
Rumah >Peranti teknologi >AI >Menyahmistifikasi beberapa teknik peningkatan suara berasaskan AI yang digunakan dalam panggilan masa nyata
Menyahmistifikasi beberapa teknik peningkatan suara berasaskan AI yang digunakan dalam panggilan masa nyata

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-10 08:58:231532semak imbas

Pengenalan latar belakang
Selepas komunikasi audio dan video masa nyata RTC menjadi infrastruktur yang amat diperlukan dalam kehidupan dan kerja orang ramai, pelbagai teknologi yang terlibat juga sentiasa berubah untuk menangani masalah berbilang senario yang kompleks, seperti cara memberikan pengguna pengalaman pendengaran yang jelas dan realistik dalam senario berbilang peranti, berbilang orang dan berbilang hingar dalam senario audio.
Sebagai persidangan antarabangsa utama dalam bidang penyelidikan pemprosesan isyarat pertuturan, ICASSP (International Conference on Acoustics, Speech and Signal Processing) sentiasa mewakili hala tuju penyelidikan yang paling canggih dalam bidang akustik. ICASSP 2023 termasuk beberapa artikel yang berkaitan dengan algoritma peningkatan pertuturan isyarat audio Antaranya, Enjin Gunung Berapi RTC Pasukan audio mempunyai sejumlah 4. kertas penyelidikan telah diterima oleh persidangan itu, meliputi topik peningkatan pertuturan khusus pembesar suara, pembatalan gema, peningkatan pertuturan berbilang saluran dan pemulihan kualiti bunyi. Artikel ini akan memperkenalkan masalah teras teras dan penyelesaian teknikal yang diselesaikan oleh empat kertas ini, dan berkongsi pemikiran dan amalan pasukan audio Volcano Engine RTC dalam bidang pengurangan hingar suara, pembatalan gema dan gangguan penyingkiran suara manusia.
"Peningkatan khusus pembesar suara berdasarkan rangkaian saraf berulang segmentasi jalur"
Alamat kertas:
https ://www.php.cn/link/73740ea85c4ec25f00f9acbd859f861d
Terdapat banyak masalah yang perlu diselesaikan dalam tugasan peningkatan pertuturan khusus pembesar suara masa nyata. Pertama, mengumpul lebar jalur frekuensi penuh bunyi meningkatkan kesukaran pemprosesan model. Kedua, berbanding dengan senario bukan masa nyata, adalah lebih sukar untuk model dalam senario masa nyata untuk mengesan pembesar suara sasaran. pemprosesan masa. Diilhamkan oleh perhatian pendengaran manusia, Enjin Volcano mencadangkan Modul Perhatian Pembesar Suara (SAM) yang memperkenalkan maklumat pembesar suara, dan menggabungkannya dengan gabungan rangkaian saraf berulang model-band peningkatan pertuturan saluran tunggal segmentasi (Band- Split Recurrent Neural Network, BSRNN), membina sistem peningkatan pertuturan manusia yang khusus sebagai modul pasca pemprosesan model pembatalan gema, dan mengoptimumkan lata kedua-dua model.
Struktur rangka kerja model
RNN split band, BSRNN ) ialah model SOTA untuk peningkatan pertuturan jalur penuh dan pemisahan muzik Strukturnya ditunjukkan dalam rajah di atas. BSRNN terdiri daripada tiga modul iaitu Modul Band-Split, Modul Band and Sequence Modeling dan Modul Band-Merge. Modul pembahagian jalur frekuensi mula-mula membahagikan spektrum kepada jalur frekuensi K Selepas ciri setiap jalur frekuensi dinormalkan kelompok (BN), ia dimampatkan kepada dimensi ciri yang sama dengan lapisan K yang disambungkan sepenuhnya (FC). Selepas itu, ciri-ciri semua jalur frekuensi digabungkan menjadi tensor tiga dimensi dan diproses selanjutnya oleh modul pemodelan jujukan jalur frekuensi, yang menggunakan GRU untuk memodelkan secara bergilir-gilir dimensi jalur masa dan frekuensi tensor ciri. Ciri yang diproses akhirnya melalui modul penggabungan jalur frekuensi untuk mendapatkan fungsi penutup spektrum akhir sebagai output Pertuturan yang dipertingkatkan boleh diperolehi dengan mendarab topeng spektrum dan spektrum input. Untuk membina model peningkatan pertuturan khusus pembesar suara, kami menambah modul perhatian pembesar suara selepas modul pemodelan setiap jujukan jalur frekuensi.
Modul Perhatian Pembesar Suara (SAM)
Struktur Modul Perhatian Pembesar Suara adalah seperti yang ditunjukkan di atas. Idea teras ialah menggunakan vektor pembenaman pembesar suara
e sebagai penarik ciri perantaraan model peningkatan pertuturan dan mengira perkaitan antaranya dengan ciri perantaraan pada setiap masa dan jalur frekuensi  s
s
h. Formula khusus adalah seperti berikut: Pertama, e dan h diubah menjadi k dan q melalui sambungan dan lilitan penuh:
K dan q didarab untuk mendapatkan perhatian Nilai Force:
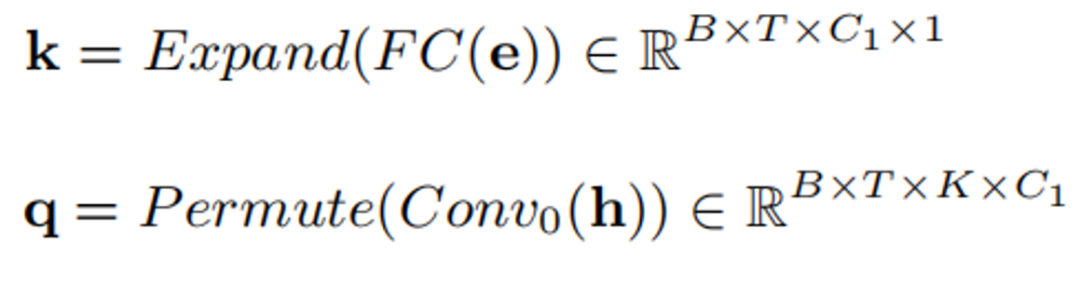
Akhir sekali, ciri asal diskalakan mengikut nilai perhatian:
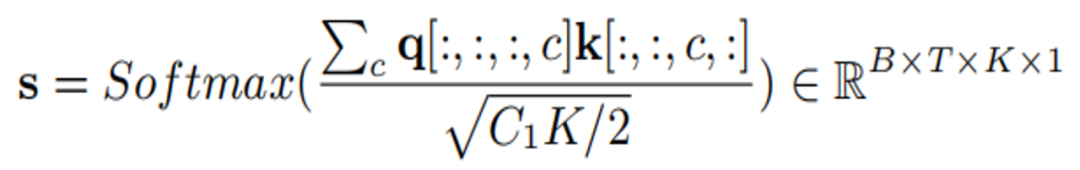
Data latihan model
Mengenai data latihan model, kami menggunakan data daripada trek peningkatan pertuturan khusus pembesar suara DNS ke-5 dan data pertuturan berkualiti tinggi DiDispeech Selepas pembersihan data, kami memperoleh kira-kira 3500 ucapan yang jelas. Dari segi pembersihan data, kami menggunakan model pra-latihan berdasarkan pengecaman pembesar suara ECAPA-TDNN [1] untuk membuang baki pertuturan pembesar suara yang mengganggu dalam data pertuturan, dan juga menggunakan model pra-latihan yang memenangi tempat pertama dalam Cabaran DNS Ke-4 untuk Mengalih keluar sisa hingar daripada data pertuturan. Dalam fasa latihan, kami menjana lebih daripada 100,000 data suara 4s, menambah denungan pada audio ini untuk mensimulasikan saluran yang berbeza dan mencampurkannya secara rawak dengan bunyi bising dan vokal gangguan, menetapkannya menjadi satu jenis hingar, dua jenis hingar, hingar dan gangguan. pertuturan Terdapat 4 senario gangguan: manusia dan hanya penceramah yang mengganggu. Pada masa yang sama, tahap pertuturan bising dan pertuturan sasaran diskalakan secara rawak untuk mensimulasikan input dengan saiz yang berbeza.
"Penyelesaian Teknikal untuk Gabungan Pengekstrakan Pembesar Suara Khusus dan Pembatalan Gema"
Alamat kertas:
https : //www.php.cn/link/7c7077ca5231fd6ad758b9d49a2a1eeb
Pembatalan gema sentiasa menjadi isu yang sangat kompleks dan penting dalam senario penyiaran luaran. Untuk mengekstrak isyarat pertuturan bersih hampir akhir berkualiti tinggi, Volcano Engine mencadangkan sistem pembatalan gema ringan yang menggabungkan pemprosesan isyarat dan teknologi pembelajaran mendalam. Berdasarkan Personalized Deep Noise Suppression (pDNS), kami terus membina sistem Personalized Acoustic Echo Cancellation (pAEC), yang merangkumi modul pra-pemprosesan berdasarkan pemprosesan isyarat digital, modul pra-pemprosesan berdasarkan model dua peringkat deep rangkaian saraf dan modul pengekstrakan pertuturan khusus pembesar suara berdasarkan BSRNN dan SAM.

Rangka kerja keseluruhan pembatalan gema khusus pembesar suara
Pra-pemprosesan pembatalan gema linear berdasarkan Modul pemprosesan isyarat digital
Modul pra-pemprosesan terutamanya merangkumi dua bahagian: pampasan kelewatan masa (TDC) dan pembatalan gema linear (LAEC), yang kedua-duanya dilakukan pada ciri sub-jalur.

Rangka kerja algoritma pembatalan gema linear sub-jalur pemprosesan isyarat
Pampasan kelewatan
TDC adalah berdasarkan korelasi silang subjalur, yang mula-mula menganggarkan kelewatan dalam setiap subjalur secara berasingan, dan kemudian menggunakan kaedah pengundian untuk menentukan kelewatan masa terakhir.
Pembatalan Gema Linear
LAEC ialah kaedah penapisan penyesuaian sub-jalur berdasarkan NLMS, yang terdiri daripada dua penapis: pra-penapis (Pra-penapis) dan pasca-penapis (Pas-penapis) , penapis pasca menggunakan langkah dinamik untuk mengemas kini parameter secara adaptif, dan prapenapis ialah sandaran pasca penapis yang stabil. Berdasarkan perbandingan sisa tenaga keluaran oleh pra-penapis dan pasca-penapis, akhirnya diputuskan isyarat ralat mana yang hendak digunakan.

Carta alir pemprosesan LAEC
Berdasarkan konvolusi berbilang peringkat - rangkaian neural konvolusi kitaran (CRN ) ) model dua peringkat
Kami mengesyorkan anda memisahkan tugas pAEC kepada dua tugas: "penindasan gema" dan "pengekstrakan pembesar suara khusus" untuk mengurangkan tekanan pemodelan model. Oleh itu, rangkaian pasca pemprosesan terutamanya terdiri daripada dua modul rangkaian saraf: modul berasaskan CRN yang ringan untuk pembatalan gema awal dan penindasan hingar, dan modul pasca pemprosesan berasaskan pDNS untuk pembinaan semula isyarat pertuturan hampir akhir.
Fasa 1: Modul ringan berasaskan CRN
Modul ringan berasaskan CRN terdiri daripada modul mampatan jalur, pengekod, dua GRU dwi-laluan, penyahkod dan Ia terdiri daripada frekuensi modul penguraian jalur. Pada masa yang sama, kami juga memperkenalkan modul Pengesanan Aktiviti Suara (VAD) untuk pembelajaran berbilang tugas, yang membantu meningkatkan persepsi pertuturan hampir tamat. CRN mengambil amplitud mampatan sebagai input dan mengeluarkan topeng nisbah ideal kompleks awal (cIRM) dan kebarangkalian VAD medan dekat isyarat sasaran.
Peringkat kedua: modul pasca pemprosesan berasaskan pDNS
Modul pDNS pada peringkat ini termasuk rangkaian saraf berulang segmentasi jalur BSRNN yang diperkenalkan di atas dan modul mekanisme perhatian pembesar suara SAM, modul lata Ia adalah disambung secara bersiri selepas modul CRN ringan. Memandangkan sistem pDNS kami telah mencapai prestasi yang agak cemerlang dalam tugas peningkatan pertuturan pembesar suara yang berciri, kami menggunakan parameter model pDNS terlatih sebagai parameter pemulaan peringkat kedua model untuk memproses output peringkat sebelumnya.
Fungsi kehilangan pengoptimuman latihan sistem lata
Kami menambah baik model dua peringkat melalui pengoptimuman lata supaya ia boleh meramalkan pertuturan hampir akhir pada peringkat pertama dan meramalkan pembesar suara tertentu dalam peringkat kedua hampir hujung suara. Kami juga menyertakan penalti pengesanan aktiviti pertuturan untuk kedekatan dengan pembesar suara untuk meningkatkan keupayaan model untuk mengecam pertuturan pada jarak dekat. Fungsi kehilangan khusus ditakrifkan seperti berikut:

Antaranya,
sepadan dengan ciri STFT yang diramalkan pada peringkat pertama dan kedua model masing-masing, mewakili pertuturan hampir akhir dan ciri STFT bagi pertuturan khusus hampir akhir,
masing-masing mewakili ramalan model dan keadaan VAD sasaran.
Data latihan model
Untuk membolehkan sistem pembatalan gema mengendalikan gema daripada berbilang peranti, berbilang bergema dan berbilang adegan pengumpulan hingar, kami memperoleh 2000+ jam latihan dengan mencampurkan gema dan bersih pertuturan Data tersebut, antaranya, data gema menggunakan data pertuturan tunggal hujung AEC Challenge 2023, pertuturan bersih datang daripada Cabaran DNS 2023 dan LibriSpeech, dan set RIR yang digunakan untuk mensimulasikan gema hampir hujung datang daripada Cabaran DNS. Memandangkan gema dalam data bual tunggal hujung AEC 2023 mengandungi sejumlah kecil data hingar, menggunakan data ini secara langsung kerana gema boleh membawa kepada herotan pertuturan hampir akhir Untuk mengurangkan masalah ini, kami menggunakan kaedah mudah tetapi strategi pembersihan data yang berkesan, menggunakan pra-pemprosesan Model AEC terlatih memproses data saluran tunggal jauh, mengenal pasti data dengan tenaga sisa yang lebih tinggi sebagai data hingar, dan berulang kali mengulangi proses pembersihan yang ditunjukkan di bawah.
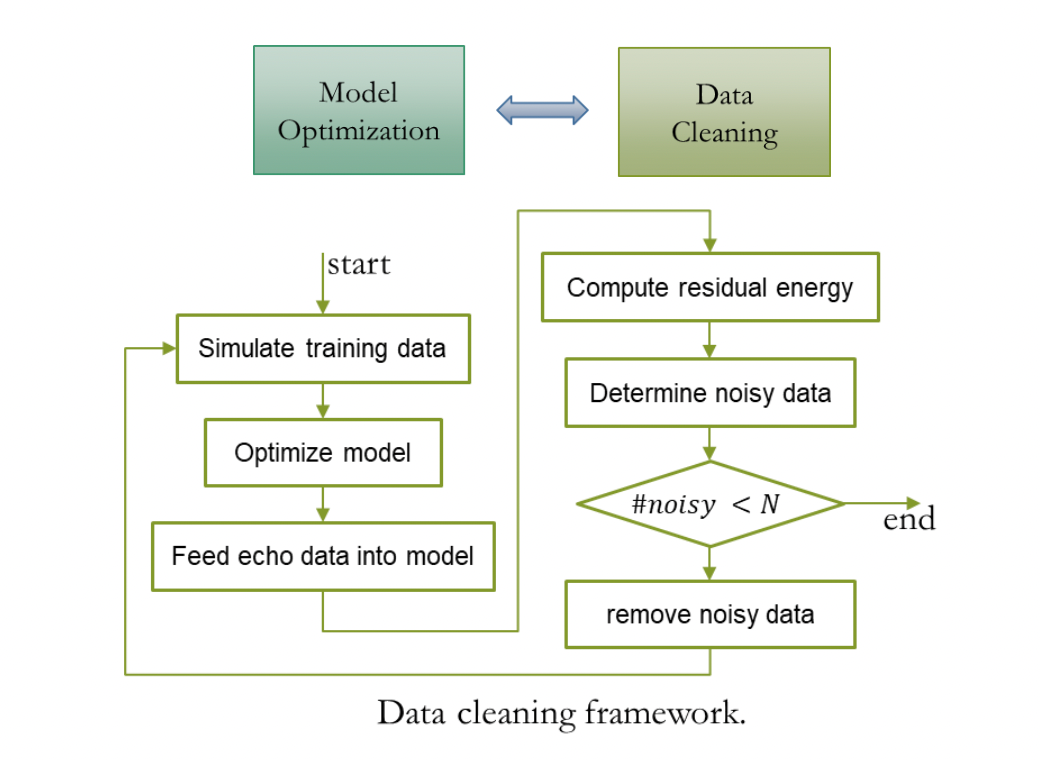
Kesan Sistem Skim Pengoptimuman Lata
Sistem peningkatan pertuturan sedemikian berdasarkan pembatalan gema bersatu dan pengekstrakan pembesar suara khusus telah dipersembahkan di ICASSP 2023 AEC Challenge Blind Its kelebihan dalam penunjuk subjektif dan objektif telah disahkan pada set ujian [2] - ia mencapai skor pendapat subjektif 4.44 (Subjektif-MOS) dan kadar ketepatan pengecaman pertuturan sebanyak 82.2% (WAcc).

"Peningkatan pertuturan berbilang saluran berdasarkan mekanisme perhatian konvolusi Fourier"
Alamat kertas:
https://www.php.cn/link/373cb8cd58cad5f1309b31c56e2d5a83
Anggaran berat rasuk berdasarkan pembelajaran mendalam kini merupakan salah satu kaedah arus perdana untuk menyelesaikan tugasan peningkatan pertuturan berbilang saluran, iaitu menapis isyarat berbilang saluran dengan menyelesaikan pemberat rasuk melalui rangkaian untuk mendapatkan pertuturan tulen. Dalam anggaran berat rasuk, peranan maklumat spektrum dan maklumat spatial adalah serupa dengan prinsip menyelesaikan matriks kovarians ruang dalam algoritma pembentukan rasuk tradisional. Walau bagaimanapun, banyak pembentuk rasuk saraf sedia ada tidak dapat menganggarkan berat rasuk secara optimum. Untuk menangani cabaran ini, Volcano Engine mencadangkan Fourier Convolutional Attention Encoder (FCAE), yang boleh menyediakan medan penerimaan global pada paksi ciri frekuensi dan meningkatkan ciri konteks paksi frekuensi. Pada masa yang sama, kami juga mencadangkan struktur Convolutional Recurrent Encoder-Decoder (CRED) berasaskan FCAE untuk menangkap ciri kontekstual spektrum dan maklumat spatial daripada ciri input. Struktur rangka kerja modelRangkaian anggaran berat rasuk
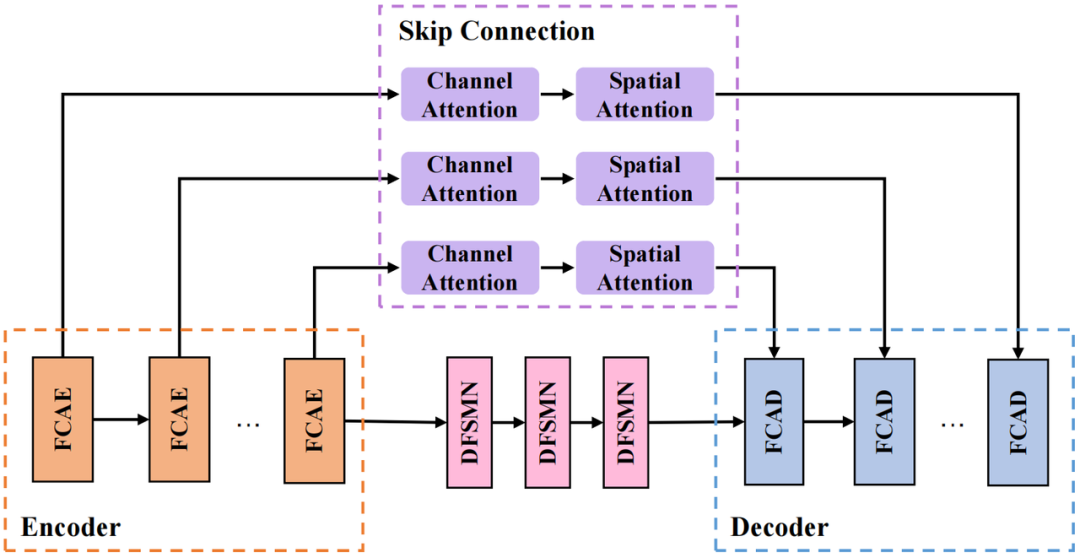
Struktur CRED yang kami pakai ditunjukkan dalam rajah di atas. Antaranya, FCAE ialah pengekod perhatian convolutional Fourier, dan FCAD ialah penyahkod yang simetri dengan FCAE modul menggunakan Rangkaian Memori Berurutan Dalam Suapan (DFSMN) untuk memodelkan pergantungan temporal jujukan tanpa menjejaskan model prestasi; bahagian sambungan lompat menggunakan modul perhatian saluran bersiri (Perhatian Saluran) dan perhatian ruang (Perhatian Ruang) untuk mengekstrak maklumat spatial rentas saluran dan menyambungkan lapisan dalam Ciri dan ciri cetek memudahkan penghantaran maklumat dalam rangkaian.
Struktur FCAE
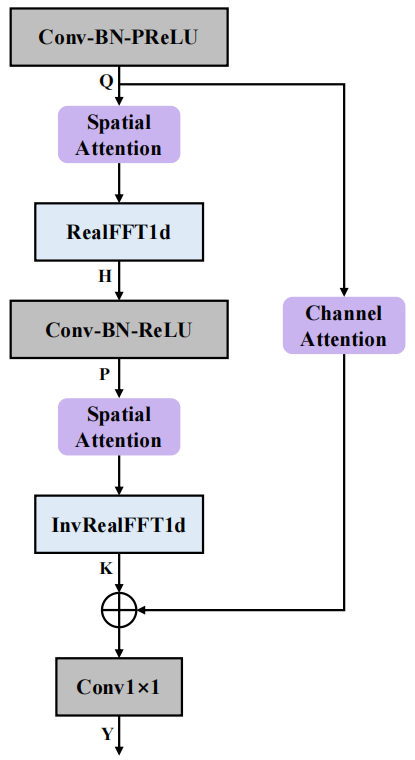
Struktur Fourier Convolutional Attention Encoder (FCAE) ditunjukkan dalam rajah di atas. Diilhamkan oleh operator lilitan Fourier [3], modul ini mengambil kesempatan daripada fakta bahawa kemas kini transformasi Fourier diskret pada mana-mana titik dalam domain transformasi akan memberi kesan global pada isyarat dalam domain asal, dan melakukan on- analisis frekuensi ciri paksi frekuensi Melalui transformasi FFT dimensi, medan penerimaan global boleh diperolehi pada paksi frekuensi, dengan itu meningkatkan pengekstrakan ciri konteks pada paksi frekuensi. Di samping itu, kami memperkenalkan modul perhatian spatial dan modul perhatian saluran untuk meningkatkan lagi keupayaan ekspresi konvolusi, mengekstrak maklumat sendi spektrum-spatial yang bermanfaat, dan meningkatkan pembelajaran rangkaian tentang ciri-ciri yang boleh dibezakan bagi pertuturan dan hingar tulen. Dari segi prestasi akhir, rangkaian mencapai peningkatan pertuturan berbilang saluran yang sangat baik dengan hanya parameter 0.74M.
Data latihan model
Dari segi set data, kami menggunakan set data sumber terbuka yang disediakan oleh pertandingan ConferencingSpeech 2021 Data ucapan bersih termasuk AISHELL-1, AISHELL-3, VCTK dan LibriSpeech (pembersih kereta api -360), pilih data dengan nisbah isyarat kepada hingar yang lebih besar daripada 15dB untuk menjana pertuturan campuran berbilang saluran dan gunakan MUSAN dan AudioSet sebagai set data hingar. Pada masa yang sama, untuk mensimulasikan senario gema berbilang bilik yang sebenar, data sumber terbuka telah digabungkan dengan lebih daripada 5,000 tindak balas impuls bilik dengan mensimulasikan perubahan dalam saiz bilik, masa dengung, sumber bunyi, lokasi sumber hingar, dsb., dan akhirnya menjana lebih daripada 60,000 sampel latihan berbilang saluran.
"Sistem Pemulihan Kualiti Bunyi Berdasarkan Model Rangkaian Neural Dua peringkat"
Alamat kertas:
https: //www.php.cn/link/e614f646836aaed9f89ce58e837e2310
Enjin Volcano juga telah membuat beberapa percubaan pada pembaikan kualiti bunyi, termasuk meningkatkan pertuturan pembesar suara tertentu, mengeliminasi gema dan mempertingkatkan audio berbilang saluran. Dalam proses komunikasi masa nyata, bentuk herotan yang berbeza akan menjejaskan kualiti isyarat pertuturan, mengakibatkan penurunan kejelasan dan kebolehfahaman isyarat pertuturan. Volcano Engine mencadangkan model dua peringkat yang menggunakan strategi pecah dan takluk berperingkat untuk membaiki pelbagai herotan yang menjejaskan kualiti pertuturan.
Struktur bingkai model
Gambar di bawah menunjukkan komposisi rangka kerja keseluruhan model dua peringkat Antaranya, model peringkat pertama terutamanya membaiki bahagian spektrum yang hilang, dan yang kedua -model peringkat terutamanya menghalang bunyi bising, bergema dan artifak Kemungkinan daripada model peringkat pertama.

Model peringkat pertama: Membaiki Net
Penggunaan keseluruhan seni bina Rangkaian Berulang Konvolusi Kompleks Dalam (DCCRN) [4] , termasuk tiga bahagian: Pengekod , modul pemodelan masa dan Penyahkod. Diilhamkan oleh pembaikan imej, kami memperkenalkan lilitan nilai kompleks Gate dan lilitan alih nilai kompleks Gate untuk menggantikan lilitan alih nilai kompleks dan lilitan alih nilai kompleks dalam Pengekod dan Penyahkod. Untuk meningkatkan lagi keaslian bahagian pembaikan audio, kami memperkenalkan Diskriminator Berbilang Tempoh dan Diskriminator Berbilang Skala untuk latihan tambahan.
Model peringkat kedua: Denoising Net
Keseluruhan seni bina S-DCCRN diguna pakai, termasuk tiga bahagian: Pengekod, dua sub-modul DCCRN ringan dan Penyahkod, di mana dua DCCRN ringan Sub- modul melaksanakan pemodelan sub-jalur dan jalur penuh masing-masing. Untuk meningkatkan keupayaan model dalam pemodelan domain masa, kami menggantikan LSTM dalam sub-modul DCCRN dengan Squeezed Temporal Convolutional Module (STCM).
Data latihan model
Audio, hingar dan gema yang bersih yang digunakan untuk latihan bagi pemulihan kualiti bunyi semuanya daripada set data pertandingan DNS 2023, di mana jumlah tempoh audio bersih ialah 750 jam dan jumlah tempoh bunyi ialah 170 jam. Semasa penambahan data model peringkat pertama, kami menggunakan audio jalur penuh untuk berbelit dengan penapis yang dijana secara rawak, dengan panjang tetingkap 20ms untuk menetapkan titik pensampelan audio secara rawak kepada sifar dan menurunkan sampel secara rawak untuk mensimulasikan kehilangan spektrum tangan, frekuensi amplitud audio dan titik pengumpulan audio masing-masing didarab dengan skala rawak pada peringkat kedua penambahan data, kami menggunakan data yang telah dijana pada peringkat pertama untuk menggabungkan pelbagai jenis impuls bilik dengan tahap gema yang berbeza.
Kesan pemprosesan audio
Dalam Cabaran AEC ICASSP 2023, pasukan audio Volcano Engine RTC memenangi dua kejuaraan di trek, dan memenangi penghormatan dalampenindasan gema dwi-talk , perlindungan suara hampir hujung dwi-bual, penindasan hingar latar belakang bual-bual tunggal hampir hujung, pemarkahan kualiti audio subjektif yang komprehensif dan ketepatan pengecaman pertuturan akhir, dsb. Penunjuknya jauh lebih baik daripada pasukan lain yang mengambil bahagian dan telah mencapai peringkat antarabangsa peringkat terkemuka.
Mari kita lihat kesan pemprosesan peningkatan suara Volcano Engine RTC dalam senario berbeza selepas penyelesaian teknikal di atas. Pembatalan gema dalam senario nisbah isyarat-ke-bunyi-gema yang berbezaDua contoh berikut menunjukkan kesan perbandingan algoritma pembatalan gema sebelum dan selepas pemprosesan dalam tenaga isyarat-ke-gema yang berbeza senario nisbah.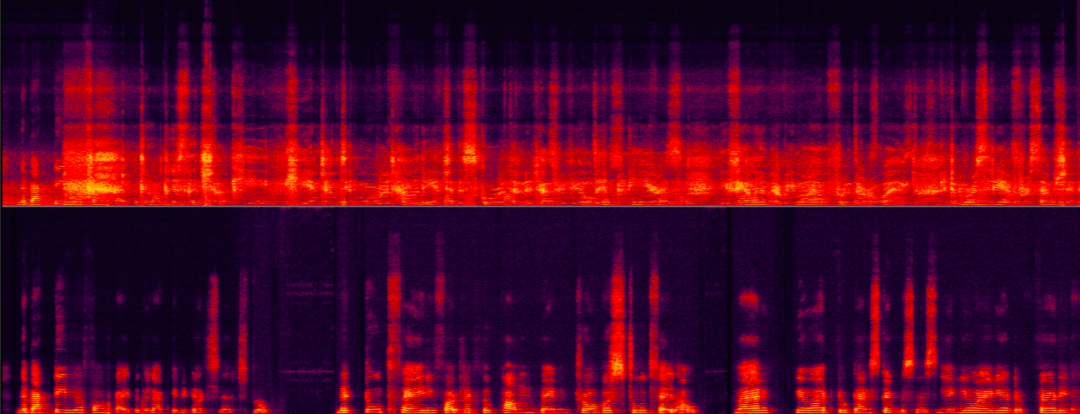
Adegan nisbah gema huruf sederhana
Adegan nisbah gema isyarat ultra-rendah menimbulkan cabaran terbesar untuk pembatalan gema Pada masa ini, kita bukan sahaja perlu mengeluarkan gema bertenaga tinggi dengan berkesan, tetapi juga mengekalkan pertuturan sasaran yang lemah pada tahap yang paling besar pada masa yang sama. Suara pembesar suara bukan sasaran (gema) hampir sepenuhnya membayangi suara pembesar suara sasaran (perempuan), menjadikannya sukar untuk dikenal pasti.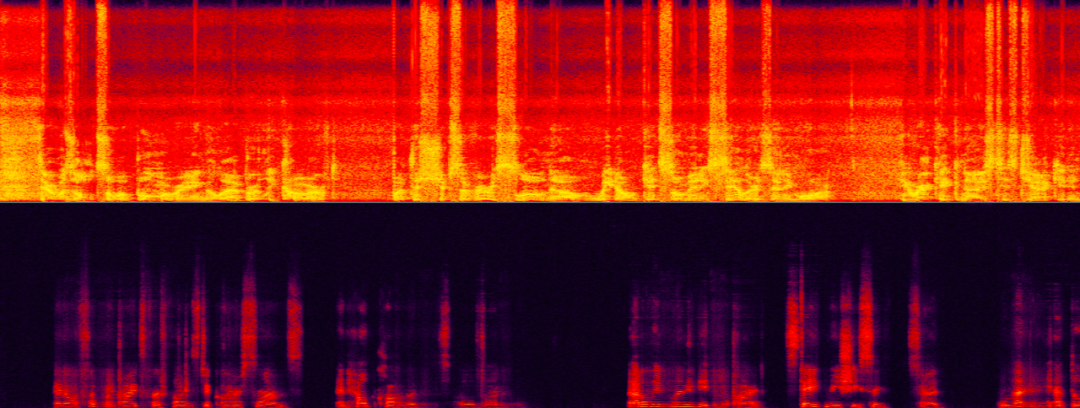
Adegan nisbah gema isyarat super rendah
Pengekstrakan pembesar suara di bawah senario gangguan latar belakang yang berbezaDua contoh berikut masing-masing menunjukkan kesan perbandingan algoritma pengekstrakan pembesar suara tertentu sebelum dan selepas memproses dalam senario gangguan hingar dan latar belakang. Dalam sampel berikut, pembesar suara khusus mempunyai gangguan bunyi seperti loceng pintu dan gangguan bunyi latar belakang Menggunakan pengurangan hingar AI sahaja hanya boleh mengeluarkan bunyi loceng pintu, jadi ia juga perlu melakukan pemprosesan vokal untuk yang khusus. penceramah.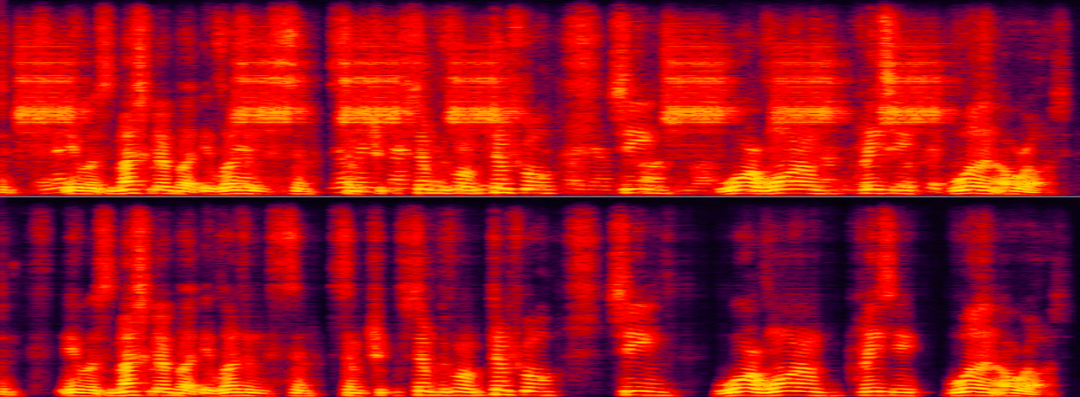
Sasarkan pembesar suara dan latar belakang yang mengganggu vokal dan bunyi
Apabila ciri cap suara suara pembesar suara sasaran dan suara mengganggu latar belakang sangat hampir, cabaran untuk algoritma pengekstrakan pembesar suara khusus adalah lebih besar pada masa ini dan ia boleh menguji keteguhan algoritma pengekstrakan pembesar suara tertentu. Dalam sampel berikut, pembesar suara sasaran dan suara mengganggu latar belakang ialah dua suara perempuan yang serupa.

Suara wanita sasaran bercampur dengan suara wanita gangguan
Ringkasan dan TinjauanDi atas memperkenalkan beberapa penyelesaian dan kesan yang dibuat oleh pasukan audio Volcano Engine RTC berdasarkan pembelajaran mendalam dalam pengurangan hingar pembesar suara tertentu, pembatalan gema, peningkatan pertuturan berbilang saluran, dsb. Senario masa depan masih berhadapan dengan Cabaran dalam pelbagai arah, seperti cara menyesuaikan pengurangan hingar suara kepada adegan hingar, cara melakukan pembaikan pelbagai jenis isyarat audio dalam julat pembaikan kualiti bunyi yang lebih luas, dan cara menjalankan model ringan dan kerumitan rendah pada pelbagai terminal, cabaran ini juga akan Ini akan menjadi hala tuju penyelidikan fokus kami yang seterusnya.
Atas ialah kandungan terperinci Menyahmistifikasi beberapa teknik peningkatan suara berasaskan AI yang digunakan dalam panggilan masa nyata. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI