
Rumah >Peranti teknologi >AI >Meta mengeluarkan model AI audio yang menyerupai pertuturan orang sebenar dalam masa 2 saat sahaja
Meta mengeluarkan model AI audio yang menyerupai pertuturan orang sebenar dalam masa 2 saat sahaja

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-21 15:20:171755semak imbas
Baru-baru ini, Meta mengeluarkan model AI Voicebox, yang mempunyai kelebihan ketara dalam simulasi audio.
Dilaporkan bahawa Voicebox hanya memerlukan sampel audio 2 saat untuk mengenal pasti butiran audio dan timbre dengan tepat, dan menukarnya kepada output pertuturan berdasarkan hasil teks.

Voicebox ialah model AI generatif yang membantu dengan penyuntingan audio, pensampelan dan penggayaan.
Teknologi ini boleh digunakan untuk membantu pencipta mengedit trek audio dengan mudah pada masa yang sama, pada masa yang sama, ia juga boleh memberikan bantuan kepada orang yang mempunyai pita suara yang rosak dan membantu mereka "membunyikan" semula. Membolehkan orang cacat penglihatan mendengar mesej bertulis rakan mereka melalui bunyi, sambil membolehkan orang bercakap apa-apa bahasa asing dengan suara mereka sendiri.
Pada masa yang sama, ia juga boleh mengisi kandungan yang hilang secara automatik berdasarkan kandungan sebelumnya dan seterusnya bagi klip suara.
Menurut Meta, Voicebox boleh memberikan kesan suara yang semula jadi dan realistik untuk pembantu AI atau NPC dalam metaverse akan datang, dengan banyak meningkatkan rendaman pengguna apabila menggunakannya.
Kepelbagaian Voicebox menyokong pelbagai tugas, termasuk:
Sintesis teks ke pertuturan kontekstual: Menggunakan sampel audio sesingkat dua saat, Kotak Suara boleh memadankan gaya audio dan menggunakannya untuk penjanaan teks ke pertuturan.
Pengeditan Suara dan Pengurangan Bunyi: Kotak suara boleh mencipta semula bahagian pertuturan yang terganggu oleh hingar atau menggantikan perkataan yang tersalah tutur tanpa perlu merakam semula keseluruhan pertuturan. Contohnya, anda boleh mengenal pasti segmen pertuturan yang diganggu oleh anjing menyalak, memangkasnya dan kemudian mengarahkan Voicebox untuk menjana semula segmen itu—seperti pemadam untuk pengeditan audio.
Penukaran merentas bahasa: Apabila diberi sampel ucapan seseorang dan teks dalam bahasa Inggeris, Perancis, Jerman, Sepanyol, Poland atau Portugis, Voicebox boleh menjana bacaan teks dalam mana-mana bahasa ini, walaupun contoh ucapan dan teks adalah bahasa yang berbeza. Pada masa hadapan, orang akan dapat menggunakan ciri ini untuk berkomunikasi dengan cara yang lebih semula jadi dan tulen, walaupun mereka tidak memahami bahasa tersebut.
Pemadanan aliran ialah kaedah yang digunakan oleh Kotak Suara yang telah ditunjukkan untuk meningkatkan prestasi model resapan. Kotak suara mengatasi VALL-E, model Inggeris terkini, dalam kebolehfahaman (5.9% lwn. 1.9% kadar ralat perkataan) dan persamaan audio (0.580 lwn. 0.681), sambil 20x lebih pantas. Untuk pemindahan gaya merentas bahasa, Voicebox mengatasi YourTTS, mengurangkan purata kadar ralat perkataan daripada 10.9% kepada 5.2% dan meningkatkan persamaan audio daripada 0.335 kepada 0.481.
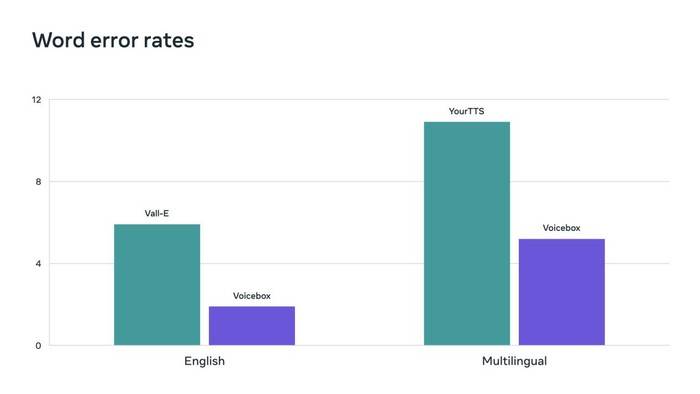
Peti suara mencapai hasil tercanggih baharu, mengatasi prestasi Vall-E dan YourTTS dalam kadar ralat perkataan.
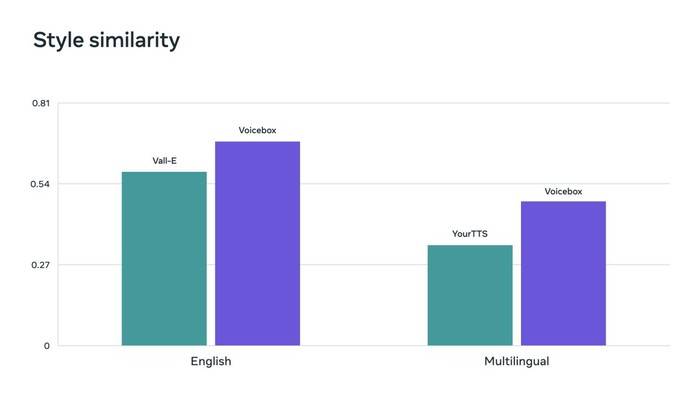
Kotak suara juga mencapai hasil terkini pada metrik persamaan gaya audio masing-masing dalam bahasa Inggeris dan penanda aras berbilang bahasa.
Perlu dinyatakan bahawa Meta pada masa ini menyedari potensi bahaya yang wujud apabila Voicebox digunakan dalam bidang pemalsuan, jadi mereka mencari cara untuk membezakan suara sebenar daripada suara yang dijana Voicebox.
Sehingga penyelesaian ditemui, Meta tidak akan mendedahkan model AI Voicebox kepada orang ramai untuk mengelakkan bahaya yang tidak perlu.
Komen editor: AI kini telah digunakan dalam pelbagai bidang Sebagai model berbilang fungsi dan cekap pertama yang berjaya melaksanakan generalisasi tugas, saya percaya Voicebox boleh memulakan era baharu AI penjanaan pertuturan. Jika Meta tidak dapat menangani penipuan audio dengan berkesan, teknologi Voicebox mungkin dilumpuhkan.
Atas ialah kandungan terperinci Meta mengeluarkan model AI audio yang menyerupai pertuturan orang sebenar dalam masa 2 saat sahaja. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI