
Rumah >Peranti teknologi >AI >Strategi pengimbangan beban Dubbo pencincangan yang konsisten
Strategi pengimbangan beban Dubbo pencincangan yang konsisten

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-26 15:39:181795semak imbas
Artikel ini menerangkan terutamanya prinsip algoritma cincang konsisten dan masalah pencongan datanya yang sedia ada, kemudian memperkenalkan kaedah untuk menyelesaikan masalah pencongan data, dan akhirnya menganalisis penggunaan algoritma cincang yang konsisten dalam Dubbo. Artikel ini memperkenalkan cara algoritma pencincangan yang konsisten berfungsi, serta masalah dan penyelesaian yang dihadapi oleh algoritma.
1. Load Balancing
Berikut adalah petikan dari laman web rasmi dubbo -
LoadBalance bermaksud pengimbangan beban dalam bahasa Cina Tanggungjawabnya adalah untuk "mengedarkan sama rata" permintaan rangkaian atau bentuk beban lain kepada mesin yang berbeza. Elakkan situasi di mana sesetengah pelayan dalam kelompok berada di bawah tekanan yang berlebihan manakala pelayan lain agak melahu. Melalui pengimbangan beban, setiap pelayan boleh mendapatkan beban yang sesuai untuk keupayaan pemprosesannya sendiri. Semasa memunggah pelayan muatan tinggi, anda juga boleh mengelakkan pembaziran sumber, membunuh dua burung dengan satu batu. Pengimbangan beban boleh dibahagikan kepada pengimbangan beban perisian dan pengimbangan beban perkakasan. Dalam pembangunan harian kami, secara amnya sukar untuk mengakses pengimbangan beban perkakasan. Tetapi pengimbangan beban perisian masih tersedia, seperti Nginx. Di Dubbo, terdapat juga konsep pengimbangan beban dan pelaksanaan yang sepadan.
Untuk mengelakkan beban berlebihan pada penyedia perkhidmatan tertentu, Dubbo perlu memperuntukkan permintaan panggilan daripada pengguna perkhidmatan. Beban pembekal perkhidmatan terlalu besar, yang mungkin menyebabkan beberapa permintaan tamat masa. Oleh itu, adalah sangat perlu untuk mengimbangi beban kepada setiap pembekal perkhidmatan. Dubbo menyediakan 4 pelaksanaan pengimbangan beban, iaitu RandomLoadBalance berdasarkan algoritma rawak berwajaran, LeastActiveLoadBalance berdasarkan algoritma panggilan paling kurang aktif, ConsistentHashLoadBalance berdasarkan konsistensi cincang dan RoundRobinLoadBalance berdasarkan algoritma tinjauan berwajaran. Walaupun kod algoritma pengimbangan beban ini tidak begitu panjang, memahami prinsipnya memerlukan pengetahuan dan pemahaman profesional tertentu. Algoritma Hash tidak tahu pelayan mana maklumat pengguna disimpan, kami perlu menanyakan pelayan 0, 1, dan 2 masing-masing. Kecekapan mendapatkan data dengan cara ini adalah sangat rendah.
Untuk senario sedemikian, kami boleh memperkenalkan algoritma cincang.
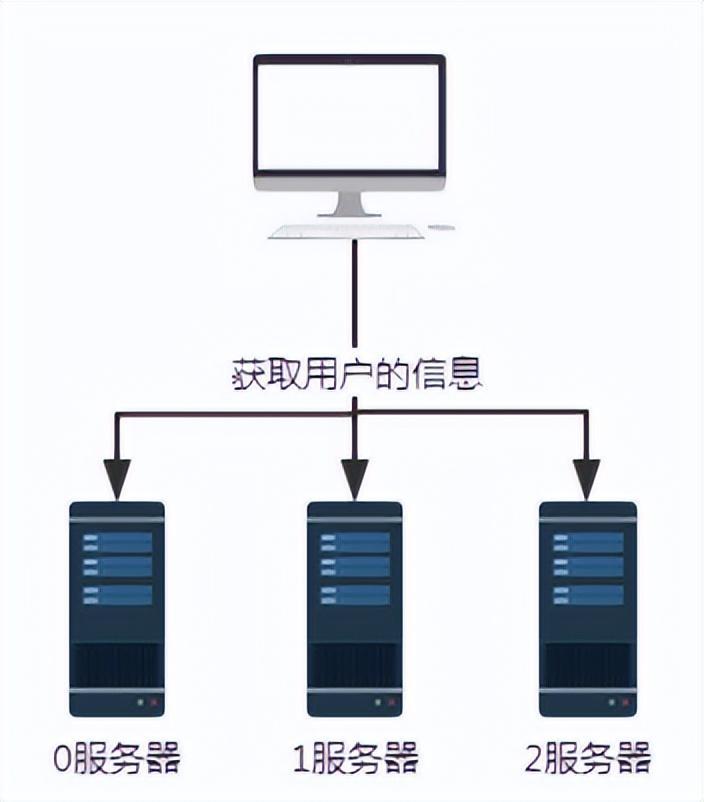
Rajah 2 Permintaan selepas memperkenalkan algoritma cincang
Dalam senario di atas, diandaikan bahawa setiap pelayan menggunakan algoritma cincang yang sama untuk menyimpan maklumat pengguna. Oleh itu, apabila mendapatkan maklumat pengguna, ikut sahaja algoritma pencincangan yang sama.
Katakan kita ingin menanyakan maklumat pengguna dengan nombor pengguna 100. Selepas algoritma hash tertentu, seperti userId mod n di sini, iaitu, 100 mod 3, hasilnya ialah 1. Jadi permintaan daripada pengguna nombor 100 akhirnya akan diterima dan diproses oleh pelayan nombor 1.
Ini menyelesaikan masalah pertanyaan tidak sah. 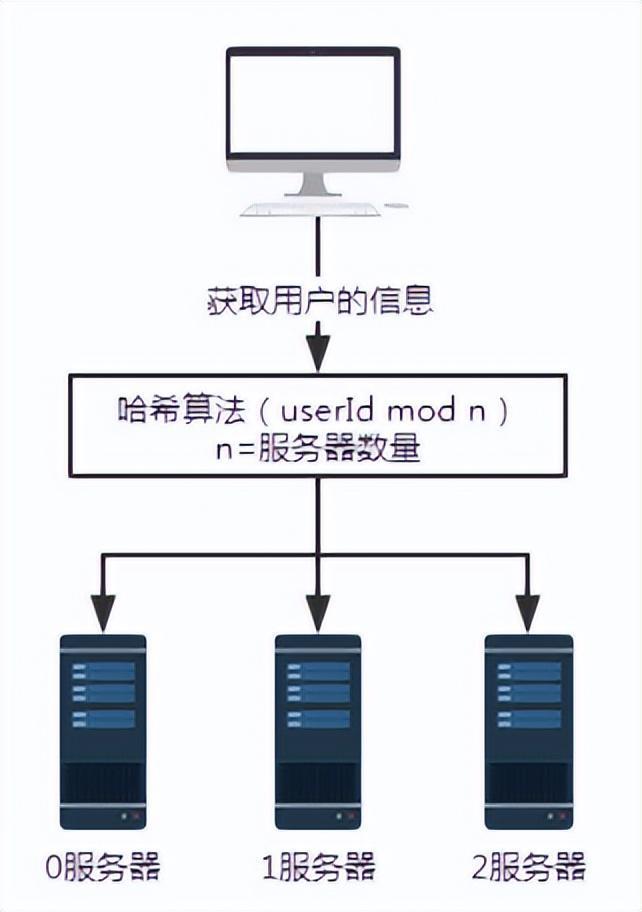
Rajah 3 Menambah pelayan
Untuk menggambarkan masalah, tambah pelayan 3. Bilangan pelayan n berubah dari 3 kepada 4. Apabila menanyakan maklumat pengguna dengan nombor pengguna 100, baki selepas membahagikan 100 dengan 4 ialah 0. Pada masa ini, permintaan diterima oleh pelayan 0.
Apabila bilangan pelayan adalah 3, permintaan dengan nombor pengguna 100 akan diproses oleh pelayan No.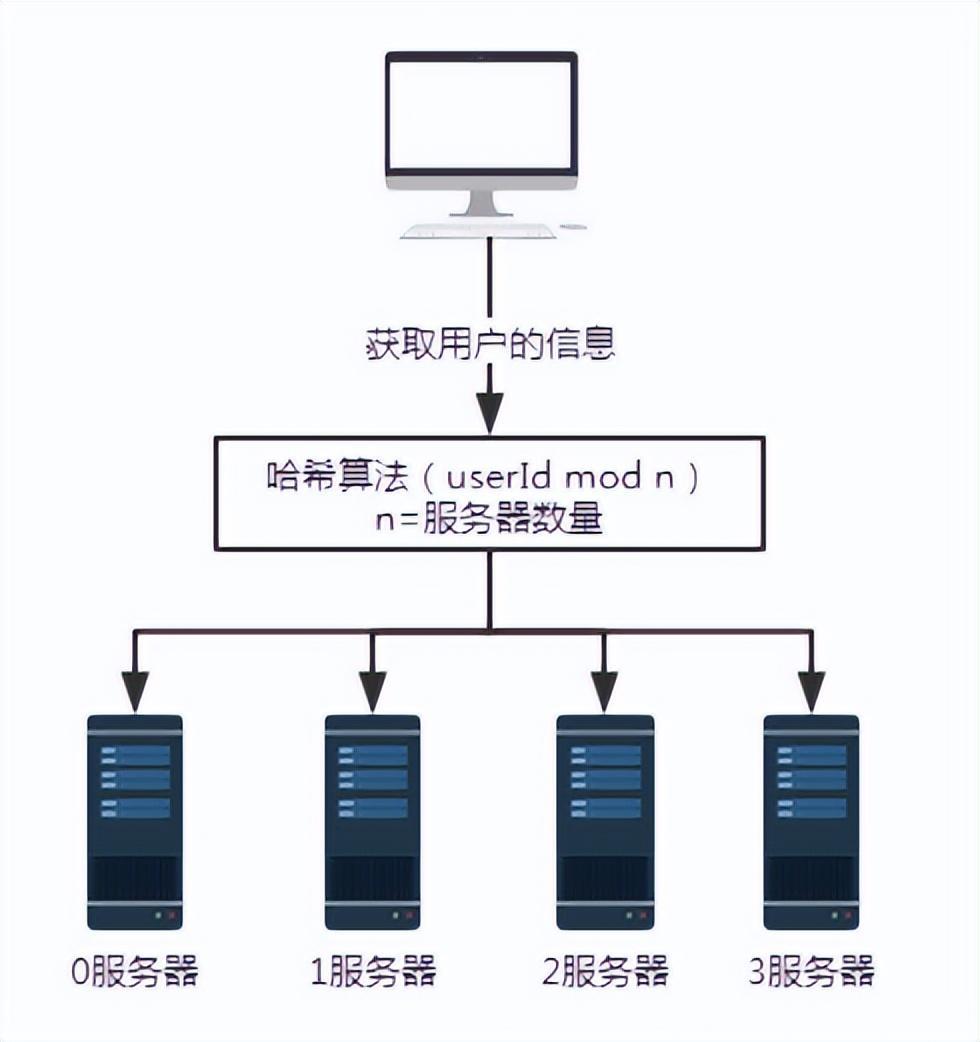 Apabila bilangan pelayan adalah 4, permintaan dengan nombor pengguna 100 akan diproses oleh pelayan 0.
Apabila bilangan pelayan adalah 4, permintaan dengan nombor pengguna 100 akan diproses oleh pelayan 0.
- Kelemahan teknologi ini ialah apabila bilangan nod dalam rangkaian mengembang atau mengecut, hubungan pemetaan nod perlu dikira semula, menyebabkan keperluan untuk pemindahan data. Oleh itu, menggandakan kapasiti biasanya digunakan apabila mengembangkan kapasiti untuk mengelakkan semua pemetaan data terganggu dan menyebabkan pemindahan penuh Dengan cara ini, hanya 50% daripada data akan dipindahkan.
3. Algoritma Hash Konsisten
** Algoritma cincang yang konsisten telah dicadangkan oleh Karger dan rakan usaha samanya di MIT pada tahun 1997. Algoritma ini pada asalnya dicadangkan untuk pengimbangan beban sistem cache berskala besar. ** Proses kerjanya adalah seperti berikut, pertama, cincang dijana untuk nod cache berdasarkan IP atau maklumat lain, dan cincang diunjurkan ke gelang [0, 232 - 1]. Setiap kali terdapat pertanyaan atau permintaan tulis, nilai cincang dijana untuk kunci item cache. Seterusnya, anda perlu mencari nod pertama dalam nod cache dengan nilai cincang yang lebih besar daripada atau sama dengan nilai yang diberikan, dan melakukan pertanyaan cache atau operasi tulis pada nod ini. Apabila nod semasa tamat tempoh, pada pertanyaan atau tulis cache seterusnya, nod cache lain dengan cincang yang lebih besar daripada entri cache semasa boleh dicari. Kesan umum adalah seperti yang ditunjukkan dalam rajah di bawah Setiap nod cache menempati kedudukan pada gelang. Apabila nilai cincang kunci item cache kurang daripada nilai cincang nod cache, item cache akan disimpan atau dibaca daripada nod cache. Item cache yang sepadan dengan tanda hijau di bawah akan disimpan dalam cache-2 nod. Item cache pada asalnya sepatutnya disimpan dalam nod cache-3, tetapi disebabkan masa henti nod ini, ia akhirnya disimpan dalam nod cache-4.
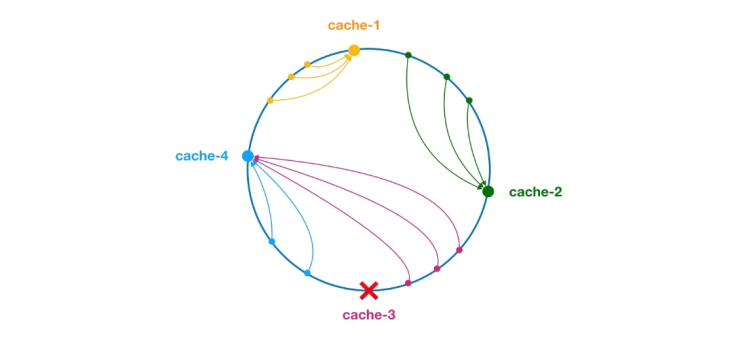
Figure 4 Algoritma hash yang konsisten dalam algoritma hash yang konsisten, sama ada nod ditambah atau ke bawah, julat yang terjejas hanya peningkatan atau downtime pelayan di ruang cincin hash. dalam arah lawan jam, selang lain tidak akan terjejas.
Tetapi pencincangan yang konsisten juga mempunyai masalah:
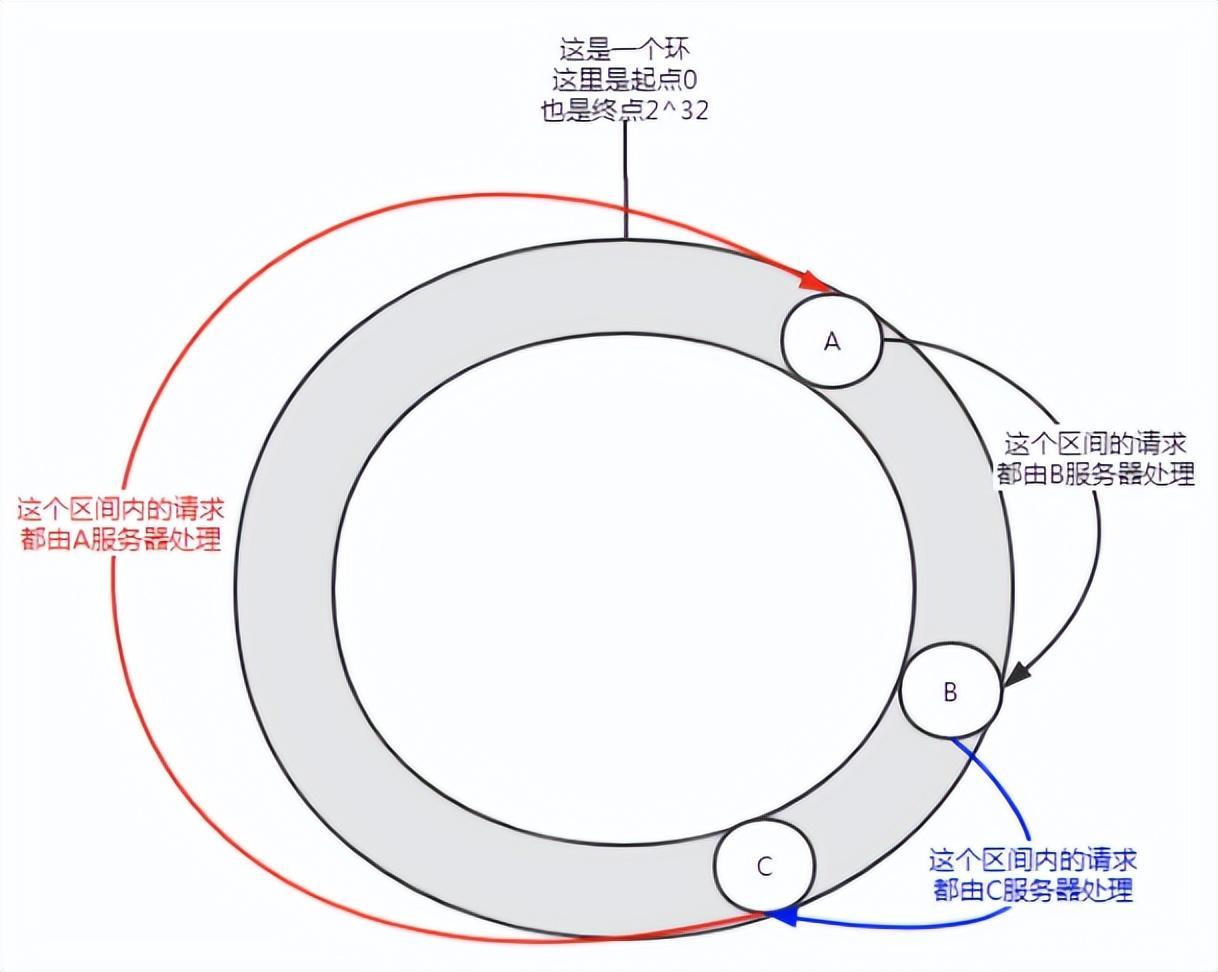 Rajah 5 Data condong
Rajah 5 Data condong
Apabila terdapat beberapa nod, pengedaran sedemikian mungkin berlaku, dan perkhidmatan A akan menanggung kebanyakan permintaan. Keadaan ini dipanggil data skew.
Jadi bagaimana untuk menyelesaikan masalah data skew?
Sertai nod maya.
Pertama sekali, pelayan boleh mempunyai berbilang nod maya mengikut keperluan. Katakan pelayan mempunyai n nod maya. Dalam pengiraan cincang, gabungan alamat IP, nombor port dan nombor boleh digunakan untuk mengira nilai cincang. Nombor itu ialah nombor dari 0 hingga n. N nod ini semua menghala ke mesin yang sama kerana ia berkongsi alamat IP dan nombor port yang sama.
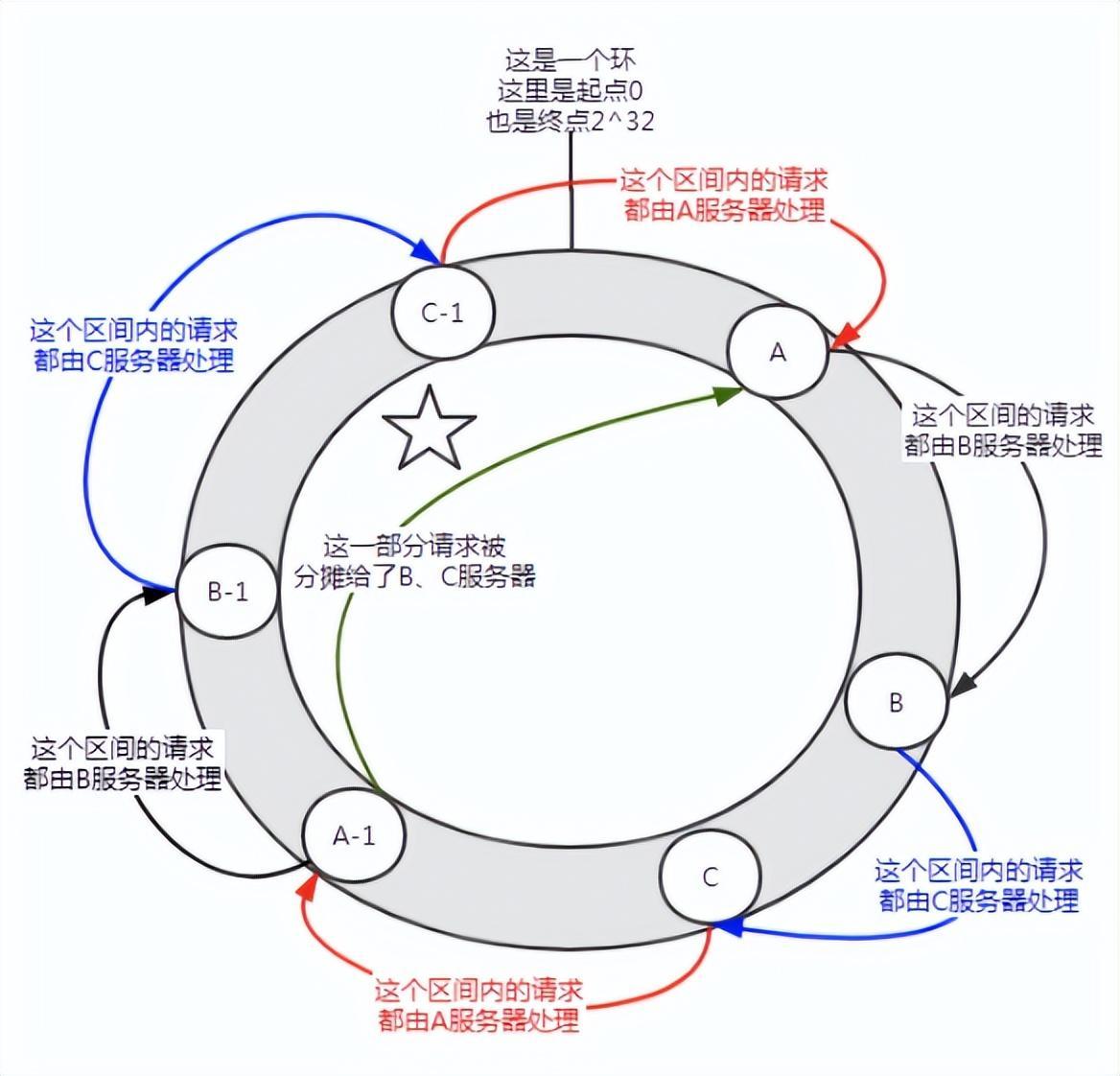 Rajah 6 Memperkenalkan nod maya
Rajah 6 Memperkenalkan nod maya
Sebelum menambah nod maya, pelayan A mengendalikan sebahagian besar permintaan. Jika setiap pelayan mempunyai nod maya (A-1, B-1, C-1) dan ditugaskan ke lokasi yang ditunjukkan dalam rajah di atas melalui pengiraan cincang. Kemudian permintaan yang dilakukan oleh pelayan A diperuntukkan kepada nod maya B-1 dan C-1 pada tahap tertentu (bahagian yang ditandakan dengan bintang berbucu lima dalam rajah), yang sebenarnya diperuntukkan kepada pelayan B dan C.
Dalam algoritma pencincangan yang konsisten, menambah nod maya boleh menyelesaikan masalah pencongan data.
4. Aplikasi pencincangan yang konsisten dalam DUBBO
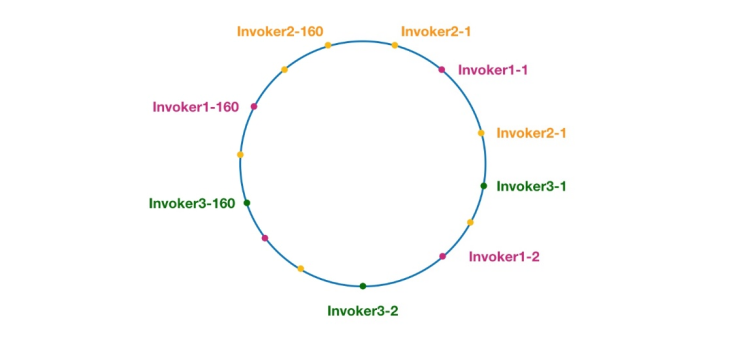 Rajah 7 Cincin pencincangan yang konsisten dalam Dubbo
Rajah 7 Cincin pencincangan yang konsisten dalam Dubbo
Nod dengan warna yang sama di sini semuanya dimiliki oleh pembekal perkhidmatan yang sama, seperti Invoker1-1, Invoker1-2 ,… Invoker1-160. Dengan menambah nod maya, kami boleh menyebarkan Invoker ke atas gelang cincang, dengan itu mengelakkan masalah pencongan data. Apa yang dipanggil data skew merujuk kepada keadaan di mana sejumlah besar permintaan jatuh pada nod yang sama kerana nod tidak tersebar cukup, manakala nod lain hanya menerima sebilangan kecil permintaan. Contohnya:
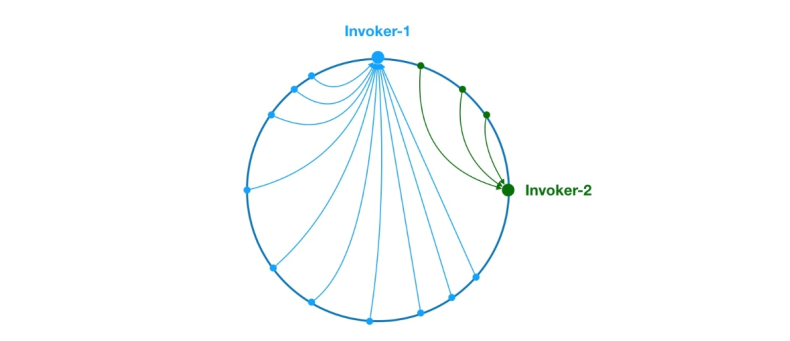 Rajah 8 Masalah pencongan data
Rajah 8 Masalah pencongan data
Seperti di atas, disebabkan pengagihan Invoker-1 dan Invoker-2 yang tidak sekata pada cincin, 75% permintaan dalam sistem akan jatuh pada Invoker-1, dan hanya 25% Permintaan akan jatuh pada Invoker-2. Untuk menyelesaikan masalah ini, nod maya boleh diperkenalkan untuk mengimbangi volum permintaan setiap nod.
Sekarang pengetahuan latar belakang telah dipopularkan, mari kita mula menganalisis kod sumber. Mari mulakan dengan kaedah doSelect ConsistentHashLoadBalance, seperti berikut:
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}}
Seperti di atas, kaedah doSelect terutamanya melakukan beberapa kerja persediaan, seperti mengesan sama ada senarai invoker telah berubah dan mencipta ConsistentHashSelector. Selepas tugasan ini selesai, kaedah pilih ConsistentHashSelector dipanggil untuk melaksanakan logik pengimbangan beban. Sebelum menganalisis kaedah pilih, mari kita lihat dahulu proses pemulaan pemilih cincang yang konsisten ConsistentHashSelector, seperti berikut:
private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}}
ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。注意到 ConsistentHashLoadBalance 无需考虑权重的影响。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。ConsistentHashSelector的初始化工作在此完成。接下来,我们来看看 select 方法的逻辑。
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();}
如上,选择的过程相对比较简单了。首先,需要对参数进行 md5 和 hash 运算,以生成一个哈希值。接着使用这个值去 TreeMap 中查找需要的 Invoker。
到此关于 ConsistentHashLoadBalance 就分析完了。
在阅读 ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。
五、应用场景
- DNS 负载均衡最早的负载均衡技术是通过 DNS 来实现的,在 DNS 中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。DNS 负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。
- 代理服务器负载均衡使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。
- 地址转换网关负载均衡支持负载均衡的地址转换网关,可以将一个外部 IP 地址映射为多个内部 IP 地址,对每次 TCP 连接请求动态使用其中一个内部地址,达到负载均衡的目的。
- 协议内部支持负载均衡除了这三种负载均衡方式之外,有的协议内部支持与负载均衡相关的功能,例如 HTTP 协议中的重定向能力等,HTTP 运行于 TCP 连接的最高层。
- NAT 负载均衡 NAT(Network Address Translation 网络地址转换)简单地说就是将一个 IP 地址转换为另一个 IP 地址,一般用于未经注册的内部地址与合法的、已获注册的 Internet IP 地址间进行转换。适用于解决 Internet IP 地址紧张、不想让网络外部知道内部网络结构等的场合下。
- 反向代理负载均衡普通代理方式是代理内部网络用户访问 internet 上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到 internet 上服务器的连接请求发送给代理服务器处理。反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。反向代理负载均衡技术是把将来自 internet 上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
- 混合型负载均衡在有些大型网络,由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。
作者:京东物流 乔杰
来源:京东云开发者社区
Atas ialah kandungan terperinci Strategi pengimbangan beban Dubbo pencincangan yang konsisten. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI