
Rumah >Peranti teknologi >AI >Karya baharu Tian Yuandong: Membuka lapisan pertama kotak hitam Transformer, mekanisme perhatiannya tidak begitu misteri
Karya baharu Tian Yuandong: Membuka lapisan pertama kotak hitam Transformer, mekanisme perhatiannya tidak begitu misteri

- 王林ke hadapan
- 2023-06-12 13:56:091393semak imbas
Seni bina Transformer telah merentasi banyak bidang termasuk pemprosesan bahasa semula jadi, penglihatan komputer, pertuturan, pelbagai mod, dsb. Walau bagaimanapun, pada masa ini hanya hasil percubaan yang menakjubkan, dan penyelidikan yang berkaitan tentang prinsip kerja Transformer masih sangat terhad.
Misteri terbesar ialah mengapa Transformer boleh memunculkan perwakilan yang cekap daripada dinamik latihan kecerunan dengan hanya bergantung pada "kehilangan ramalan mudah"?
Baru-baru ini Dr. Tian Yuandong mengumumkan hasil penyelidikan terkini pasukannya Dengan cara yang teliti secara matematik, beliau menganalisis prestasi Transformer 1 lapisan (lapisan perhatian diri ditambah dekoder. lapisan) dalam tugasan ramalan token seterusnya dinamik latihan SGD pada.

Pautan kertas: https://arxiv.org/abs/2305.16380
Kertas ini membuka kotak hitam tentang cara lapisan perhatian kendiri menggabungkan dinamik token input dan mendedahkan sifat bias induktif yang berpotensi.
Secara khusus, dengan andaian bahawa tiada pengekodan kedudukan, urutan input yang panjang, dan lapisan penyahkod belajar lebih cepat daripada lapisan perhatian diri, para penyelidik membuktikan bahawa perhatian diri adalah Algoritma pengimbasan diskriminatif :
Bermula dari perhatian seragam (perhatian seragam), untuk token seterusnya yang spesifik untuk diramalkan, model secara beransur-ansur memberi perhatian kepada token kunci yang berbeza, dan kurang memberi perhatian kepada token biasa yang muncul dalam berbilang tetingkap token seterusnya
Untuk token yang berbeza, model akan mengurangkan berat perhatian secara beransur-ansur, mengikuti latihan Urutan kejadian bersama antara pekat token kunci dan token pertanyaan dari rendah ke tinggi.
Apa yang menarik ialah proses ini tidak membawa kepada pemenang-ambil-semua, tetapi diperlahankan oleh perubahan fasa yang dikawal oleh kadar pembelajaran dua lapisan, dan akhirnya menjadi ( hampir) gabungan token tetap Dinamik ini juga disahkan pada data sintetik dan dunia sebenar.
Dr. Tian Yuandong ialah penyelidik dan pengurus penyelidikan di Institut Penyelidikan Kecerdasan Buatan Meta dan peneraju projek Go AI adalah pembelajaran pengukuhan yang mendalam dan aplikasinya dalam permainan , serta analisis teori model pembelajaran mendalam. Beliau menerima ijazah sarjana muda dan sarjana dari Universiti Shanghai Jiao Tong pada 2005 dan 2008, dan ijazah kedoktorannya dari Institut Robotik Universiti Carnegie Mellon di Amerika Syarikat pada 2013.
Memenangi 2013 International Conference on Computer Vision (ICCV) Marr Prize Honorable Mentions (Marr Prize Honorable Mentions) dan ICML2021 Outstanding Paper Honorable Mention Award.
Selepas menamatkan pengajian dalam Ph.D., beliau menerbitkan satu siri "Ringkasan Kedoktoran Lima Tahun", meliputi aspek seperti pemilihan hala tuju penyelidikan, pengumpulan bacaan, pengurusan masa, sikap kerja , pendapatan dan pembangunan kerjaya yang mampan Ringkasan pemikiran dan pengalaman mengenai kerjaya kedoktoran.
Mendedahkan Transformer 1-layer
Model pra-latihan berdasarkan seni bina Transformer biasanya hanya termasuk tugas penyeliaan yang sangat mudah, seperti meramal perkataan seterusnya, mengisi kosong, dsb., tetapi ia boleh Menyediakan perwakilan yang sangat kaya untuk tugas hiliran adalah membingungkan.
Walaupun kerja terdahulu telah membuktikan bahawa Transformer pada asasnya adalah penghampir universal, model pembelajaran mesin yang biasa digunakan sebelum ini, seperti kNN, kernel SVM, dan perceptron berbilang lapisan dsb. sebenarnya adalah penghampir universal Teori ini tidak dapat menjelaskan jurang yang besar dalam prestasi antara kedua-dua jenis model ini.
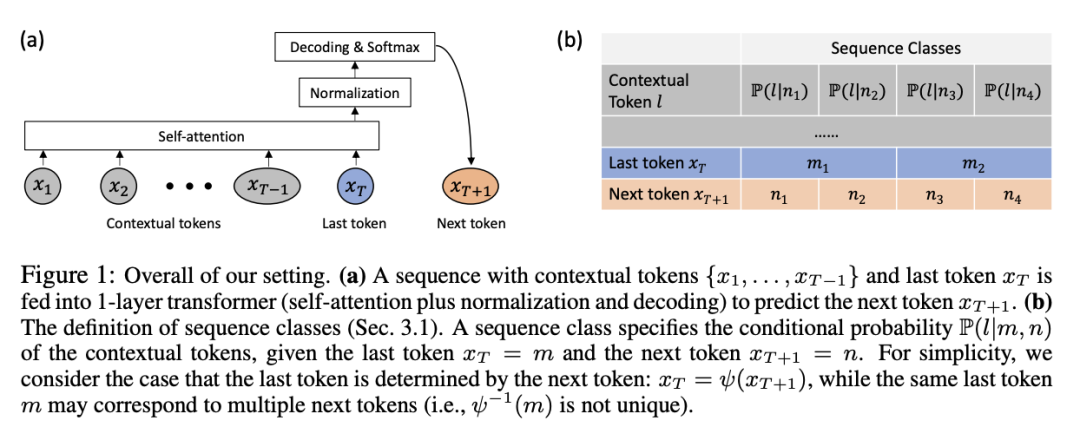
Penyelidik percaya bahawa adalah penting untuk memahami dinamik latihan Transformer, iaitu, dalam Semasa latihan, anda boleh belajar bagaimana parameter berubah dari semasa ke semasa.
Artikel pertama kali menggunakan definisi matematik yang ketat untuk menerangkan secara rasmi dinamik latihan SGD bagi Transformer pengekodan kedudukan tanpa lapisan pada ramalan token seterusnya (paradigma latihan yang biasa digunakan untuk siri GPT model).
Pengubah 1 lapisan mengandungi lapisan perhatian kendiri softmax dan lapisan penyahkod yang meramalkan token seterusnya. Bukti 1. Bias Kekerapan
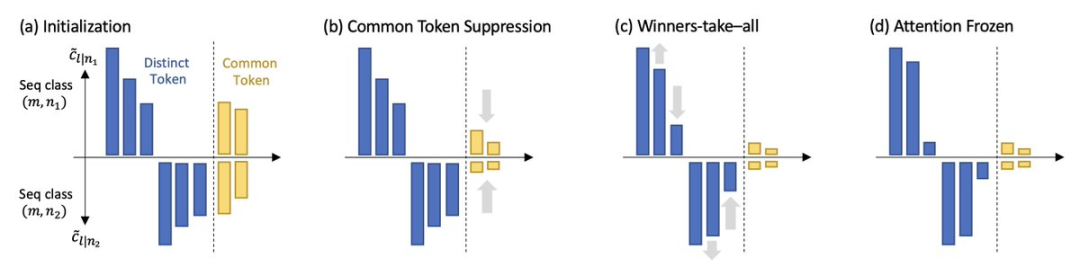
2. Bias DiskriminasiModel memberi lebih perhatian kepada yang akan diramalkan seterusnya Satu-satunya token unik yang muncul dalam token seterusnya, dan kehilangan minat terhadap token biasa yang muncul dalam berbilang token seterusnya.
Dua ciri ini menunjukkan bahawa perhatian diri secara tersirat menjalankan algoritma pengimbasan diskriminatif dan mempunyai bias induktif, iaitu, ia berat sebelah terhadap token kunci Unik yang sering berlaku bersama token pertanyaan
Tambahan pula, walaupun lapisan perhatian diri cenderung menjadi lebih jarang semasa latihan, seperti yang dicadangkan oleh bias frekuensi, model Oleh kerana peralihan fasa dalam dinamik latihan, ia tidak runtuh menjadi satu. panas.
Peringkat akhir pembelajaran tidak menumpu kepada mana-mana titik pelana dengan kecerunan sifar, sebaliknya memasuki perubahan perhatian Perlahan rantau (iaitu logaritma dari semasa ke semasa), dengan pembekuan parameter dan dipelajari.
Hasil penyelidikan selanjutnya menunjukkan bahawa permulaan peralihan fasa dikawal oleh kadar pembelajaran: kadar pembelajaran yang besar akan menghasilkan corak perhatian yang jarang, manakala di bawah kadar pembelajaran perhatian kendiri yang tetap , kadar pembelajaran penyahkod yang besar membawa kepada peralihan fasa yang lebih pantas dan corak perhatian yang padat.
Para penyelidik menamakan dinamik SGD yang ditemui dalam imbasan dan snap kerja mereka:

Perhatian diri difokuskan pada token utama, iaitu, token berbeza yang sering muncul pada masa yang sama dengan token ramalan seterusnya berkurangan;
peringkat snap: Perhatian hampir dibekukan dan gabungan token telah ditetapkan.
Fenomena ini juga telah disahkan dalam eksperimen data dunia sebenar yang mudah, menggunakan SGD yang dilatih di WikiText1 Memerhati diri yang paling rendah -lapisan perhatian pada lapisan dan Transformer 3-layer, kita dapati bahawa walaupun kadar pembelajaran kekal malar sepanjang proses latihan, perhatian akan membeku pada masa tertentu semasa proses latihan dan menjadi jarang.
Atas ialah kandungan terperinci Karya baharu Tian Yuandong: Membuka lapisan pertama kotak hitam Transformer, mekanisme perhatiannya tidak begitu misteri. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI