
Rumah >Peranti teknologi >AI >OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.
OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.

- 王林ke hadapan
- 2023-06-07 19:37:44750semak imbas
Baru-baru ini, tweet oleh Matthias Plappert mencetuskan perbincangan meluas dalam kalangan LLM.
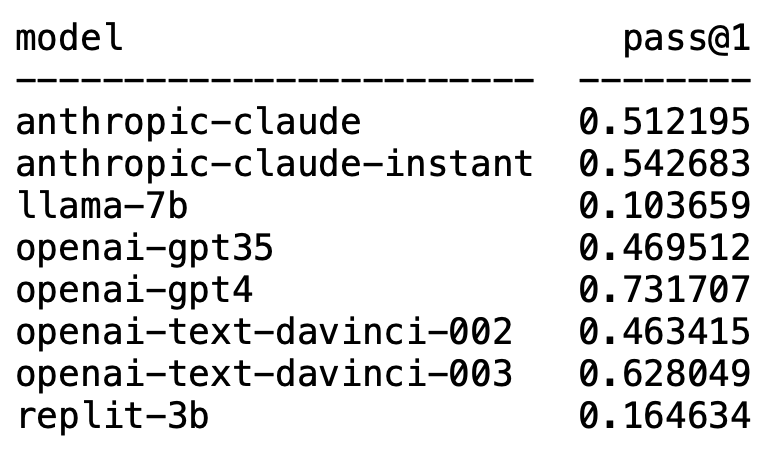
Plappert ialah seorang saintis komputer terkenal dia menerbitkan keputusan ujian penanda arasnya pada LLM arus perdana dalam lingkaran AI di HumanEval.
Pengujiannya berat sebelah terhadap penjanaan kod.
Hasilnya mengejutkan dan mengejutkan.

Tidak disangka-sangka, GPT-4 sudah pasti mendominasi senarai dan memenangi tempat pertama.
Tanpa diduga, teks-davinci-003 OpenAI tiba-tiba muncul dan menduduki tempat kedua.
Plappert berkata bahawa text-davinci-003 boleh dipanggil model "harta karun".
LLaMA yang biasa digunakan tidak mahir dalam penjanaan kod.
OpenAI mendominasi senarai
Plappert berkata bahawa prestasi GPT-4 lebih baik daripada data dalam literatur.
Data ujian satu pusingan GPT-4 dalam kertas ialah kadar lulus 67%, manakala ujian Plappert mencapai 73%.

Apabila menganalisis punca, beliau berkata terdapat banyak kemungkinan untuk perbezaan data. Salah satunya ialah gesaan yang dia berikan kepada GPT-4 adalah lebih baik sedikit berbanding ketika pengarang kertas itu mengujinya.
Sebab lain ialah dia mengagak suhu model itu bukan 0 apabila kertas menguji GPT-4.
"Suhu" ialah parameter yang digunakan untuk melaraskan kreativiti dan kepelbagaian apabila model menjana teks. "Suhu" ialah nilai yang lebih besar daripada 0, biasanya antara 0 dan 1. Ia mempengaruhi taburan kebarangkalian perkataan ramalan sampel apabila model menjana teks.
Apabila "suhu" model lebih tinggi (seperti 0.8, 1 atau lebih tinggi), model akan lebih cenderung untuk memilih daripada perkataan yang lebih pelbagai dan berbeza, yang menjadikan Teks yang dihasilkan adalah lebih berisiko dan lebih kreatif, tetapi mungkin juga menghasilkan lebih banyak ralat dan ketidakselarasan.
Apabila "suhu" rendah (seperti 0.2, 0.3, dll.), model terutamanya akan memilih daripada perkataan dengan kebarangkalian yang lebih tinggi, sekali gus menghasilkan teks yang lebih lancar dan lebih koheren .
Tetapi pada ketika ini, teks yang dijana mungkin kelihatan terlalu konservatif dan berulang.
Oleh itu, dalam aplikasi sebenar, adalah perlu untuk menimbang dan memilih nilai "suhu" yang sesuai berdasarkan keperluan khusus.
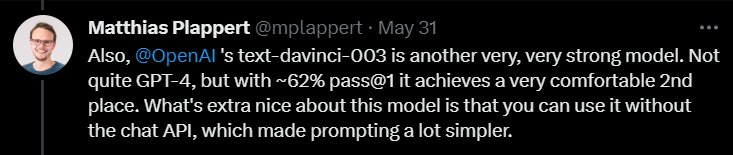
Seterusnya, apabila mengulas pada text-davinci-003, Plappert berkata bahawa ini juga merupakan model yang sangat berkebolehan di bawah OpenAI.
Walaupun ia tidak sehebat GPT-4, dengan kadar lulus 62% dalam satu pusingan ujian, ia masih kukuh menduduki tempat kedua.
Plappert menekankan bahawa perkara terbaik tentang text-davinci-003 ialah pengguna tidak perlu menggunakan API ChatGPT. Ini bermakna memberi gesaan boleh menjadi lebih mudah.
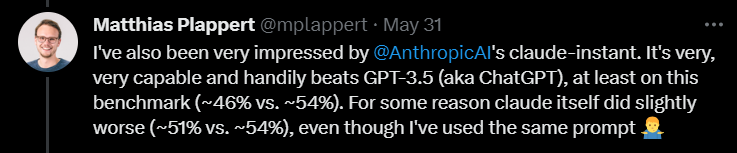
Selain itu, Plappert juga memberikan model segera klaude Anthropic AI penilaian yang agak tinggi.
Dia berpendapat prestasi model ini bagus dan boleh mengalahkan GPT-3.5. Kadar lulus GPT-3.5 ialah 46%, manakala kadar lulus claude-instant ialah 54%.
Sudah tentu, LLM Anthropic AI yang lain, claude, tidak boleh dimainkan oleh claude-instant, dan kadar lulus hanya 51%.
Plappert berkata bahawa gesaan yang digunakan untuk menguji kedua-dua model adalah sama.
Selain model biasa ini, Plappert juga telah menguji banyak model sumber terbuka kecil.
Plappert berkata adalah bagus dia boleh menjalankan model ini secara tempatan.
Walau bagaimanapun, dari segi skala, model ini jelas tidak sebesar model OpenAI dan Anthropic AI, jadi membandingkannya agak menggembirakan.

Penjanaan kod LLaMA? Sudah tentu, Plappert tidak berpuas hati dengan keputusan ujian LLaMA.
Berdasarkan keputusan ujian, LLaMA berprestasi sangat teruk dalam menjana kod. Mungkin kerana mereka menggunakan pensampelan kurang semasa mengumpul data daripada GitHub.
 Walaupun dibandingkan dengan Codex 2.5B, prestasi LLaMA bukanlah yang terbaik. (Kadar lulus 10% berbanding 22%)
Walaupun dibandingkan dengan Codex 2.5B, prestasi LLaMA bukanlah yang terbaik. (Kadar lulus 10% berbanding 22%)
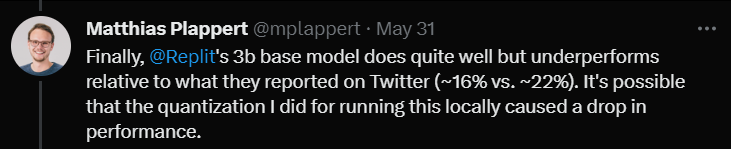
 Akhir sekali, dia menguji model saiz 3B Replit.
Akhir sekali, dia menguji model saiz 3B Replit.
Dia berkata bahawa prestasi itu tidak buruk, tetapi dibandingkan dengan data yang dipromosikan di Twitter (kadar lulus 16% berbanding 22%)
Plappert percaya ini mungkin kerana kaedah kuantifikasi yang digunakannya semasa menguji model ini menyebabkan kadar lulus menurun beberapa mata peratusan.
 Pada akhir ulasan, Plappert menyebut satu perkara yang menarik.
Pada akhir ulasan, Plappert menyebut satu perkara yang menarik.
Seorang pengguna mendapati di Twitter bahawa GPT-3.5-turbo berprestasi lebih baik apabila menggunakan Completion API (API penyiapan) platform Azure (bukannya Chat API) yang baik.
Plappert percaya bahawa fenomena ini mempunyai sedikit kesahihan, kerana memasukkan gesaan melalui API Sembang boleh menjadi agak rumit.
Atas ialah kandungan terperinci OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI