
Rumah >Peranti teknologi >AI >Pukul LLaMA? Kedudukan 'Falcon' yang paling berkuasa dalam sejarah diragui, Fu Yao secara peribadi menguji 7 baris kod, dan LeCun memajukannya untuk menyukai
Pukul LLaMA? Kedudukan 'Falcon' yang paling berkuasa dalam sejarah diragui, Fu Yao secara peribadi menguji 7 baris kod, dan LeCun memajukannya untuk menyukai

- 王林ke hadapan
- 2023-06-10 19:46:581410semak imbas
Beberapa masa lalu, Falcon yang masih muda telah menghancurkan LLaMA dalam kedudukan LLM, menyebabkan gelombang dalam seluruh komuniti.
Tetapi, adakah Falcon benar-benar lebih baik daripada LLaMA?
Jawapan ringkas: Mungkin tidak.
Pasukan Fu Yao menjalankan penilaian model yang lebih mendalam:
"Kami Penilaian LLaMA 65B telah diterbitkan semula pada MMLU dan mencapai skor 61.4, yang hampir dengan skor rasmi (63.4), jauh lebih tinggi daripada skornya pada Papan Pendahulu LLM Terbuka (48.8), dan jauh lebih tinggi daripada Falcon ( 52.7).”
Tiada kejuruteraan pantas yang mewah, tiada penyahkodan yang mewah, semuanya adalah tetapan lalai.
Pada masa ini, kod dan kaedah ujian telah didedahkan kepada umum di Github.
Terdapat keraguan tentang Falcons mengatasi LLaMA, LeCun menyatakan pendiriannya, masalah skrip ujian...
LLaMA adalah benar· Kekuatan
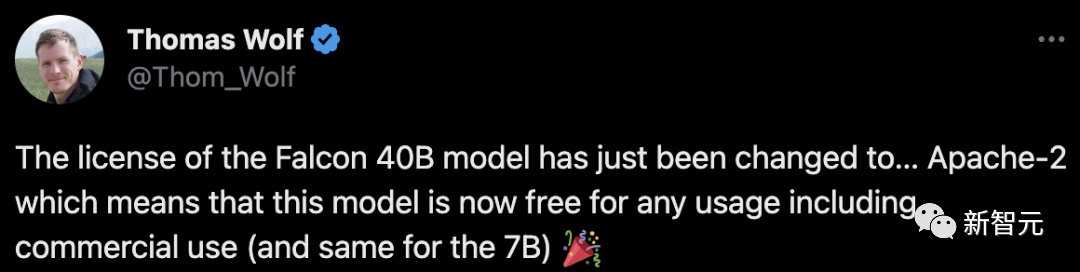
Pada masa ini dalam ranking OpenLLM, Falcon menduduki tempat pertama, mengatasi LLaMA, dan sangat disyorkan oleh penyelidik termasuk Thomas Wolf.

Namun, sesetengah orang mempunyai keraguan mereka.
Pertama, netizen mempersoalkan dari mana datangnya nombor LLaMA ini nampaknya tidak konsisten dengan nombor dalam kertas...
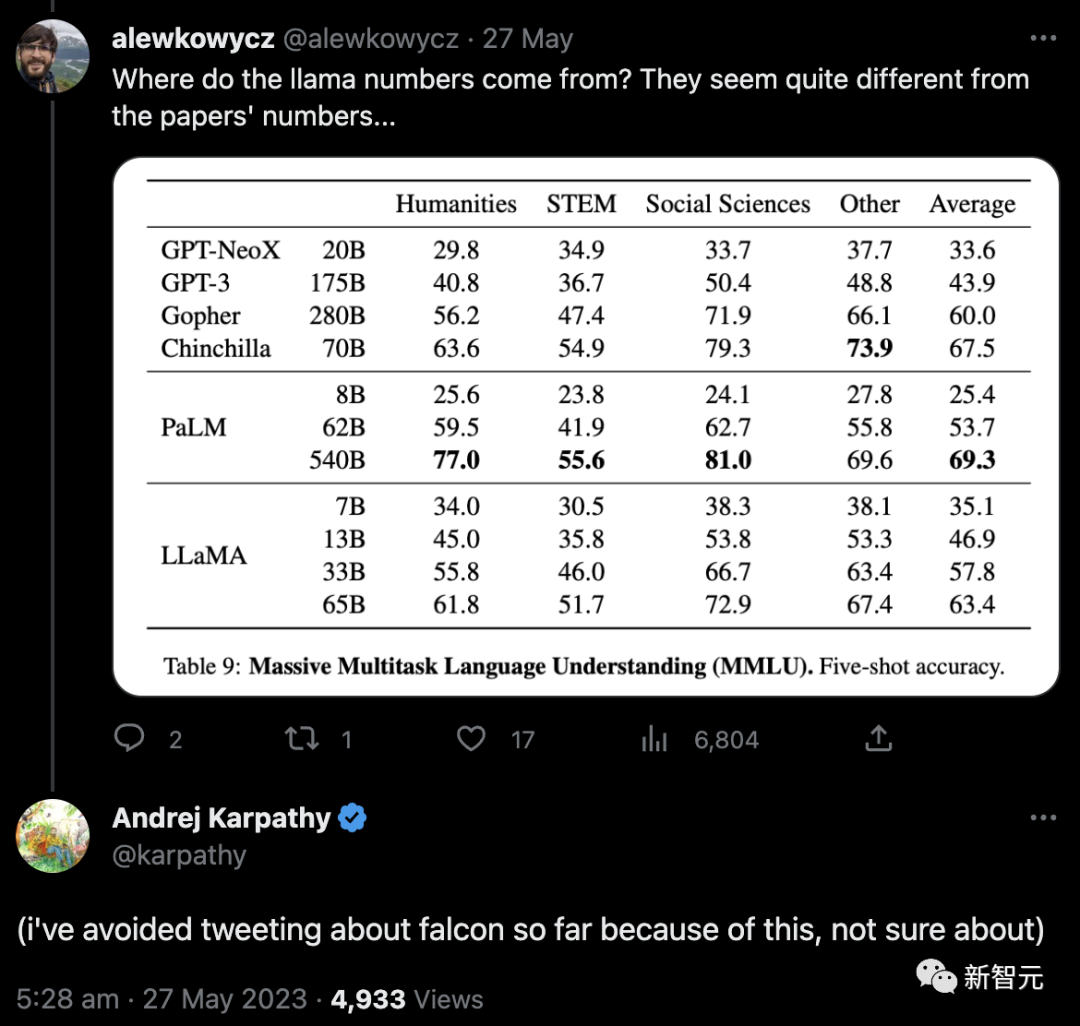
Seterusnya, saintis OpenAI Andrej Karpathy turut menyatakan kebimbangan tentang sebab skor LLaMA 65B pada kedudukan LLM Terbuka jauh lebih rendah daripada kedudukan rasmi (48.8 berbanding 63.4).
Dan siaran, setakat ini saya telah mengelak daripada tweet tentang Falcons kerana ini, tidak pasti.
Untuk menjelaskan masalah ini, Fu Yao dan ahli pasukan memutuskan untuk menjalankan ujian awam pada LLaMA 65B, dan keputusannya ialah 61.4 mata.
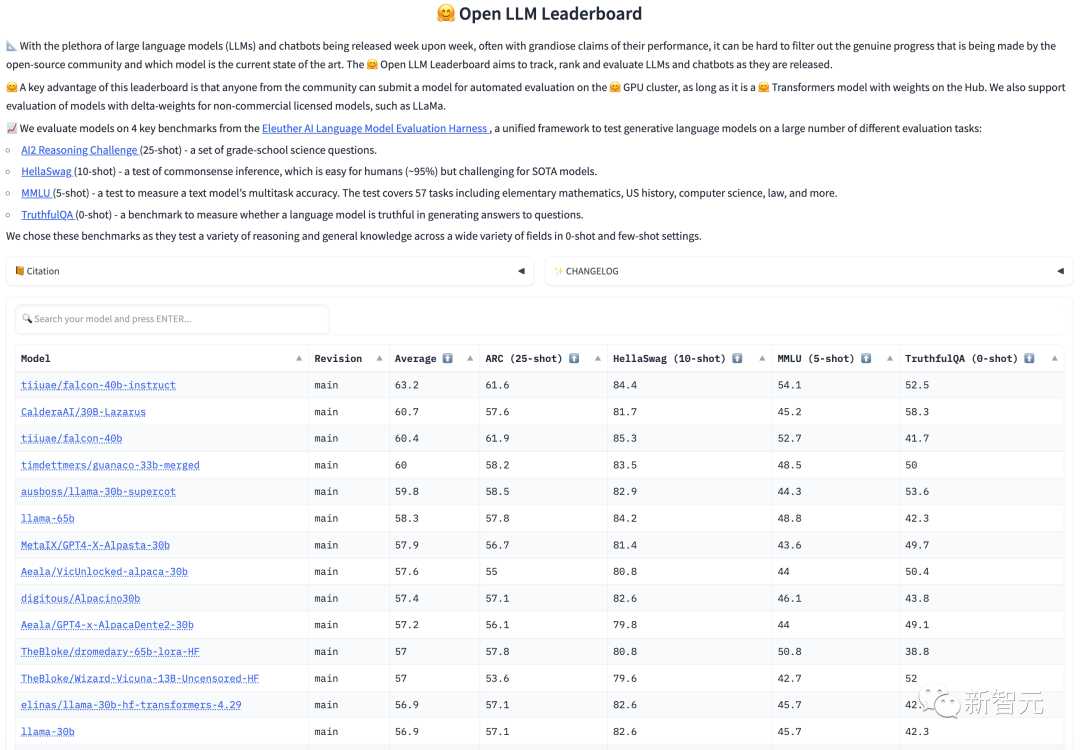
Dalam ujian, penyelidik tidak menggunakan sebarang mekanisme khas, dan LLaMA 65B dapat mencapai skor ini.
Hasil ini hanya membuktikan bahawa jika anda mahu model mencapai tahap yang hampir dengan GPT-3.5, sebaiknya gunakan RLHF pada LLaMA 65B.
Berdasarkan penemuan kertas kerja Chain-of-Thought Hub yang diterbitkan baru-baru ini oleh pasukan Fu Yao.

Sudah tentu, Fu Yao berkata bahawa penilaian mereka tidak bertujuan untuk menimbulkan pertikaian antara LLaMA dan Falcon Lagipun, ini adalah sumber terbuka yang hebat projek. Model telah memberikan sumbangan besar kepada bidang ini!
Selain itu, Falcon mempunyai lesen yang lebih mudah, yang juga memberikan potensi pembangunan yang hebat.
Untuk ulasan terbaharu ini, netizen BlancheMinerva menegaskan bahawa perbandingan yang adil adalah untuk menjalankan Falcon pada MMLU di bawah tetapan lalai.
Sehubungan itu, Fu Yao berkata bahawa ini adalah betul dan kerja sedang dijalankan dan hasilnya dijangka tersedia dalam satu hari.

Tidak kira apa keputusan akhir, anda mesti tahu bahawa gunung GPT-4 adalah matlamat yang sangat ingin dicapai oleh komuniti sumber terbuka kejar.
Masalah ranking OpenLLM
Penyelidik dari Meta memuji Fu Yao kerana menghasilkan semula keputusan LLaMa dengan baik dan menunjukkan masalah ranking OpenLLM.
Pada masa yang sama, beliau turut berkongsi beberapa soalan mengenai kedudukan OpenLLM.
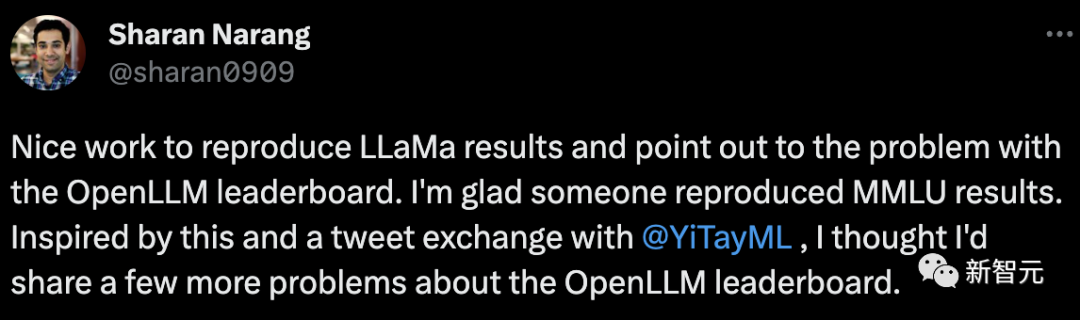
Pertama, keputusan MMLU: Keputusan MMLU LLaMa 65B ialah 15 mata pada papan pendahulu, tetapi adalah sama untuk model 7B. Terdapat juga jurang prestasi kecil antara model 13B dan 30B.
OpenLLM benar-benar perlu melihat perkara ini sebelum mengumumkan model mana yang terbaik.
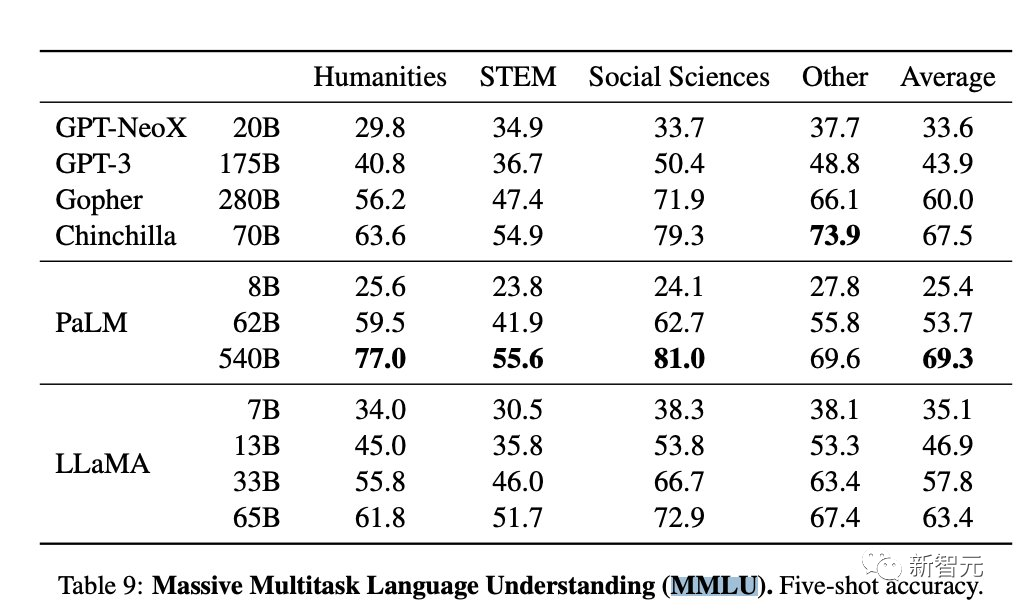
Tanda aras: Bagaimanakah penanda aras ini dipilih?
Pukulan ARC 25 dan pukulan Hellaswag 10 nampaknya tidak begitu relevan dengan LLM. Adalah lebih baik jika beberapa penanda aras generatif boleh dimasukkan. Walaupun tanda aras generatif mempunyai hadnya, ia masih boleh berguna.

Skor Purata Tunggal: Ia sentiasa menarik untuk mengurangkan keputusan kepada skor tunggal dan skor purata adalah paling mudah.
Tetapi dalam kes ini, adakah purata 4 penanda aras benar-benar berguna? Adakah mendapat 1 mata di MMLU sama dengan mendapat 1 mata di HellaSwag?
Dalam dunia lelaran pesat LLM, pasti ada nilai dalam membangunkan senarai kedudukan sedemikian.

Dan Lucas Beyer, seorang penyelidik dari Google, turut menyatakan pendapatnya,
Gila Ya, Penyelidik NLP mempunyai pemahaman yang berbeza tentang penanda aras yang sama, sekali gus membawa kepada keputusan yang sama sekali berbeza. Pada masa yang sama, setiap kali salah seorang rakan sekerja saya melaksanakan metrik, saya segera bertanya kepada mereka sama ada mereka benar-benar menyemak pengeluaran semula kod rasmi yang sempurna, dan jika tidak, buang keputusan mereka.

Selain itu, dia berkata setakat yang saya tahu, tanpa mengira model, ia sebenarnya tidak mengeluarkan semula hasil penanda aras asal.

Netizen bergema bahawa ini adalah realiti penanda aras LLM...

Falcon - sumber terbuka, tersedia secara komersil, prestasi yang kukuh
Bercakap tentang Falcon, ia sebenarnya bernilai semakan yang baik.
Menurut LeCun, dalam era model besar, sumber terbuka adalah yang paling penting.
Selepas kod LLaMA Meta dibocorkan, pembangun dari semua lapisan masyarakat mula bersemangat untuk mencubanya.
Falcon ialah senjata menakjubkan yang dibangunkan oleh Institut Inovasi Teknologi (TII) di Abu Dhabi, Emiriah Arab Bersatu.
Dari segi prestasi ketika pertama kali dikeluarkan, Falcon menunjukkan prestasi yang lebih baik daripada LLaMA.
Pada masa ini, "Falcon" mempunyai tiga versi - 1B, 7B dan 40B.
TII berkata Falcon ialah model bahasa sumber terbuka paling berkuasa setakat ini. Versi terbesarnya, Falcon 40B, mempunyai 40 bilion parameter, yang masih sedikit lebih kecil dalam skala daripada LLaMA, yang mempunyai 65 bilion parameter.
Walau bagaimanapun, TII sebelum ini telah menyatakan bahawa walaupun saiznya kecil, Falcon mempunyai prestasi yang hebat.
Faisal Al Bannai, Setiausaha Agung Majlis Penyelidikan Teknologi Lanjutan (ATRC), percaya bahawa pengeluaran "Falcon" akan memecahkan jalan untuk mendapatkan LLM dan membolehkan penyelidik dan usahawan mencadangkan penyelesaian terbaik.

Dua versi FalconLM, Falcon 40B Instruct dan Falcon 40B, berada di antara dua teratas dalam ranking OpenLLM Hugging Face, manakala LLaMA Meta Terletak di tempat ketiga.
Masalah dengan kedudukan yang disebutkan di atas adalah betul-betul ini.
Walaupun kertas "Falcon" belum lagi dikeluarkan secara terbuka, Falcon 40B telah dilatih secara meluas mengenai set data rangkaian token 1 trilion yang disaring dengan teliti.
Penyelidik telah mendedahkan bahawa "Falcon" sangat mementingkan kepentingan mencapai prestasi tinggi pada data berskala besar semasa proses latihan.
Apa yang kita semua tahu ialah LLM sangat sensitif terhadap kualiti data latihan, itulah sebabnya penyelidik menghabiskan banyak usaha untuk membina sistem yang boleh melakukan pemprosesan yang cekap pada puluhan beribu-ribu saluran paip data teras CPU.
Tujuannya adalah untuk mengekstrak kandungan berkualiti tinggi daripada Internet berdasarkan penapisan dan penyahduplikasian.
Pada masa ini, TII telah mengeluarkan set data rangkaian yang diperhalusi, iaitu set data yang ditapis dan dinyahduplikasi dengan teliti. Amalan telah membuktikan bahawa ia sangat berkesan.
Model yang dilatih menggunakan set data ini sahaja boleh setanding dengan LLM lain, atau bahkan mengatasinya dalam prestasi. Ini menunjukkan kualiti dan pengaruh "Falcon" yang sangat baik.

Selain itu, model Falcon juga mempunyai keupayaan berbilang bahasa.
Ia memahami bahasa Inggeris, Jerman, Sepanyol dan Perancis, dan beberapa bahasa Eropah kecil seperti Belanda, Itali, Romania, Portugis, Czech, Poland dan Sweden yang saya juga tahu banyak tentang ia.
Falcon 40B ialah model sumber terbuka kedua selepas keluaran model H2O.ai.
Selain itu, terdapat satu lagi perkara yang sangat penting - Falcon kini merupakan satu-satunya model sumber terbuka yang boleh digunakan secara percuma secara komersial.
Pada awalnya, TII menghendaki bahawa jika Falcon digunakan untuk tujuan komersial dan menjana lebih daripada $1 juta dalam pendapatan boleh diagihkan, 10% "cukai penggunaan" akan dikenakan.
Tetapi tidak mengambil masa lama untuk taikun Timur Tengah yang kaya untuk menarik balik sekatan ini.
Sekurang-kurangnya buat masa ini, semua penggunaan komersial dan penalaan halus Falcon adalah percuma.
Orang kaya berkata bahawa mereka tidak perlu menjana wang melalui model ini buat masa ini.
Selain itu, TII juga meminta rancangan pengkomersilan dari seluruh dunia.
Untuk penyelesaian penyelidikan saintifik dan pengkomersilan yang berpotensi, mereka juga akan menyediakan lebih banyak "sokongan kuasa pengkomputeran latihan" atau menyediakan peluang pengkomersilan selanjutnya.

Ini bermaksud: Selagi projek itu bagus, model itu percuma! Kuasa pengkomputeran yang mencukupi! Jika anda tidak mempunyai wang yang mencukupi, kami masih boleh mengumpulnya untuk anda!
Untuk pemula, ini hanyalah "penyelesaian sehenti untuk keusahawanan model besar AI" daripada taikun Timur Tengah.
Menurut pasukan pembangunan, aspek penting kelebihan daya saing FalconLM ialah pemilihan data latihan.
Pasukan penyelidik membangunkan proses untuk mengekstrak data berkualiti tinggi daripada set data rangkak awam dan mengalih keluar data pendua.
Selepas pembersihan menyeluruh kandungan berlebihan dan pendua, 5 trilion token telah dikekalkan - cukup untuk melatih model bahasa yang berkuasa.
40B Falcon LM menggunakan 1 trilion token untuk latihan, dan versi 7B model menggunakan 1.5 trilion token untuk latihan.
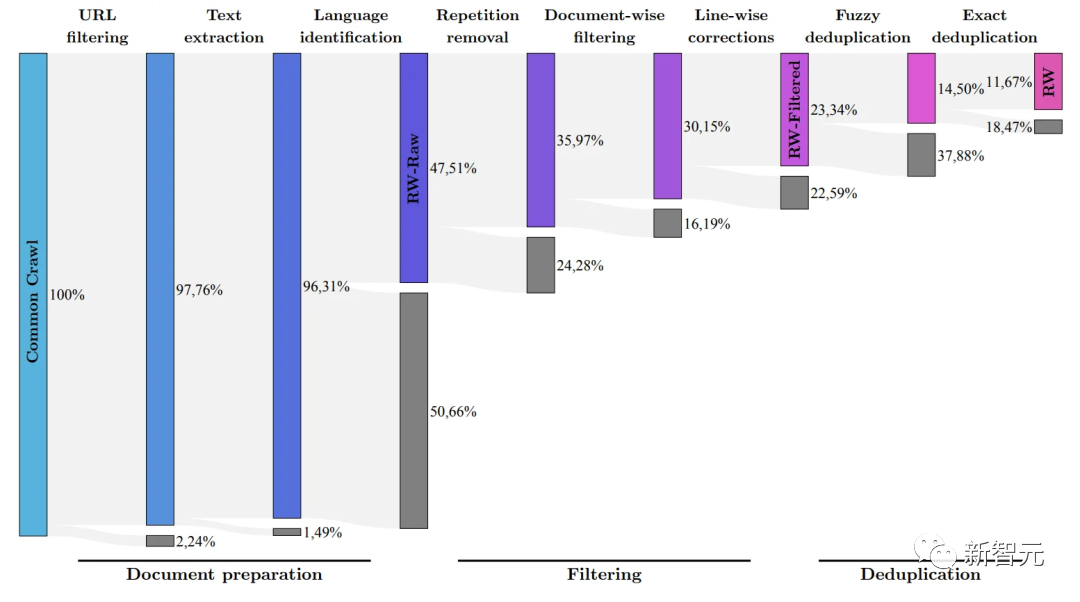
(Pasukan penyelidik bertujuan untuk menapis hanya data mentah berkualiti tinggi daripada Common Crawl menggunakan set data RefinedWeb)
Selain itu, kos latihan Falcon secara relatifnya lebih terkawal.
TII menyatakan bahawa berbanding dengan GPT-3, Falcon mencapai peningkatan prestasi yang ketara sambil menggunakan hanya 75% daripada belanjawan pengkomputeran latihan.
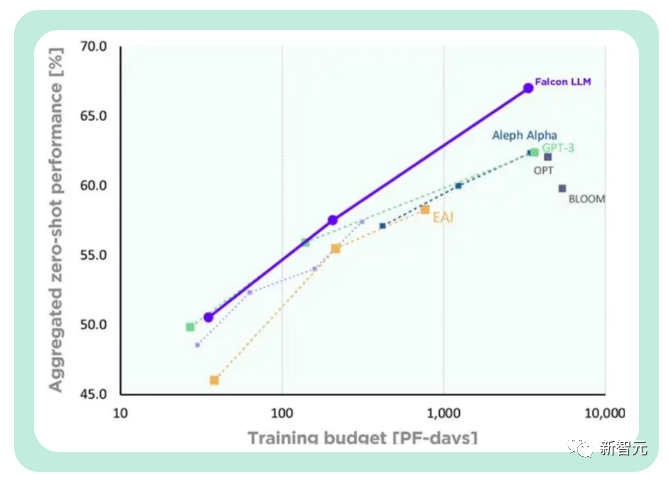
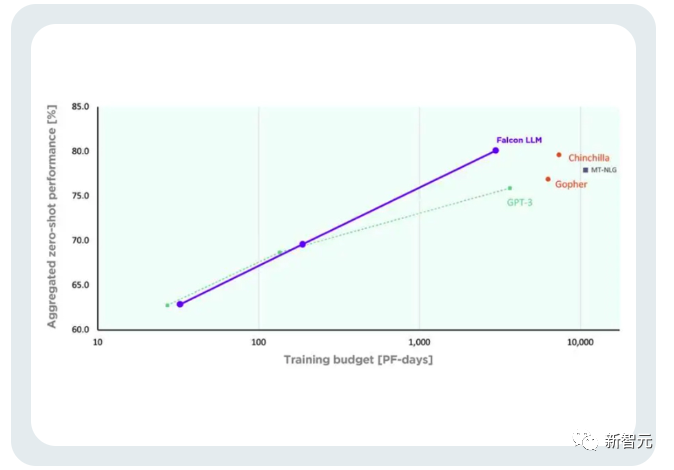
Dan ia hanya memerlukan 20% daripada masa pengiraan semasa inferens, yang telah berjaya dilaksanakan Penggunaan yang cekap bagi sumber pengkomputeran.
Atas ialah kandungan terperinci Pukul LLaMA? Kedudukan 'Falcon' yang paling berkuasa dalam sejarah diragui, Fu Yao secara peribadi menguji 7 baris kod, dan LeCun memajukannya untuk menyukai. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI