
Rumah >Peranti teknologi >AI >IPhone mengambil masa dua saat untuk menghasilkan gambar, dan model Stable Diffusion mudah alih yang paling cepat diketahui ada di sini.
IPhone mengambil masa dua saat untuk menghasilkan gambar, dan model Stable Diffusion mudah alih yang paling cepat diketahui ada di sini.

- 王林ke hadapan
- 2023-06-12 11:15:481434semak imbas
Resapan Stabil (SD) ialah model resapan penjanaan teks kepada imej yang paling popular. Walaupun keupayaan penjanaan imej yang berkuasa mengejutkan, kelemahan yang jelas ialah ia memerlukan sumber pengkomputeran yang besar dan kelajuan inferens sangat perlahan: mengambil SD-v1.5 sebagai contoh, walaupun menggunakan storan separuh ketepatan, saiz modelnya ialah 1.7GB . Dengan 1 bilion parameter, masa inferens pada peranti selalunya hampir 2 minit.
Untuk menyelesaikan masalah kelajuan inferens, akademia dan industri telah memulakan penyelidikan mengenai pecutan SD, terutamanya memfokuskan kepada dua laluan: (1) mengurangkan bilangan langkah inferens, laluan ini boleh Dibahagikan kepada dua sub-laluan, satu adalah untuk mengurangkan bilangan langkah dengan mencadangkan penjadual bunyi yang lebih baik, kerja-kerja perwakilan adalah DDIM [1], PNDM [2], DPM [3], dan lain-lain; bilangan langkah melalui penyulingan progresif (Penyulingan Progresif) Bilangan langkah, kerja perwakilan ialah Penyulingan Progresif [4] dan penyaman w [5], dsb. (2) Pengoptimuman kemahiran kejuruteraan Tugas perwakilan ialah Qualcomm menggunakan pengoptimuman int8 + pengoptimuman tindanan penuh untuk mencapai SD-v1.5 pada telefon Android dalam masa 15 saat [6]. .4 pada telefon Samsung pecutan kepada 12s [7].
Walaupun usaha ini telah berjalan jauh, ia masih belum cukup pantas.
Baru-baru ini, Snap Research Institute melancarkan model Stable Diffusion berprestasi tinggi terkini Dengan mengoptimumkan struktur rangkaian, proses latihan dan fungsi kehilangan dalam semua aspek, ia boleh menghasilkan imej dalam masa 2 saat pada iPhone 14 Pro (512x512), dan mencapai skor CLIP yang lebih baik daripada SD-v1.5. Ini ialah model Resapan Stabil hujung ke hujung yang paling cepat diketahui!

- Alamat kertas: https://arxiv.org/pdf/2306.00980.pdf
- Laman web: https://snap-research.github.io/SnapFusion
Kaedah Teras
Model Resapan Stabil terbahagi kepada tiga bahagian: pengekod/penyahkod VAE, pengekod teks dan UNet Antaranya, UNet menyumbang majoriti mutlak dari segi jumlah parameter dan jumlah pengiraan, jadi SnapFusion terutamanya. mengoptimumkan UNet. Ia dibahagikan kepada dua bahagian: (1) Pengoptimuman struktur UNet: Dengan menganalisis kesesakan kelajuan UNet asal, artikel ini mencadangkan satu set proses penilaian dan evolusi automatik untuk struktur UNet, dan memperoleh struktur UNet yang lebih cekap ( dipanggil Efficient UNet) . (2) Pengoptimuman bilangan langkah inferens: Seperti yang kita semua tahu, model resapan ialah proses denoising berulang semasa inferens Semakin banyak langkah lelaran, semakin tinggi kualiti imej yang dihasilkan, tetapi kos masa juga meningkat secara linear dengan bilangan langkah lelaran. Untuk mengurangkan bilangan langkah dan mengekalkan kualiti imej, kami mencadangkan fungsi kehilangan penyulingan sedar CFG yang secara eksplisit mempertimbangkan peranan CFG (Bimbingan Tanpa Pengelas) semasa proses latihan ini terbukti menjadi kunci kepada meningkatkan skor CLIP!
Jadual berikut ialah perbandingan gambaran keseluruhan antara model SD-v1.5 dan SnapFusion. Dapat dilihat bahawa peningkatan kelajuan datang daripada dua bahagian, penyahkod UNet dan VAE dan UNet bahagian adalah yang besar. Terdapat dua aspek untuk penambahbaikan bahagian UNet Satu ialah pengurangan kependaman tunggal (1700ms -> 230ms, 7.4x pecutan), yang diperoleh melalui cadangan struktur UNet yang Efisien. 50 -> 8, 6.25 x pecutan), yang diperoleh melalui Penyulingan sedar CFG yang dicadangkan. Penyahkod VAE dipercepatkan melalui pemangkasan berstruktur.

Berikut memfokuskan pada reka bentuk UNet Cekap dan reka bentuk fungsi kehilangan Penyulingan sedar CFG.
(1) Efficient UNet
Kami mencari kelajuan dengan menganalisis modul Cross-Attention dan ResNet dalam UNet Kesesakan terletak pada modul Cross-Attention (terutamanya Cross-Attention dalam peringkat Downsample pertama), seperti yang ditunjukkan dalam rajah di bawah. Punca masalah ini ialah kerumitan modul perhatian mempunyai hubungan segi empat sama dengan saiz spatial peta ciri Pada peringkat Downsample pertama, saiz spatial peta ciri masih besar, mengakibatkan kerumitan pengiraan yang tinggi.
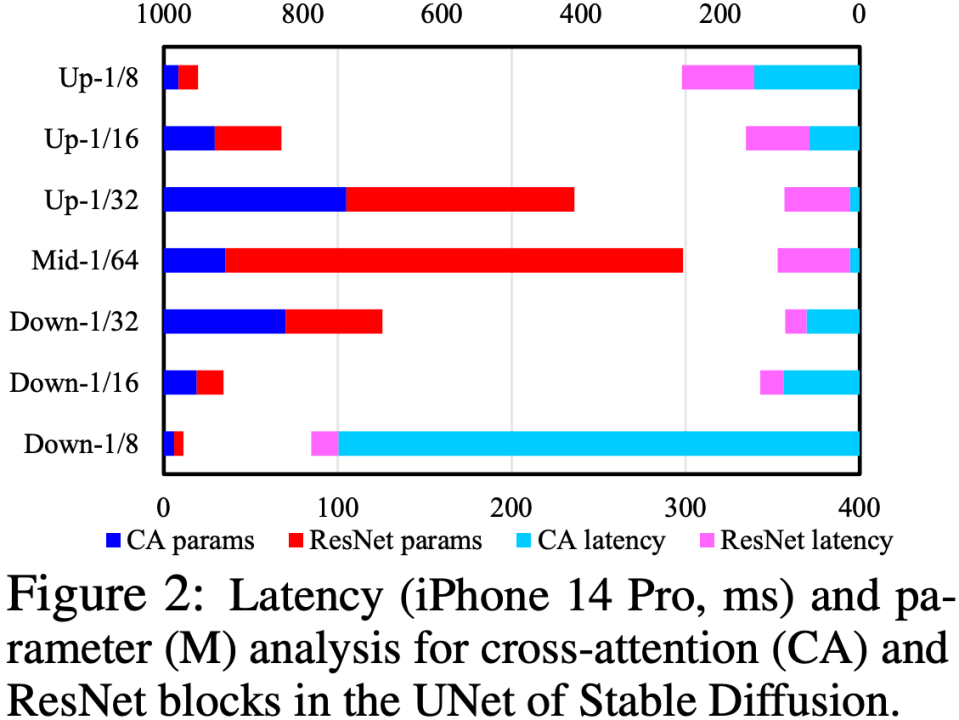
Untuk mengoptimumkan struktur UNet, kami mencadangkan satu set proses penilaian automatik dan evolusi struktur UNet: mula-mula menjalankan latihan yang mantap pada UNet, dan secara rawak menggugurkan beberapa modul semasa latihan untuk menguji setiap Impak sebenar setiap modul pada prestasi digunakan untuk membina jadual carian "kesan pada skor CLIP vs. kependaman"; dan kemudian berdasarkan jadual carian, keutamaan diberikan untuk mengalih keluar modul yang mempunyai sedikit kesan pada skor CLIP dan sangat memakan masa. Set proses ini dilakukan secara automatik dalam talian Selepas selesai, kami akan mendapat struktur UNet baharu yang dipanggil Efficient UNet. Berbanding dengan UNet asal, ia mencapai pecutan 7.4x tanpa penurunan prestasi.
(2) Penyulingan Langkah CFG-aware
CFG (Bimbingan Tanpa Pengelas) ialah peringkat inferens SD Kemahiran penting yang boleh meningkatkan kualiti gambar, sangat penting! Walaupun terdapat kerja pada model resapan menggunakan penyulingan langkah untuk mempercepatkan [4], mereka tidak memasukkan CFG sebagai matlamat pengoptimuman dalam latihan penyulingan Maksudnya, fungsi kehilangan penyulingan tidak mengetahui bahawa CFG akan digunakan kemudian. Menurut pemerhatian kami, ini akan menjejaskan skor CLIP secara serius apabila bilangan langkah adalah kecil.
Untuk menyelesaikan masalah ini, kami mencadangkan untuk membenarkan kedua-dua model guru dan pelajar melakukan CFG sebelum mengira fungsi kehilangan penyulingan, supaya fungsi kehilangan dikira pada ciri selepas CFG , oleh itu Kesan skala CFG yang berbeza dipertimbangkan secara eksplisit. Dalam percubaan, kami mendapati bahawa walaupun skor CLIP boleh dipertingkatkan dengan sepenuhnya menggunakan Penyulingan sedar CFG, FID juga menjadi lebih teruk dengan ketara. Kami kemudiannya mencadangkan skim pensampelan rawak untuk mencampurkan fungsi kehilangan Penyulingan Langkah asal dan fungsi kehilangan Penyulingan sedar CFG, mencapai kewujudan bersama kelebihan kedua-duanya, yang bukan sahaja meningkatkan skor CLIP dengan ketara, tetapi juga tidak memburukkan FID. . Langkah ini mencapai pecutan 6.25 kali dalam peringkat inferens selanjutnya, mencapai jumlah pecutan lebih kurang 46 kali.
Selain daripada dua sumbangan utama di atas, artikel itu juga termasuk pecutan pemangkasan penyahkod VAE dan reka bentuk proses penyulingan yang teliti. Sila rujuk kertas untuk kandungan tertentu.
Hasil eksperimen
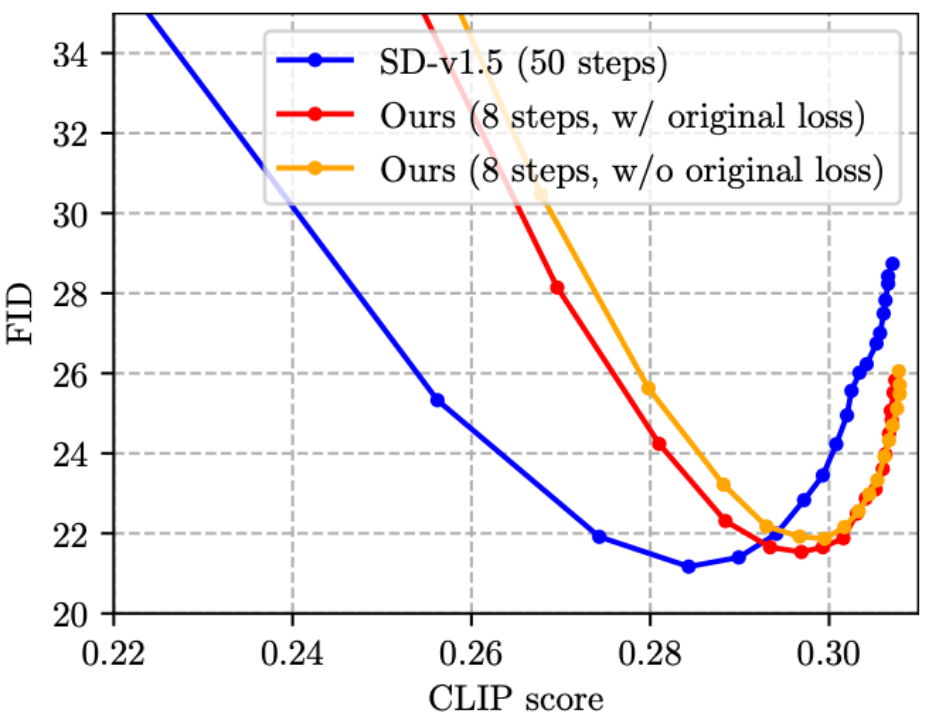
SnapFusion menanda aras SD-v1.5 fungsi teks ke imej, matlamatnya adalah untuk mengurangkan masa inferens dengan ketara sambil mengekalkan kualiti imej, yang paling menggambarkan Ini adalah ditunjukkan dalam rajah di bawah:
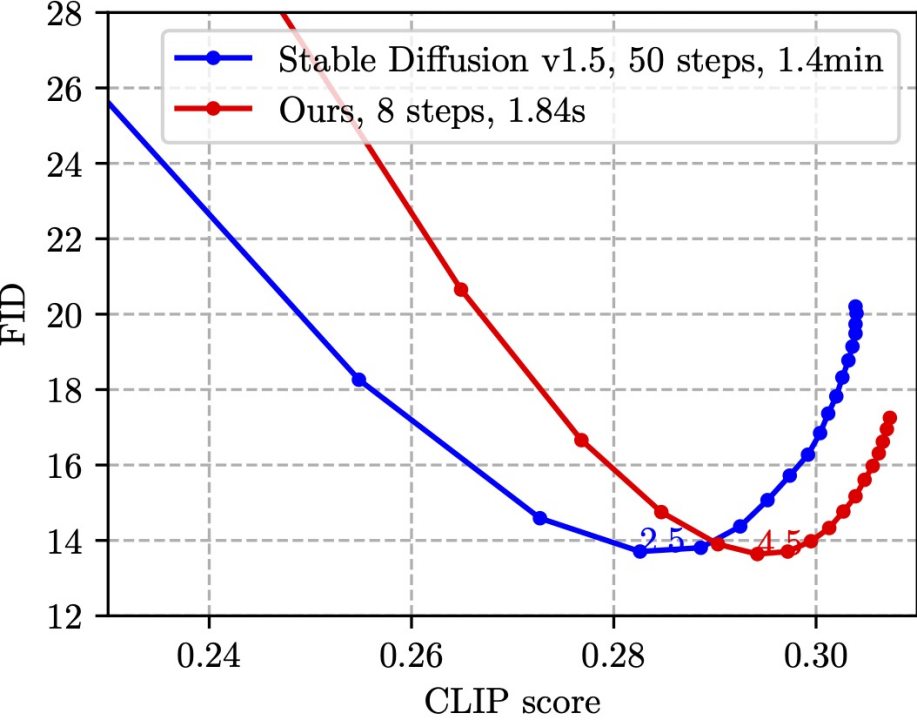
Angka ini secara rawak memilih 30K pasangan imej kapsyen pada set pengesahan MS COCO'14 untuk mengira skor CLIP dan FID. Skor CLIP mengukur ketekalan semantik antara gambar dan teks, lebih besar lebih baik FID mengukur jarak pengedaran antara gambar yang dijana dan gambar sebenar (biasanya dianggap sebagai ukuran kepelbagaian gambar yang dihasilkan), lebih kecil lebih baik. Titik yang berbeza dalam graf diperoleh menggunakan skala CFG yang berbeza, dan setiap skala CFG sepadan dengan titik data. Seperti yang dapat dilihat dari rajah, kaedah kami (garis merah) boleh mencapai FID terendah yang sama seperti SD-v1.5 (garis biru), dan pada masa yang sama, skor CLIP kaedah kami adalah lebih baik. Perlu diingat bahawa SD-v1.5 mengambil masa 1.4 minit untuk menjana imej, manakala SnapFusion hanya mengambil masa 1.84s Ini juga merupakan model Stable Diffusion mudah alih yang kami ketahui!
Berikut ialah beberapa sampel yang dihasilkan oleh SnapFusion:

Lebih banyak sampel Sila rujuk lampiran artikel.
Selain keputusan utama ini, artikel itu juga menunjukkan banyak eksperimen Kajian Ablasi, dengan harapan dapat memberikan pengalaman rujukan untuk pembangunan model SD yang cekap:
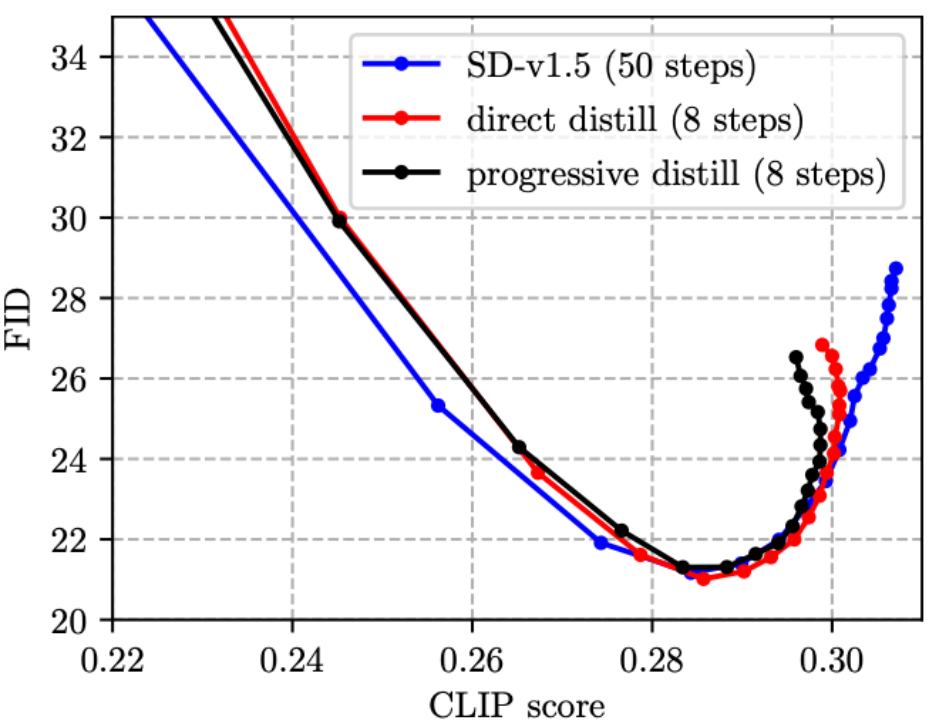
(1) Kerja sebelumnya mengenai Penyulingan Langkah biasanya menggunakan skema progresif [4, 5], tetapi kami mendapati bahawa penyulingan progresif tidak mempunyai kelebihan berbanding penyulingan langsung pada model SD, dan prosesnya adalah rumit, jadi kami Penyulingan langsung skema digunakan dalam artikel ini.
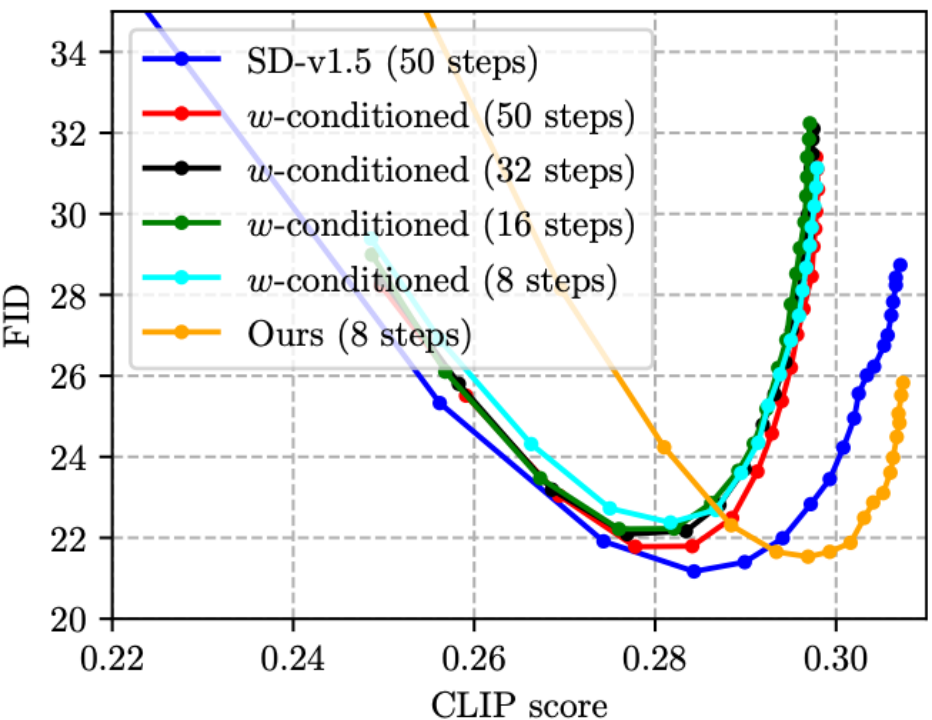
(2) Walaupun CFG boleh meningkatkan kualiti imej dengan banyak, harganya menggandakan kos inferens. Artikel Mengenai Penyulingan Calon Anugerah CVPR'23 tahun ini [5] mencadangkan penyamanan w, yang menggunakan parameter CFG sebagai input kepada UNet untuk penyulingan (model yang terhasil dipanggil UNet berhawa dingin), dengan itu menghapuskan langkah CFG semasa membuat penaakulan dan merealisasikan penaakulan kos. Walau bagaimanapun, kami mendapati bahawa berbuat demikian sebenarnya akan menyebabkan kualiti imej berkurangan dan skor CLIP menurun (seperti yang ditunjukkan dalam rajah di bawah, skor CLIP bagi empat baris berhawa dingin tidak melebihi 0.30, yang lebih buruk daripada SD- v1.5). Kaedah kami boleh mengurangkan bilangan langkah dan meningkatkan skor CLIP pada masa yang sama, terima kasih kepada fungsi kehilangan penyulingan sedar CFG yang dicadangkan! Apa yang patut diberi perhatian adalah bahawa kos inferens garis hijau (berhawa dingin, 16 langkah) dan garis oren (Kami, 8 langkah) dalam rajah di bawah adalah sama, tetapi garis oren jelas lebih baik, menunjukkan bahawa kami laluan teknikal adalah lebih baik daripada penyaman udara w [5] adalah lebih berkesan pada model SD berpandukan CFG suling.
(3) Kerja Penyulingan Langkah sedia ada [4, 5] tidak menggabungkan fungsi kehilangan asal dan penyulingan. fungsi kehilangan ditambah bersama Rakan yang biasa dengan penyulingan pengetahuan klasifikasi imej harus tahu bahawa reka bentuk ini secara intuitif tidak optimum. Jadi kami mencadangkan untuk menambah fungsi kehilangan asal kepada latihan, seperti yang ditunjukkan dalam rajah di bawah, yang sememangnya berkesan (sedikit mengurangkan FID).
Ringkasan dan kerja masa hadapan
Kertas kerja ini mencadangkan SnapFusion, model Resapan Stabil berprestasi tinggi untuk terminal mudah alih. SnapFusion mempunyai dua sumbangan teras: (1) Melalui analisis lapisan demi lapisan bagi UNet sedia ada, ia mengesan kesesakan kelajuan dan mencadangkan struktur UNet yang cekap baharu (Efficient UNet), yang boleh menggantikan UNet secara setara dalam Stable Diffusion yang asal kepada mencapai 7.4 x pecutan; (2) Optimumkan bilangan langkah lelaran dalam fasa inferens dan cadangkan skim penyulingan langkah baharu (Penyulingan Langkah sedar CFG), yang boleh meningkatkan markah CLIP dengan ketara sambil mengurangkan bilangan langkah, mencapai 6.25x pecutan. Secara keseluruhan, SnapFusion mencapai output imej dalam masa 2 saat pada iPhone 14 Pro, yang kini merupakan model Stable Diffusion mudah alih yang paling cepat diketahui.
Kerja masa hadapan:
1 Model SD boleh digunakan dalam pelbagai senario penjanaan imej, ini artikel terhad kepada Disebabkan kekangan masa, kami pada masa ini hanya menumpukan pada tugas teras teks ke imej, dan tugas lain (seperti mengecat, ControlNet, dll.) akan diikuti kemudian.
2. Artikel ini tertumpu terutamanya pada peningkatan kelajuan dan tidak mengoptimumkan storan model. Kami percaya bahawa Efficient UNet yang dicadangkan masih mempunyai ruang untuk pemampatan Digabungkan dengan kaedah pengoptimuman berprestasi tinggi yang lain (seperti pemangkasan, kuantisasi), ia dijangka mengecilkan storan dan mengurangkan masa kepada kurang daripada 1 saat, menjadikan SD masa nyata. pada akhirnya selangkah lebih jauh.
Atas ialah kandungan terperinci IPhone mengambil masa dua saat untuk menghasilkan gambar, dan model Stable Diffusion mudah alih yang paling cepat diketahui ada di sini.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI