
Rumah >Peranti teknologi >AI >'Meletakkan' model parameter 33 bilion yang besar ke dalam GPU gred pengguna tunggal, mempercepatkan 15% tanpa mengorbankan prestasi
'Meletakkan' model parameter 33 bilion yang besar ke dalam GPU gred pengguna tunggal, mempercepatkan 15% tanpa mengorbankan prestasi

- PHPzke hadapan
- 2023-06-07 22:33:211436semak imbas
Prestasi model bahasa besar yang telah dilatih (LLM) pada tugasan tertentu terus bertambah baik Selepas itu, jika arahan segera sesuai, ia boleh digeneralisasikan dengan lebih baik kepada lebih banyak tugasan kepada peningkatan dalam data latihan dan parameter Walau bagaimanapun, trend terkini menunjukkan bahawa penyelidik lebih memfokuskan pada model yang lebih kecil, tetapi model ini dilatih pada lebih banyak data dan oleh itu lebih mudah untuk digunakan.
Sebagai contoh, LLaMA dengan saiz parameter 7B dilatih pada token 1T Walaupun prestasi purata lebih rendah sedikit daripada GPT-3, saiz parameter ialah 1/25 daripada yang terakhir . Bukan itu sahaja, tetapi teknologi pemampatan semasa boleh memampatkan lagi model ini, dengan ketara mengurangkan keperluan memori sambil mengekalkan prestasi. Dengan penambahbaikan sedemikian, model yang berprestasi baik boleh digunakan pada peranti pengguna akhir seperti komputer riba.
Walau bagaimanapun, ini menghadapi satu lagi cabaran, iaitu cara memampatkan model ini kepada saiz yang cukup kecil agar sesuai dengan peranti ini, sambil mengambil kira kualiti penjanaan. Penyelidikan menunjukkan bahawa walaupun model dimampatkan menjana jawapan dengan ketepatan yang boleh diterima, teknik pengkuantitian 3-4-bit sedia ada masih merendahkan ketepatan. Memandangkan penjanaan LLM dilakukan secara berurutan dan bergantung pada token yang dijana sebelum ini, ralat relatif kecil terkumpul dan membawa kepada rasuah keluaran yang teruk. Untuk memastikan kualiti yang boleh dipercayai, adalah penting untuk mereka bentuk kaedah pengkuantitian lebar bit rendah yang tidak merendahkan prestasi ramalan berbanding model 16-bit.
Walau bagaimanapun, mengkuantifikasi setiap parameter kepada 3-4 bit selalunya mengakibatkan kehilangan ketepatan yang sederhana atau tinggi, terutamanya 1-10B yang sangat sesuai untuk penggunaan tepi Model yang lebih kecil dalam julat parameter.
Untuk menyelesaikan masalah ketepatan, penyelidik dari University of Washington, ETH Zurich dan institusi lain mencadangkan format mampatan baharu dan teknologi pengkuantitian SpQR (Sparse-Quantized Representation, sparse - quantified representasi), mencapai pemampatan hampir-lossless LLM merentas skala model buat kali pertama sambil mencapai tahap mampatan yang serupa dengan kaedah sebelumnya.
SpQR berfungsi dengan mengenal pasti dan mengasingkan pemberat anomali yang menyebabkan ralat pengkuantitian yang sangat besar, menyimpannya dengan ketepatan yang lebih tinggi sambil memampatkan semua pemberat lain Ke kedudukan 3-4, kurang daripada 1% ketepatan relatif kebingungan kerugian dicapai dalam LLaMA dan Falcon LLM. Ini membolehkan LLM parameter 33B dijalankan pada satu GPU pengguna 24GB tanpa sebarang penurunan prestasi sambil 15% lebih pantas.
Algoritma SpQR adalah cekap dan boleh mengekod pemberat ke dalam format lain dan menyahkodnya dengan cekap semasa masa jalan. Secara khusus, penyelidikan ini menyediakan SpQR dengan algoritma inferens GPU yang cekap yang membolehkan inferens lebih pantas daripada model garis dasar 16-bit sambil mencapai lebih 4x keuntungan mampatan memori.

- Alamat kertas: https://arxiv.org/pdf/2306.03078.pdf
- Alamat projek: https://github.com/Vahe1994/SpQR
Kaedah
Penyelidikan ini mencadangkan format baharu pengkuantitian jarang hibrid - Perwakilan Kuantiti Jarang (SpQR), yang boleh memampatkan LLM pra-latihan dengan tepat kepada 3-4 bit setiap parameter sambil kekal hampir tanpa kerugian.
Secara khusus, kajian membahagikan keseluruhan proses kepada dua langkah. Langkah pertama ialah pengesanan outlier: kajian mula-mula mengasingkan pemberat terpencil dan menunjukkan bahawa pengkuantitian mereka membawa kepada ralat yang tinggi: pemberat terpencil kekal dengan ketepatan tinggi, manakala pemberat lain disimpan dengan ketepatan rendah (mis. dalam format 3-bit). Kajian kemudiannya melaksanakan varian pengkuantitian berkumpulan dengan saiz kumpulan yang sangat kecil dan menunjukkan bahawa skala pengkuantitian itu sendiri boleh dikuantisasi menjadi perwakilan 3-bit.
SpQR sangat mengurangkan jejak memori LLM tanpa mengorbankan ketepatan, sambil menghasilkan LLM 20%-30% lebih pantas berbanding inferens 16-bit.
Tambahan pula, kajian mendapati kedudukan pemberat sensitif dalam matriks berat tidak rawak tetapi mempunyai struktur tertentu. Untuk menyerlahkan strukturnya semasa kuantifikasi, kajian mengira sensitiviti setiap berat dan memvisualisasikan sensitiviti berat ini untuk model LLaMA-65B. Rajah 2 di bawah menggambarkan unjuran keluaran lapisan perhatian diri terakhir LLaMA-65B.
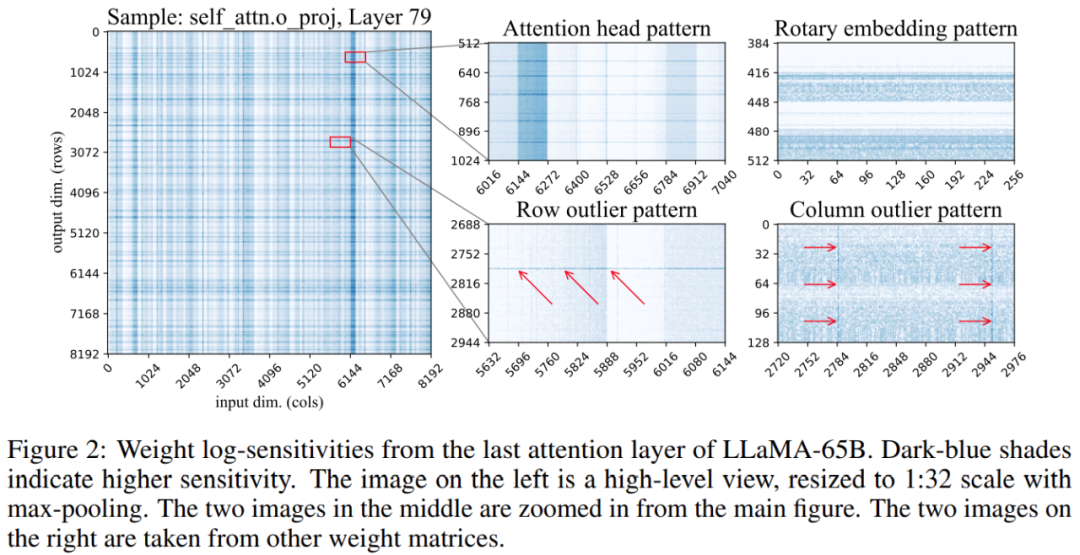
Kajian ini membuat dua perubahan pada proses kuantifikasi: satu untuk menangkap kumpulan berat sensitif yang kecil Digunakan untuk menangkap outlier individu . Rajah 3 di bawah menunjukkan seni bina keseluruhan SpQR:
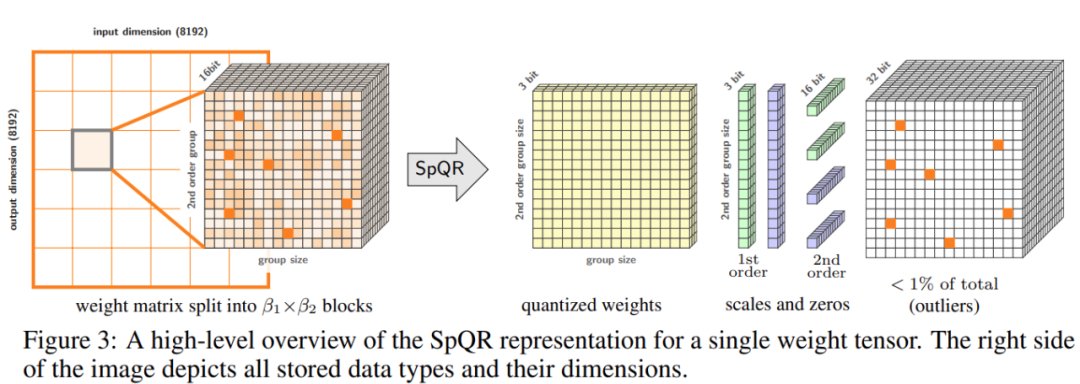
Jadual berikut menunjukkan algoritma pengkuantitian SpQR, dan serpihan kod di sebelah kiri menerangkan keseluruhan proses, coretan kod di sebelah kanan mengandungi subrutin untuk kuantifikasi sekunder dan mencari outlier:

Kajian ini akan SpQR dibandingkan dengan dua skim pengkuantitian lain: GPTQ, RTN (pembundaran-ke-terdekat), dan dua metrik digunakan untuk menilai prestasi model pengkuantitian. Yang pertama ialah pengukuran kebingungan, menggunakan set data termasuk WikiText2, Penn Treebank dan C4 yang kedua ialah ketepatan sampel sifar pada lima tugas: WinoGrande, PiQA, HellaSwag, ARC-easy, ARC-challenge;
Hasil utama. Keputusan Rajah 1 menunjukkan bahawa pada saiz model yang serupa, SpQR menunjukkan prestasi yang lebih baik daripada GPTQ (dan RTN yang sepadan), terutamanya pada model yang lebih kecil. Penambahbaikan ini disebabkan oleh SpQR mencapai lebih banyak pemampatan di samping mengurangkan degradasi kerugian.
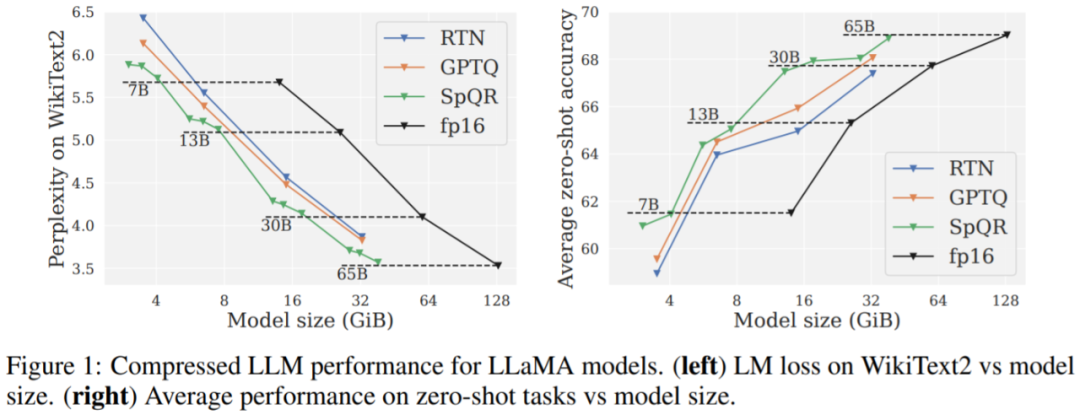
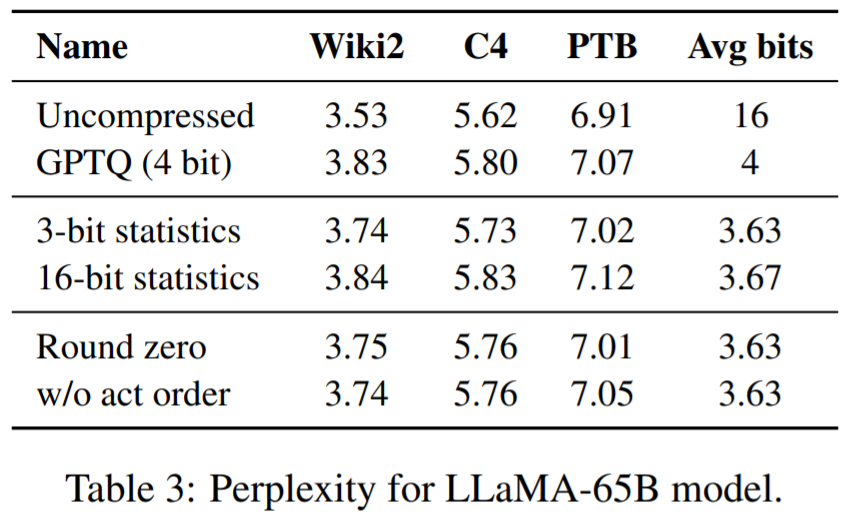
Jadual 1, Jadual 2 Keputusan menunjukkan bahawa untuk pengkuantitian 4-bit, ralat SpQR berbanding garis dasar 16-bit dibahagi dua berbanding kepada GPTQ.
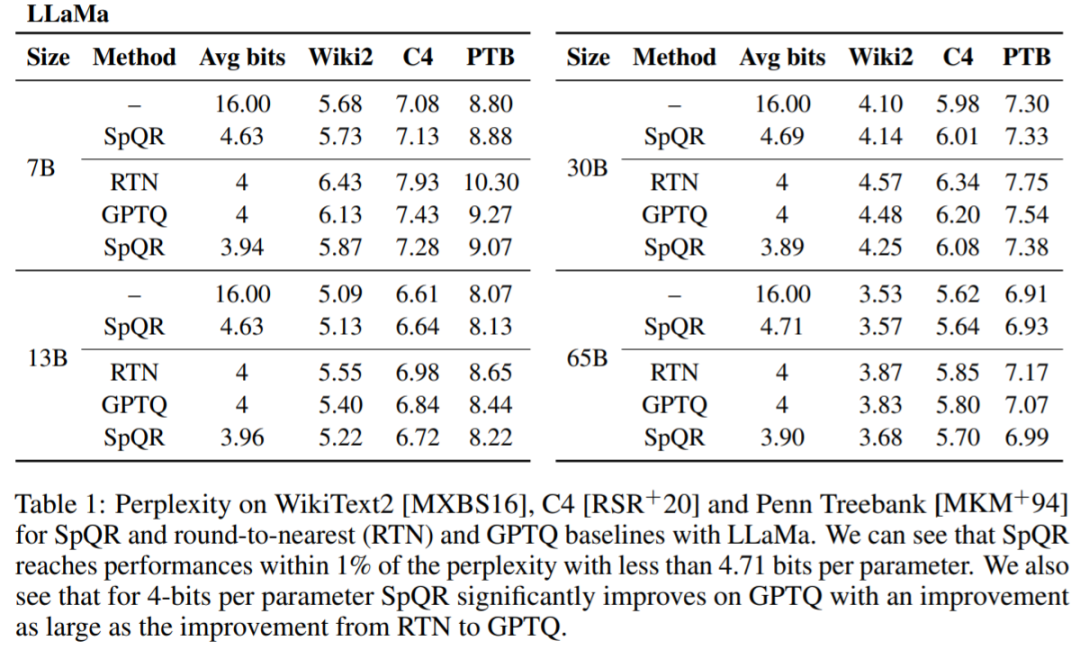
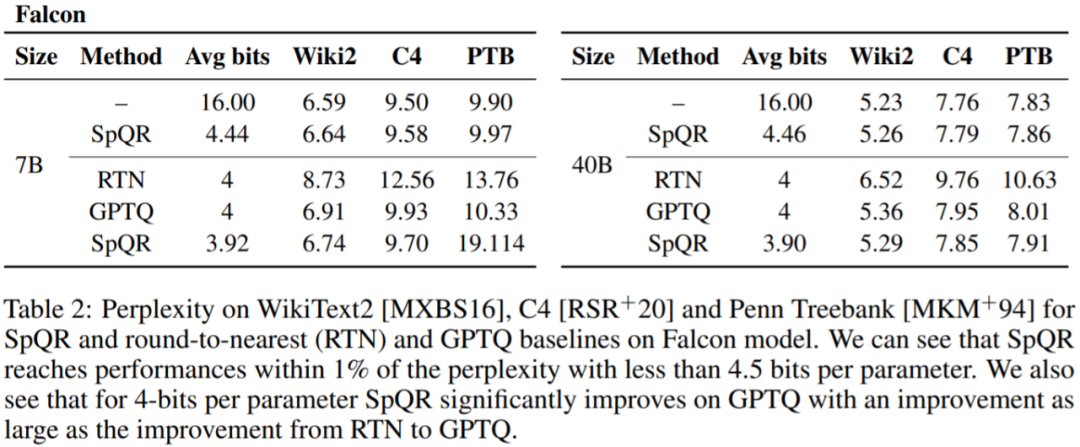
Jadual 3 melaporkan model LLaMA-65B Kekeliruan terhasil pada set data yang berbeza.
Akhir sekali, kajian menilai kelajuan inferens SpQR. Kajian ini membandingkan algoritma pendaraban matriks jarang yang direka khas dengan algoritma yang dilaksanakan dalam PyTorch (cuSPARSE), dan hasilnya ditunjukkan dalam Jadual 4. Seperti yang anda lihat, walaupun pendaraban matriks jarang standard dalam PyTorch tidak lebih pantas daripada inferens 16-bit, algoritma pendaraban matriks jarang yang direka khas dalam artikel ini boleh meningkatkan kelajuan sebanyak kira-kira 20-30%.

Atas ialah kandungan terperinci 'Meletakkan' model parameter 33 bilion yang besar ke dalam GPU gred pengguna tunggal, mempercepatkan 15% tanpa mengorbankan prestasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI