
Rumah >Peranti teknologi >AI >Model bersatu untuk penjanaan imej boleh dikawal berbilang mod ada di sini, dan parameter model serta kod inferens semuanya adalah sumber terbuka
Model bersatu untuk penjanaan imej boleh dikawal berbilang mod ada di sini, dan parameter model serta kod inferens semuanya adalah sumber terbuka

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-06 17:12:041370semak imbas

- Alamat kertas: https://arxiv.org/abs/2305.11147
- Alamat kod: https://github.com/salesforce/UniControl
- Laman utama projek: https:/ //shorturl.at/lmMX6
Pengenalan: Resapan Stabil menunjukkan keupayaan penjanaan visual yang berkuasa. Walau bagaimanapun, mereka sering gagal dalam menghasilkan imej dengan kawalan spatial, struktur atau geometri. Kerja-kerja seperti ControlNet [1] dan T2I-adpater [2] mencapai penjanaan imej terkawal untuk modaliti yang berbeza, tetapi dapat menyesuaikan diri dengan pelbagai keadaan visual dalam model bersatu tunggal kekal sebagai cabaran yang tidak dapat diselesaikan. UniControl menggabungkan pelbagai tugas keadaan-ke-imej (C2I) yang boleh dikawal dalam satu rangka kerja. Untuk menjadikan UniControl mampu mengendalikan keadaan visual yang pelbagai, penulis memperkenalkan HyperNet yang menyedari tugas untuk melaraskan model resapan bersyarat hiliran supaya ia boleh menyesuaikan diri dengan tugas C2I yang berbeza secara serentak. UniControl dilatih dalam sembilan tugas C2I yang berbeza, menunjukkan keupayaan penjanaan visual yang kuat dan keupayaan generalisasi sifar pukulan. Pengarang telah sumber terbuka parameter model dan kod inferens Set data dan kod latihan juga akan menjadi sumber terbuka secepat mungkin.

Rajah 1: Model UniControl terdiri daripada pelbagai tugasan pra-latihan dan tugasan sifar
Motivasi: Model penjanaan imej boleh dikawal sedia ada direka bentuk untuk satu modaliti, Taskonomy [3] et al bahawa ciri dan maklumat dikongsi antara modaliti visual yang berbeza, jadi kertas kerja ini percaya bahawa model pelbagai modal bersatu mempunyai potensi yang besar.
Penyelesaian: Artikel ini mencadangkan Penyesuai gaya MOE dan HyperNet peka Tugas untuk melaksanakan keupayaan penjanaan keadaan berbilang mod dalam UniControl. Dan pengarang mencipta set data baharu MultiGen-20M, yang mengandungi 9 tugas utama, lebih daripada 20 juta tiga kali ganda segera keadaan imej dan saiz imej ≥512.
Kelebihan: 1) Model yang lebih padat (1.4B #params, 5.78GB checkpoint), lebih sedikit parameter untuk mencapai berbilang tugas. 2) Keupayaan penjanaan visual yang lebih berkuasa dan ketepatan kawalan. 3) Keupayaan generalisasi sifar tembakan pada modaliti yang tidak pernah dilihat.
1. Pengenalan
Model asas generatif mengubah cara kecerdasan buatan berinteraksi dalam bidang seperti pemprosesan bahasa semula jadi, penglihatan komputer, pemprosesan audio dan kawalan robot. Dalam pemprosesan bahasa semula jadi, model asas generatif seperti InstructGPT atau GPT-4 berfungsi dengan baik pada pelbagai tugas, dan keupayaan multitasking ini merupakan salah satu ciri yang paling menarik. Selain itu, mereka boleh melakukan pembelajaran sifar pukulan atau beberapa pukulan untuk mengendalikan tugas yang tidak kelihatan.
Walau bagaimanapun, dalam model generatif dalam bidang visual, keupayaan berbilang tugas ini tidak menonjol. Walaupun penerangan teks menyediakan cara yang fleksibel untuk mengawal kandungan imej yang dijana, mereka sering gagal dalam menyediakan kawalan spatial, struktur atau geometri tahap piksel. Penyelidikan popular terkini seperti ControlNet dan penyesuai T2I boleh meningkatkan Model Resapan Stabil (SDM) untuk mencapai kawalan yang tepat. Walau bagaimanapun, tidak seperti isyarat bahasa, yang boleh diproses oleh modul bersatu seperti CLIP, setiap model ControlNet hanya boleh memproses modaliti khusus yang telah dilatih.
Untuk mengatasi batasan kerja terdahulu, kertas kerja ini mencadangkan UniControl, model resapan bersatu yang boleh mengendalikan kedua-dua bahasa dan pelbagai keadaan visual. Reka bentuk bersatu UniControl membolehkan latihan yang lebih baik dan kecekapan inferens serta penjanaan terkawal yang dipertingkatkan. UniControl, sebaliknya, mendapat manfaat daripada hubungan yang wujud antara keadaan visual yang berbeza untuk meningkatkan kesan generatif setiap keadaan.
Keupayaan penjanaan terkawal bersatu UniControl bergantung pada dua bahagian, satu ialah "Penyesuai gaya MOE" dan satu lagi ialah "HyperNet sedar tugas". Penyesuai gaya MOE mempunyai kira-kira 70K parameter dan boleh mempelajari peta ciri peringkat rendah daripada pelbagai modaliti Task-aware HyperNet boleh memasukkan arahan tugas sebagai gesaan bahasa semula jadi dan pembenaman tugasan output untuk dibenamkan dalam rangkaian hiliran untuk memodulasi parameter hiliran untuk menyesuaikan diri dengan input modal yang berbeza.
Kajian ini telah melatih UniControl untuk mendapatkan keupayaan pembelajaran berbilang tugas dan sifar pukulan, termasuk sembilan tugasan berbeza dalam lima kategori: Edge (Canny, HED, Sketch) , kawasan pemetaan (Segmentasi, Kotak Terikat Objek), rangka (Rangka Manusia), geometri (Kedalaman, Permukaan Normal) dan penyuntingan imej (Lukisan Imej). Kajian itu kemudian melatih UniControl pada perkakasan NVIDIA A100 selama lebih 5,000 jam GPU (model baharu masih dilatih hari ini). Dan UniControl menunjukkan kebolehsuaian sifar pukulan kepada tugasan baharu.
Sumbangan penyelidikan ini boleh diringkaskan seperti berikut:
- Penyelidikan ini mencadangkan UniControl, pengawal bersatu yang boleh mengendalikan pelbagai keadaan visual Model (1.4B #params, pusat pemeriksaan 5.78GB) untuk penjanaan visual yang boleh dikawal.
- Kajian ini mengumpulkan set data generasi visual berbilang keadaan baharu yang mengandungi lebih daripada 20 juta tiga kali ganda keadaan imej-teks, meliputi sembilan tugasan berbeza dalam lima kategori.
- Kajian ini menjalankan eksperimen untuk menunjukkan bahawa model bersatu UniControl mengatasi penjanaan imej terkawal bagi setiap tugasan kerana mempelajari hubungan intrinsik antara keadaan visual yang berbeza.
- UniControl menunjukkan keupayaan untuk menyesuaikan diri dengan tugas yang tidak kelihatan secara sifar, menunjukkan kemungkinan dan potensinya untuk digunakan secara meluas dalam persekitaran terbuka.
2. Reka Bentuk Model
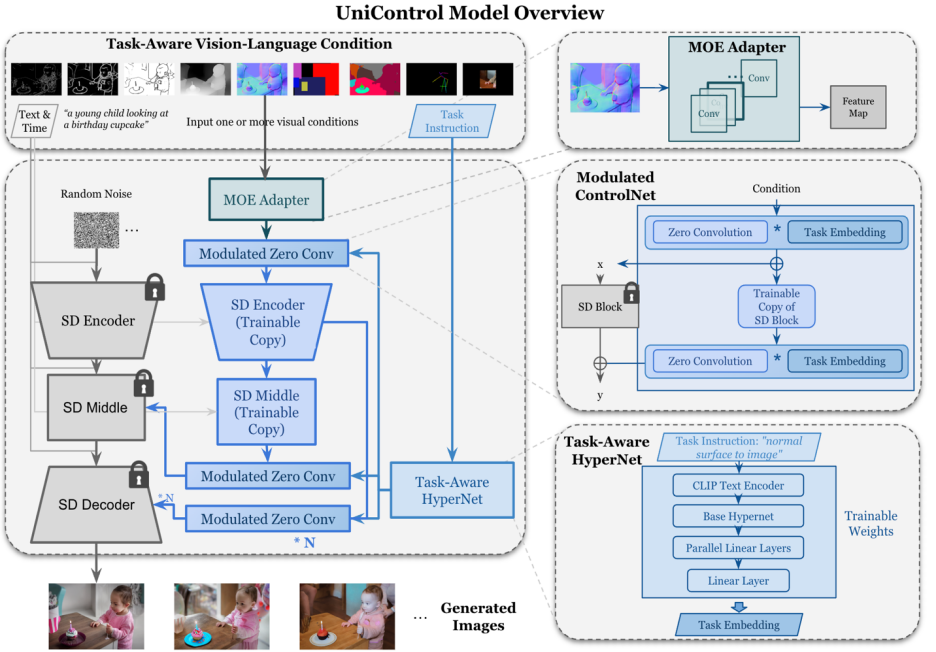
Rajah 2: Model struktur. Untuk menampung pelbagai tugas, kajian itu mereka bentuk Penyesuai gaya MOE dengan kira-kira 70K parameter setiap tugas, dan HyperNet yang sedar tugas (~12M parameter) untuk memodulasi 7 lapisan sifar konvolusi. Struktur ini membolehkan kefungsian berbilang tugas dilaksanakan dalam satu model, memastikan kepelbagaian berbilang tugas sambil mengekalkan perkongsian parameter asas. Pengurangan saiz model yang ketara berbanding model tugasan tunggal bertindan yang setara (kira-kira 1.4B parameter setiap model).
Reka bentuk model UniControl memastikan dua sifat:
1) Mengatasi ciri peringkat rendah daripada penyelewangan modaliti yang berbeza. Ini membantu UniControl mempelajari maklumat yang perlu dan unik daripada semua tugasan. Contohnya, apabila model bergantung pada peta pembahagian sebagai keadaan visual, maklumat 3D mungkin diabaikan.
2) Dapat mempelajari meta-pengetahuan merentas tugasan. Ini membolehkan model memahami pengetahuan yang dikongsi antara tugas dan perbezaan antara tugasan.
Untuk menyediakan sifat ini, model ini memperkenalkan dua modul baru: Penyesuai gaya MOE dan HyperNet yang sedar tugas.
Penyesuai gaya MOE ialah satu set modul konvolusi Setiap Penyesuai sepadan dengan modaliti yang berasingan Ia diilhamkan oleh model campuran pakar (MOE) dan digunakan sebagai UniControl menangkap pelbagai penglihatan peringkat rendah. Modul penyesuai ini mempunyai kira-kira 70K parameter dan sangat cekap dari segi pengiraan. Ciri visual kemudiannya akan dimasukkan ke dalam rangkaian bersatu untuk diproses.
HyperNet yang sedar tugas melaraskan modul konvolusi sifar ControlNet melalui syarat arahan tugas. HyperNet mula-mula menayangkan arahan tugas ke dalam pembenaman tugas, dan kemudian penyelidik menyuntik pembenaman tugas ke dalam lapisan konvolusi sifar ControlNet. Di sini, pembenaman tugas sepadan dengan saiz matriks kernel lilitan lapisan lilitan sifar. Sama seperti StyleGAN [4], kajian ini secara langsung mendarab kedua-duanya untuk memodulasi parameter lilitan, dan parameter lilitan termodulat digunakan sebagai parameter lilitan akhir. Oleh itu, parameter lilitan sifar termodulat bagi setiap tugasan adalah berbeza Ini memastikan kebolehsuaian model kepada setiap modaliti Di samping itu, semua pemberat dikongsi.
3. Latihan model
Berbeza daripada SDM atau ControlNet, keadaan penjanaan imej model ini ialah satu isyarat bahasa, atau satu jenis keadaan visual seperti canny. UniControl perlu mengendalikan pelbagai keadaan visual daripada tugasan yang berbeza, serta isyarat lisan. Oleh itu, input UniControl terdiri daripada empat bahagian: hingar, gesaan teks, keadaan visual dan arahan tugas. Antaranya, arahan tugasan boleh diperoleh secara semula jadi mengikut modaliti keadaan visual.

Dengan pasangan latihan yang dijana sedemikian, kajian ini menggunakan DDPM [5] untuk melatih model.
4. Keputusan eksperimen

Rajah 6: Perbandingan visual ujian hasil tetapkan. Data ujian datang daripada MSCOCO [6] dan Laion [7]
Hasil perbandingan dengan rasmi atau ControlNet yang diterbitkan semula dalam kajian ini ditunjukkan dalam Rajah 6, lagi Sila rujuk kertas untuk keputusan.
5.Generalisasi Tugasan sifar
Model menguji keupayaan tangkapan sifar dalam dua senario berikut:
Generalisasi tugas bercampur: Kajian ini menganggap dua keadaan visual yang berbeza sebagai input kepada UniControl, satu ialah campuran peta segmentasi dan rangka manusia, dan menambah kata kunci khusus "latar belakang" dan "latar depan" pada gesaan teks. Di samping itu, kajian itu menulis semula arahan tugas hibrid sebagai hibrid arahan untuk menggabungkan dua tugasan, seperti "peta pembahagian dan rangka manusia kepada imej".
Generalisasi tugas baharu: UniControl diperlukan untuk menjana imej boleh dikawal pada keadaan visual baharu yang tidak kelihatan. Untuk mencapai matlamat ini, adalah penting untuk menganggarkan pemberat tugasan berdasarkan hubungan antara tugas pra-latihan yang tidak kelihatan dan dilihat. Berat tugasan boleh dianggarkan dengan menetapkan atau mengira skor persamaan arahan tugasan secara manual dalam ruang benam. Penyesuai gaya MOE boleh dipasang secara linear dengan anggaran berat tugasan untuk mengekstrak ciri cetek daripada keadaan visual baru yang tidak kelihatan.
Hasil yang divisualisasikan ditunjukkan dalam Rajah 7. Untuk mendapatkan lebih banyak hasil, sila rujuk kertas.

Rajah 7: Hasil visualisasi UniControl pada tugas Zero-shot
6 Ringkasan
Secara amnya, model UniControl menyediakan model asas baharu untuk penjanaan penglihatan yang boleh dikawal melalui kepelbagaian kawalannya. Model sedemikian boleh memberikan kemungkinan untuk mencapai tahap autonomi yang lebih tinggi dan kawalan manusia terhadap tugas penjanaan imej. Kajian ini berharap untuk membincangkan dan bekerjasama dengan lebih ramai penyelidik untuk menggalakkan lagi pembangunan bidang ini.
Lebih banyak kesan visual
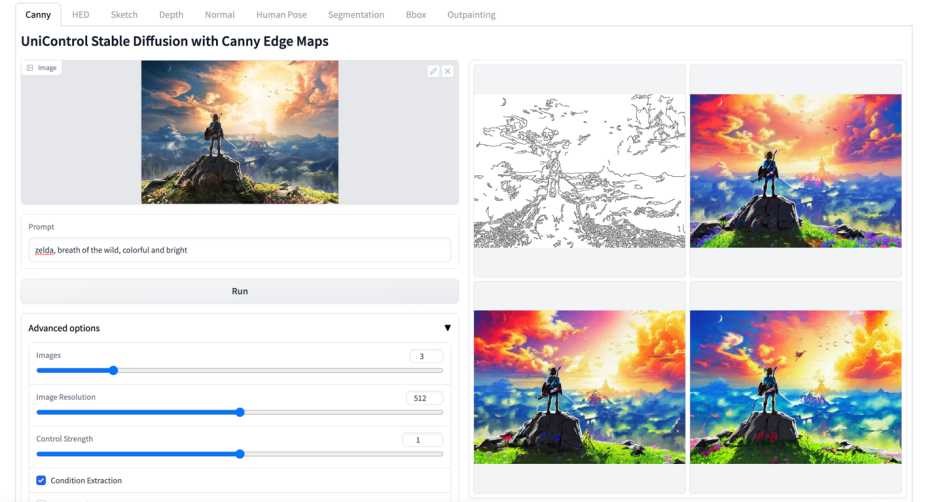
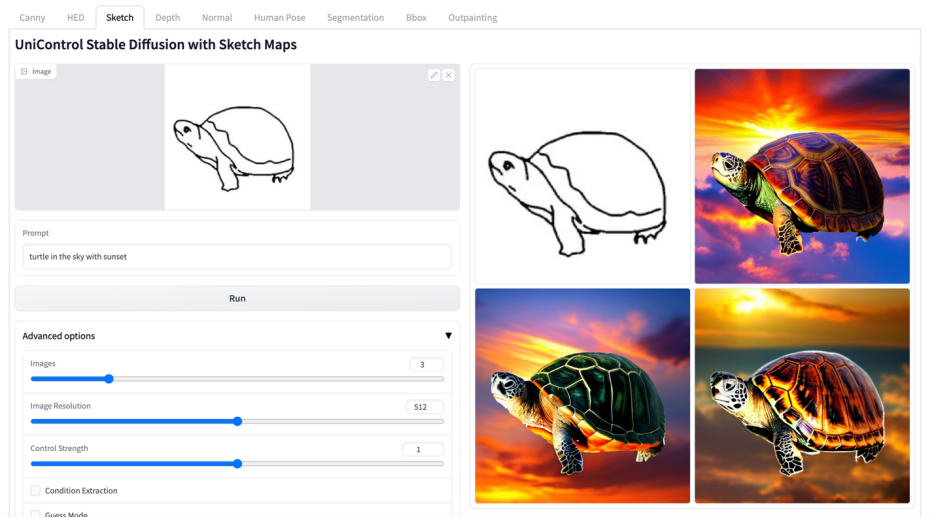
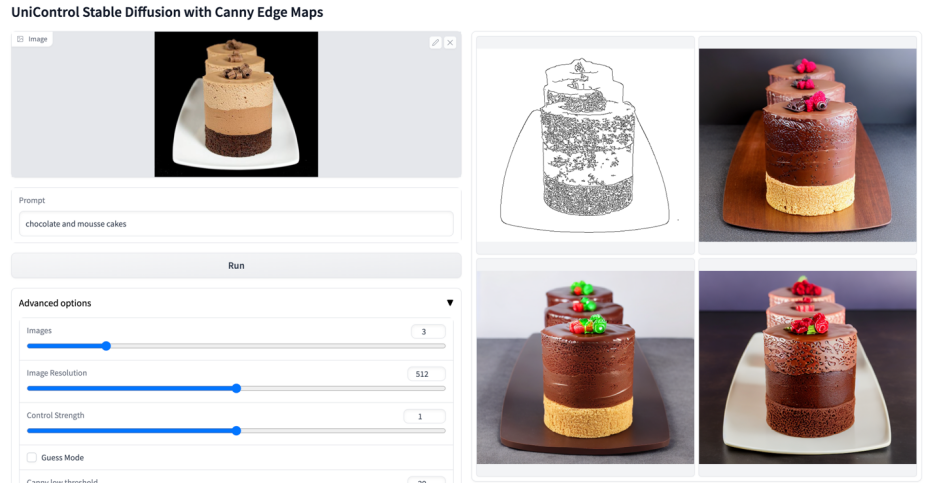
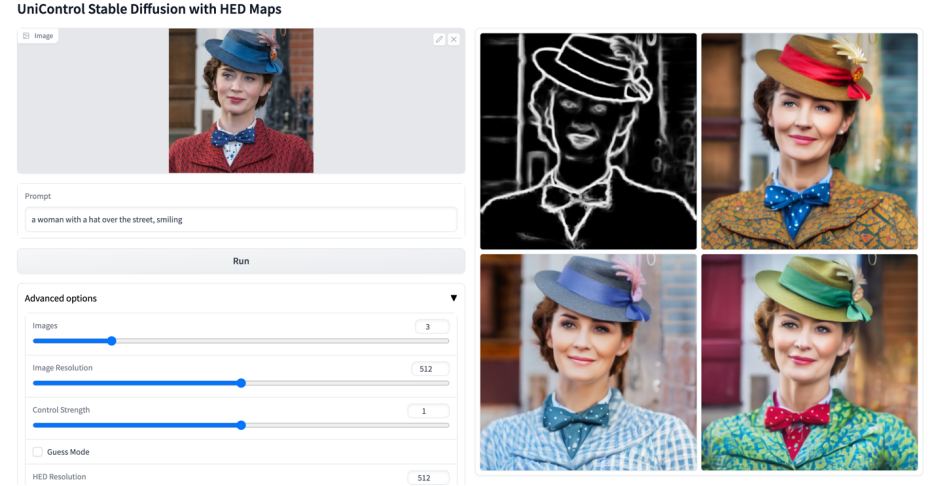
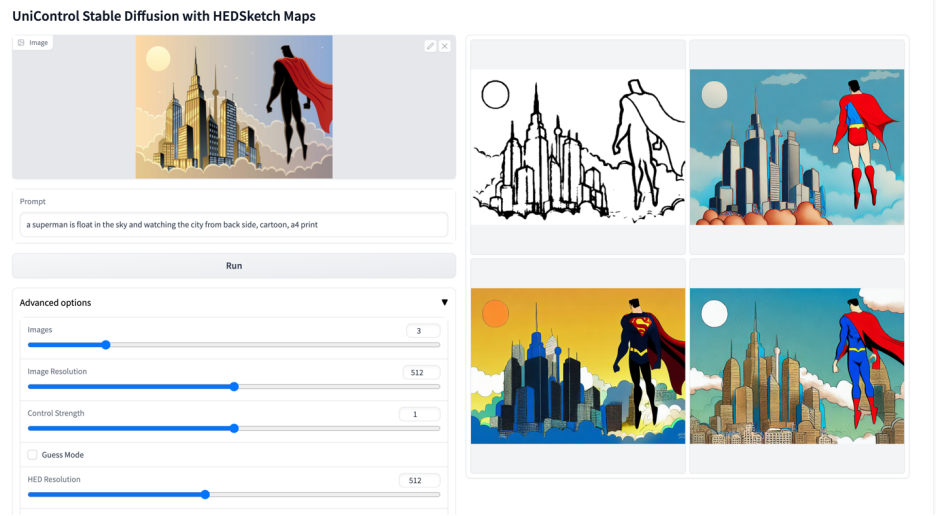
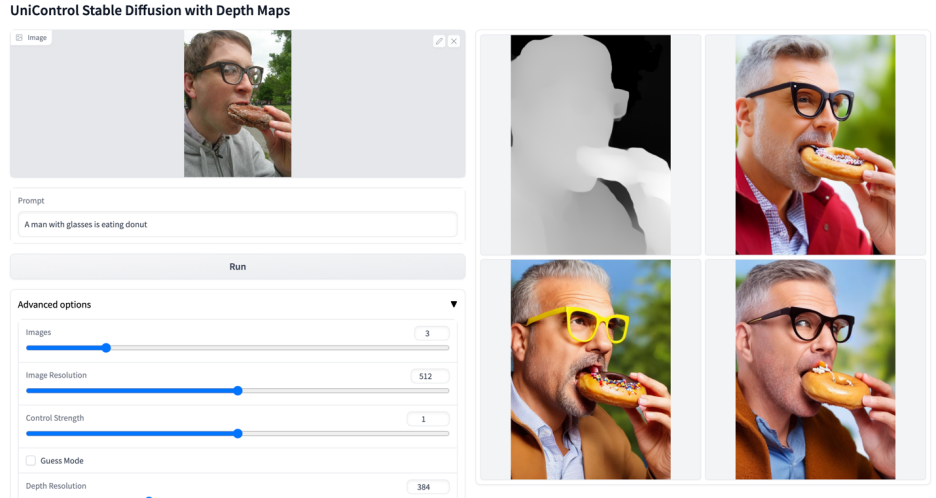
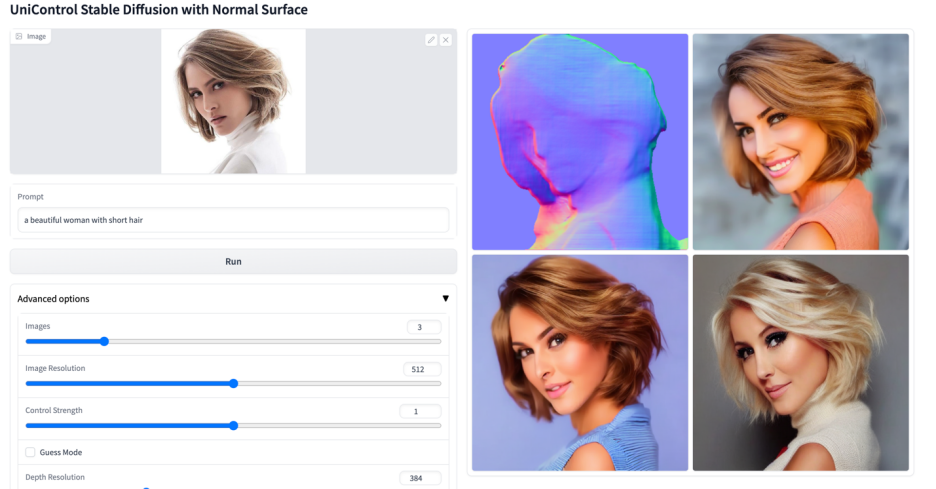
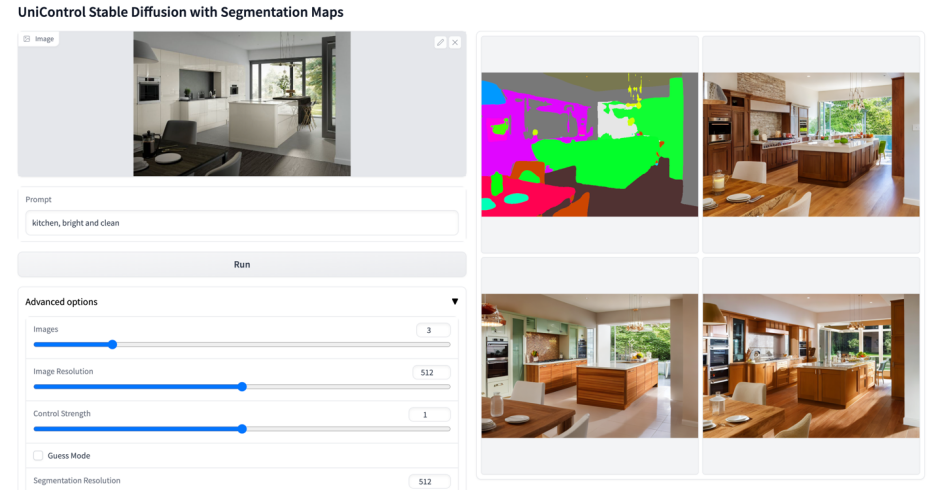
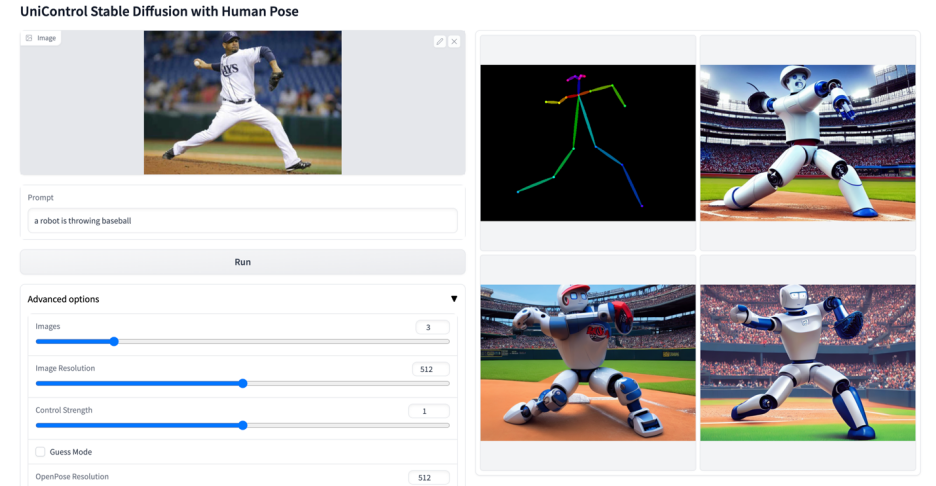
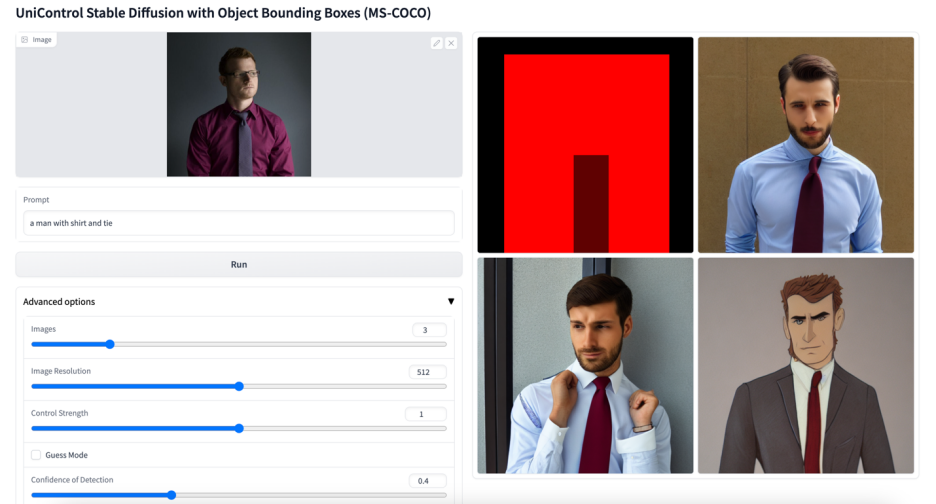
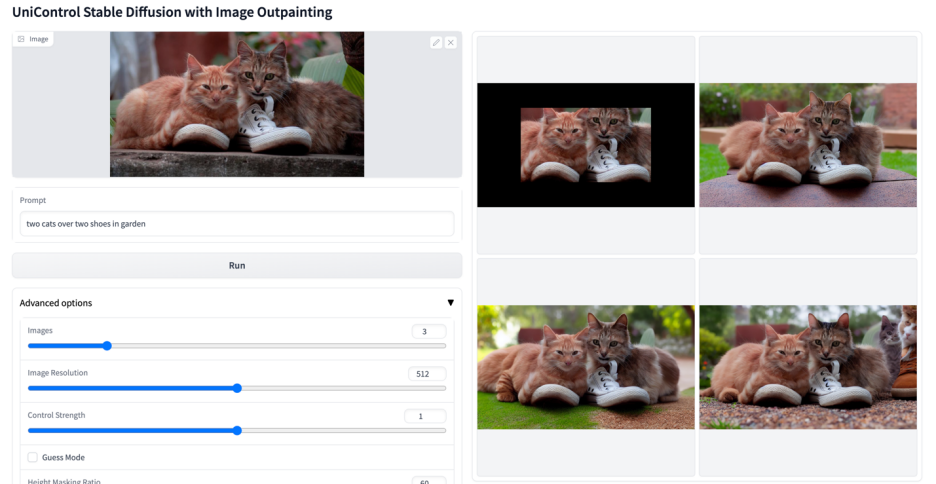
Atas ialah kandungan terperinci Model bersatu untuk penjanaan imej boleh dikawal berbilang mod ada di sini, dan parameter model serta kod inferens semuanya adalah sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI