
Rumah >Peranti teknologi >AI >Menambah keupayaan audio-visual yang komprehensif pada model bahasa yang besar, DAMO Academy membuka sumber Video-LLaMA
Menambah keupayaan audio-visual yang komprehensif pada model bahasa yang besar, DAMO Academy membuka sumber Video-LLaMA

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-09 21:28:041675semak imbas
Video memainkan peranan yang semakin penting dalam media sosial dan budaya Internet hari ini, Douyin, Kuaishou, Bilibili, dll. telah menjadi platform popular untuk ratusan juta pengguna. Pengguna berkongsi detik hidup mereka, karya kreatif, detik menarik dan kandungan lain di sekitar video untuk berinteraksi dan berkomunikasi dengan orang lain.
Baru-baru ini, model bahasa yang besar telah menunjukkan keupayaan yang mengagumkan. Bolehkah kita melengkapkan model besar dengan "mata" dan "telinga" supaya mereka boleh memahami video dan berinteraksi dengan pengguna?
Bermula daripada masalah ini, penyelidik dari DAMO Academy mencadangkan Video-LLaMA, model besar dengan keupayaan audio-visual yang komprehensif. Video-LLaMA boleh melihat dan memahami isyarat video dan audio dalam video, dan boleh memahami arahan input pengguna untuk menyelesaikan satu siri tugasan kompleks berdasarkan audio dan video, seperti penerangan audio/video, penulisan, soal jawab, dsb. Pada masa ini, kertas, kod dan demo interaktif semuanya terbuka. Di samping itu, pada halaman utama projek Video-LLaMA, pasukan penyelidik juga menyediakan model versi Cina untuk menjadikan pengalaman pengguna Cina lebih lancar.

- Pautan kertas: https://arxiv.org/abs/2306.02858
- Alamat kod: https://github.com/DAMO-NLP-SG/Video-LLaMA
- Alamat demo:
- Modelscope: https://modelscope.cn/studios /damo/video-llama/summary
- Peluk muka: https://huggingface.co/spaces/DAMO-NLP-SG/Video-LLaMA
- Contoh alamat fail input:
- https://www.php cn /link/0fbce6c74ff376d18cb352e7fdc6273b
Reka bentuk model
Video-LLaMA mengguna pakai prinsip reka bentuk modular dan visual untuk menggabungkan aspek reka bentuk modular dan visual video. Maklumat modaliti audio dipetakan ke dalam ruang input model bahasa yang besar untuk mencapai keupayaan untuk mengikuti arahan silang mod. Tidak seperti penyelidikan model besar sebelumnya (MiNIGPT4, LLaVA) yang memfokuskan pada pemahaman imej statik, Video-LLaMA menghadapi dua cabaran dalam pemahaman video: menangkap perubahan pemandangan dinamik dalam penglihatan dan menyepadukan isyarat audio-visual.
Untuk menangkap perubahan pemandangan dinamik dalam video, Video-LLaMA memperkenalkan cabang bahasa visual boleh pasang. Cawangan ini mula-mula menggunakan pengekod imej terlatih dalam BLIP-2 untuk mendapatkan ciri individu bagi setiap bingkai imej, dan kemudian menggabungkannya dengan pembenaman kedudukan bingkai yang sepadan Semua ciri imej dihantar ke Video Q-Former dan Video Q -Bekas akan Mengagregatkan perwakilan imej peringkat bingkai dan menjana perwakilan video sintetik panjang tetap. Akhir sekali, lapisan linear digunakan untuk menjajarkan perwakilan video ke ruang benam model bahasa besar.
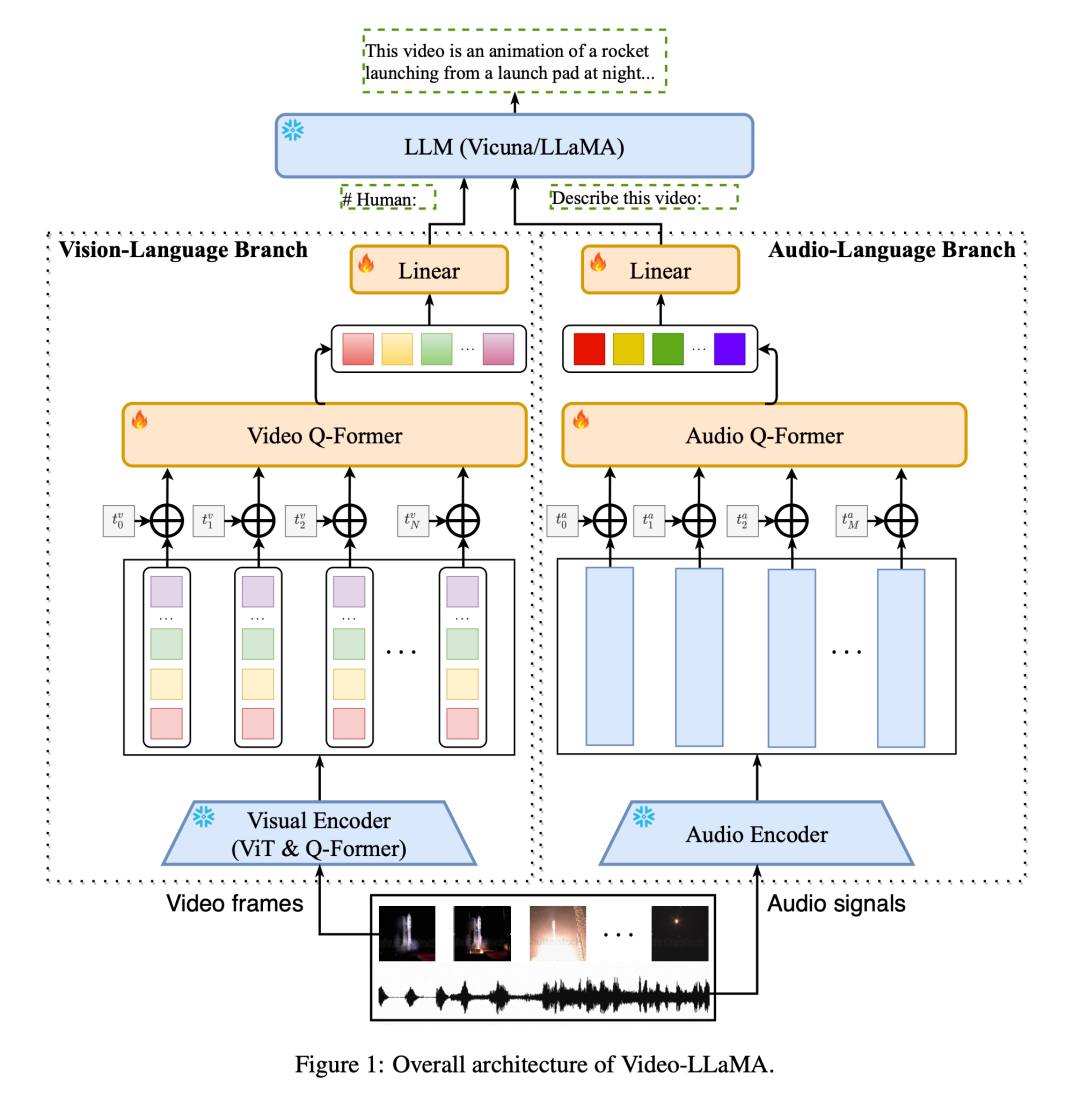
Bagi isyarat bunyi dalam video, Video-LLaMA menggunakan cawangan bahasa audio untuk pemprosesan. Pertama, berbilang klip audio dua saat diambil secara seragam daripada video asal dan setiap klip ditukar kepada spektrogram mel 128 dimensi. Kemudian, ImageBind yang berkuasa digunakan sebagai pengekod audio untuk mengekstrak ciri setiap klip bunyi secara individu. Selepas menambahkan pembenaman kedudukan yang boleh dipelajari, Audio Q-Former mengagregatkan ciri segmen secara keseluruhan dan menjana ciri audio panjang tetap. Sama seperti cabang bahasa visual, lapisan linear akhirnya digunakan untuk menjajarkan perwakilan audio ke ruang benam model bahasa besar.
Untuk mengurangkan kos latihan, Video-LLaMA membekukan pengekod imej/audio yang telah dilatih dan hanya mengemas kini parameter berikut dalam cabang visual dan audio: Video/Audio Q-Former , lapisan pengekodan kedudukan dan lapisan linear (ditunjukkan dalam Rajah 1).
Untuk mengetahui perhubungan penjajaran antara penglihatan dan teks, pengarang terlebih dahulu melatih cabang penglihatan menggunakan set data teks video berskala besar (WebVid-2M) dan set data teks imej (CC-595K). Selepas itu, pengarang menggunakan set data arahan imej daripada MiniGPT-4, LLaVA dan set data arahan video daripada Video-Chat untuk diperhalusi bagi mencapai keupayaan mengikut arahan silang mod yang lebih baik.
Bagi pembelajaran perhubungan penjajaran teks audio, disebabkan kekurangan data teks audio berkualiti tinggi berskala besar, pengarang menggunakan strategi penyelesaian untuk mencapai matlamat ini. Pertama, matlamat parameter yang boleh dipelajari dalam cabang audio-linguistik boleh difahami sebagai menjajarkan output pengekod audio dengan ruang benam LLM. Pengekod audio ImageBind mempunyai keupayaan penjajaran berbilang modal yang sangat kuat, yang boleh menyelaraskan benam modaliti yang berbeza ke dalam ruang bersama. Oleh itu, pengarang menggunakan data teks visual untuk melatih cawangan bahasa audio, menjajarkan ruang pembenaman biasa ImageBind ke ruang pembenaman teks LLM, dengan itu mencapai modaliti audio kepada penjajaran ruang pembenaman teks LLM. Dengan cara yang bijak ini, Video-LLaMA dapat menunjukkan keupayaan untuk memahami audio semasa inferens, walaupun ia tidak pernah dilatih mengenai data audio.
Contoh demonstrasi
Pengarang menunjukkan beberapa contoh Video-LLaMA video/audio/dialog berasaskan imej.
(1) Dua contoh berikut menunjukkan keupayaan persepsi audio-visual yang komprehensif Video-LLaMA Perbualan dalam contoh berkisar pada video audio. Dalam Contoh 2, hanya pemain yang ditunjukkan pada skrin, tetapi bunyi adalah sorakan dan tepukan penonton Jika model hanya boleh menerima isyarat visual, ia tidak akan dapat menyimpulkan respons positif penonton tiada bunyi alat muzik dalam audio Tetapi terdapat saksofon dalam gambar Jika model hanya boleh menerima isyarat pendengaran, ia tidak akan tahu bahawa pemain memainkan saksofon.

(2) Video-LLaMA juga mempunyai keupayaan pemahaman persepsi yang kuat untuk imej statik, dan boleh melengkapkan penerangan imej, soalan dan jawab Tunggu tugasan.

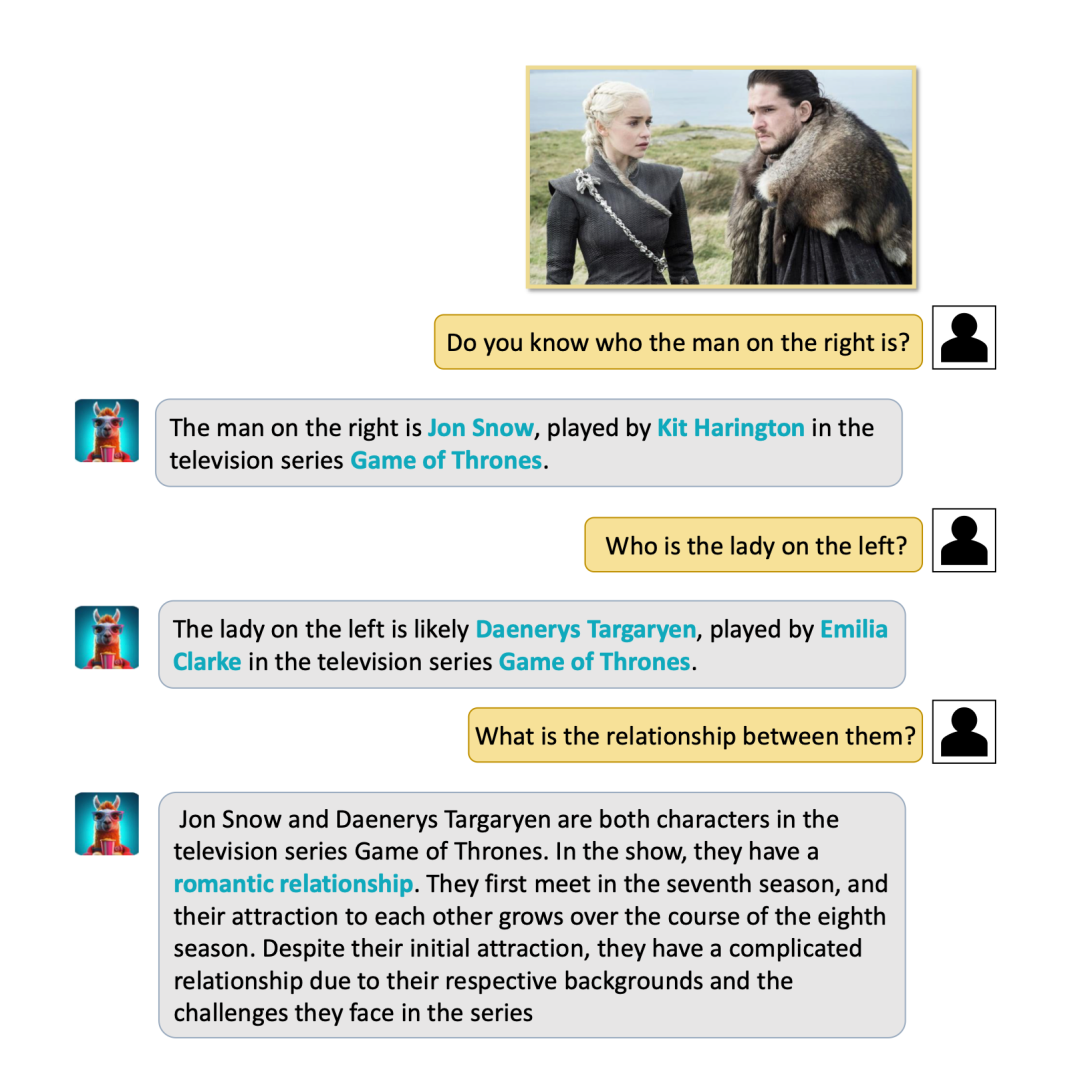
(3) Anehnya, Video-LLaMA boleh berjaya mengenal pasti tanda tempat dan orang terkenal, serta boleh Melakukan Soal Jawab yang waras. Sebagai contoh, VIdeo-LLaMA di bawah berjaya mengenal pasti Rumah Putih dan memperkenalkan situasi Rumah Putih. Contoh lain ialah memasukkan foto pegun Long Ma dan Jon Snow (watak dalam filem klasik dan siri televisyen "Game of Thrones" VIdeo-LLaMA bukan sahaja berjaya mengenal pasti mereka, tetapi juga memberitahu mereka tentang hubungan mereka yang sentiasa wujud disunting dan dikacau.

(4) Peristiwa dinamik khusus video , Video-llama juga boleh menangkap dengan baik, seperti pergerakan catcall dan arah bot.

Ringkasan
Pada masa ini, pemahaman audio dan video masih sangat kompleks dan tiada penyelesaian yang matang namun Walaupun Video-LLaMA telah menunjukkan keupayaan yang mengagumkan, penulis juga menyebut bahawa ia mempunyai beberapa batasan.
(1) Keupayaan persepsi terhad: Keupayaan visual dan pendengaran Video-LLaMA masih agak asas, dan masih sukar untuk membezakan maklumat visual dan bunyi yang kompleks. Sebahagian daripada sebabnya ialah kualiti dan saiz set data tidak cukup baik. Kumpulan penyelidikan ini sedang berusaha keras untuk membina set data penjajaran teks audio-video-teks berkualiti tinggi untuk meningkatkan keupayaan persepsi model.
(2) Kesukaran memproses video panjang: Video panjang (seperti filem dan rancangan TV) mengandungi sejumlah besar maklumat, yang memerlukan keupayaan penaakulan yang tinggi dan sumber pengkomputeran untuk model.
(3) Masalah halusinasi yang wujud dalam model bahasa masih wujud dalam Video-LLaMA.
Secara amnya, Video-LLaMA, sebagai model besar dengan keupayaan audio-visual yang komprehensif, telah mencapai hasil yang mengagumkan dalam bidang pemahaman audio dan video. Apabila penyelidik terus bekerja keras, cabaran di atas akan diatasi satu demi satu, menjadikan model pemahaman audio dan video mempunyai nilai praktikal yang luas.
Atas ialah kandungan terperinci Menambah keupayaan audio-visual yang komprehensif pada model bahasa yang besar, DAMO Academy membuka sumber Video-LLaMA. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI