
Rumah >Peranti teknologi >AI >Kesannya mencapai 96% model OpenAI dengan skala yang sama, dan ia adalah sumber terbuka sebaik sahaja ia dikeluarkan! Pasukan domestik mengeluarkan model besar baharu, dan Ketua Pegawai Eksekutif pergi ke pertempuran untuk menulis kod
Kesannya mencapai 96% model OpenAI dengan skala yang sama, dan ia adalah sumber terbuka sebaik sahaja ia dikeluarkan! Pasukan domestik mengeluarkan model besar baharu, dan Ketua Pegawai Eksekutif pergi ke pertempuran untuk menulis kod

- 王林ke hadapan
- 2023-06-07 14:20:101593semak imbas
Model besar yang dibangunkan sendiri domestik mengalu-alukan muka baharu, dan ia adalah sumber terbuka sebaik sahaja ia dikeluarkan!
Berita terkini ialah model bahasa besar berbilang mod TigerBot telah diumumkan secara rasmi, termasuk dua versi 7 bilion parameter dan 180 bilion parameter, kedua-dua sumber terbuka.
AI perbualan yang disokong oleh model ini dilancarkan serentak.
Menulis slogan, membuat borang dan membetulkan kesilapan tatabahasa semuanya sangat berkesan; ia juga menyokong pelbagai mod dan boleh menghasilkan gambar.

Hasil penilaian menunjukkan bahawa TigerBot-7B telah mencapai 96% prestasi keseluruhan model OpenAI dengan saiz yang sama .
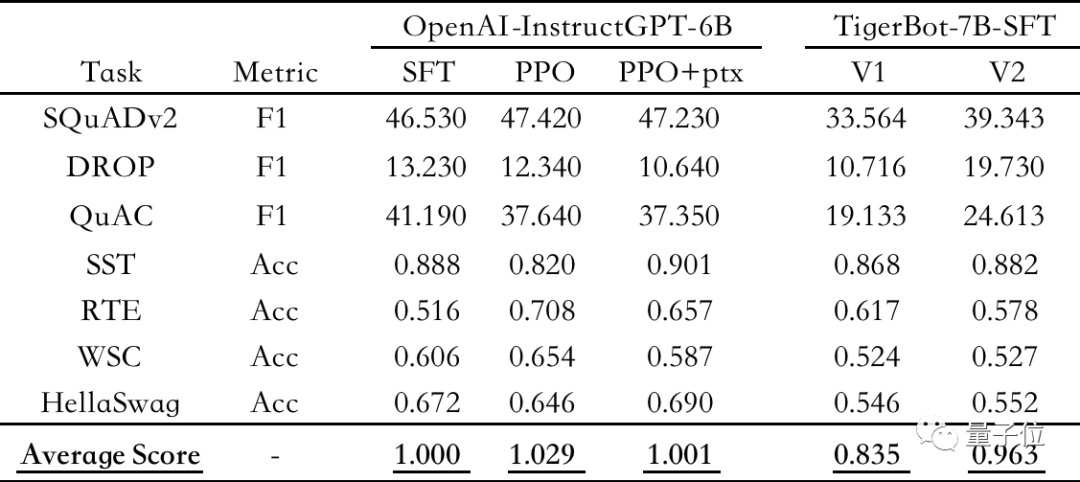
△Penilaian automatik pada set data NLP awam, menggunakan OpenAI-instruct GPT-6B-SFT sebagai penanda aras, menormalkan dan purata setiap model Skor daripada
dan TigerBot-180B yang lebih besar mungkin merupakan model bahasa besar skala terbesar yang kini sumber terbuka dalam industri.
Selain itu, pasukan itu juga mempunyai sumber terbuka data pra-latihan 100G dan menyelia penalaan halus 1G atau 1 juta keping data.
Berdasarkan TigerBot, pembangun boleh mencipta model besar mereka sendiri dalam setengah hari.
Pada masa ini, TigerBot dialog AI telah dijemput untuk ujian dalaman, dan data kod sumber terbuka serta data lain telah dimuat naik ke GitHub (lihat penghujung artikel untuk pautan terperinci).
Tugas penting ini datang daripada pasukan kecil hanya 5 orang pada mulanya Ketua pengaturcara & saintis ialah CEO sendiri.
Tetapi pasukan ini sama sekali tidak dikenali.
Sejak 2017, mereka telah memulakan perniagaan mereka dalam bidang NLP, pengkhususan dalam carian medan menegak. Terbaik dalam bidang kewangan dengan tumpuan data yang berat, dan mempunyai kerjasama yang mendalam dengan Pengasas Sekuriti, Guosen Securities, dsb.
Pengasas dan Ketua Pegawai Eksekutif mempunyai lebih daripada 20 tahun pengalaman dalam industri. Beliau adalah profesor pelawat di UC Berkeley dan memegang 3 kertas persidangan terbaik dan 10 paten teknologi.
Kini, mereka berazam untuk beralih dari kawasan khusus kepada model besar tujuan umum.
Dan kami bermula dengan model asas terendah dari awal Menyelesaikan 3,000 lelaran percubaan dalam masa 3 bulan, dan kami masih mempunyai keyakinan untuk membuka sumber hasil berperingkat kepada dunia luar.
Ia membuatkan orang tertanya-tanya, siapakah mereka? nak buat apa? Apakah keputusan berperingkat yang telah dicapai setakat ini?
Apakah TigerBot?
Secara khusus, TigerBot ialah model tugasan berbilang bahasa yang dibangunkan sendiri dalam negara yang besar.
Meliputi 15 kategori utama keupayaan seperti penjanaan, soal jawab terbuka, pengaturcaraan, lukisan, terjemahan, sumbangsaran, dsb., dan menyokong lebih daripada 60 subtugasan.
Ia juga menyokong fungsi pemalam, yang membolehkan model disambungkan ke Internet dan mendapatkan lebih banyak data dan maklumat baharu.
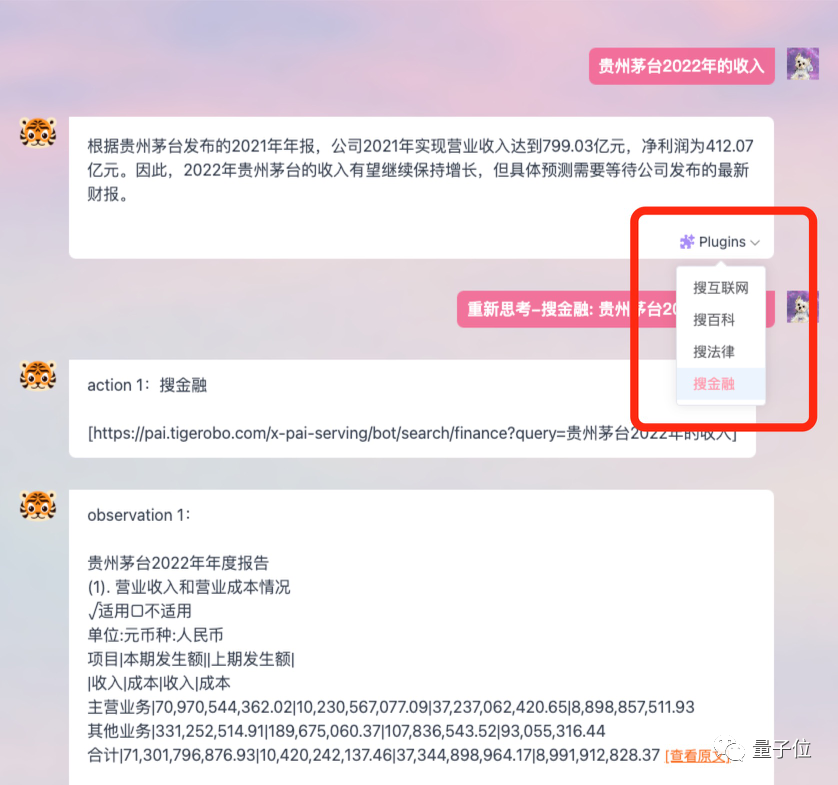
Ia diletakkan lebih ke arah pejabat dan mencadangkan matlamat untuk meningkatkan aliran kerja dan kecekapan orang ramai.
Sebagai contoh, biarkan ia membantu saya menulis kilat berita tentang Apple Vision Pro, dan kesannya adalah sama:

Atau tulis rangka tesis, jelas dan tersusun:
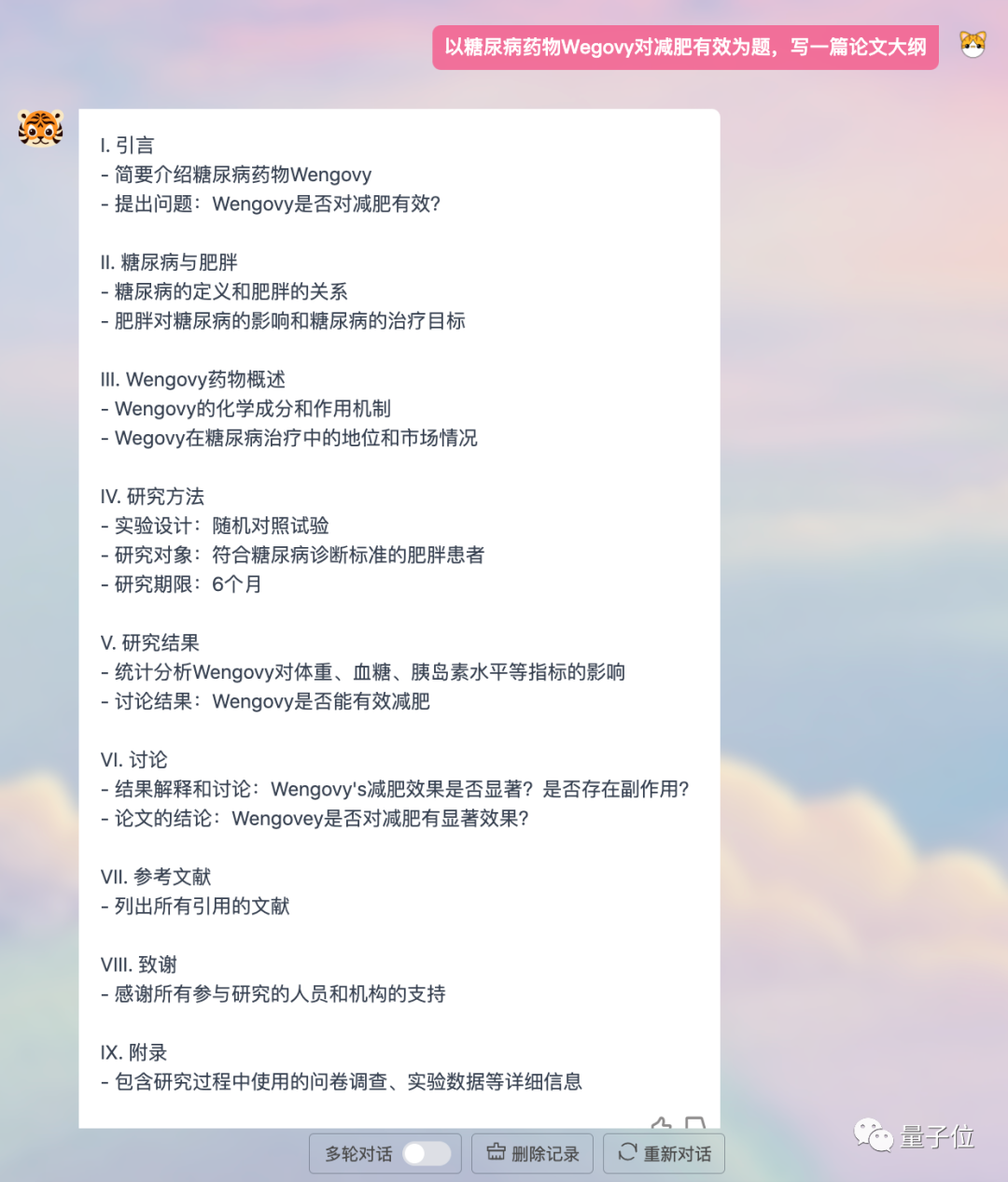
Pengaturcaraan tiada masalah dan perbualan bahasa Inggeris disokong.
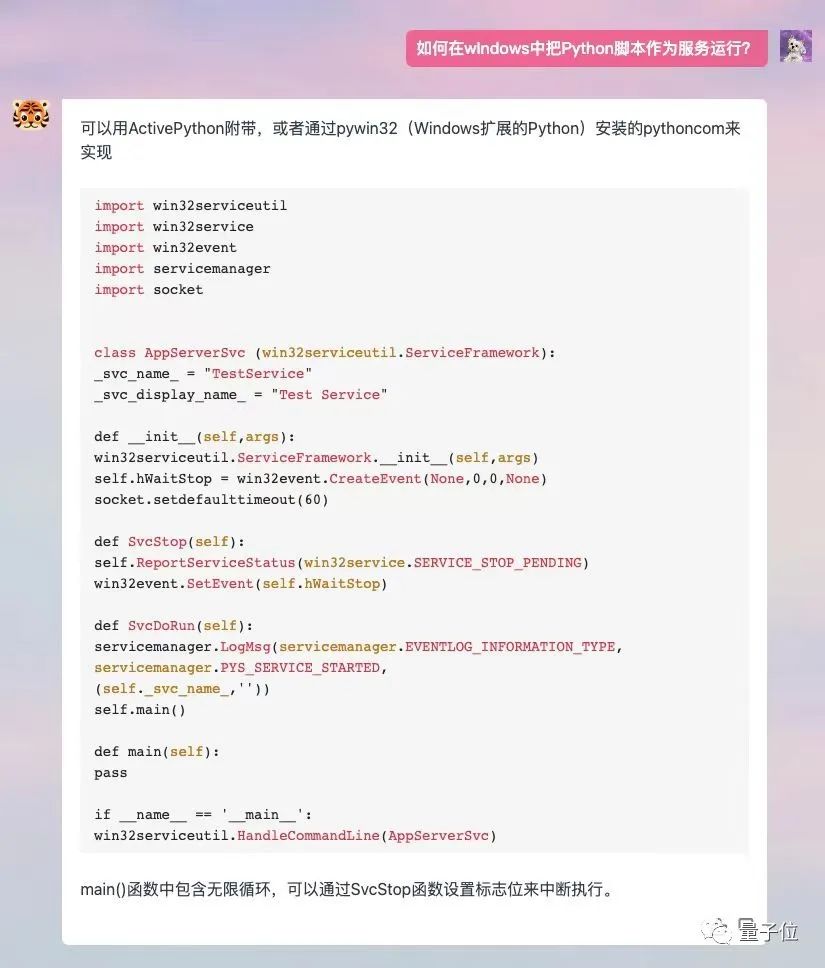
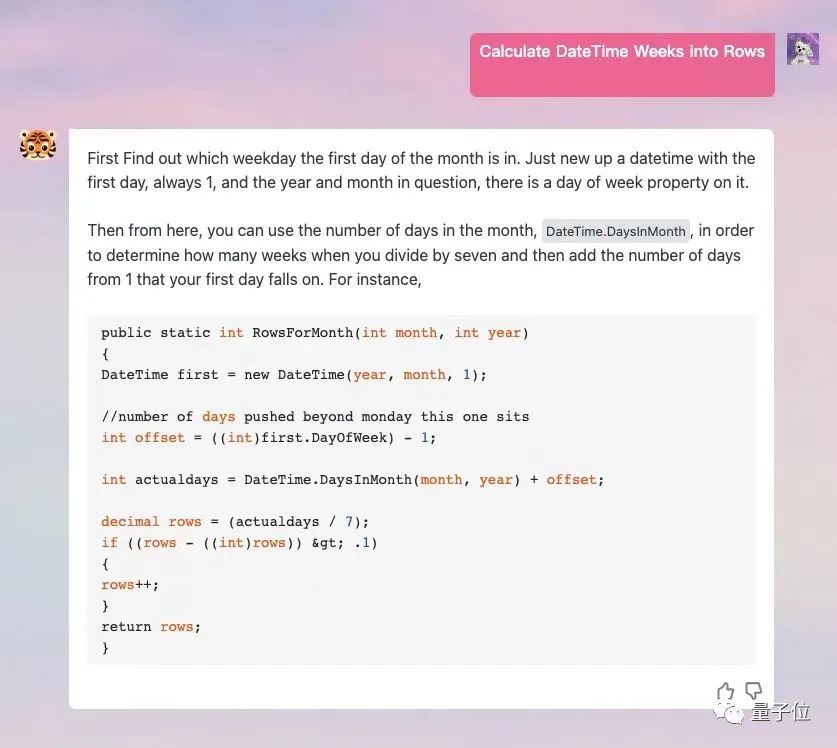
Jika anda membiarkannya melukis, 3 akan dijana setiap masa Terdapat yang berbeza, anda boleh memilihnya sendiri.

Dengan keluaran ini, TigerBot telah melancarkan sejumlah dua saiz: 7 bilion parameter (TigerBot-7B) dan 180 bilion parameter (TigerBot-180B).
Pasukan akan membuka sumber semua hasil berperingkat yang dicapai setakat ini - model, kod dan data.
Model sumber terbuka termasuk tiga versi:
- TigerBot-7B-sft
- TigerBot-7B-base
- TigerBot-180B-research
Antaranya, TigerBot-7B-base berprestasi lebih baik daripada model setanding OpenAI dan BLOOM. TigerBot-180B-research mungkin model sumber terbuka terbesar dalam industri pada masa ini (OPT sumber terbuka Meta mempunyai saiz parameter 175 bilion, dan BLOOM mempunyai skala 176 bilion).
Kod sumber terbuka termasuk latihan asas dan kod inferens, pengkuantitian dan kod inferens untuk model inferens dwi-kad 180B.
Data tersebut termasuk data pra-latihan 100G dan penyeliaan penalaan halus 1G atau 1 juta keping data.
Menurut penilaian automatik kertas OpenAI InstructGPT pada set data NLP awam, TigerBot-7B telah mencapai 96% daripada prestasi keseluruhan model OpenAI dengan saiz yang sama.
Dan versi ini hanya MVP (Model Minimum Berdaya maju) .
Keputusan ini terutamanya disebabkan oleh pengoptimuman selanjutnya pasukan terhadap seni bina model dan algoritma berdasarkan GPT dan BLOOM Ia juga merupakan kerja inovasi utama pasukan TigerBot dalam beberapa bulan yang lalu, menjadikan keupayaan Pembelajaran model , kreativiti dan penjanaan terkawal telah dipertingkatkan dengan ketara.
Bagaimana untuk melaksanakannya secara khusus? Tengok bawah.
Peningkatan prestasi sambil mengurangkan kos
Inovasi yang dibawa oleh TigerBot terutamanya termasuk aspek berikut:
- Algoritma inovatif yang mencadangkan arahan untuk melengkapkan model penalaan halus yang diselia Ciri-ciri kebolehbelajaran
- Gunakan kaedah pemodelan ensemble dan probabilistik untuk mencapai fakta dan kreativiti yang boleh dikawal
- Memecahkan masalah ingatan dan komunikasi dalam rangka kerja arus perdana seperti kelajuan dalam dalam latihan selari, dan mencapai persekitaran kilokalori Beberapa bulan tanpa gangguan
- Memandangkan pengedaran bahasa Cina yang lebih tidak teratur, pengoptimuman yang lebih sesuai telah dibuat daripada tokenizer kepada algoritma latihan
Pertama sekali, mari kita lihat arahan untuk menyelesaikan Kaedah penalaan halus diselia.
Ia membolehkan model memahami dengan cepat jenis soalan yang ditanya oleh manusia dan meningkatkan ketepatan jawapan sambil menggunakan hanya sebilangan kecil parameter.
Pada dasarnya, pembelajaran diselia yang lebih kukuh digunakan untuk kawalan.
Menggunakan Bahasa Penanda, kaedah probabilistik membolehkan model besar membezakan kategori arahan dengan lebih tepat. Sebagai contoh, adakah soalan arahan lebih berfakta atau berbeza? Adakah ia kod? Adakah ia satu borang?
Jadi TigerBot merangkumi 10 kategori utama dan 120 kategori tugas kecil. Kemudian biarkan model mengoptimumkan ke arah yang sepadan berdasarkan pertimbangan. Faedah langsung yang dibawa oleh
ialah bilangan parameter yang akan dipanggil adalah lebih kecil, dan model mempunyai kebolehsuaian yang lebih baik kepada data atau tugas baharu, iaitu, kebolehbelajaran dipertingkatkan.
Dengan 500,000 keping latihan data yang sama, kelajuan penumpuan TigerBot adalah 5 kali lebih pantas daripada Alpaca yang dilancarkan oleh Stanford, dan penilaian pada set data awam menunjukkan bahawa prestasi dipertingkatkan sebanyak 17%.
Kedua, cara model boleh mengimbangi kreativiti dan kebolehkawalan fakta kandungan yang dihasilkan juga sangat kritikal.
TigerBot menggunakan kaedah ensembel di satu pihak, menggabungkan berbilang model untuk mengambil kira kreativiti dan kebolehkawalan fakta.
Anda juga boleh melaraskan pertukaran model antara kedua-duanya mengikut keperluan pengguna.
Sebaliknya, ia juga menggunakan kaedah klasik pemodelan probabilistik (Pemodelan Kebarangkalian) dalam bidang AI.
Ia membolehkan model memberikan dua kebarangkalian berdasarkan token yang dijana terkini semasa proses menjana kandungan. Kebarangkalian menentukan sama ada kandungan harus terus menyimpang, dan kebarangkalian menunjukkan tahap sisihan kandungan yang dijana daripada kandungan fakta.
Dengan menggabungkan dua nilai kebarangkalian, model akan membuat pertukaran antara kreativiti dan kebolehkawalan. Kedua-dua kebarangkalian dalam TigerBot dilatih dengan data khas.
Memandangkan apabila model menghasilkan token seterusnya, selalunya mustahil untuk melihat teks penuh, TigerBot akan membuat pertimbangan lain selepas jawapan ditulis Jika jawapan akhirnya didapati tidak tepat, ia akan memerlukan model untuk menulis semula.
Sepanjang pengalaman kami, kami juga mendapati bahawa jawapan yang dijana oleh TigerBot tidak berada dalam mod keluaran verbatim seperti ChatGPT, sebaliknya memberikan jawapan lengkap selepas "berfikir".

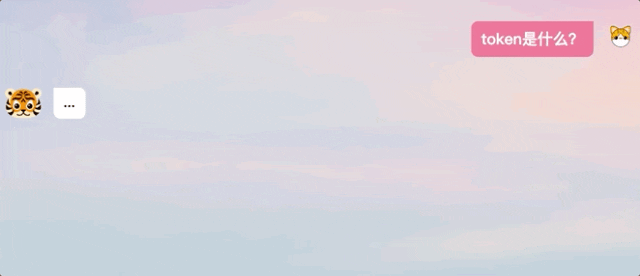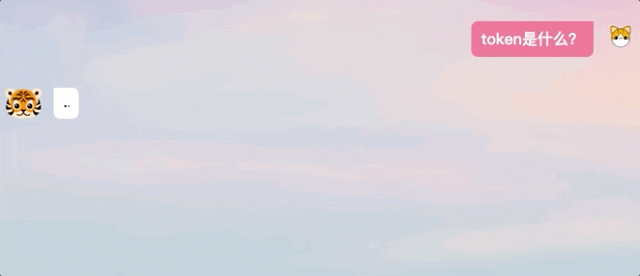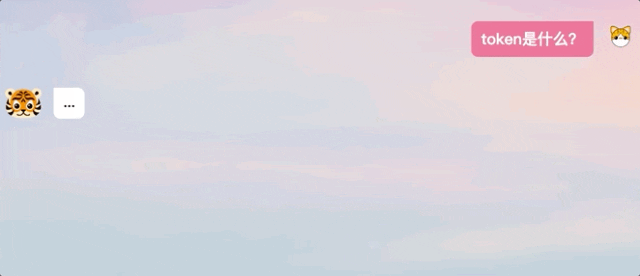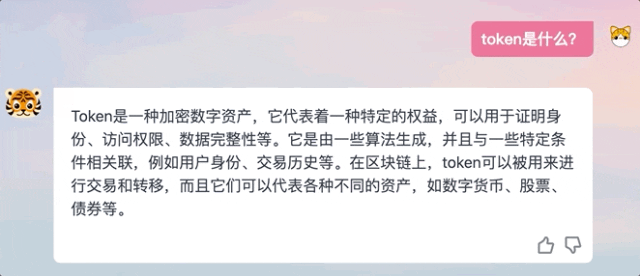
△Perbandingan kaedah menjawab ChatGPT dan TigerBot
Dan kerana kelajuan inferens TigerBot sangat pantas, ia boleh menyokong penulisan semula model yang pantas.
Di sini kita bercakap tentang inovasi TigerBot dalam latihan dan penaakulan.
Selain mempertimbangkan pengoptimuman seni bina asas model, pasukan TigerBot percaya bahawa tahap kejuruteraan juga sangat penting dalam era semasa model besar.
Dalam satu pihak, ia adalah kerana keperluan untuk mempertimbangkan kecekapan operasi - memandangkan trend model besar berterusan, adalah sangat penting siapa yang boleh mengulangi model dengan lebih cepat, sudah tentu, yang ekonomi kuasa pengkomputeran juga mesti dipertimbangkan.
Oleh itu, dari segi latihan selari, mereka memecahkan beberapa masalah ingatan dan komunikasi dalam rangka kerja arus perdana seperti kelajuan dalam, dan mencapai latihan tanpa gangguan selama beberapa bulan dalam persekitaran kilokalori.
Ini membolehkan mereka menjimatkan ratusan ribu perbelanjaan latihan bulanan.
Akhir sekali, TigerBot telah membuat pengoptimuman yang sepadan daripada tokenizer kepada algoritma latihan untuk menangani masalah kesinambungan yang kukuh dan pelbagai kesamaran dalam bahasa Cina.
Ringkasnya, inovasi teknologi yang dicapai oleh TigerBot semuanya berlaku di kawasan yang paling mendapat perhatian dalam bidang model besar.
Ia bukan sahaja pengoptimuman seni bina asas, tetapi juga mempertimbangkan keperluan pengguna, kos overhed dan isu lain di peringkat pelaksanaan. Dan keseluruhan proses inovasi adalah sangat pantas, dan ia boleh direalisasikan dalam beberapa bulan oleh pasukan kecil kira-kira 10 orang.
Ini mempunyai keperluan yang sangat tinggi terhadap keupayaan pembangunan pasukan sendiri, cerapan teknikal dan pengalaman pelaksanaan.
Jadi, siapa yang membawa TigerBot ke mata umum secara tiba-tiba?
Siapa Teknologi Hubo?
Pasukan pembangunan di belakang TigerBot sebenarnya tersembunyi dalam namanya - Teknologi Hubo.
Ia ditubuhkan pada tahun 2017, yang sering orang panggil pusingan terakhir tempoh letupan AI.
Teknologi Hubo meletakkan dirinya sebagai "sebuah syarikat yang dipacu oleh teknologi kecerdasan buatan", memfokuskan pada aplikasi teknologi NLP, dengan visi untuk mencipta pengalaman carian pintar dan mudah generasi akan datang.
Pada laluan pelaksanaan tertentu, mereka memilih salah satu medan paling sensitif kepada maklumat data - Kewangan. Ia mempunyai teknologi yang dibangunkan sendiri seperti carian pintar, pengesyoran pintar, pemahaman bacaan mesin, ringkasan dan terjemahan dalam medan menegak, dan melancarkan sistem carian kewangan dan soal jawab pintar "Carian Hubo".
Pengasas dan CEO syarikat ialah Chen Ye, seorang saintis AI bertaraf dunia.

Beliau lulus dari Universiti Wisconsin-Madison dengan Ph.D dan merupakan profesor pelawat di University of California, Berkeley telah berlatih selama lebih dari 20 tahun sekarang.
Beliau telah berturut-turut memegang jawatan penting seperti ketua saintis dan pengarah R&D di Microsoft, eBay dan Yahoo, dan mengetuai pembangunan sistem penyasaran tingkah laku Yahoo, sistem pengesyoran eBay dan mekanisme pasaran pembidaan pengiklanan carian Microsoft.
Pada 2014, Chen Ye menyertai Dianping. Selepas penggabungan Meituan-Dianping, beliau berkhidmat sebagai naib presiden kanan Meituan-Dianping, yang bertanggungjawab ke atas platform pengiklanan kumpulan itu, membantu hasil pengiklanan tahunan kumpulan itu meningkat daripada 10 juta kepada lebih daripada 4 bilion.
Dari segi akademik, Chen Ye telah memenangi anugerah kertas terbaik di persidangan teratas (KDD dan SIGIR) sebanyak tiga kali, menerbitkan 20 kertas kerja di persidangan akademik kecerdasan buatan seperti SIGKKD, SIGIR, dan IEEE, dan memegang 10 paten.
Pada Julai 2017, Chen Ye secara rasmi mengasaskan Teknologi Hubo. Setahun selepas penubuhannya, Hubo dengan cepat memperoleh lebih 100 juta yuan dalam bentuk pembiayaan, dan syarikat pada masa ini mendedahkan jumlah pembiayaan sebanyak 400 juta yuan .

7 bulan yang lalu, ChatGPT dilahirkan Selepas 6 tahun, AI sekali lagi menumbangkan persepsi orang ramai.
Malah seorang pakar teknikal seperti Chen Ye, yang telah bekerja dalam bidang AI selama bertahun-tahun, menyifatkan ia sebagai "kejutan yang tidak pernah berlaku dalam kerjayanya."
Selain terkejut, saya lebih teruja.
Chen Ye berkata bahawa selepas melihat ChatGPT, dia hampir tidak perlu berfikir atau membuat keputusan.
Jadi, mulai Januari, Hubo secara rasmi menubuhkan pasukan pembangunan awal TigerBot.
Tetapi ia tidak seperti yang dijangkakan. Ini adalah pasukan dengan gaya geek yang sangat tersendiri.
Dengan kata-kata mereka sendiri, mereka memberi penghormatan kepada model klasik "Garage Entrepreneurship" di Silicon Valley pada 1990-an.
Pasukan pada mulanya hanya mempunyai 5 orang Chen Ye ialah ketua pengaturcara & saintis, bertanggungjawab untuk kerja kod teras. Walaupun bilangan ahli berkembang kemudian, ia hanya terhad kepada 10 orang, pada asasnya seorang setiap jawatan.
Mengapa anda melakukan ini?
Jawapan Chen Ye ialah:
Saya rasa penciptaan dari 0 hingga 1 adalah perkara yang sangat culun, dan tiada pasukan geek yang mempunyai lebih daripada 10 orang.
Selain hal teknikal dan saintifik semata-mata, pasukan kecil lebih tajam.
Sesungguhnya, proses pembangunan TigerBot mendedahkan ketegasan dan sensitiviti dalam setiap aspek.
Chen Ye membahagikan kitaran ini kepada tiga peringkat.
Dalam fasa pertama, sejurus selepas ChatGPT menjadi popular, pasukan itu dengan pantas mengimbas semua literatur berkaitan daripada OpenAI dan institusi lain dalam tempoh lima tahun yang lalu untuk mendapatkan pemahaman umum tentang kaedah dan mekanisme ChatGPT.
Memandangkan kod ChatGPT itu sendiri bukan sumber terbuka, dan terdapat sedikit kerja sumber terbuka yang berkaitan pada masa itu, Chen Ye menulis kod TigerBot sendiri dan segera mula menjalankan eksperimen.
Logik mereka sangat mudah, membolehkan model berjaya disahkan pada data berskala kecil dahulu, dan kemudian menjalani semakan saintifik yang sistematik, iaitu membentuk set kod yang stabil.
Dalam tempoh satu bulan, pasukan mengesahkan bahawa model itu boleh mencapai 80% daripada kesan model OpenAI pada skala yang sama pada skala 7 bilion.
Pada peringkat kedua, dengan terus menyerap kelebihan model dan kod sumber terbuka, dan menambahkan pengoptimuman dan pemprosesan khas data Cina, pasukan itu dengan cepat menghasilkan versi model yang paling awal dan boleh digunakan versi beta dalaman adalah pada 2 Bulan dalam talian.
Pada masa yang sama, mereka juga mendapati selepas bilangan parameter mencapai paras berpuluh bilion, model tersebut menunjukkan fenomena kemunculan.
Dalam fasa ketiga, iaitu, dalam satu atau dua bulan yang lalu, pasukan telah mencapai beberapa keputusan dan penemuan dalam penyelidikan asas.
Banyak inovasi yang diperkenalkan di atas telah disiapkan dalam tempoh ini.
Pada masa yang sama, jumlah kuasa pengkomputeran yang lebih besar telah disepadukan semasa peringkat ini untuk mencapai kelajuan lelaran yang lebih pantas Dalam masa 1-2 minggu, keupayaan TigerBot-7B dengan cepat meningkat daripada 80% daripada InstructGPT kepada 96%.
Chen Ye berkata bahawa semasa kitaran pembangunan ini, pasukan sentiasa mengekalkan operasi ultra-cekap. TigerBot-7B melalui 3,000 lelaran dalam beberapa bulan.
Kelebihan pasukan kecil ialah respons pantas Mereka boleh mengesahkan kerja pada waktu pagi dan menyelesaikan menulis kod pada sebelah petang. Pasukan data boleh menyelesaikan kerja pembersihan berkualiti tinggi dalam masa beberapa jam.
Tetapi pembangunan dan lelaran berkelajuan tinggi hanyalah salah satu daripada manifestasi gaya geek TigerBot.
Kerana mereka hanya bergantung pada hasil yang dihasilkan oleh 10 orang dalam beberapa bulan, dan akan membuka sumbernya kepada industri dalam bentuk set penuh API.
Memeluk sumber terbuka setakat ini agak jarang berlaku dalam trend semasa, terutamanya dalam bidang pengkomersialan.
Lagipun, dalam persaingan yang sengit, membina halangan teknikal adalah masalah yang perlu dihadapi oleh syarikat komersial.
Jadi, kenapa Hubo Technology berani buka sumber?
Chen Ye memberikan dua sebab:
Pertama , sebagai juruteknik dalam bidang AI, daripada naluri yang paling sesuai untuk teknologi Faith, dia adalah seorang sedikit ghairah dan sedikit sensasi.
Kami mahu menyumbang kepada inovasi China dengan model berskala besar bertaraf dunia. Memberikan industri model umum yang boleh digunakan dengan asas asas yang kukuh akan membolehkan lebih ramai orang melatih model profesional yang besar dengan cepat dan merealisasikan penciptaan ekologi kelompok industri.
Kedua, TigerBot akan terus mengekalkan lelaran berkelajuan tinggi Chen Ye percaya bahawa dalam situasi perlumbaan ini, mereka boleh mengekalkan Kedudukan mereka. Walaupun kita melihat seseorang membangunkan produk dengan prestasi yang lebih baik berdasarkan TigerBot, bukankah ini perkara yang baik untuk industri?
Chen Ye mendedahkan bahawa Teknologi Hubo akan terus memajukan kerja TigerBot dengan pantas dan mengembangkan lagi data untuk meningkatkan prestasi model.
“Trend model besar adalah seperti tergesa-gesa emas”
Enam bulan selepas keluaran ChatGPT, dengan kemunculan model besar satu demi satu dan susulan pantas gergasi, landskap industri AI telah berubah dengan pantas.
Walaupun ia masih agak huru-hara pada masa ini, secara kasarnya, ia terbahagi kepada tiga lapisan: lapisan model, lapisan tengah dan lapisan aplikasi.
Lapisan model menentukan keupayaan asas, yang sangat penting.
Tahap inovasi, kestabilan dan keterbukaannya secara langsung menentukan kekayaan lapisan aplikasi.
Pembangunan lapisan aplikasi adalah manifestasi luaran evolusi trend model besar; ia juga merupakan faktor pengaruh penting untuk peringkat seterusnya kehidupan sosial manusia dalam visi AIGC.
Jadi, pada titik permulaan trend model besar, cara untuk menyatukan asas model asas adalah sesuatu yang mesti difikirkan oleh industri.
Pada pandangan Chen Ye, manusia hanya membangunkan 10-20% daripada potensi model besar, dan masih terdapat banyak ruang untuk inovasi dan penambahbaikan di peringkat asas.
Sama seperti lombong emas di Barat, tempat asalnya lombong emas ditemui.
Jadi di bawah trend dan keperluan pembangunan industri sedemikian, Hubo Technology, sebagai wakil inovasi dalam bidang domestik, menjunjung tinggi sepanduk sumber terbuka, bermula dengan cepat, mengejar yang paling canggih di dunia- teknologi canggih, dan sememangnya membawa faedah kepada industri Terdapat suasana yang tersendiri.
Inovasi AI domestik berjalan pada kelajuan tinggi Pada masa hadapan, saya percaya kita akan melihat lebih banyak pasukan dengan idea dan keupayaan muncul untuk menyuntik cerapan baharu dan membawa perubahan baharu kepada bidang model besar.
Dan ini mungkin bahagian paling menarik dalam evolusi trend yang rancak.
Momen kebajikan:
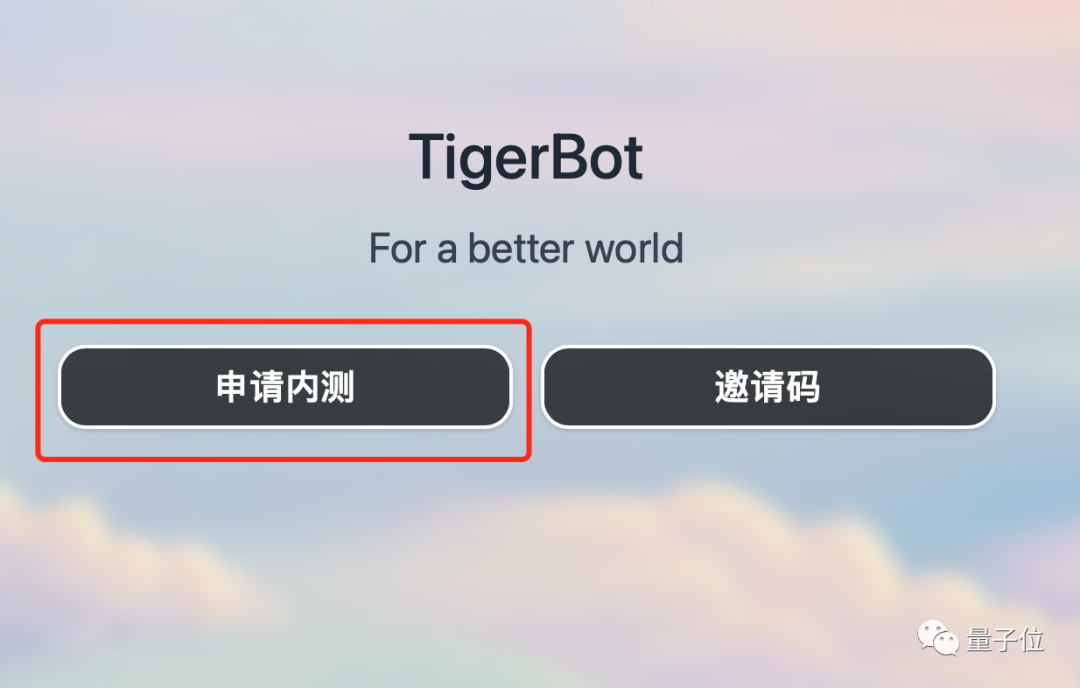
Jika anda ingin merasai pengalaman kasut kanak-kanak TigerBot, anda boleh memasuki laman web melalui pautan di bawah atau klik "Baca teks asal", klik "Apply for Internal Beta", dan tulis "qubit" dalam kod organisasi Boleh lulus ujian dalaman~
Alamat laman web rasmi: https://www.tigerbot.com/chat
Alamat sumber terbuka GitHub: https://github.com/TigerResearch/TigerBot
Atas ialah kandungan terperinci Kesannya mencapai 96% model OpenAI dengan skala yang sama, dan ia adalah sumber terbuka sebaik sahaja ia dikeluarkan! Pasukan domestik mengeluarkan model besar baharu, dan Ketua Pegawai Eksekutif pergi ke pertempuran untuk menulis kod. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI