan tetingkap konteks dikurangkan, yang menjadikan model lebih mudah untuk disesuaikan.
Perlu diambil perhatian bahawa kaedah indeks kedudukan penskalaan semula tidak memperkenalkan pemberat tambahan, dan juga tidak mengubah suai seni bina model dalam apa jua cara.
Eksperimen
Kajian ini menunjukkan bahawa interpolasi kedudukan secara berkesan boleh mengembangkan tetingkap konteks kepada 32 kali ganda saiz asal dan bahawa pengembangan ini boleh diselesaikan hanya dalam beberapa ratus langkah latihan.
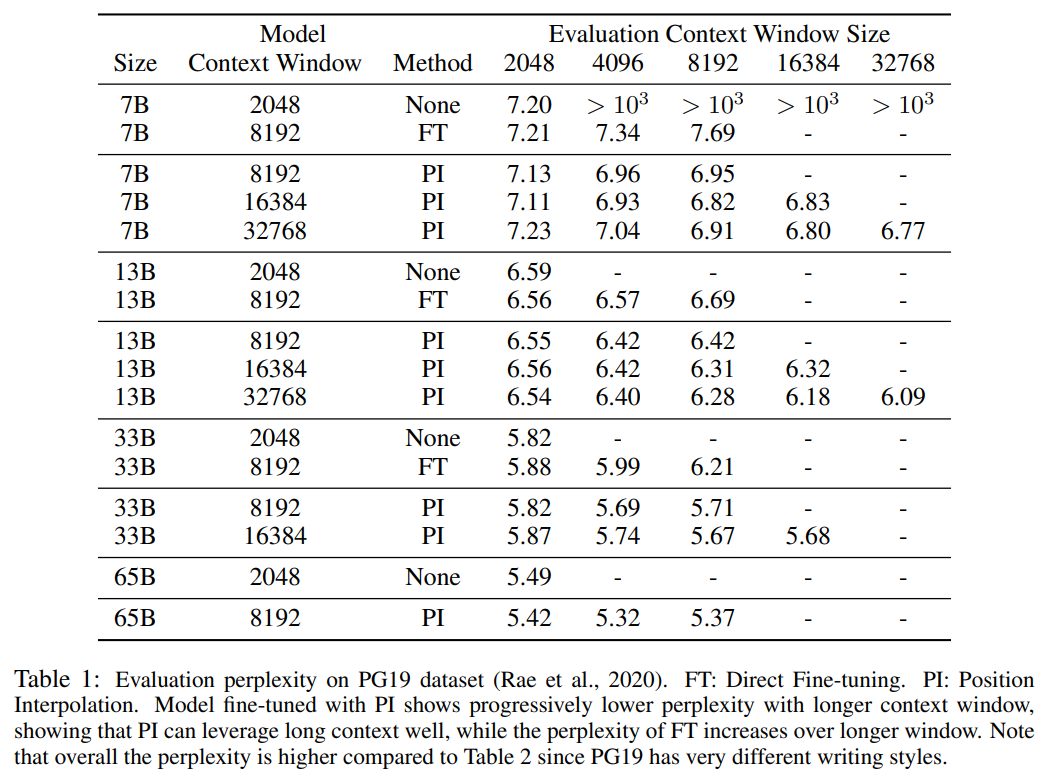
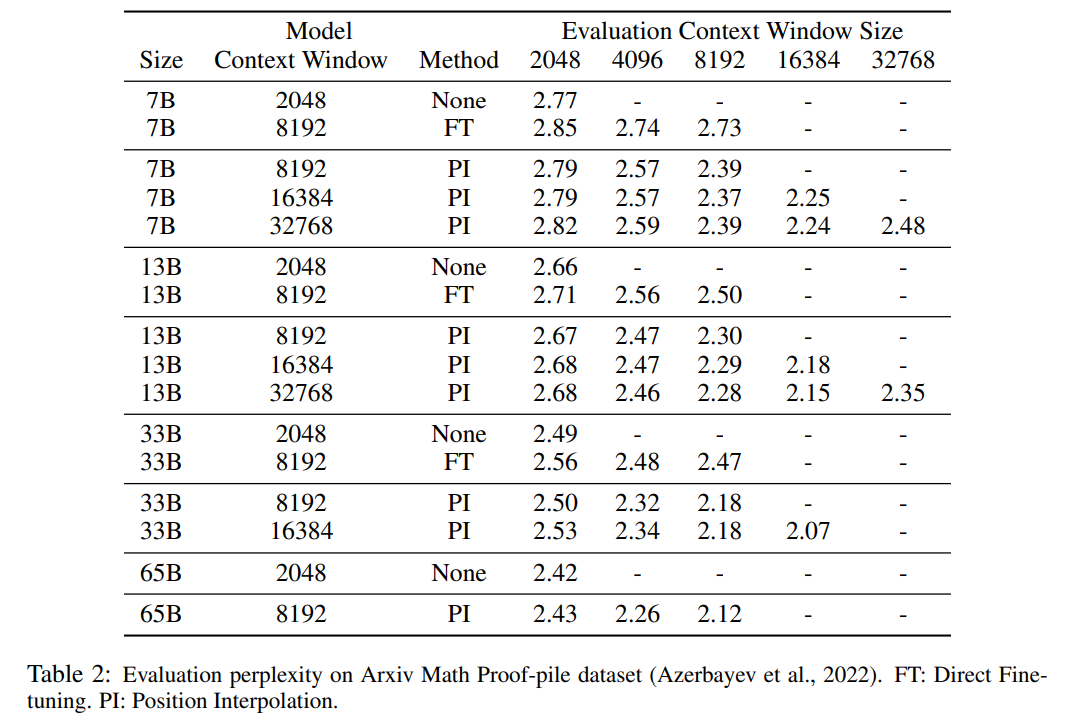
Jadual 1 dan Jadual 2 melaporkan kebingungan model PI dan model garis dasar pada set data cerucuk Bukti Matematik PG-19 dan Arxiv. Keputusan menunjukkan bahawa model yang dilanjutkan menggunakan kaedah PI dengan ketara meningkatkan kebingungan pada saiz tetingkap konteks yang lebih panjang.
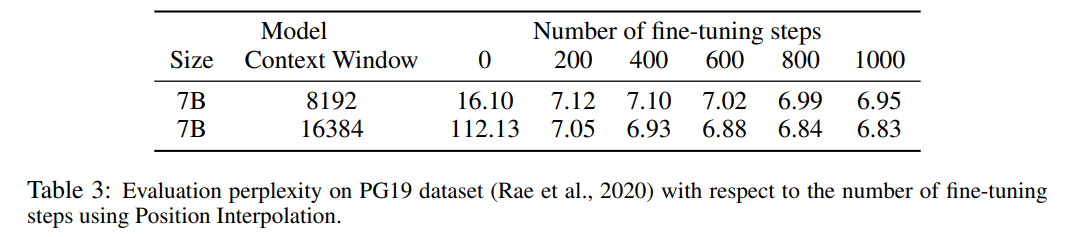
Jadual 3 melaporkan hubungan antara kebingungan dan bilangan langkah penalaan halus apabila memanjangkan model LLaMA 7B kepada saiz tetingkap konteks 8192 dan 16384 menggunakan kaedah PI pada set data PG19.
Ia dapat dilihat daripada keputusan bahawa tanpa penalaan halus (bilangan langkah ialah 0), model boleh menunjukkan keupayaan pemodelan bahasa tertentu, contohnya, apabila tetingkap konteks dikembangkan kepada 8192, kebingungan adalah kurang daripada 20 (berbanding Di bawah, kebingungan kaedah ekstrapolasi langsung adalah lebih besar daripada 10^3). Pada 200 langkah, kebingungan model melebihi model asal pada saiz tetingkap konteks 2048, menunjukkan bahawa model itu dapat menggunakan jujukan yang lebih panjang dengan berkesan untuk pemodelan bahasa berbanding tetapan pra-latihan. Peningkatan mantap dalam model dilihat pada 1000 langkah dan kebingungan yang lebih baik dicapai.
 Gambar
Gambar
Jadual di bawah menunjukkan bahawa model yang dilanjutkan oleh PI berjaya mencapai matlamat penskalaan dari segi saiz tetingkap konteks yang berkesan, iaitu selepas hanya 200 langkah penalaan halus, saiz tetingkap konteks yang berkesan mencapai nilai maksimum, Konsisten merentas saiz model 7B dan 33B dan sehingga 32768 tetingkap konteks. Sebaliknya, saiz tetingkap konteks berkesan model LLaMA yang dilanjutkan hanya dengan penalaan halus langsung hanya meningkat daripada 2048 kepada 2560, tanpa tanda peningkatan saiz tetingkap dipercepatkan yang ketara walaupun selepas lebih daripada 10000 langkah penalaan halus.
 Gambar
Gambar
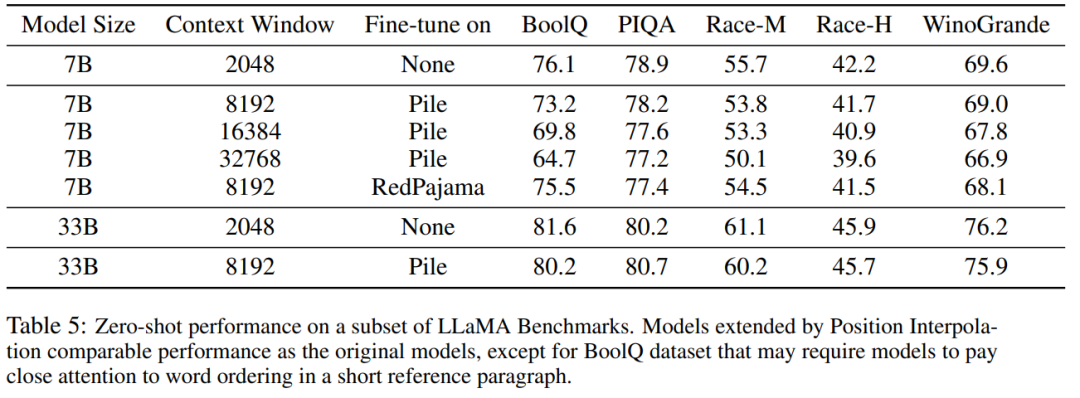
Jadual 5 menunjukkan bahawa model yang dilanjutkan kepada 8192 menghasilkan hasil yang setanding pada tugasan asas asal, yang direka bentuk untuk tetingkap konteks yang lebih kecil, untuk saiz model 7B dan 33B yang mencapai tugasan penanda aras sehingga 2%.
 Gambar
Gambar
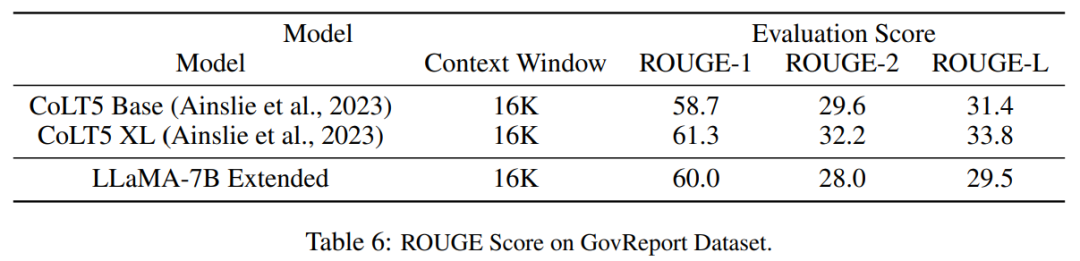
Jadual 6 menunjukkan bahawa model PI dengan tetingkap konteks 16384 boleh mengendalikan tugas ringkasan teks panjang dengan berkesan.
 Gambar
Gambar
Atas ialah kandungan terperinci Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI