
Rumah >Peranti teknologi >AI >'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer
'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer

- 王林ke hadapan
- 2023-06-14 13:43:171616semak imbas
Beberapa masa lalu, tweet yang menunjukkan ketidakkonsistenan antara gambar rajah seni bina Transformer dan kod dalam kertas kerja pasukan Google Brain "Perhatian Adalah Semua yang Anda Perlukan" mencetuskan banyak perbincangan.
Sesetengah orang berpendapat bahawa penemuan Sebastian adalah kesilapan yang jujur, tetapi ia juga pelik. Lagipun, memandangkan populariti kertas Transformer, ketidakkonsistenan ini sepatutnya disebut seribu kali.
Sebastian Raschka berkata sebagai respons kepada komen netizen bahawa kod "paling asli" memang konsisten dengan gambar rajah seni bina, tetapi versi kod yang diserahkan pada 2017 telah diubah suai, tetapi seni binanya tidak dikemas kini pada masa yang sama. Ini juga punca perbincangan "tidak konsisten".
Seterusnya, Sebastian menerbitkan artikel mengenai Ahead of AI secara khusus menerangkan sebab gambar rajah seni bina Transformer yang asal tidak konsisten dengan kod, dan memetik beberapa kertas untuk menerangkan secara ringkas perkembangan dan perubahan Transformer.
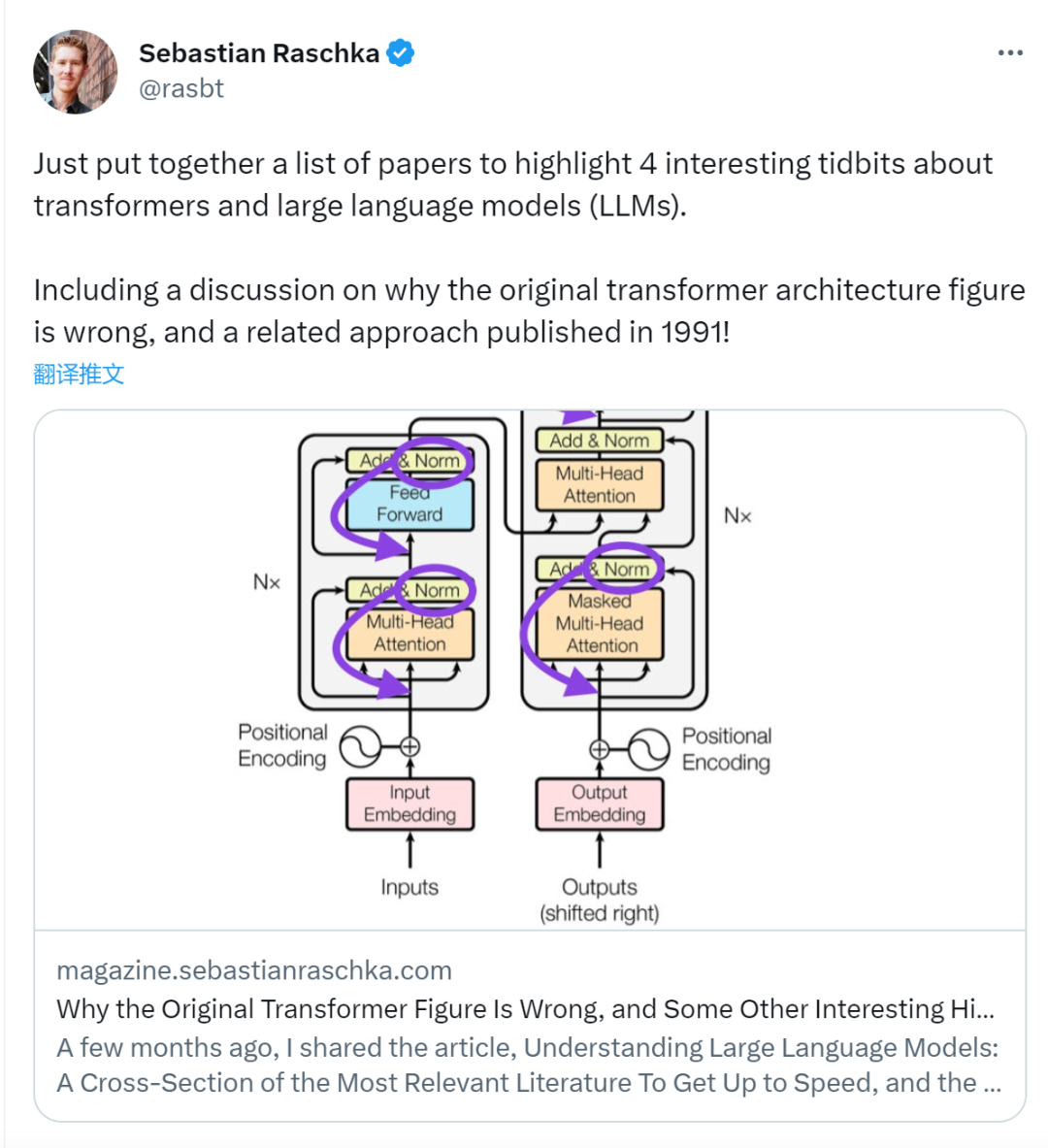
Berikut ialah teks asal artikel tersebut, mari kita lihat tentang maksud artikel tersebut:
Pada masa yang sama, adalah penting untuk memastikan senarai itu ringkas dan padat supaya semua orang dapat mencapai kelajuan dalam tempoh masa yang munasabah. Terdapat juga beberapa kertas yang mengandungi banyak maklumat dan mungkin perlu disertakan.
Saya ingin berkongsi empat kertas kerja yang berguna untuk memahami Transformer dari perspektif sejarah. Walaupun saya hanya menambahnya terus pada artikel Memahami Model Bahasa Besar, saya juga berkongsinya secara berasingan dalam artikel ini supaya ia lebih mudah ditemui oleh mereka yang telah membaca Memahami Model Bahasa Besar sebelum ini.
On Layer Normalization in the Transformer Architecture (2020)
Walaupun imej asal Transformer dalam gambar di bawah (kiri) (https://arxiv.org/abs/1706.03762) ialah ringkasan berguna seni bina penyahkod pengekod asal, tetapi terdapat sedikit perbezaan dalam rajah. Sebagai contoh, ia melakukan normalisasi lapisan antara blok baki, yang tidak sepadan dengan pelaksanaan kod rasmi (dikemas kini) yang disertakan dengan kertas Transformer asal. Varian yang ditunjukkan di bawah (tengah) dipanggil Transformer Pasca-LN.
Penormalan lapisan dalam kertas seni bina Transformer menunjukkan bahawa Pra-LN berfungsi dengan lebih baik dan boleh menyelesaikan masalah kecerunan seperti yang ditunjukkan di bawah. Banyak seni bina menggunakan pendekatan ini dalam amalan, tetapi ia boleh membawa kepada pecahan dalam perwakilan.
Jadi, sementara masih ada perbincangan mengenai penggunaan Pasca-LN atau Pra-LN, terdapat juga kertas kerja baharu yang mencadangkan untuk memohon kedua-duanya bersama-sama: "ResiDual: Transformer with Dual Residual Connections" (https://arxiv.org/abs/2304.14802), tetapi sama ada ia berguna dalam amalan masih belum diketahui.
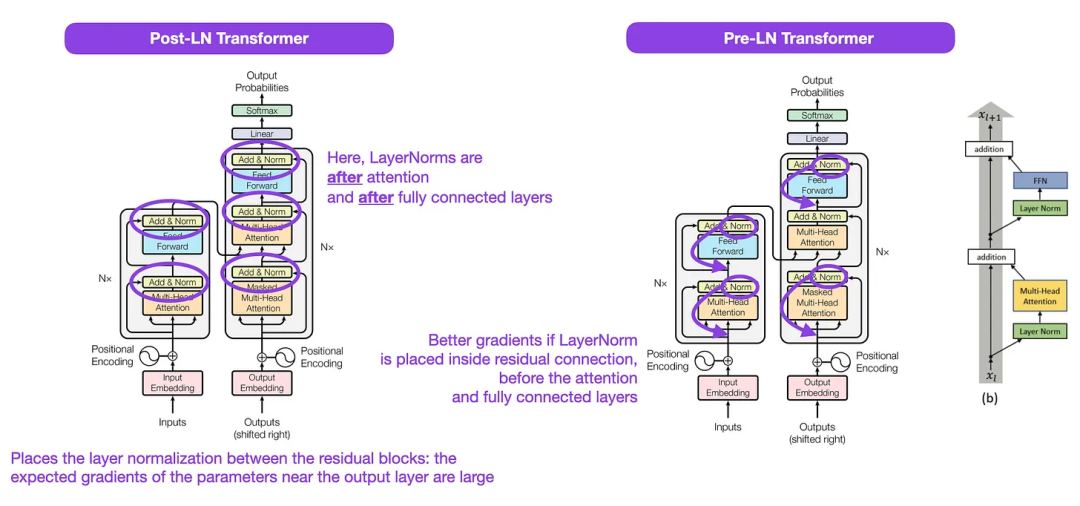 Ilustrasi: Sumber https://arxiv.org/abs/1706.03762 ( Kiri & Center) dan https://arxiv.org/abs/2002.04745 (kanan)
Ilustrasi: Sumber https://arxiv.org/abs/1706.03762 ( Kiri & Center) dan https://arxiv.org/abs/2002.04745 (kanan)
Belajar Mengawal Kenangan Berat Pantas: Alternatif kepada Rangkaian Neural Berulang Dinamik (1991)
Artikel ini disyorkan untuk mereka yang berminat dengan berita-berita sejarah dan kaedah awal yang pada asasnya serupa dengan Transformer moden.
Sebagai contoh, pada tahun 1991, 25 tahun sebelum kertas Transformer, Juergen Schmidhuber mencadangkan alternatif kepada rangkaian saraf berulang (https://www.semanticscholar.org/paper/Learning-to-Control- Fast-Weight -Memories%3A-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922), dipanggil Fast Weight Programmers (FWP). Satu lagi rangkaian saraf yang mencapai perubahan berat yang pantas ialah rangkaian saraf suapan yang terlibat dalam kaedah FWP yang belajar secara perlahan menggunakan algoritma penurunan kecerunan.
Blog ini (https://people.idsia.ch//~juergen/fast-weight-programmer-1991-transformer.html#sec2) membandingkannya dengan Transformer moden The analogi adalah seperti berikut:
Dalam terminologi Transformer hari ini, FROM dan TO dipanggil kunci dan nilai masing-masing. Input yang digunakan rangkaian pantas dipanggil pertanyaan. Pada asasnya, pertanyaan dikendalikan oleh matriks berat pantas, iaitu jumlah produk luar kunci dan nilai (mengabaikan penormalan dan unjuran). Kita boleh menggunakan produk luar tambahan atau produk tensor pesanan kedua untuk mencapai kawalan aktif boleh dibezakan hujung ke hujung terhadap perubahan pantas dalam pemberat kerana semua operasi kedua-dua rangkaian menyokong pembezaan. Semasa pemprosesan jujukan, keturunan kecerunan boleh digunakan untuk menyesuaikan rangkaian pantas dengan cepat kepada masalah rangkaian perlahan. Ini secara matematik bersamaan dengan (kecuali untuk normalisasi) apa yang dikenali sebagai Transformer dengan perhatian kendiri linear (atau Transformer linear).
Seperti yang dinyatakan dalam petikan di atas, pendekatan ini kini dikenali sebagai Linear Transformer atau Transformer dengan linearized self-attention. Ia datang daripada makalah "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention" (https://arxiv.org/abs/2006.16236) dan "Rethinking Attention with Performers" (https://arxiv. org/abs/2009.14794) .
Pada tahun 2021, makalah "Linear Transformers Are Secretly Fast Weight Programmers" (https://arxiv.org/abs/2102.11174) dengan jelas menunjukkan bahawa perhatian diri linear dan Persamaan 1990-an antara pengaturcara berat pantas.
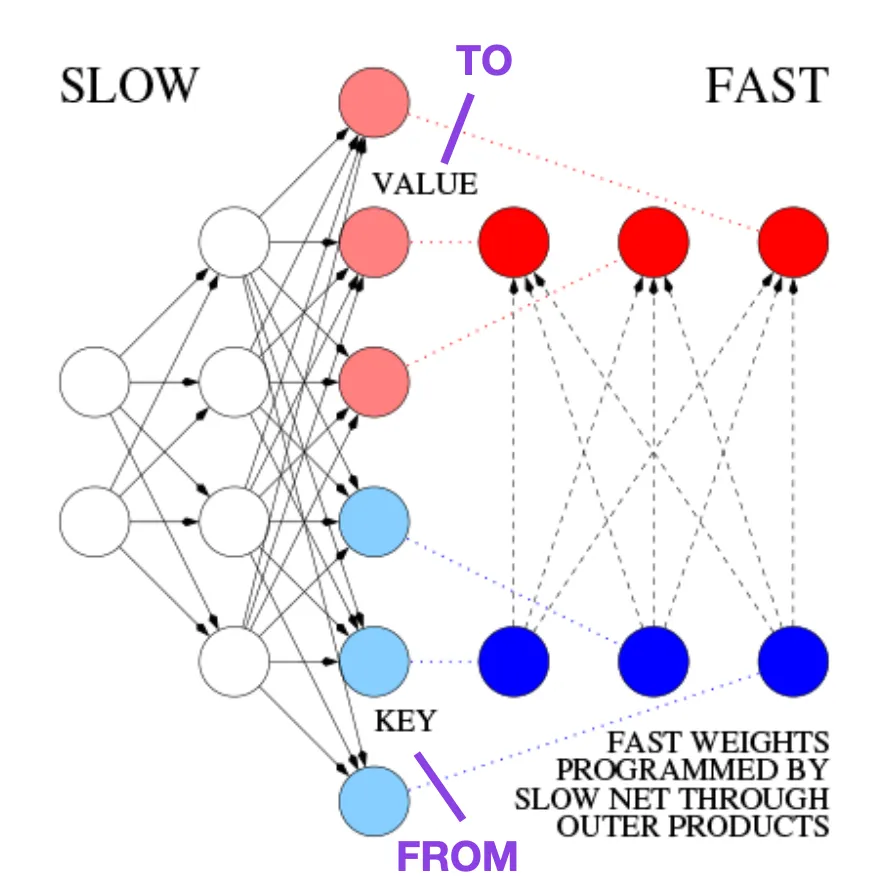
Sumber imej: https://people.idsia.ch// ~juergen/fast-weight-programmer-1991-transformer.html#sec2
Penalaan Halus Model Bahasa Universal untuk Klasifikasi Teks (2018)
Ini adalah satu lagi kertas kerja yang sangat menarik dari perspektif sejarah. Ia ditulis setahun selepas keluaran asal Attention Is All You Need, dan tidak melibatkan transformer, sebaliknya memfokuskan pada rangkaian saraf berulang, tetapi ia masih berbaloi untuk ditonton. Kerana ia secara berkesan mencadangkan model bahasa pra-latihan dan tugas hiliran pembelajaran pemindahan. Walaupun pembelajaran pemindahan sudah mantap dalam penglihatan komputer, ia masih belum menjadi popular dalam bidang pemprosesan bahasa semula jadi (NLP). ULMFit (https://arxiv.org/abs/1801.06146) ialah salah satu kertas kerja pertama yang menunjukkan bahawa model bahasa pra-latihan boleh menghasilkan hasil SOTA pada banyak tugas NLP apabila diperhalusi pada tugas tertentu.
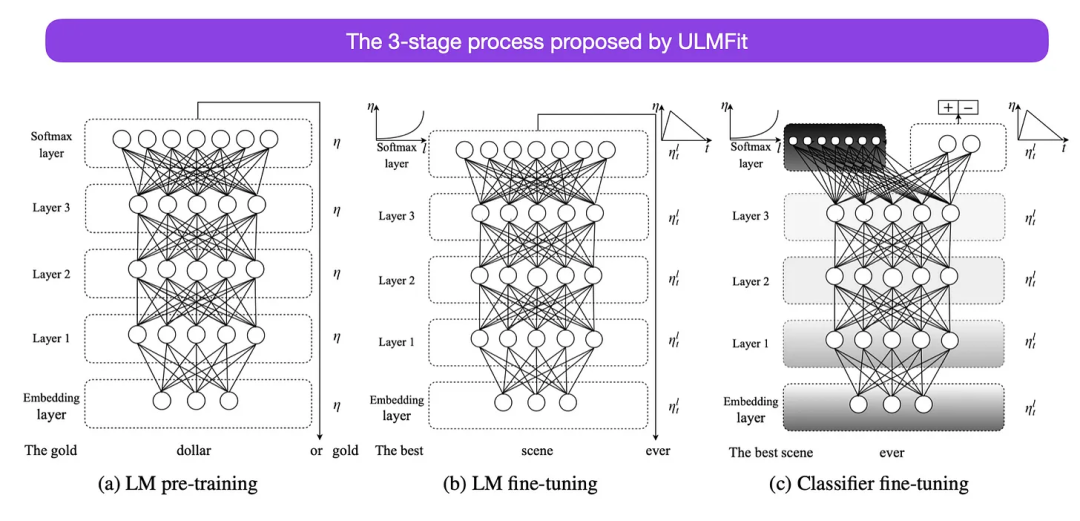
Proses penalaan model bahasa yang dicadangkan oleh ULMFit dibahagikan kepada tiga peringkat:
- 1 Model korpus;
- 2. Perhalusi model bahasa yang telah dilatih berdasarkan data khusus tugasan supaya dapat menyesuaikan diri dengan gaya dan perbendaharaan kata tertentu;
- 3. Perhalusi pengelas pada data khusus tugas untuk mengelakkan pelupaan bencana dengan menyahbekukan lapisan secara beransur-ansur.
Kaedah melatih model bahasa pada korpus besar dan kemudian memperhalusinya pada tugas hiliran adalah berdasarkan model Transformer dan model asas (seperti BERT, GPT - 2/3/4, RoBERTa, dsb.).
Walau bagaimanapun, sebagai bahagian penting ULMFiT, penyahbekuan progresif biasanya tidak dilakukan dalam amalan, kerana seni bina Transformer biasanya memperhalusi semua lapisan sekaligus.
Gopher ialah kertas kerja yang sangat bagus (https://arxiv.org/abs/2112.11446) yang merangkumi analisis yang meluas untuk memahami latihan LLM. Para penyelidik melatih model parameter 80-lapisan, 280 bilion pada 300 bilion token. Ini termasuk beberapa pengubahsuaian seni bina yang menarik, seperti menggunakan RMSNorm (root mean square normalization) dan bukannya LayerNorm (layer normalization). Kedua-dua LayerNorm dan RMSNorm adalah lebih baik daripada BatchNorm kerana ia tidak terhad kepada saiz kelompok dan tidak memerlukan penyegerakan, yang merupakan kelebihan dalam tetapan teragih dengan saiz kelompok yang lebih kecil. RMSNorm biasanya dianggap menstabilkan latihan dalam seni bina yang lebih mendalam.
Selain daripada berita-berita menarik di atas, fokus utama artikel ini adalah untuk menganalisis analisis prestasi tugasan pada skala yang berbeza. Penilaian ke atas 152 tugasan yang berbeza menunjukkan bahawa peningkatan saiz model adalah paling berfaedah untuk tugasan seperti kefahaman, semakan fakta dan mengenal pasti bahasa toksik, manakala pengembangan seni bina kurang berfaedah untuk tugasan yang berkaitan dengan penaakulan logik dan matematik.
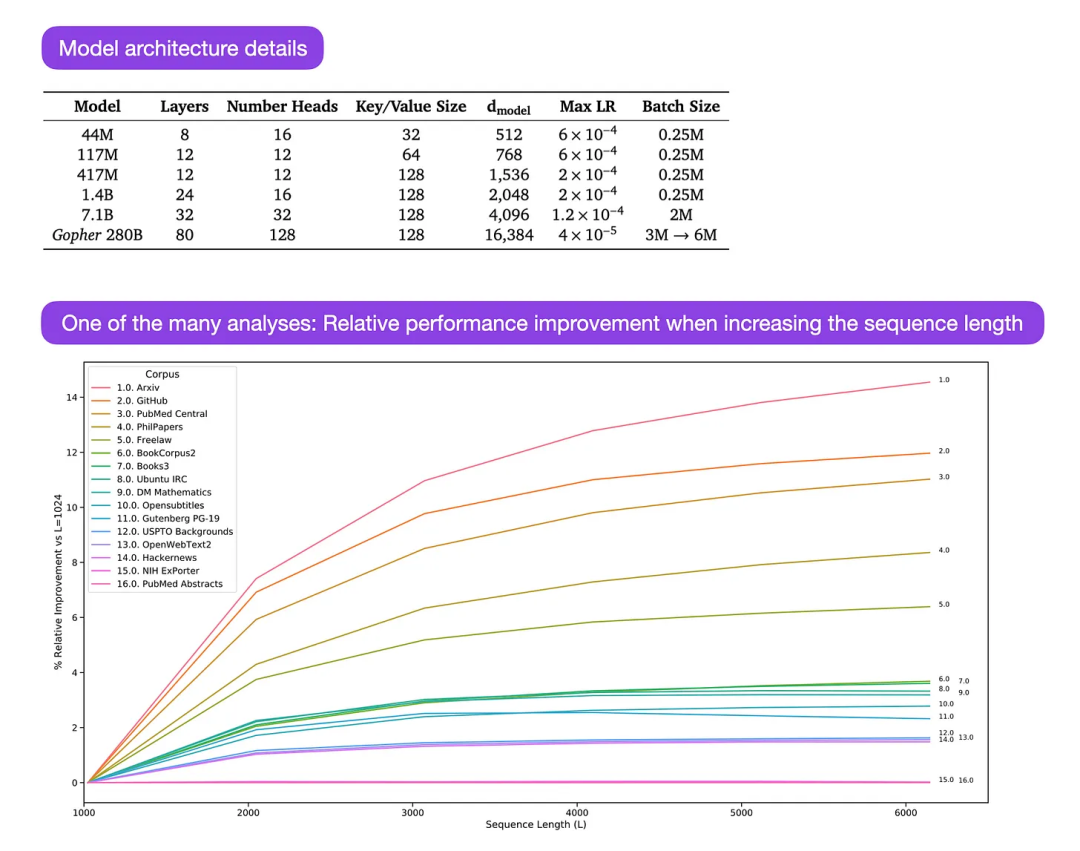
Kapsyen imej: Sumber https://arxiv.org/abs/2112.11446
Atas ialah kandungan terperinci 'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI