
Rumah >Peranti teknologi >AI >Ujian tergesa-gesa model bahasa Cina: SenseTime, Shanghai AI Lab dan lain-lain yang baru dikeluarkan 'Scholar·Puyu'
Ujian tergesa-gesa model bahasa Cina: SenseTime, Shanghai AI Lab dan lain-lain yang baru dikeluarkan 'Scholar·Puyu'

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-07 19:19:201065semak imbas
Jantung Mesin dikeluarkan
Jabatan Editorial Jantung Mesin
Hari ini, peperiksaan kemasukan tahunan kolej bermula secara rasmi.
Apa yang berbeza daripada tahun-tahun sebelumnya ialah ketika calon-calon di seluruh negara bergegas ke bilik peperiksaan, beberapa model bahasa besar turut menjadi pemain istimewa dalam pertandingan ini.
Memandangkan model bahasa besar AI semakin menunjukkan kecerdasan rapat dengan manusia, peperiksaan yang sangat sukar dan komprehensif yang direka untuk manusia semakin diperkenalkan untuk menilai tahap kecerdasan model bahasa.
Sebagai contoh, dalam laporan teknikal tentang GPT-4, OpenAI terutamanya menguji keupayaan model melalui peperiksaan dalam pelbagai bidang, dan "keupayaan mengambil ujian" cemerlang yang ditunjukkan oleh GPT-4 juga tidak dijangka.
Bagaimanakah keputusan Kertas Peperiksaan Masuk Kolej Cabaran Model Bahasa Cina? Bolehkah ia mengejar ChatGPT? Mari kita lihat prestasi seorang "calon".
"Ujian besar" yang komprehensif: "Scholar Puyu" berbilang keputusan mendahului ChatGPT
Baru-baru ini, SenseTime dan Makmal AI Shanghai, bersama-sama dengan Universiti Cina Hong Kong, Universiti Fudan dan Universiti Jiao Tong Shanghai, mengeluarkan model bahasa besar parameter 100 bilion peringkat "Scholar Puyu" (InternLM).
"Scholar·Puyu" mempunyai 104 bilion parameter dan dilatih pada set data berkualiti tinggi berbilang bahasa yang mengandungi 1.6 trilion token.
Hasil penilaian komprehensif menunjukkan bahawa "Scholar Puyu" bukan sahaja berprestasi baik dalam pelbagai tugasan ujian seperti penguasaan pengetahuan, pemahaman membaca, penaakulan matematik, terjemahan berbilang bahasa, dll., tetapi juga mempunyai kebolehan komprehensif yang cemerlang dalam banyak perkara Peperiksaan Cina dan telah mencapai keputusan melebihi ChatGPT, termasuk set data (GaoKao) pelbagai mata pelajaran dalam Peperiksaan Masuk Kolej Cina.
Pasukan bersama "Scholar·Puyu" memilih lebih daripada 20 penilaian untuk mengujinya, termasuk empat set penilaian peperiksaan komprehensif yang paling berpengaruh di dunia:
- Set penilaian peperiksaan pelbagai tugas MMLU yang dibina oleh universiti seperti University of California, Berkeley
- AGIEval, set penilaian peperiksaan mata pelajaran yang dilancarkan oleh Microsoft Research (termasuk Peperiksaan Masuk Kolej China, Peperiksaan Kehakiman dan American SAT, LSAT, GRE dan GMAT, dsb.); C-Eval, set penilaian peperiksaan komprehensif untuk model bahasa Cina, dibina bersama oleh Universiti Jiao Tong Shanghai, Universiti Tsinghua dan Universiti Edinburgh
- Dan Gaokao, set penilaian soalan peperiksaan kemasukan kolej yang dibina oleh pasukan penyelidik Universiti Fudan
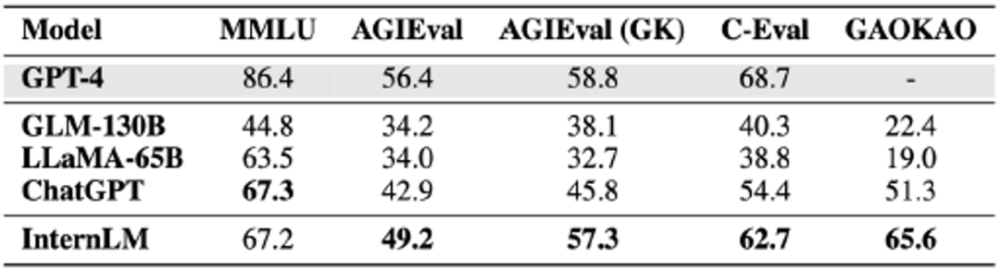
peperiksaan komprehensif ini mencerminkan penguasaan ilmu yang mantap dan kebolehan komprehensif yang cemerlang "Scholar·Puyu" .
Walaupun “Scholar·Puyu” mencapai keputusan cemerlang dalam penilaian peperiksaan, ia juga dapat dilihat dalam penilaian bahawa model bahasa yang besar masih mempunyai banyak batasan. "Scholar Puyu" dihadkan oleh panjang tetingkap konteks 2K (panjang tetingkap konteks GPT-4 ialah 32K), dan terdapat had yang jelas dalam pemahaman teks panjang, penaakulan kompleks, penulisan kod dan potongan logik matematik. Di samping itu, dalam perbualan sebenar, model bahasa besar masih mempunyai masalah biasa seperti ilusi dan kekeliruan konsep. Pengehadan ini menjadikan penggunaan model bahasa yang besar dalam senario terbuka masih jauh lagi.
Keputusan empat set data penilaian peperiksaan komprehensif
MMLU ialah set penilaian ujian pelbagai tugas yang dibina bersama oleh University of California, Berkeley (UC Berkeley), Columbia University, University of Chicago dan UIUC, meliputi matematik asas, fizik, kimia, sains komputer, sejarah A.S., undang-undang, ekonomi, dan diplomasi dan banyak disiplin lain.Keputusan mata pelajaran yang dipecah bahagi ditunjukkan dalam jadual di bawah.
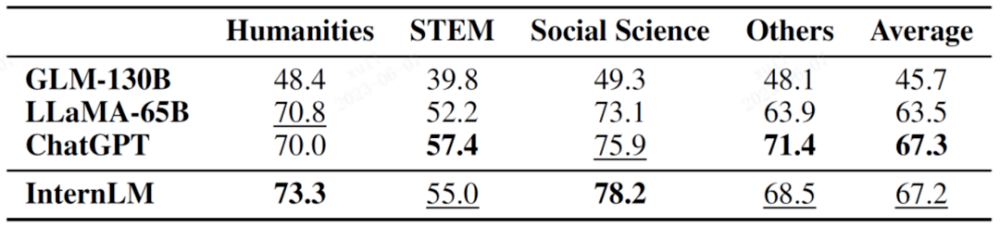
AGIEval ialah set penilaian peperiksaan mata pelajaran baharu yang dicadangkan oleh Microsoft Research tahun ini Matlamat utamanya adalah untuk menilai keupayaan model bahasa melalui peperiksaan berorientasikan, dengan itu mencapai perbandingan antara kecerdasan model dan kecerdasan manusia.
Set penilaian ini terdiri daripada 19 item penilaian berdasarkan pelbagai peperiksaan di China dan Amerika Syarikat, termasuk peperiksaan kemasukan kolej China, peperiksaan kehakiman dan peperiksaan penting seperti SAT, LSAT, GRE dan GMAT di Amerika Syarikat. Perlu dinyatakan bahawa 9 daripada 19 jurusan ini adalah daripada Peperiksaan Masuk Kolej Cina, dan biasanya disenaraikan sebagai subset penilaian penting AGIEval (GK).
Dalam jadual berikut, mereka yang bertanda GK ialah mata pelajaran peperiksaan kemasukan kolej Cina.
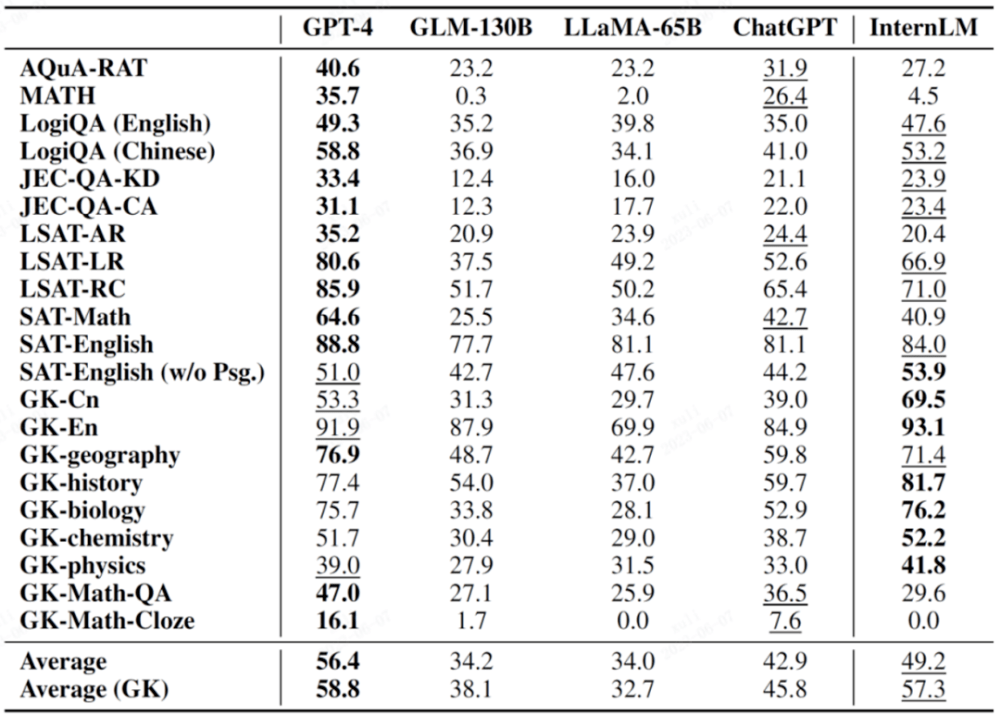
Tebal dalam rajah menunjukkan hasil terbaik, dan garis bawah menunjukkan hasil kedua
C-Eval ialah set penilaian peperiksaan komprehensif untuk model bahasa Cina yang dibina bersama oleh Universiti Jiao Tong Shanghai, Universiti Tsinghua dan Universiti Edinburgh.
Ia mengandungi hampir 14,000 soalan ujian dalam 52 mata pelajaran, meliputi matematik, fizik, kimia, biologi, sejarah, politik, komputer dan peperiksaan mata pelajaran lain, serta peperiksaan profesional untuk penjawat awam, akauntan awam bertauliah, peguam dan doktor.
Keputusan ujian boleh diperoleh melalui papan pendahulu.
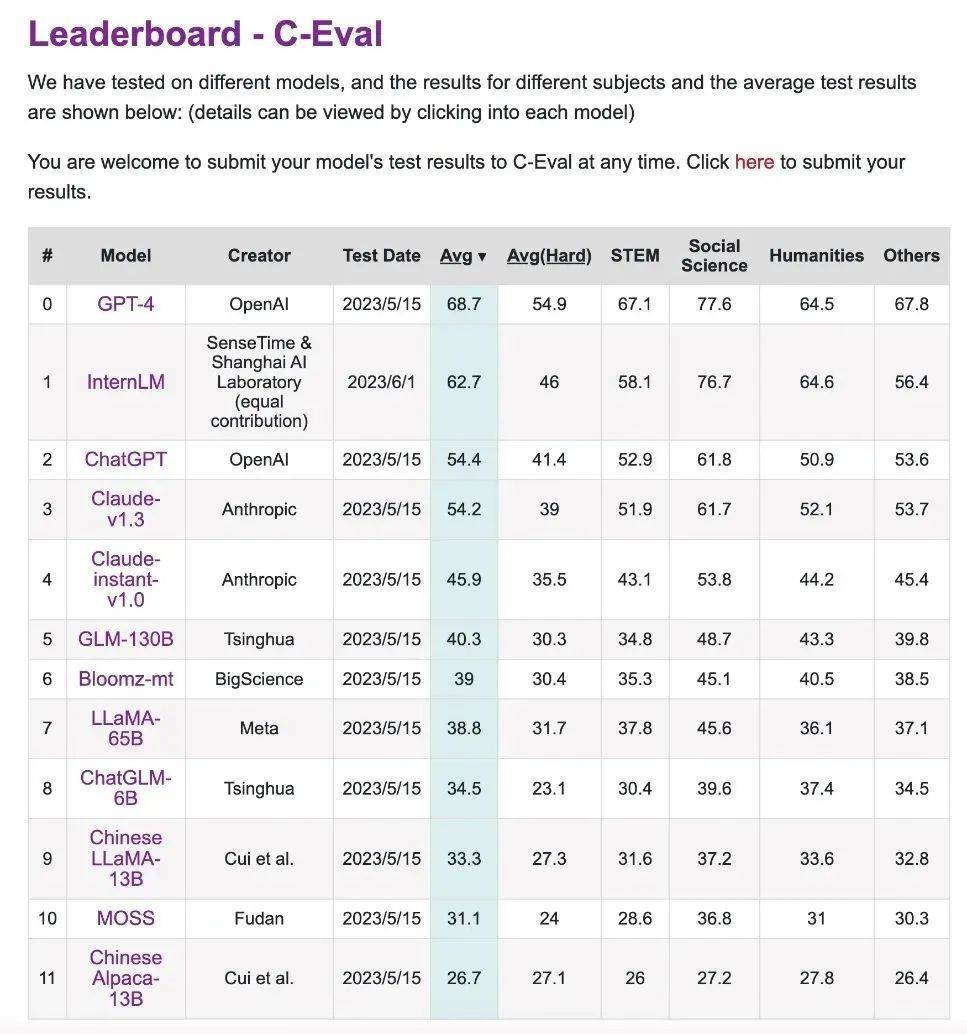
Pautan ini ialah senarai kedudukan pertandingan penilaian CEVA
Gaokao ialah set penilaian ujian komprehensif berdasarkan soalan Peperiksaan Kemasukan Kolej Cina yang dibina oleh pasukan penyelidik Universiti Fudan Ia merangkumi pelbagai subjek Peperiksaan Masuk Kolej Cina, serta pelbagai jenis soalan seperti itu sebagai soalan aneka pilihan, isi tempat kosong dan soal jawab.
Dalam penilaian GaoKao, “Scholar·Puyu” menerajui ChatGPT dalam lebih daripada 75% projek.
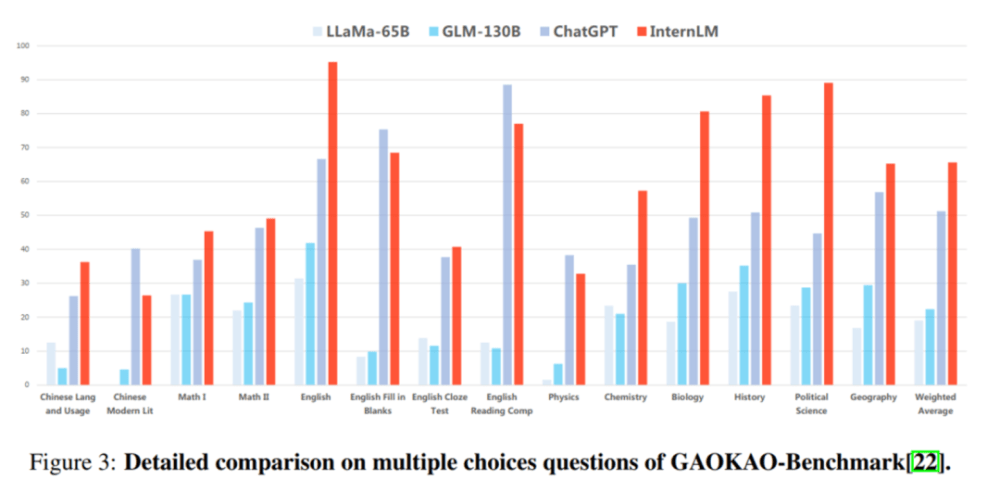
Sub-penilaian: Prestasi cemerlang dalam pemahaman bacaan dan keupayaan penaakulan
Untuk mengelakkan "berorientasikan sebahagian subjek", penyelidik juga menilai dan membandingkan keupayaan sub-skor model bahasa seperti "Scholar Puyu" melalui pelbagai set penilaian akademik.
Keputusan menunjukkan bahawa "Scholar Puyu" bukan sahaja berprestasi baik dalam pemahaman bacaan dalam bahasa Cina dan Inggeris, tetapi juga mencapai keputusan yang baik dalam penilaian seperti penaakulan matematik dan keupayaan pengaturcaraan .
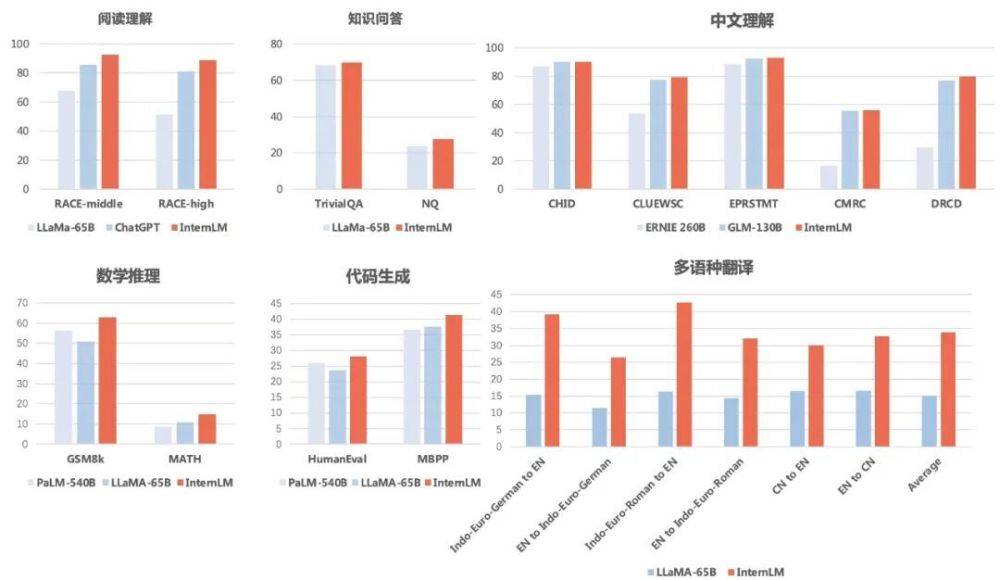
Dari segi soalan dan jawapan ilmu, "Scholar Puyu" mendapat markah 69.8 dan 27.6 pada TriviaQA dan NaturalQuestions, kedua-duanya mengatasi LLaMA-65B (skor 68.2 dan 23.8).
Dari segi kefahaman bacaan (Bahasa Inggeris) , "Scholar·Puyu" jelas mendahului LLaMA-65B dan ChatGPT. Puyu mendapat markah 92.7 dan 88.9 dalam kefahaman membaca bahasa Inggeris sekolah menengah dan sekolah menengah, 85.6 dan 81.2 pada ChatGPT, malah lebih rendah pada LLaMA-65B.
Dari segi pemahaman bahasa Cina, prestasi "Scholar Puyu" secara menyeluruh mengatasi dua model bahasa Cina utama ERNIE-260B dan GLM-130B.
Dari segi terjemahan pelbagai bahasa, "Scholar Puyu" mempunyai purata skor 33.9 dalam terjemahan pelbagai bahasa, dengan ketara mengatasi LLaMA (skor purata 15.1).
Dari segi penaakulan matematik, "Scholar Puyu" masing-masing mendapat 62.9 dan 14.9 dalam GSM8K dan MATH, dua ujian matematik yang digunakan secara meluas untuk penilaian, jauh lebih tinggi daripada PaLM -540B Google (skor 56.5). dan 8.8) dan LLaMA-65B (skor 50.9 dan 10.9).
Dari segi keupayaan pengaturcaraan, "Scholar Puyu" masing-masing mendapat 28.1 dan 41.4 dalam dua penilaian yang paling mewakili, HumanEval dan MBPP (selepas penalaan halus dalam bidang pengekodan , markah pada HumanEval boleh bertambah baik kepada 45.7), jauh mendahului PaLM-540B (skor 26.2 dan 36.8) dan LLaMA-65B (skor 23.7 dan 37.7).
Selain itu, penyelidik juga menilai keselamatan "Scholar Puyu". On TruthfulQA (terutamanya menilai ketepatan fakta jawapan) dan CrowS-Pairs (terutamanya menilai sama ada jawapan mengandungi bias), bahasa "Scholar Puyu"" telah mencapai tahap terkemuka.
Atas ialah kandungan terperinci Ujian tergesa-gesa model bahasa Cina: SenseTime, Shanghai AI Lab dan lain-lain yang baru dikeluarkan 'Scholar·Puyu'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI