

 Peranti teknologiAITeks sumber terbuka meta menjana model muzik yang besar Kami mencubanya dengan lirik 'Qilixiang'.
Peranti teknologiAITeks sumber terbuka meta menjana model muzik yang besar Kami mencubanya dengan lirik 'Qilixiang'.Teks sumber terbuka meta menjana model muzik yang besar Kami mencubanya dengan lirik 'Qilixiang'.

Sebelum memasukkan teks utama, mari dengar dua keping muzik yang dijana oleh MusicGen. Kami memasukkan keterangan teks "seorang lelaki berjalan dalam hujan, berjumpa dengan seorang gadis cantik, dan mereka menari dengan gembira"
dan kemudian cuba masukkan dua ayat pertama daripada lirik Jay "Qili Xiang" Chou "Di luar tingkap" Burung pipit bercakap di tiang telefon Anda mengatakan ayat ini sangat seperti musim panas" (Bahasa Cina disokong)
Alamat percubaan: https://huggingface.co/spaces /facebook/MusicGen
Teks kepada muzik merujuk kepada tugas menjana karya muzik yang diberi penerangan teks, seperti "90an riff gitar lagu rock". Menjana muzik melibatkan pemodelan urutan panjang sebagai tugas yang mencabar. Tidak seperti pertuturan, muzik memerlukan penggunaan spektrum penuh, yang bermaksud isyarat diambil pada kadar yang lebih tinggi, iaitu kadar pensampelan standard untuk rakaman muzik ialah 44.1 kHz atau 48 kHz, manakala pertuturan diambil sampel pada 16 kHz.
Selain itu, muzik mengandungi harmoni dan melodi instrumen yang berbeza, yang memberikan muzik struktur yang kompleks. Tetapi kerana pendengar manusia sangat sensitif terhadap disonansi, mereka tidak mempunyai banyak toleransi untuk melodi dalam muzik yang dihasilkan. Sudah tentu, keupayaan untuk mengawal proses penjanaan dalam pelbagai cara adalah penting untuk pencipta muzik, seperti kunci, instrumen, melodi, genre, dll.
Kemajuan terkini dalam pembelajaran perwakilan audio yang diselia sendiri, pemodelan jujukan dan sintesis audio menyediakan syarat untuk membangunkan model sedemikian. Untuk menjadikan pemodelan audio lebih mudah, penyelidikan baru-baru ini mencadangkan untuk mewakili isyarat audio sebagai aliran token diskret yang "mewakili isyarat yang sama." Ini membolehkan penjanaan audio berkualiti tinggi dan pemodelan audio yang cekap. Walau bagaimanapun ini memerlukan pemodelan bersama beberapa aliran pergantungan selari.
Kharitonov et al [2022], Kreuk et al [2022] mencadangkan untuk menggunakan kaedah kelewatan untuk memodelkan berbilang aliran token pertuturan secara selari, iaitu, memperkenalkan offset antara berbeza. aliran. Agostinelli et al. [2023] mencadangkan menggunakan jujukan token diskret berbilang butiran berbeza untuk mewakili serpihan muzik dan memodelkannya menggunakan hierarki model autoregresif. Sementara itu, Donahue et al [2023] menggunakan pendekatan yang sama tetapi menyasarkan tugas nyanyian kepada generasi iringan. Baru-baru ini, Wang et al [2023] mencadangkan untuk menyelesaikan masalah ini dalam dua peringkat: menyekat pemodelan kepada aliran token pertama. Selepas rangkaian kemudian digunakan untuk memodelkan aliran baki secara bersama dalam cara bukan autoregresif.
Dalam artikel ini, penyelidik Meta AI mencadangkan MUSICGEN, model penjanaan muzik yang mudah dan boleh dikawal yang boleh menjana muzik berkualiti tinggi dengan penerangan teks.

Alamat kertas: https: //arxiv.org/pdf/2306.05284.pdf
Para penyelidik mencadangkan rangka kerja umum untuk memodelkan berbilang aliran token akustik selari sebagai generalisasi penyelidikan terdahulu (Lihat Rajah 1) di bawah. Untuk meningkatkan kebolehkawalan sampel yang dijana, kertas kerja ini juga memperkenalkan keadaan melodi tanpa pengawasan, yang membolehkan model menjana muzik padanan secara struktur berdasarkan harmoni dan melodi yang diberikan. Kertas kerja ini melaksanakan penilaian meluas MUSICGEN, dan kaedah yang dicadangkan mengatasi garis dasar penilaian dengan margin yang besar: MUSICGEN menerima skor subjektif 84.8 daripada 100, berbanding 80.5 untuk garis dasar terbaik. Selain itu, artikel ini menyediakan kajian ablasi yang menggambarkan kepentingan setiap komponen kepada prestasi model keseluruhan.
Akhir sekali, penilaian manusia menunjukkan bahawa MUSICGEN menghasilkan sampel berkualiti tinggi yang kedua-duanya mematuhi penerangan teks dan juga sejajar dengan melodi yang lebih baik dengan struktur harmonik yang diberikan.

Sumbangan utama artikel ini adalah seperti berikut:
- Mencadangkan model yang ringkas dan cekap: ia boleh menghasilkan muzik berkualiti tinggi pada 32khz. MUSICGEN boleh menjana muzik yang konsisten dengan model bahasa satu peringkat melalui strategi interleaving buku kod yang berkesan; melodi yang disediakan adalah konsisten dan konsisten dengan maklumat keadaan tekstual;
- Gambaran keseluruhan kaedah
- MUSICGEN mengandungi penyahkod berasaskan transformer autoregresif yang dikondisikan pada teks atau perwakilan melodi. Model (bahasa) adalah berdasarkan unit pengkuantitian tokenizer audio EnCodec, yang menyediakan pembinaan semula kesetiaan tinggi daripada perwakilan diskret bingkai rendah. Selain itu, model mampatan yang menggunakan kuantiti vektor sisa (RVQ) akan menjana berbilang aliran selari. Dalam tetapan ini, setiap aliran terdiri daripada token diskret daripada buku kod yang dipelajari berbeza.
Tokenisasi audio
Para penyelidik menggunakan EnCodec, iaitu pengekod auto konvolusi yang menggunakan ruang terpendam terkuantiti RVQ dan lawan kerugian pembinaan semula. Diberi rujukan pembolehubah rawak audio X ∈ R^d·f_s, dengan d mewakili tempoh audio dan f_s mewakili kadar pensampelan. EnCodec mengekod pembolehubah ini ke dalam tensor berterusan dengan kadar bingkai f_r ≪ f_s, dan kemudian perwakilan dikuantasikan sebagai Q ∈ {1, }^K×d・f_r, dengan K mewakili buku kod yang digunakan dalam Kuantiti RVQ. N mewakili saiz buku kod.
Mod selang buku kod
Penguraian autoregresif diratakan tepat. Model autoregresif memerlukan jujukan rawak diskret U ∈ {1, , N}^S dan panjang jujukan S. Mengikut konvensyen, penyelidik akan menggunakan U_0 = 0, yang merupakan token khas deterministik yang mewakili permulaan jujukan. Mereka kemudiannya boleh memodelkan pengedaran.
Penguraian autoregresif yang tidak tepat. Satu lagi kemungkinan ialah mempertimbangkan penguraian autoregresif, di mana sesetengah buku kod memerlukan ramalan selari. Sebagai contoh, takrifkan satu lagi urutan, V_0 = 0, dan t∈ {1, N}, k ∈ {1, }, V_t,k . Apabila indeks buku kod k dialih keluar (cth. V_t), ini mewakili gabungan semua buku kod pada masa t.
Mod interleaving buku kod sewenang-wenangnya. Untuk bereksperimen dengan penguraian sedemikian dan mengukur dengan tepat kesan penggunaan penguraian yang tidak tepat, para penyelidik memperkenalkan mod interleaving buku kod. Mula-mula pertimbangkan Ω = {(t, k): {1, ・f_r}, k ∈, K}}, iaitu set semua pasangan indeks. Corak buku kod ialah urutan P=(P_0, P_1, P_2, . . . , P_S), di mana P_0 = ∅, dan 0
Pensyaratan model
Pensyaratan teks. Diberi penerangan teks yang sepadan dengan audio input
Penyesuaian melodi. Walaupun teks ialah pendekatan dominan kepada model generatif bersyarat hari ini, pendekatan yang lebih semula jadi kepada muzik adalah dengan menyesuaikan struktur melodi daripada trek audio lain atau pun bersiul atau bersenandung. Pendekatan ini juga membolehkan pengoptimuman lelaran keluaran model. Untuk menyokong ini, kami cuba mengawal struktur melodi dengan memodulasi bersama kromatogram input dan penerangan teks. Dalam eksperimen awal, mereka memerhatikan bahawa penyaman pada kromatogram asal sering membina semula sampel asal, yang membawa kepada overfitting. Untuk tujuan ini, penyelidik memilih tong kekerapan masa utama dalam setiap langkah masa untuk memperkenalkan kesesakan maklumat.
Seni bina model
Unjuran buku kod dan pembenaman kedudukan. Memandangkan corak buku kod, hanya beberapa buku kod wujud dalam setiap langkah corak P_s. Penyelidik mendapatkan semula nilai dari Q yang sepadan dengan indeks dalam P_s. Setiap buku kod muncul dalam P_s paling banyak sekali atau tidak sama sekali.
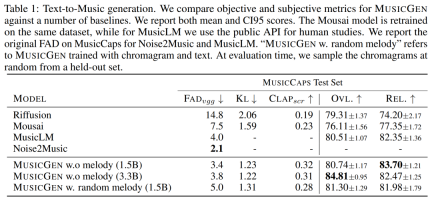
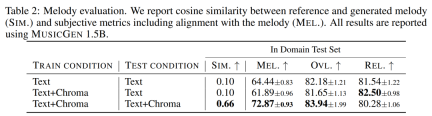
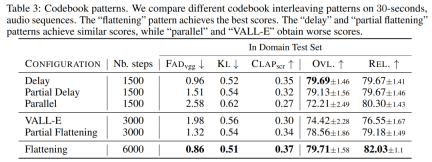
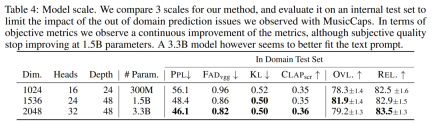
Penyahkod Transformer. Input dimasukkan ke dalam pengubah dengan lapisan L dan dimensi D, setiap lapisan terdiri daripada blok perhatian kendiri sebab. Blok perhatian silang kemudian digunakan, yang disediakan oleh isyarat penyaman C. Apabila menggunakan pelaziman melodi, penyelidik menetapkan awalan tensor C terkondisi kepada input pengubah. Ramalan logit. Pada langkah corak P_s, keluaran penyahkod pengubah ditukar kepada ramalan logit bagi nilai Q. Setiap buku kod muncul paling banyak sekali dalam P_s+1. Jika buku kod wujud, lapisan linear khusus buku kod digunakan daripada saluran D ke N untuk mendapatkan ramalan logit. Model tokenisasi audio. Kajian ini menggunakan model EnCodec lima lapisan bukan sebab untuk audio mono 32 kHz dengan langkah 640, kadar bingkai 50 Hz dan saiz tersembunyi awal 64 yang digandakan dalam setiap lima lapisan model itu. Model Transformer, Kajian ini melatih model Transformer autoregresif dengan saiz yang berbeza: parameter 300M, 1.5B, 3.3B. Set data latihan. Kaji menggunakan 20,000 jam muzik berlesen untuk melatih MUSICGEN. Secara terperinci, kajian itu menggunakan set data dalaman yang mengandungi 10K lagu berkualiti tinggi, serta set data muzik ShutterStock dan Pond5 yang masing-masing mengandungi 25K dan 365K trek instrumental sahaja. Dataset penilaian. Kajian ini menilai kaedah yang dicadangkan pada penanda aras MusicCaps dan membandingkannya dengan kerja sebelumnya. MusicCaps terdiri daripada 5.5K sampel (10 saat panjang) yang disediakan oleh ahli muzik pakar dan 1K subset yang seimbang merentas genre. Jadual 1 di bawah memberikan perbandingan kaedah yang dicadangkan dengan Mousai, Riffusion, MusicLM dan Noise2Music. Keputusan menunjukkan bahawa MUSICGEN mengatasi garis dasar yang dinilai oleh pendengar manusia dari segi kualiti audio dan konsistensi dengan penerangan teks yang disediakan. Noise2Music menunjukkan prestasi terbaik pada FAD pada MusicCaps, diikuti oleh MUSICGEN yang dilatih dengan keadaan teks. Menariknya, menambah keadaan melodi merendahkan metrik objektif, tetapi tidak menjejaskan penilaian manusia dengan ketara dan masih lebih baik daripada garis dasar yang dinilai. Pengkaji menggunakan ukuran objektif dan subjektif pada set penilaian yang diberikan, dalam teks MUSICGEN telah dinilai di bawah keadaan yang sama seperti perwakilan melodi Keputusan ditunjukkan dalam Jadual 2 di bawah. Keputusan menunjukkan bahawa MUSICGEN yang dilatih dengan pensyaratan kromatogram berjaya menjana muzik yang mengikut melodi tertentu, membolehkan kawalan yang lebih baik ke atas output yang dihasilkan. MUSICGEN adalah teguh untuk menjatuhkan kroma pada masa inferens menggunakan OVL dan REL. Kesan mod interleaving buku kod. Kami menilai pelbagai corak buku kod menggunakan rangka kerja dalam Bahagian 2.2, K = 4, yang diberikan oleh model tokenisasi audio. Artikel ini melaporkan penilaian objektif dan subjektif dalam Jadual 3 di bawah. Walaupun meratakan meningkatkan penjanaan, ia adalah mahal dari segi pengiraan. Prestasi yang sama boleh dicapai pada sebahagian kecil daripada kos menggunakan kaedah penangguhan mudah. Kesan saiz model. Jadual 4 di bawah melaporkan keputusan untuk saiz model yang berbeza, iaitu model parametrik 300M, 1.5B dan 3.3B. Seperti yang dijangkakan, peningkatan saiz model menghasilkan skor yang lebih baik, tetapi hanya dengan mengorbankan masa latihan dan inferens yang lebih lama. Dari segi penilaian subjektif, kualiti keseluruhan adalah optimum pada 1.5B, tetapi model yang lebih besar boleh lebih memahami gesaan teks. Hasil percubaan
Atas ialah kandungan terperinci Teks sumber terbuka meta menjana model muzik yang besar Kami mencubanya dengan lirik 'Qilixiang'.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

 Pembangunan permainan AI memasuki era agentiknya dengan portal pemimpi UphealMay 02, 2025 am 11:17 AM
Pembangunan permainan AI memasuki era agentiknya dengan portal pemimpi UphealMay 02, 2025 am 11:17 AMPermainan Upheaval: Merevolusi Pembangunan Permainan Dengan Ejen AI Upheaval, sebuah studio pembangunan permainan yang terdiri daripada veteran dari gergasi industri seperti Blizzard dan Obsidian, bersedia untuk merevolusikan penciptaan permainan dengan platfor AI yang inovatif
 Uber mahu menjadi kedai Robotaxi anda, adakah pembekal membiarkan mereka?May 02, 2025 am 11:16 AM
Uber mahu menjadi kedai Robotaxi anda, adakah pembekal membiarkan mereka?May 02, 2025 am 11:16 AMStrategi Robotaxi Uber: ekosistem perjalanan untuk kenderaan autonomi Pada persidangan Curbivore baru-baru ini, Uber's Richard Willder melancarkan strategi mereka untuk menjadi platform perjalanan untuk penyedia Robotaxi. Memanfaatkan kedudukan dominan mereka di
 Ejen AI bermain permainan video akan mengubah robot masa depanMay 02, 2025 am 11:15 AM
Ejen AI bermain permainan video akan mengubah robot masa depanMay 02, 2025 am 11:15 AMPermainan video terbukti menjadi alasan ujian yang tidak ternilai untuk penyelidikan AI canggih, terutamanya dalam pembangunan agen autonomi dan robot dunia nyata, malah berpotensi menyumbang kepada pencarian kecerdasan umum buatan (AGI). A
 Kompleks Perindustrian Permulaan, VC 3.0, dan Manifesto James CurrierMay 02, 2025 am 11:14 AM
Kompleks Perindustrian Permulaan, VC 3.0, dan Manifesto James CurrierMay 02, 2025 am 11:14 AMKesan landskap modal teroka yang berkembang jelas dalam media, laporan kewangan, dan perbualan setiap hari. Walau bagaimanapun, akibat khusus untuk pelabur, permulaan, dan dana sering diabaikan. Venture Capital 3.0: Paradigma
 Adobe mengemas kini Cloud Creative dan Firefly di Adobe Max London 2025May 02, 2025 am 11:13 AM
Adobe mengemas kini Cloud Creative dan Firefly di Adobe Max London 2025May 02, 2025 am 11:13 AMAdobe Max London 2025 menyampaikan kemas kini penting kepada Awan Kreatif dan Firefly, mencerminkan peralihan strategik ke arah aksesibiliti dan AI generatif. Analisis ini menggabungkan pandangan dari taklimat pra-peristiwa dengan kepimpinan Adobe. (Nota: Adob
 Segala -galanya Meta diumumkan di LlamaconMay 02, 2025 am 11:12 AM
Segala -galanya Meta diumumkan di LlamaconMay 02, 2025 am 11:12 AMPengumuman Llamacon Meta mempamerkan strategi AI yang komprehensif yang direka untuk bersaing secara langsung dengan sistem AI yang tertutup seperti OpenAI, sementara pada masa yang sama mencipta aliran pendapatan baru untuk model sumber terbuka. Pendekatan beragam ini mensasarkan bo
 Kontroversi pembuatan bir atas cadangan bahawa AI tidak lebih dari sekadar teknologi biasaMay 02, 2025 am 11:10 AM
Kontroversi pembuatan bir atas cadangan bahawa AI tidak lebih dari sekadar teknologi biasaMay 02, 2025 am 11:10 AMTerdapat perbezaan yang serius dalam bidang kecerdasan buatan pada kesimpulan ini. Ada yang menegaskan bahawa sudah tiba masanya untuk mendedahkan "pakaian baru Maharaja", sementara yang lain menentang idea bahawa kecerdasan buatan hanyalah teknologi biasa. Mari kita bincangkannya. Analisis terobosan AI yang inovatif ini adalah sebahagian daripada lajur Forbes yang berterusan yang meliputi kemajuan terkini dalam bidang AI, termasuk mengenal pasti dan menjelaskan pelbagai kerumitan AI yang berpengaruh (klik di sini untuk melihat pautan). Kecerdasan Buatan sebagai Teknologi Biasa Pertama, beberapa pengetahuan asas diperlukan untuk meletakkan asas untuk perbincangan penting ini. Pada masa ini terdapat banyak penyelidikan yang didedikasikan untuk terus membangunkan kecerdasan buatan. Matlamat keseluruhan adalah untuk mencapai kecerdasan umum buatan (AGI) dan juga kecerdasan super buatan (AS)
 Model warga, mengapa nilai AI adalah ukuran perniagaan seterusnyaMay 02, 2025 am 11:09 AM
Model warga, mengapa nilai AI adalah ukuran perniagaan seterusnyaMay 02, 2025 am 11:09 AMKeberkesanan model AI syarikat kini merupakan penunjuk prestasi utama. Sejak ledakan AI, AI generatif telah digunakan untuk segala -galanya daripada menyusun jemputan ulang tahun untuk menulis kod perisian. Ini telah membawa kepada percambahan mod bahasa


Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Penyesuai Pelayan SAP NetWeaver untuk Eclipse
Integrasikan Eclipse dengan pelayan aplikasi SAP NetWeaver.

VSCode Windows 64-bit Muat Turun
Editor IDE percuma dan berkuasa yang dilancarkan oleh Microsoft

SublimeText3 Linux versi baharu
SublimeText3 Linux versi terkini

mPDF
mPDF ialah perpustakaan PHP yang boleh menjana fail PDF daripada HTML yang dikodkan UTF-8. Pengarang asal, Ian Back, menulis mPDF untuk mengeluarkan fail PDF "dengan cepat" dari tapak webnya dan mengendalikan bahasa yang berbeza. Ia lebih perlahan dan menghasilkan fail yang lebih besar apabila menggunakan fon Unicode daripada skrip asal seperti HTML2FPDF, tetapi menyokong gaya CSS dsb. dan mempunyai banyak peningkatan. Menyokong hampir semua bahasa, termasuk RTL (Arab dan Ibrani) dan CJK (Cina, Jepun dan Korea). Menyokong elemen peringkat blok bersarang (seperti P, DIV),

Dreamweaver CS6
Alat pembangunan web visual

