
Rumah >Peranti teknologi >AI >Kemiskinan menyediakan saya
Kemiskinan menyediakan saya

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-26 08:32:45856semak imbas
. Jika kaedah pra-latihan ini wujud, permulaannya memerlukan kuasa pengkomputeran, data dan sumber manual yang sangat sedikit, atau malah hanya korpus asal seorang dan satu kad. Selepas pemprosesan data tanpa pengawasan dan pemindahan pra-latihan ke domain anda sendiri, anda boleh mendapatkan NLG sampel, NLG dan keupayaan penaakulan vektor Keupayaan mengingat semula perwakilan vektor lain Adakah anda berminat untuk mencubanya.


Sama ada anda ingin melakukan sesuatu perlu diputuskan dengan mengukur input dan output. Pra-latihan adalah masalah besar dan memerlukan beberapa prasyarat dan sumber, serta faedah jangkaan yang mencukupi sebelum ia boleh dilaksanakan. Syarat yang biasanya diperlukan ialah: pembinaan korpus yang mencukupi Secara umumnya, kualiti adalah lebih jarang daripada kuantiti, jadi kualiti korpus boleh dilonggarkan, tetapi kuantiti mesti mencukupi, kedua, terdapat rizab bakat yang sepadan perbandingan, , model kecil lebih mudah untuk dilatih dan mempunyai halangan yang lebih sedikit, manakala model besar akan menghadapi lebih banyak masalah adalah sumber pengkomputeran Menurut senario dan padanan bakat, ia adalah yang terbaik untuk mempunyai kad grafik memori besar. Faedah yang dibawa oleh pra-latihan juga sangat intuitif Pemindahan model secara langsung boleh membawa kesan penambahbaikan secara langsung berkaitan dengan pelaburan pra-latihan dan perbezaan domain .
Dalam senario kami, medan data sangat berbeza daripada medan umum, malah perbendaharaan kata perlu diganti dengan ketara, dan skala perniagaan adalah mencukupi. Jika tidak dilatih terlebih dahulu, model itu juga akan diperhalusi khusus untuk setiap tugas hiliran. Manfaat yang dijangkakan daripada pra-latihan adalah pasti. Korpus kita kurang kualiti, tetapi cukup kuantiti. Sumber kuasa pengkomputeran adalah sangat terhad dan boleh diberi pampasan dengan memadankan rizab bakat yang sepadan. Pada masa ini, syarat untuk pra-latihan telah pun dipenuhi. 
Gambar di bawah adalah paradigma baharu yang kami cadangkan Apabila berhijrah ke bidang kami untuk meneruskan pra-latihan, kami menggunakan tugas pemodelan bahasa bersama dan tugas pembelajaran perbandingan untuk menjadikan model output mempunyai NLU sampel sifar, NLG, dan perwakilan vektor, keupayaan ini dimodelkan dan boleh diakses atas permintaan. Dengan cara ini, terdapat lebih sedikit model yang perlu diselenggara, terutamanya apabila projek dimulakan, ia boleh digunakan secara langsung untuk penyelidikan Jika penalaan lebih lanjut diperlukan, jumlah data yang diperlukan juga sangat berkurangan. .
Matlamat pra-latihan termasuk pemodelan bahasa dan perwakilan kontrastif Fungsi kehilangan ialah Total Loss = LM Loss + α CL Loss Ia dilatih bersama dengan tugas pemodelan bahasa dan tugas perwakilan kontras, di mana α mewakili pekali berat. Pemodelan bahasa menggunakan model topeng, serupa dengan T5, yang hanya menyahkod bahagian topeng. Tugas perwakilan kontras adalah serupa dengan CLIP Dalam kumpulan, terdapat sepasang sampel positif latihan yang berkaitan dan sampel bukan negatif lain Bagi setiap pasangan sampel (i, I) i, terdapat sampel positif I, dan yang lain sampel adalah sampel negatif , menggunakan kehilangan rentas entropi simetri untuk memaksa perwakilan sampel positif menjadi rapat dan perwakilan sampel negatif berada jauh. Menggunakan penyahkodan T5 boleh memendekkan panjang penyahkodan. Perwakilan vektor bukan linear diletakkan di atas pengekod pemuatan kepala Satu ialah perwakilan vektor diperlukan untuk menjadi lebih pantas dalam senario, dan satu lagi ialah dua fungsi yang ditunjukkan bertindak jauh untuk mengelakkan konflik sasaran latihan. Jadi di sini datang soalan tugas Cloze adalah sangat biasa dan tidak memerlukan sampel Jadi bagaimana pasangan sampel yang serupa berasal? 
Sudah tentu, sebagai kaedah pra-latihan, pasangan sampel mesti dilombong oleh algoritma tanpa pengawasan. Biasanya, kaedah asas yang digunakan dalam bidang pencarian maklumat untuk melombong sampel positif ialah reverse cloze, yang melombong beberapa serpihan dalam dokumen dan menganggap bahawa ia adalah berkaitan. Di sini kami membahagikan dokumen kepada ayat dan kemudian menghitung pasangan ayat. Kami menggunakan subrentetan biasa terpanjang untuk menentukan sama ada dua ayat berkaitan. Seperti yang ditunjukkan dalam rajah, dua pasangan ayat positif dan negatif diambil Jika subrentetan sepunya terpanjang cukup panjang pada tahap tertentu, ia dinilai serupa, jika tidak, ia tidak serupa. Ambang dipilih oleh anda sendiri Contohnya, ayat yang panjang memerlukan tiga aksara Cina, dan lebih banyak huruf Inggeris diperlukan Ayat pendek boleh menjadi lebih santai.
Kami menggunakan korelasi sebagai pasangan sampel dan bukannya kesetaraan semantik kerana kedua-dua matlamat itu bercanggah. Seperti yang ditunjukkan dalam rajah di atas, maksud kucing menangkap tikus dan tikus menangkap kucing adalah bertentangan tetapi berkaitan. Carian senario kami tertumpu terutamanya pada perkaitan. Selain itu, korelasi adalah lebih luas daripada kesetaraan semantik, dan kesetaraan semantik lebih sesuai untuk penalaan halus berterusan berdasarkan korelasi.
Sesetengah ayat ditapis beberapa kali, dan sesetengah ayat tidak ditapis. Kami mengehadkan kekerapan ayat yang dipilih. Bagi ayat yang tidak berjaya, ia boleh disalin sebagai sampel positif, disambung ke dalam ayat yang dipilih, atau kloz terbalik boleh digunakan sebagai sampel positif.
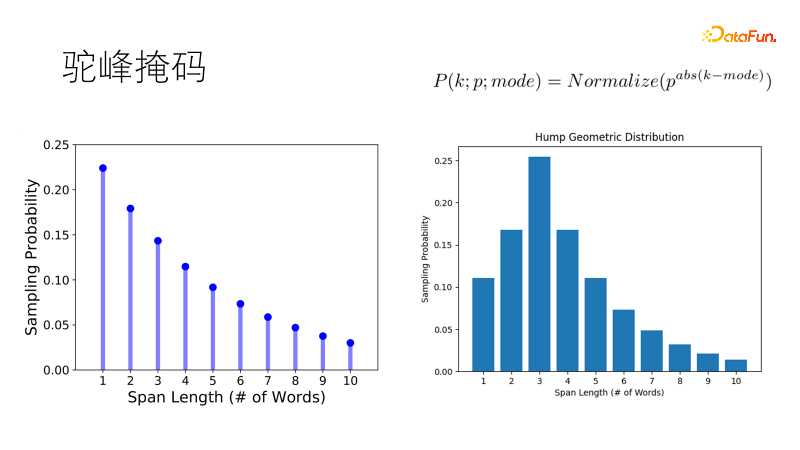
Kaedah penyamaran tradisional seperti SpanBert menggunakan taburan geometri untuk sampel panjang topeng mempunyai kebarangkalian tinggi dan topeng panjang mempunyai kebarangkalian yang rendah, dan sesuai untuk ayat yang panjang. Tetapi korpus kita berpecah-belah Apabila berhadapan dengan ayat pendek satu atau dua puluh perkataan, kecenderungan tradisional adalah menutup dua perkataan tunggal dan bukannya satu kata ganda, yang tidak memenuhi jangkaan kita. Jadi kami menambah baik taburan ini supaya ia mempunyai kebarangkalian tertinggi untuk mengambil sampel panjang optimum, dan kebarangkalian panjang lain secara beransur-ansur berkurangan, sama seperti bonggol unta, menjadi taburan geometri bonggol unta, yang lebih mantap dalam ayat pendek kami- senario yang kaya.
3. Keputusan eksperimen
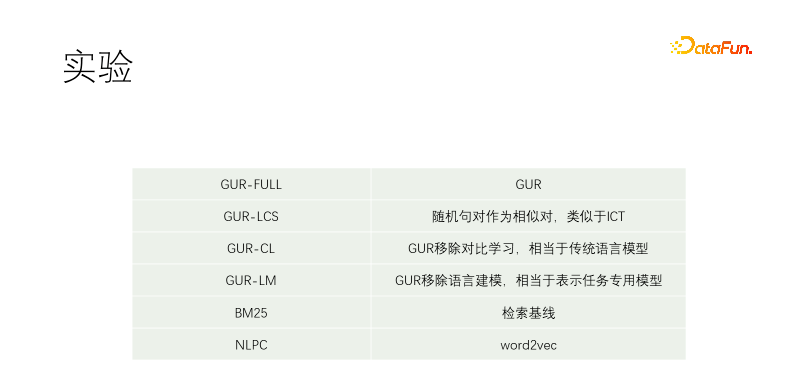
Kami menjalankan eksperimen terkawal. Termasuk GUR-FULL, yang menggunakan pemodelan bahasa dan perwakilan kontrastif vektor; pasangan sampel UR-LCS tidak ditapis oleh LCS tidak mempunyai pembelajaran perwakilan kontras, yang setara dengan model bahasa tradisional GUR-LM sahaja; pembelajaran perwakilan kontras, tanpa pembelajaran pemodelan bahasa, adalah setara dengan penalaan halus khusus untuk tugas hiliran NLPC ialah operator word2vec dalam Baidu.
Percubaan bermula dengan T5-kecil dan pra-latihan berterusan. Korpora latihan termasuk Wikipedia, Wikisource, CSL dan korpora kami sendiri. Korpus kami sendiri ditangkap dari perpustakaan bahan, dan kualitinya sangat buruk Bahagian kualiti terbaik ialah tajuk perpustakaan bahan. Oleh itu, apabila menggali sampel positif dalam dokumen lain, hampir mana-mana pasangan teks disaring, manakala dalam korpus kami, tajuk digunakan untuk memadankan setiap ayat teks. GUR-LCS belum dipilih oleh LCS Jika ia tidak dilakukan dengan cara ini, pasangan sampel akan menjadi terlalu buruk Jika ia dilakukan dengan cara ini, perbezaan dengan GUR-FULL akan menjadi lebih kecil.
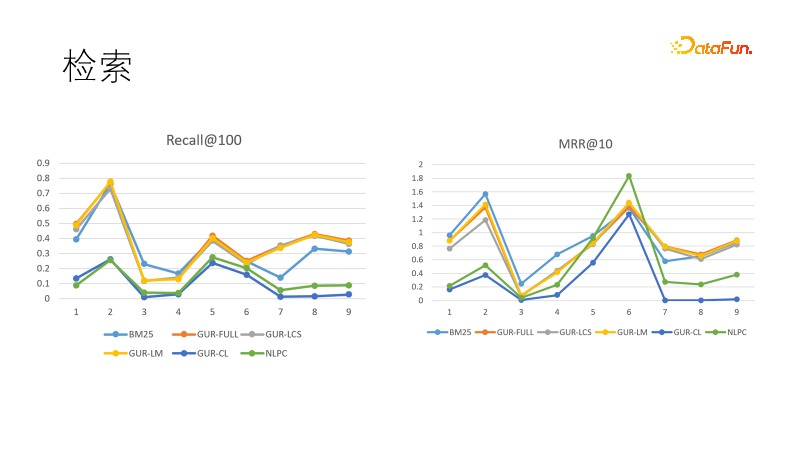
Kami menilai kesan perwakilan vektor model pada beberapa tugas mendapatkan semula. Gambar di sebelah kiri menunjukkan prestasi beberapa model dalam ingatan Kami mendapati bahawa model yang dipelajari melalui perwakilan vektor menunjukkan prestasi terbaik, mengatasi prestasi BM25. Kami juga membandingkan sasaran kedudukan, dan kali ini BM25 kembali untuk menang. Ini menunjukkan bahawa model padat mempunyai keupayaan generalisasi yang kuat dan model jarang mempunyai determinisme yang kuat, dan kedua-duanya boleh saling melengkapi. Malah, dalam tugas hiliran dalam bidang pencarian maklumat, model padat dan model jarang sering digunakan bersama.
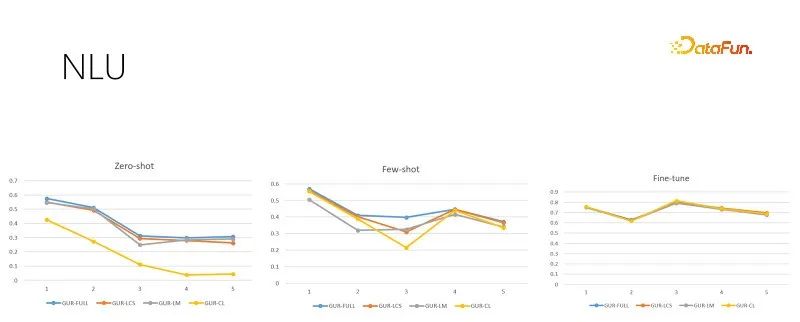
Gambar di atas adalah tugas penilaian NLU dengan saiz sampel latihan yang berbeza Setiap tugasan mempunyai berpuluh-puluh hingga ratusan kategori, dan skor ACC digunakan untuk menilai kesannya. Model GUR juga menukar label klasifikasi kepada vektor untuk mencari label terdekat bagi setiap ayat. Rajah di atas dari kiri ke kanan menunjukkan sampel sifar, sampel kecil dan penilaian penalaan halus yang mencukupi mengikut saiz sampel latihan yang semakin meningkat. Gambar di sebelah kanan ialah prestasi model selepas penalaan halus yang mencukupi, yang menunjukkan kesukaran setiap sub-tugas dan juga merupakan siling prestasi sampel sifar dan sampel kecil. Ia boleh dilihat bahawa model GUR boleh mencapai penaakulan sampel sifar dalam beberapa tugas klasifikasi dengan bergantung pada perwakilan vektor. Dan keupayaan sampel kecil model GUR adalah yang paling cemerlang.
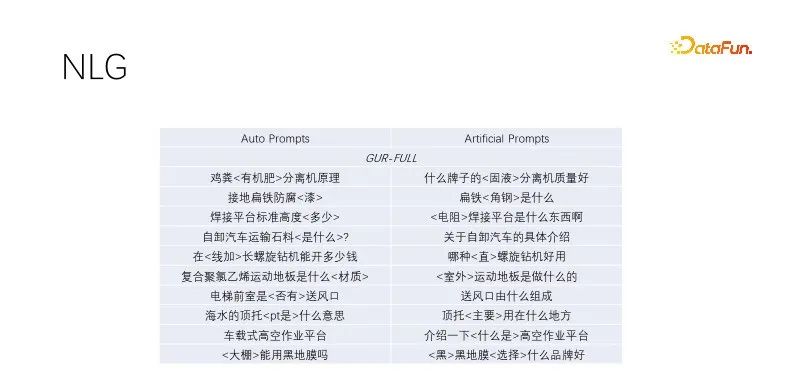
Ini ialah prestasi sampel sifar dalam NLG. Apabila kami melakukan penjanaan tajuk dan pengembangan pertanyaan, kami melombong tajuk dengan trafik berkualiti tinggi, mengekalkan kata kunci dan secara rawak menutup bukan kata kunci Model yang dilatih oleh pemodelan bahasa berprestasi baik. Kesan segera automatik ini serupa dengan kesan sasaran yang dibina secara manual, dengan kepelbagaian yang lebih luas dan mampu memenuhi pengeluaran besar-besaran. Beberapa model yang telah menjalani tugas pemodelan bahasa melakukan yang sama Rajah di atas menggunakan contoh model GUR.
4. Kesimpulan
Artikel ini mencadangkan paradigma pra-latihan baharu Eksperimen kawalan di atas menunjukkan bahawa latihan bersama tidak akan menyebabkan konflik matlamat. Apabila model GUR terus dilatih, ia boleh meningkatkan keupayaan perwakilan vektornya sambil mengekalkan keupayaan pemodelan bahasanya. Pra-latihan sekali, inferens dengan sifar sampel asal di mana-mana. Sesuai untuk pra-latihan kos rendah untuk jabatan perniagaan.

Pautan di atas merekodkan butiran latihan kami Untuk butiran rujukan, lihat petikan kertas itu. Saya berharap dapat memberikan sedikit sumbangan kepada pendemokrasian AI. Model besar dan kecil mempunyai senario aplikasi mereka sendiri Selain digunakan secara langsung untuk tugas hiliran, model GUR juga boleh digunakan bersama dengan model besar. Dalam perancangan, kami mula-mula menggunakan model kecil untuk pengecaman dan kemudian menggunakan model besar untuk mengarahkan tugasan Model besar juga boleh menghasilkan sampel untuk model kecil, dan model kecil GUR boleh menyediakan pengambilan vektor untuk model besar.
Model dalam kertas ialah model kecil yang dipilih untuk meneroka berbilang percubaan Secara praktikal, jika model yang lebih besar dipilih, keuntungan akan jelas. Penerokaan kami tidak mencukupi dan kerja lanjut diperlukan Jika anda bersedia, anda boleh menghubungi laohur@gmail.com dan berharap untuk membuat kemajuan bersama-sama dengan semua orang.
Atas ialah kandungan terperinci Kemiskinan menyediakan saya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI