
Rumah >Peranti teknologi >AI >Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.
Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-27 17:46:101522semak imbas
Generative AI telah menarik perhatian komuniti kecerdasan buatan Kedua-dua individu dan perusahaan telah mula berminat untuk mencipta aplikasi penukaran modal yang berkaitan, seperti gambar Vincent, video Vincent, muzik Vincent, dll.
Baru-baru ini, beberapa penyelidik dari institusi penyelidikan saintifik seperti ServiceNow Research dan LIVIA telah cuba menjana carta dalam kertas kerja berdasarkan penerangan teks. Untuk tujuan ini, mereka mencadangkan kaedah baharu FigGen, dan kertas berkaitan juga dimasukkan sebagai Tiny Paper dalam ICLR 2023.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/pdf/2306.00800.pdf
Sesetengah orang mungkin bertanya, apakah yang sukar dalam menghasilkan carta? Bagaimanakah ini membantu penyelidikan saintifik?
Penjanaan carta penyelidikan saintifik membantu menyebarkan hasil penyelidikan dengan cara yang ringkas dan mudah difahami, dan menjana carta secara automatik boleh membawa banyak kelebihan kepada penyelidik, seperti menjimatkan masa dan tenaga tanpa menghabiskan banyak usaha mereka bentuk carta dari awal . Selain itu, mereka bentuk angka yang menarik secara visual dan mudah difahami boleh menjadikan kertas itu boleh diakses oleh lebih ramai orang.
Walau bagaimanapun, menjana gambar rajah juga menghadapi beberapa cabaran. Ia perlu mewakili hubungan yang kompleks antara komponen diskret seperti kotak, anak panah, teks, dll. Tidak seperti menjana imej semula jadi, konsep dalam graf kertas mungkin mempunyai perwakilan yang berbeza dan memerlukan pemahaman yang terperinci Contohnya, menjana graf rangkaian saraf akan melibatkan masalah yang tidak ditimbulkan dengan varians yang tinggi.
Oleh itu, penyelidik dalam kertas kerja ini melatih model generatif pada set data pasangan rajah kertas untuk menangkap hubungan antara komponen rajah dan teks yang sepadan dalam kertas. Ini memerlukan berurusan dengan panjang yang berbeza-beza dan penerangan teks yang sangat teknikal, gaya carta yang berbeza, nisbah bidang imej dan fon pemaparan teks, saiz dan isu orientasi.
Semasa proses pelaksanaan khusus, penyelidik telah diilhamkan oleh hasil teks-ke-imej baru-baru ini dan menggunakan model resapan untuk menjana carta yang berpotensi untuk menghasilkan carta penyelidikan saintifik daripada huraian teks - FigGen.
Apakah ciri unik model resapan ini? Mari kita beralih kepada butiran.
Model dan Kaedah
Para penyelidik melatih model resapan terpendam dari awal.
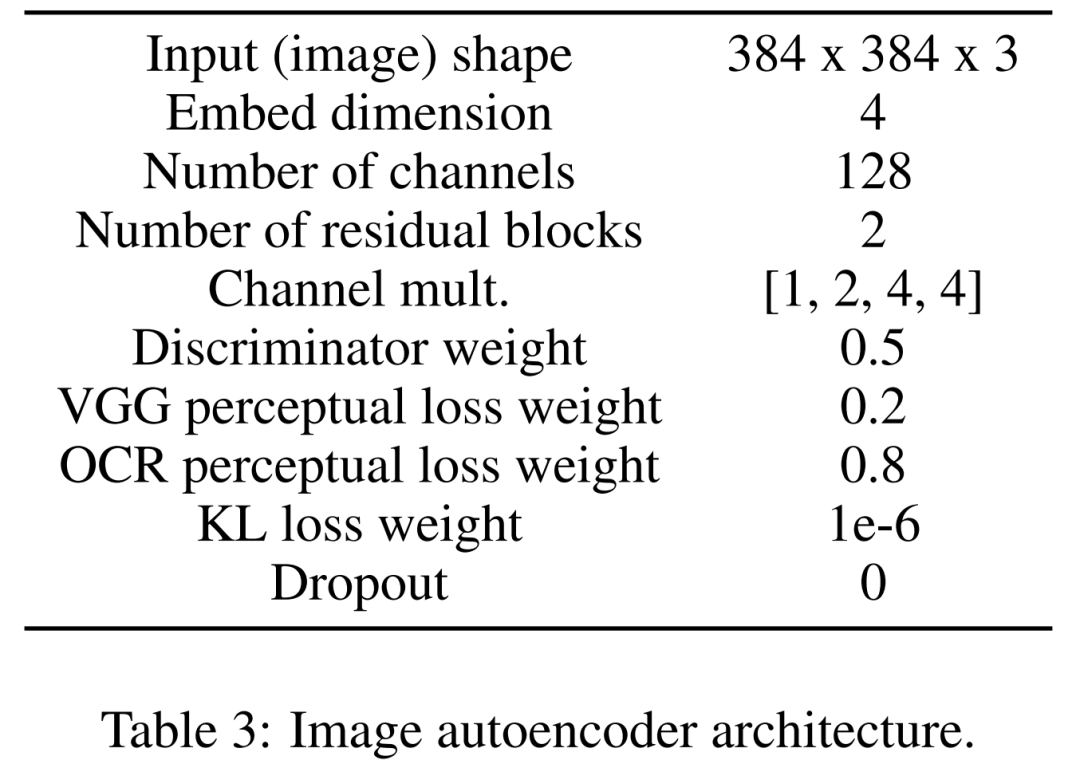
Mula-mula pelajari pengekod automatik imej untuk memetakan imej ke dalam perwakilan terpendam termampat. Pengekod imej menggunakan kehilangan KL dan kehilangan persepsi OCR. Pengekod teks yang digunakan untuk pelaziman dipelajari dari hujung ke hujung dalam latihan model resapan ini. Jadual 3 di bawah menunjukkan parameter terperinci seni bina autopengekod imej.
Model resapan kemudian berinteraksi secara langsung dalam ruang terpendam, melaksanakan penjadualan hadapan yang rosak data sambil belajar mengeksploitasikan U-Net bersyarat temporal dan tekstual untuk memulihkan proses.
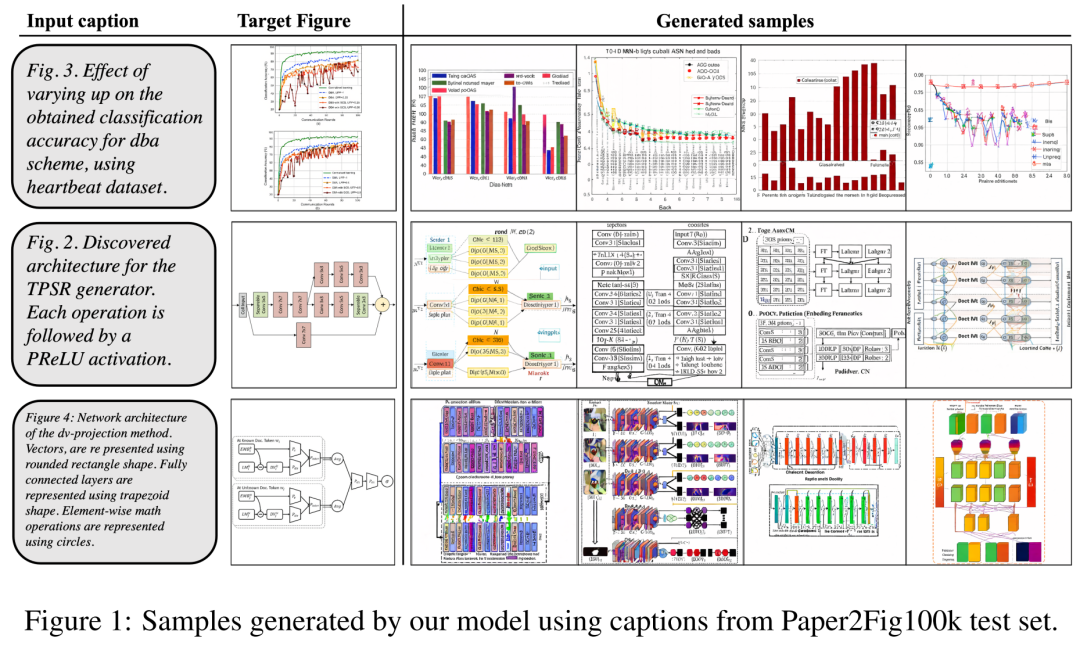
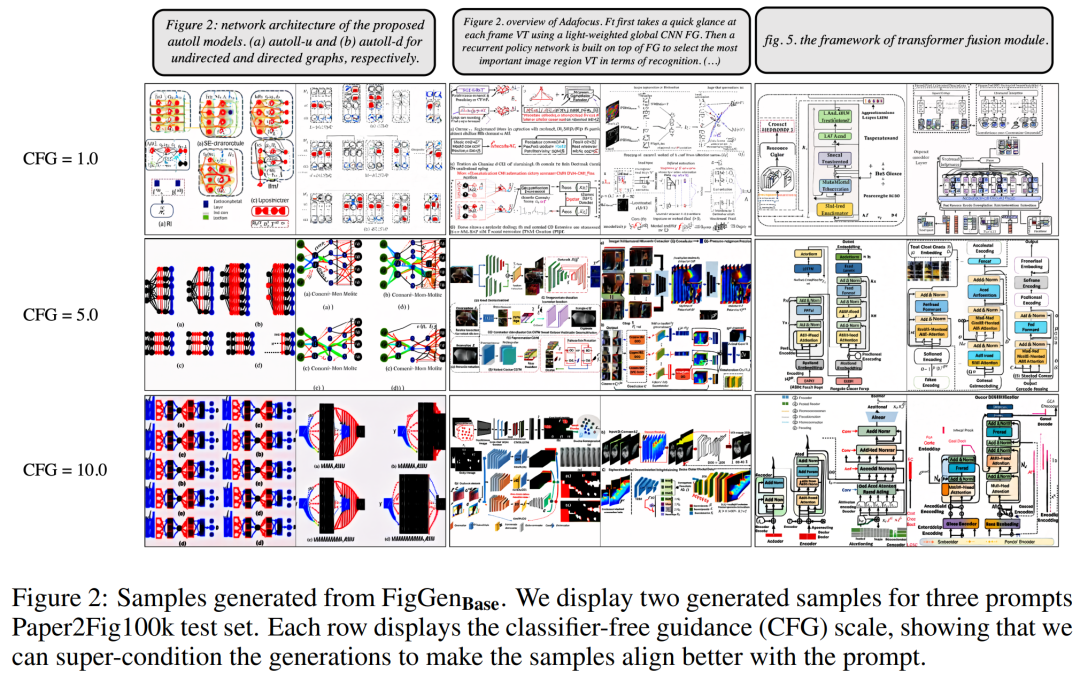
Bagi set data, penyelidik menggunakan Paper2Fig100k, yang terdiri daripada pasangan teks carta dalam kertas dan mengandungi 81,194 sampel latihan dan 21,259 sampel pengesahan. Rajah 1 di bawah ialah contoh rajah yang dijana menggunakan penerangan teks dalam set ujian Paper2Fig100k.
Butiran model
Pertama ialah pengekod imej. Pada peringkat pertama, pengekod automatik imej mempelajari pemetaan daripada ruang piksel kepada perwakilan terpendam termampat, menjadikan latihan model resapan lebih pantas. Pengekod imej juga perlu belajar untuk memetakan imej asas kembali ke ruang piksel tanpa kehilangan butiran penting rajah (seperti kualiti pemaparan teks).
Untuk tujuan ini, penyelidik mentakrifkan codec konvolusi dengan halangan yang mengurangkan sampel imej pada faktor f=8. Pengekod dilatih untuk meminimumkan kehilangan KL, kehilangan sedar VGG dan kehilangan sedar OCR dengan pengedaran Gaussian.
Kedua ialah pengekod teks. Penyelidik telah mendapati bahawa pengekod teks tujuan umum tidak sesuai untuk tugas penjanaan graf. Oleh itu, mereka mentakrifkan pengubah Bert yang dilatih dari awal dalam proses resapan, yang menggunakan saluran pembenaman bersaiz 512, yang juga merupakan saiz benam yang mengawal lapisan perhatian silang U-Net. Para penyelidik juga meneroka perubahan dalam bilangan lapisan pengubah di bawah tetapan yang berbeza (8, 32, dan 128).
Yang terakhir ialah model resapan terpendam. Jadual 2 di bawah menunjukkan seni bina rangkaian U-Net. Kami melakukan proses resapan pada perwakilan terpendam yang setara dengan imej, dengan saiz input imej dimampatkan kepada 64x64x4, menjadikan model resapan lebih pantas. Mereka menentukan 1,000 langkah resapan dan penjadualan hingar linear. . yang mana empat kad grafik NVIDIA V100 12GB telah digunakan. Untuk mencapai kestabilan latihan, mereka memanaskan model dalam lelaran 50k tanpa menggunakan diskriminator.
Untuk melatih model resapan terpendam, para penyelidik juga menggunakan pengoptimum Adam, yang mempunyai saiz kelompok berkesan 32 dan kadar pembelajaran 1e−4. Apabila melatih model pada dataset Paper2Fig100k, mereka menggunakan lapan kad grafik NVIDIA A100 80GB. 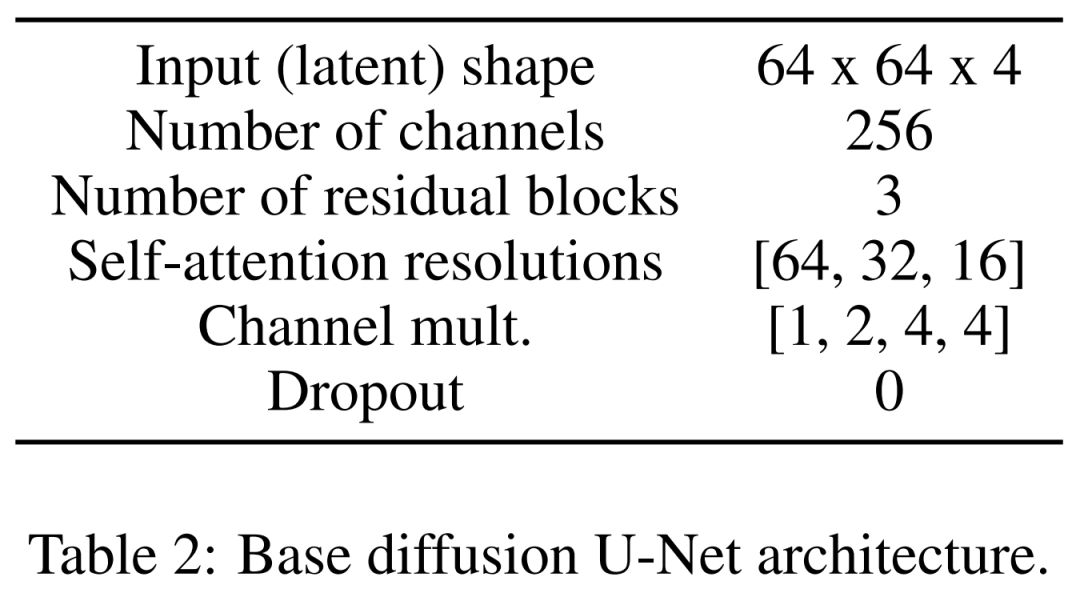
Hasil eksperimenSemasa proses penjanaan, para penyelidik menggunakan pensampel DDIM dengan 200 langkah dan menghasilkan 12,000 sampel untuk setiap model untuk mengira FID, IS, KID dan OCR-SIM1. Penggunaan teguh panduan bebas pengelas (CFG) untuk menguji hiperkondisi.
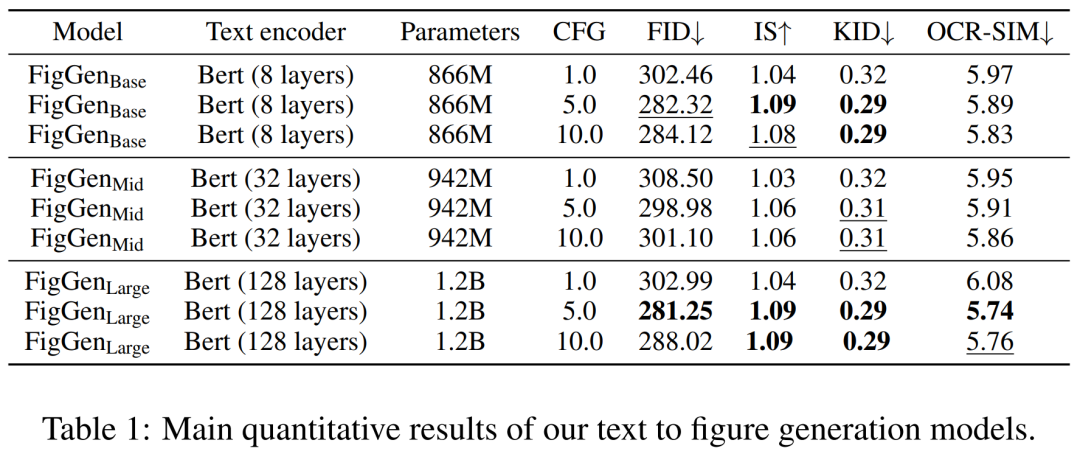
Jadual 1 di bawah menunjukkan keputusan pengekod teks yang berbeza. Ia boleh dilihat bahawa pengekod teks besar menghasilkan keputusan kualitatif yang terbaik dan penjanaan keadaan boleh diperbaiki dengan meningkatkan saiz CFG. Walaupun sampel kualitatif tidak mempunyai kualiti yang mencukupi untuk menyelesaikan masalah, FigGen telah memahami hubungan antara teks dan imej.
Rajah 2 di bawah menunjukkan sampel FigGen tambahan yang dijana semasa melaraskan parameter Bimbingan Percuma Pengelas (CFG). Para penyelidik memerhatikan bahawa peningkatan saiz CFG, yang juga ditunjukkan secara kuantitatif, membawa kepada peningkatan dalam kualiti imej.
Gambar
Rajah 3 di bawah menunjukkan lebih banyak contoh generasi daripada FigGen. Beri perhatian kepada variasi panjang antara sampel, serta tahap teknikal penerangan teks, yang akan mempengaruhi kesukaran model untuk menjana imej yang boleh difahami dengan betul.
 Gambar
Gambar
Walau bagaimanapun, para penyelidik juga mengakui bahawa walaupun carta yang dihasilkan ini tidak dapat memberikan bantuan praktikal kepada pengarang kertas kerja, ia masih merupakan hala tuju yang menjanjikan untuk diterokai.
 Sila rujuk kertas asal untuk butiran penyelidikan lanjut.
Sila rujuk kertas asal untuk butiran penyelidikan lanjut.
Atas ialah kandungan terperinci Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI