
Rumah >Peranti teknologi >AI >Penjelasan terperinci tentang struktur Transformer dan aplikasinya - GPT, BERT, MT-DNN, GPT-2
Penjelasan terperinci tentang struktur Transformer dan aplikasinya - GPT, BERT, MT-DNN, GPT-2

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-05 18:05:271700semak imbas
Sebelum memperkenalkan Transformer, mari kita semak semula struktur RNN
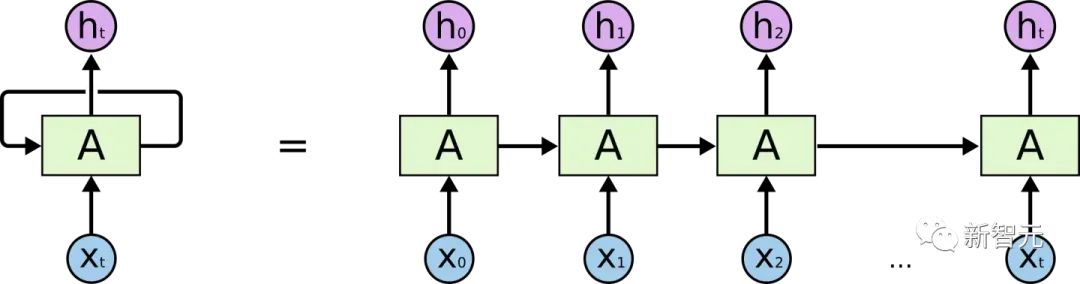
Jika anda mempunyai pemahaman tertentu tentang RNN, anda pasti akan tahu bahawa RNN Terdapat dua masalah yang jelas
- Isu kecekapan: ia perlu diproses perkataan demi perkataan, dan perkataan seterusnya tidak boleh diproses sehingga keadaan tersembunyi perkataan sebelumnya adalah output
- Jika jarak pemindahan terlalu panjang, akan berlaku kehilangan kecerunan, letupan kecerunan dan masalah lupa
Untuk mengurangkan kecerunan dan masalah melupakan antara pemindahan, Pelbagai sel RNN telah direka, dua yang paling terkenal ialah LSTM dan GRU
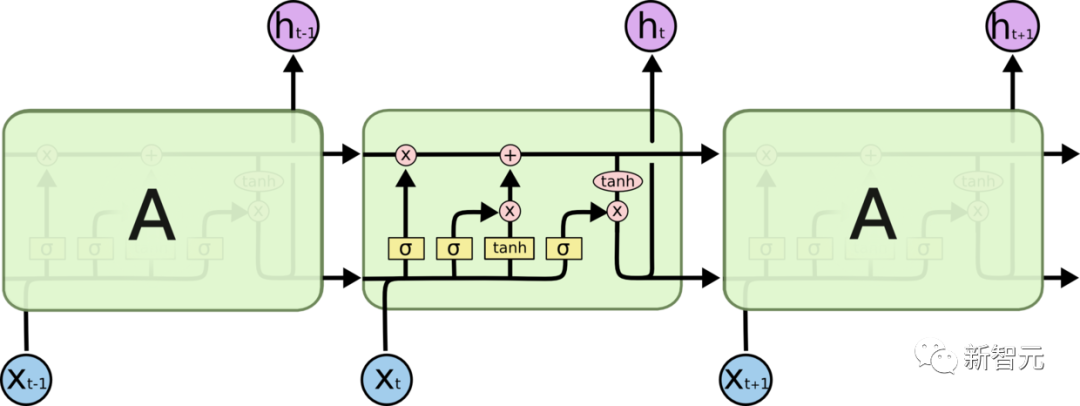
LSTM (Memori Jangka Pendek Panjang)
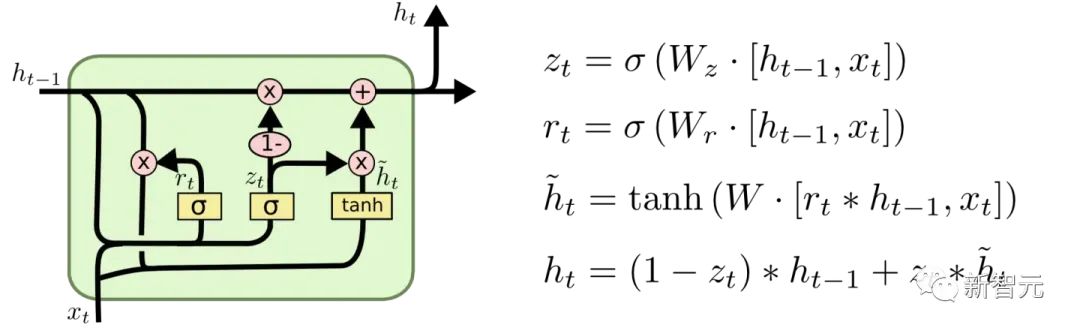
GRU (Unit Berulang Berpagar)
Walau bagaimanapun, untuk memetik metafora daripada blogger di Internet, berbuat demikian akan Ia seperti menukar roda gerabak, mengapa tidak menggantikannya dengan kereta sahaja?
Jadi terdapat struktur teras yang akan kami perkenalkan dalam artikel ini - Transformer. Transformer ialah kerja yang dicadangkan oleh Google Brain 2017. Ia mereka bentuk semula kelemahan RNN, menyelesaikan isu kecekapan RNN dan kecacatan penghantaran serta mengatasi prestasi RNN dalam banyak isu. Struktur asas Transformer ditunjukkan dalam rajah di bawah Ia adalah struktur N-in-N-out Maksudnya, setiap unit Transformer adalah bersamaan dengan lapisan RNN Ia menerima semua perkataan bagi keseluruhan ayat sebagai input, dan kemudian menyediakan setiap perkataan dalam ayat Setiap perkataan menghasilkan output. Tetapi tidak seperti RNN, Transformer boleh memproses semua perkataan dalam ayat pada masa yang sama, dan jarak operasi antara mana-mana dua perkataan ialah 1. Ini secara berkesan menyelesaikan masalah kecekapan dan jarak RNN yang dinyatakan di atas.
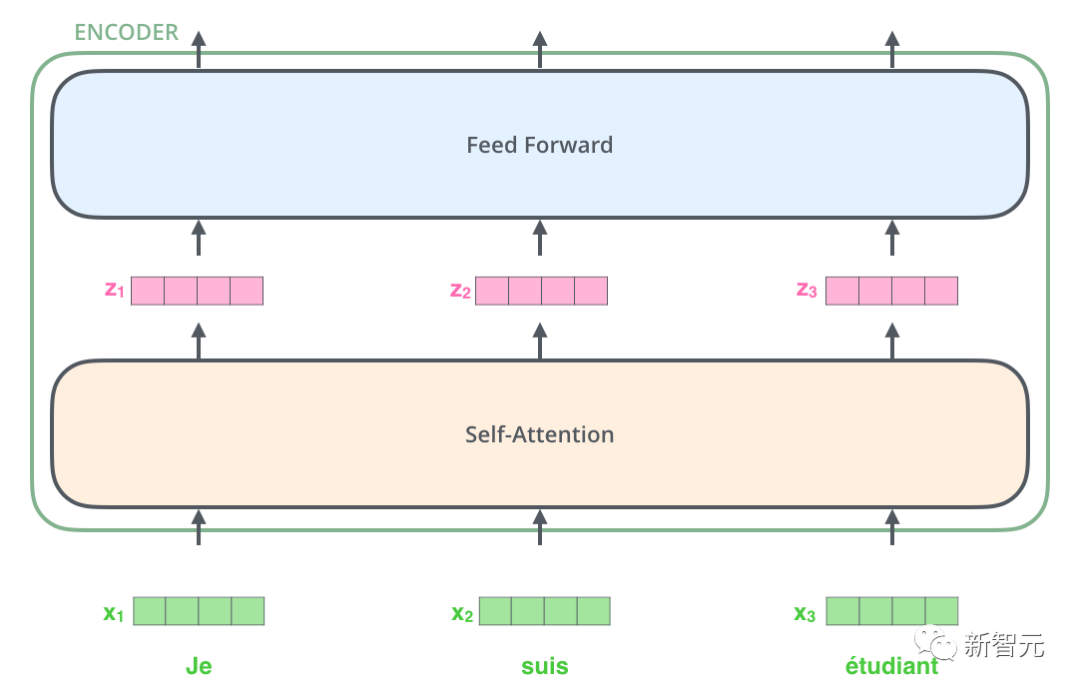
Setiap unit Transformer mempunyai dua sub-lapisan yang paling penting, iaitu lapisan Self-Attention dan lapisan Feed Forward, yang akan dibincangkan kemudian. struktur terperinci dua lapisan diperkenalkan. Artikel tersebut menggunakan Transformer untuk membina model terjemahan bahasa yang serupa dengan Seq2Seq, dan mereka bentuk dua struktur Transformer berbeza untuk Pengekod dan Penyahkod.
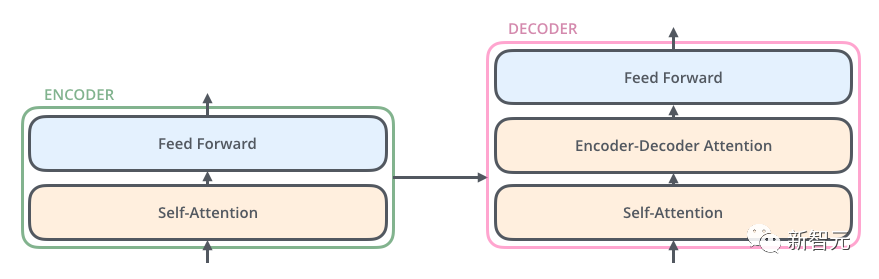
Pengubah Penyahkod mempunyai lapisan Perhatian Pengekod-Penyahkod tambahan berbanding dengan Pengubah Pengekod, yang digunakan untuk menerima output daripada Pengekod sebagai parameter. Akhirnya, selagi ia disusun seperti yang ditunjukkan dalam rajah di bawah, struktur Transformer Seq2Seq boleh disiapkan.
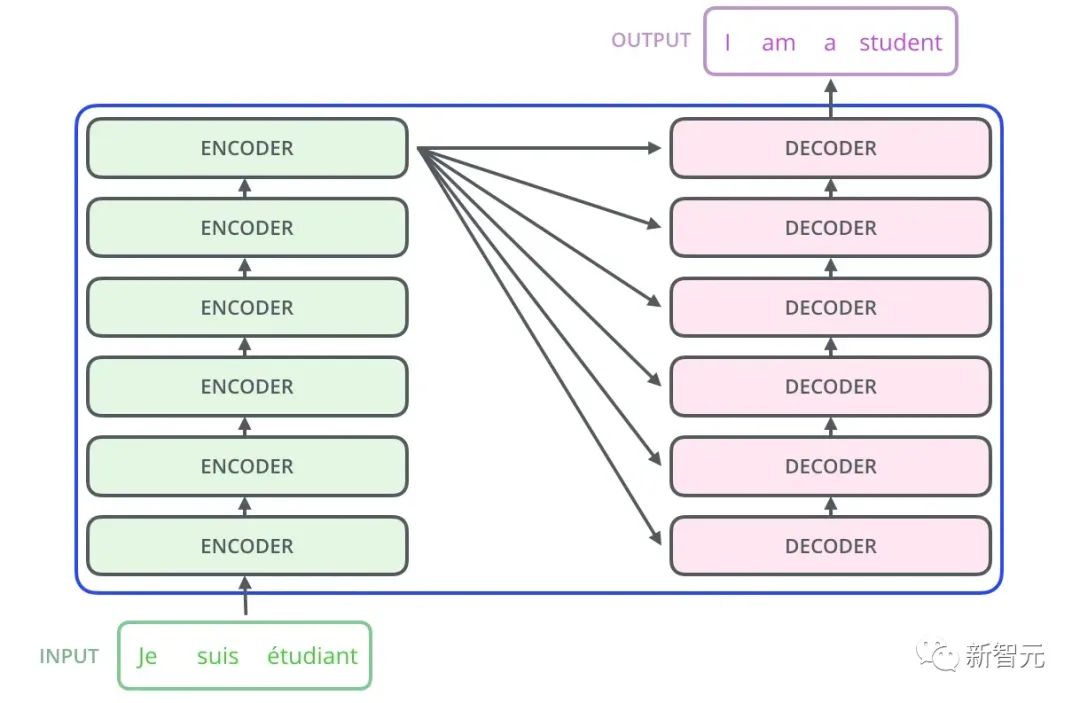
Beri saya contoh cara menggunakan Transformer Seq2Seq ini untuk terjemahan
- Pertama daripada semua, Transformer mengekod ayat dalam bahasa asal dan memperoleh ingatan.
- Apabila menyahkod buat kali pertama, input hanya satu tanda
- Output unik yang diperoleh oleh penyahkod daripada input unik ini digunakan untuk meramal perkataan pertama ayat.
Nyahkod untuk kali kedua dan tambahkan output pertama pada input Input menjadi
Setelah memahami struktur umum Transformer dan cara menggunakannya untuk menyelesaikan tugas terjemahan, mari kita lihat struktur terperinci Transformer :
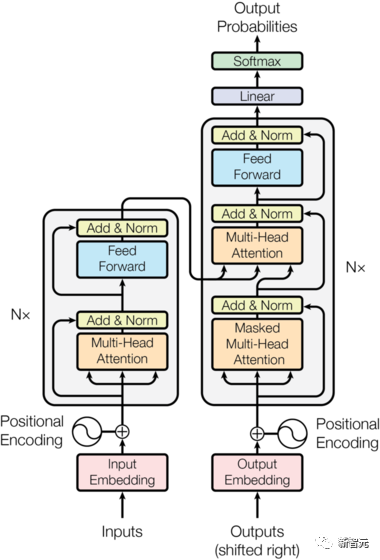
Komponen teras ialah Rangkaian Perhatian Kendiri dan Suapan Ke Hadapan yang dinyatakan di atas, tetapi terdapat banyak butiran lain Seterusnya, kami akan mula mentafsir struktur Transformer mengikut struktur.
Perhatian Diri
Perhatian Diri ialah apabila sesuatu perkataan dalam ayat memberi perhatian kepada semua perkataannya. Kira berat setiap perkataan untuk perkataan ini, dan kemudian mewakili perkataan ini sebagai jumlah wajaran semua perkataan. Setiap operasi Perhatian Diri adalah seperti operasi Konvolusi atau operasi Pengagregatan untuk setiap perkataan. Operasi khusus adalah seperti berikut:
Pertama, setiap perkataan mengalami perubahan linear melalui tiga matriks Wq, Wk, Wv, dibahagikan kepada tiga, untuk menjana pertanyaannya sendiri bagi setiap perkataan , vektor ialah tiga vektor. Apabila melakukan Perhatian Diri dengan perkataan sebagai pusat, vektor kunci perkataan digunakan untuk melakukan produk titik dengan vektor pertanyaan bagi setiap perkataan, dan kemudian berat dinormalisasi melalui Softmax. Kemudian gunakan pemberat ini untuk mengira jumlah wajaran bagi vektor semua perkataan sebagai output perkataan ini. Proses khusus ditunjukkan dalam rajah di bawah
Sebelum normalisasi, ia perlu dinormalisasi dengan membahagikan dengan dimensi dk vektor, jadi Perhatian Diri akhir boleh dinyatakan sebagai
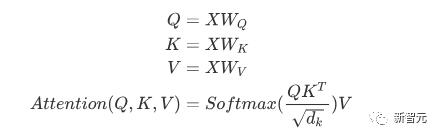
Akhir sekali, setiap Perhatian Kendiri menerima input n vektor perkataan dan output n Vektor teragregat.
Seperti yang dinyatakan di atas, Perhatian Diri dalam Pengekod adalah berbeza daripada yang terdapat dalam Penyahkod Q, K dan V dalam Pengekod semuanya datang daripada output unit lapisan atas , manakala Penyahkod hanya Q datang daripada output unit Penyahkod sebelumnya, dan K dan V kedua-duanya datang daripada output lapisan terakhir Pengekod. Dalam erti kata lain, Penyahkod mengira berat melalui keadaan semasa dan output Pengekod, dan kemudian menimbang pengekodan Pengekod untuk mendapatkan keadaan lapisan seterusnya.
Perhatian Bertopeng
Dengan memerhati gambar rajah struktur di atas, kita juga boleh mencari perbezaan lain antara Penyahkod dan Pengekod. Iaitu, lapisan input setiap unit Penyahkod mesti terlebih dahulu melalui lapisan Perhatian Bertopeng. Jadi apakah perbezaan antara Masked dan versi Attention biasa?
Pengekod perlu mempertimbangkan konteks setiap perkataan kerana ia ingin mengekod keseluruhan ayat. Oleh itu, semasa proses pengiraan setiap perkataan, semua perkataan dalam ayat dapat dilihat. Walau bagaimanapun, Penyahkod adalah serupa dengan penyahkod dalam Seq2Seq Setiap perkataan hanya boleh melihat status perkataan sebelumnya, jadi ia adalah struktur Perhatian Kendiri sehala.
Pelaksanaan Masked Attention juga sangat mudah Hanya tambah (&) pada matriks segi tiga bawah sebelum ini sebelum langkah Softmax Perhatian Diri biasa
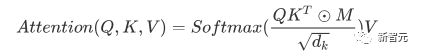
Multi-Head Attention
Multi-Head Attention ialah melakukan Perhatian di atas h kali, Kemudian concat keluaran h untuk mendapatkan keluaran akhir. Ini boleh meningkatkan kestabilan algoritma dan mempunyai aplikasi yang berkaitan dalam banyak kerja berkaitan Perhatian. Dalam pelaksanaan Transformer, untuk meningkatkan kecekapan Multi-Head, W dikembangkan dengan h kali, dan kemudian k, q, dan v kepala yang berbeza bagi perkataan yang sama disusun bersama untuk pengiraan serentak melalui pandangan (bentuk semula ) dan operasi transpose untuk melengkapkan pengiraan Kemudian penyambungan dilengkapkan semula melalui bentuk semula dan transpose, yang bersamaan dengan pemprosesan selari semua kepala.
Rangkaian Suapan Hadapan Bijak Kedudukan
n vektor keluaran selepas Perhatian dalam Pengekod dan Penyahkod ( Berikut n ialah bilangan perkataan) masing-masing dimasukkan ke dalam lapisan yang disambungkan sepenuhnya untuk melengkapkan rangkaian suapan hadapan kedudukan demi kedudukan.
Tambah & Norma ialah rangkaian sisa, yang hanya menambah input satu lapisan dan output piawainya. Setiap lapisan Perhatian Diri dan lapisan FFN dalam Transformer akan diikuti oleh lapisan Tambah & Norma. Pengekodan Kedudukan Memandangkan tiada RNN dalam Transformer mahupun Unlike CNN, semua perkataan dalam ayat dilayan sama rata, jadi tidak ada hubungan berurutan antara perkataan. Dalam erti kata lain, ia berkemungkinan mengalami kekurangan yang sama seperti model beg-of-words. Bagi menyelesaikan masalah ini, Transformer mencadangkan penyelesaian Pengekodan Kedudukan, iaitu menindih vektor tetap pada setiap vektor perkataan input untuk mewakili kedudukannya. Pengekodan Kedudukan yang digunakan dalam artikel ini adalah seperti berikut: di mana pos ialah kedudukan perkataan dalam ayat, i ialah kedudukan ke-i dalam vektor perkataan, iaitu, vektor perkataan setiap perkataan ditindih ke dalam satu baris, Kemudian gelombang dengan fasa yang berbeza atau panjang gelombang yang semakin meningkat secara beransur-ansur ditindih pada setiap lajur untuk membezakan kedudukan secara unik. Aliran kerja Transformer Aliran kerja Transformer ialah penyambungan setiap sub-proses yang diperkenalkan di atas Tambah & Normalisasi->FFN->Tambah & Normalkan proses, dan kemudian masukkan output ke Pengekod seterusnya Post Scriptum Model latihan dua peringkat sehala - OpenAI GPT GPT adalah salah satu percubaan untuk menggunakan Transformer untuk melaksanakan pelbagai tugas bahasa semula jadi. Terdapat tiga perkara utama:
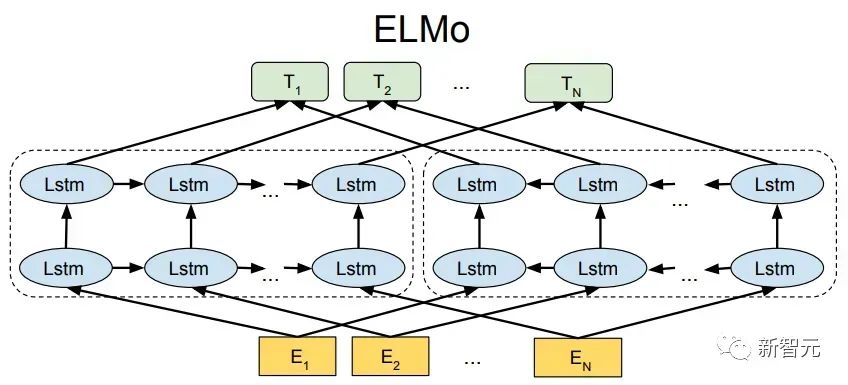
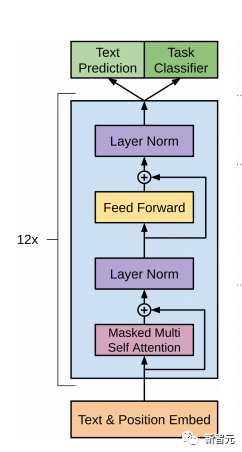
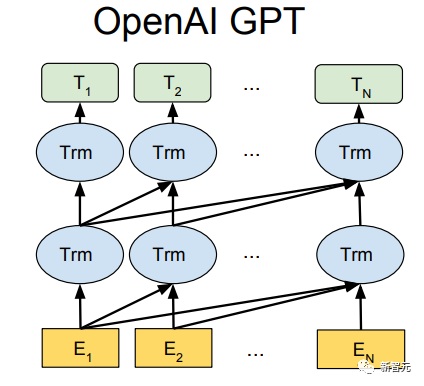
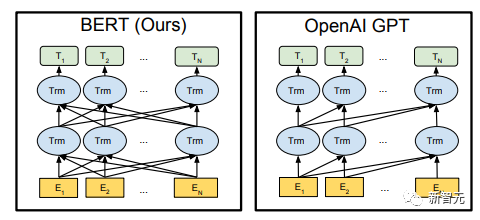
Pra. - Kaedah latihan Model Transformer Sehala Banyak tugas pembelajaran mesin memerlukan set data berlabel sebagai input. Tetapi terdapat sejumlah besar data tidak berlabel di sekeliling kita, seperti teks, gambar, kod, dsb. Pelabelan data ini memerlukan banyak tenaga kerja dan masa, dan kelajuan pelabelan adalah jauh lebih rendah daripada kelajuan penjanaan data, jadi data berlabel selalunya hanya menduduki sebahagian kecil daripada jumlah set data. Apabila kuasa pengkomputeran terus bertambah baik, jumlah data yang boleh diproses oleh komputer meningkat secara beransur-ansur. Merupakan satu pembaziran jika data yang tidak berlabel ini tidak dapat digunakan dengan baik. Jadi model dua peringkat pembelajaran separa penyeliaan dan pra-latihan + penalaan halus menjadi semakin popular. Kaedah dua peringkat yang paling biasa ialah Word2Vec, yang menggunakan sejumlah besar teks tidak berlabel untuk melatih vektor perkataan dengan maklumat semantik tertentu, dan kemudian menggunakan vektor perkataan ini sebagai input untuk tugas pembelajaran mesin hiliran, yang boleh meningkatkan keupayaan generalisasi model hiliran. Tetapi terdapat masalah dengan Word2Vec, iaitu, satu perkataan hanya boleh mempunyai satu Pembenaman. Dengan cara ini, polisemi tidak dapat diwakili dengan baik. ELMo pertama kali memikirkan untuk menyediakan maklumat kontekstual bagi setiap set kosa kata dalam peringkat pra-latihan, menggunakan model bahasa berdasarkan bi-LSTM untuk membawa maklumat semantik kontekstual kepada vektor perkataan: Formula di atas mewakili LSTM-RNN kiri dan kanan masing-masing. ialah, menggunakan dua hala Keluaran dua hala RNN digunakan untuk meramal perkataan seterusnya secara serentak (yang seterusnya di sebelah kanan, yang sebelumnya di sebelah kiri Struktur khusus adalah seperti yang ditunjukkan dalam rajah di bawah: Tetapi ELMo menggunakan RNN untuk melengkapkan pra-latihan model bahasa, jadi bagaimana menggunakan Transformer untuk melengkapkan pra-latihan? Struktur Transformer Sehala OpenAI GPT menggunakan Transformer sehala untuk menyelesaikan tugas pra-latihan ini . Apakah itu Transformer sehala? Dalam artikel Transformer, disebutkan bahawa Blok Transformer yang digunakan oleh Pengekod dan Penyahkod adalah berbeza. Dalam Blok Dekoder, Perhatian Diri Bertopeng digunakan, iaitu setiap perkataan dalam ayat hanya boleh memberi perhatian kepada semua perkataan sebelumnya termasuk dirinya sendiri Ini adalah Transformer sehala. Struktur Transformer yang digunakan oleh GPT adalah untuk menggantikan Self-Attention dalam Pengekod dengan Masked Self-Attention Struktur khusus adalah seperti yang ditunjukkan dalam rajah di bawah:
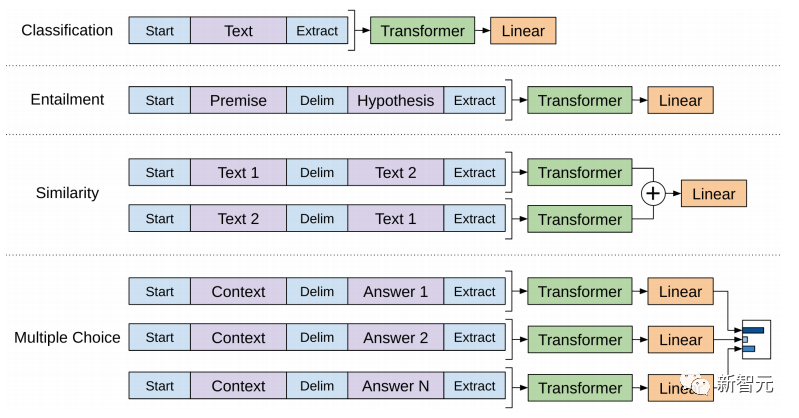
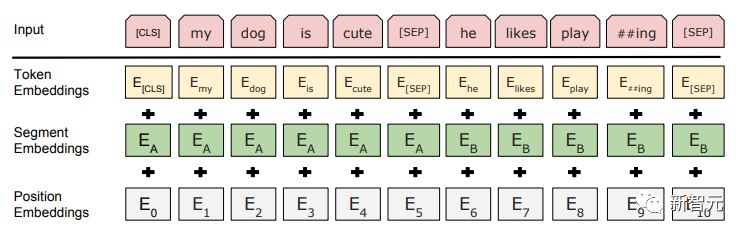
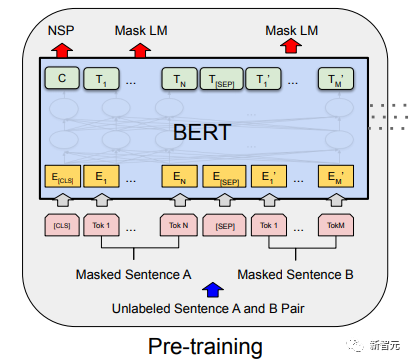
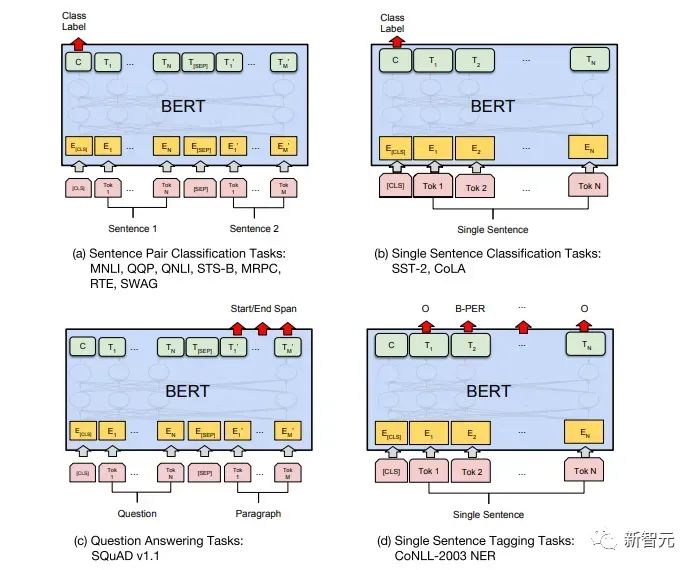
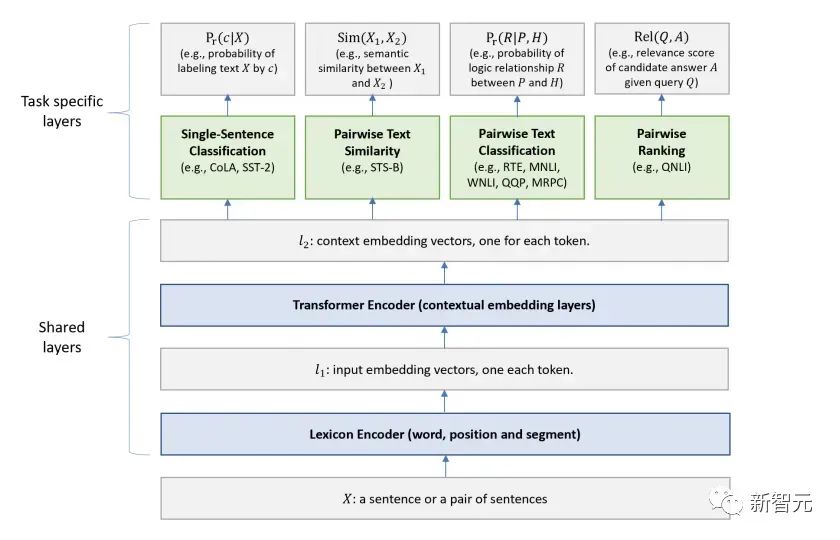
Penalaan Halus dan perubahan dalam struktur data input yang berbeza Seterusnya, masukkan langkah kedua latihan model, menggunakan sejumlah kecil data berlabel untuk memperhalusi parameter model. Kami tidak menggunakan output perkataan terakhir dalam langkah sebelumnya. Dalam langkah ini, kami akan menggunakan output ini sebagai input pembelajaran seliaan hiliran. Untuk mengelakkan Penalaan Halus menyebabkan model terlampau, artikel itu turut menyebut sasaran latihan tambahan Kaedah ini serupa dengan model pelbagai tugas atau pembelajaran separa penyeliaan. Kaedah khusus adalah menggunakan hasil ramalan perkataan terakhir untuk pembelajaran diselia sambil meneruskan latihan tanpa pengawasan perkataan sebelumnya, supaya fungsi kehilangan akhir menjadi: Untuk tugasan yang berbeza, format data input perlu diubah suai: Pautan GitHub: https://github.com/openai/finetune-transformer-lm Post Scriptum OpenAI GPT telah membuat penerokaan hebat dalam penggunaan Transformer dan kaedah latihan dua peringkat , dan juga Mencapai keputusan yang sangat baik, membuka jalan untuk BERT nanti. Model latihan dua peringkat dua hala - BERT BERT (Perwakilan Pengekod Dua Arah daripada Transformer) ialah rangka kerja perwakilan bahasa semula jadi berdasarkan Transformer yang dicadangkan oleh Google Brain pada 2018 . Ia adalah model bintang yang menjadi popular sebaik sahaja ia dicadangkan. Seperti GPT, BERT mengguna pakai kaedah latihan Pra-latihan + Penalaan Halus, dan mencapai hasil yang lebih baik dalam tugas seperti pengelasan dan pelabelan. BERT sangat serupa dengan GPT Kedua-duanya adalah model latihan dua peringkat berdasarkan Transformer Mereka dibahagikan kepada dua peringkat: Pra-Latihan dan Penalaan Halus. peringkat latihan. Model Transformer universal dilatih dengan cara yang diselia, dan kemudian parameter dalam model ini diperhalusi dalam peringkat Penalaan Halus untuk menyesuaikannya dengan tugas hiliran yang berbeza. Walaupun BERT dan GPT kelihatan sangat serupa, matlamat latihan, struktur model dan penggunaan mereka masih sedikit berbeza: Dwiarah Transformer BERT menggunakan Transformer yang tidak melalui Mask struktur Transformer Pengekod dalam artikel Transformer adalah betul-betul sama: Dalam GPT, kerana latihan model bahasa perlu diselesaikan, Pra-Latihan diperlukan hanya untuk dapat untuk melihat perkataan seterusnya apabila meramalkannya. Perkataan semasa dan sebelumnya, inilah sebabnya GPT meninggalkan struktur dua hala asal Transformer dan menggunakan struktur sehala. BERT menggunakan Transformer dua hala untuk mendapatkan maklumat kontekstual pada masa yang sama, dan bukannya menyerahkan sepenuhnya maklumat kontekstual seperti GPT. Tetapi dengan cara ini, tidak mungkin lagi menggunakan model bahasa biasa untuk pra-latihan seperti GPT, kerana struktur BERT menyebabkan output setiap Transformer untuk melihat keseluruhan ayat Tidak kira apa yang anda gunakan untuk meramalkan output ini. anda akan "melihatnya" "Jawapan rujukan, iaitu soalan "lihat sendiri". Walaupun ELMo menggunakan RNN dua hala, kedua-dua RNN adalah bebas, jadi masalah melihat dirinya boleh dielakkan. Fasa Pra-Latihan Lepas tu BERT nak guna dua Model Transformer -way, kita perlu melepaskan model bahasa yang digunakan dalam GPT sebagai fungsi objektif pra-latihan. Sebaliknya, BERT mencadangkan kaedah pra-latihan yang sama sekali berbeza. Dalam Transformer, kami ingin mengetahui maklumat di atas, Jika anda mahu untuk mengetahui maklumat di bawah, tetapi pada masa yang sama pastikan bahawa keseluruhan model tidak mengetahui maklumat tentang perkataan yang akan diramalkan, maka jangan beritahu model maklumat tentang perkataan itu. Maksudnya, BERT mencungkil beberapa perkataan yang perlu diramalkan dalam ayat input, kemudian menganalisis ayat tersebut melalui konteks, dan akhirnya menggunakan output kedudukan yang sepadan untuk meramalkan perkataan yang digali. Ia sebenarnya seperti melakukan cloze. Walau bagaimanapun, menggantikan secara langsung sejumlah besar perkataan dengan teg 1 Pilih secara rawak 15% perkataan dalam data input untuk ramalan , 2.80% daripada vektor perkataan digantikan dengan 3.10% daripada vektor perkataan digantikan pada input Untuk vektor perkataan perkataan lain 4 10% yang lain kekal tidak berubah Ini bersamaan dengan memberitahu model yang saya boleh berikan kepada Anda. jawapan mungkin tidak memberi anda jawapan, atau ia mungkin memberi anda jawapan yang salah saya akan menyemak jawapan anda di mana terdapat BERT juga mencadangkan satu lagi kaedah pra-latihan NSP, yang digabungkan dengan MLM Dilaksanakan serentak untuk membentuk pra-latihan pelbagai tugas. Kaedah pra-latihan ini adalah untuk memasukkan dua ayat berturut-turut ke dalam Transformer Ayat kiri didahului oleh teg Untuk membezakan hubungan antara kedua-dua ayat, BERT bukan sahaja menambah Positional Encoding, tetapi juga menambah Segmen Embedding yang perlu dipelajari semasa pra-latihan untuk membezakan kedua-dua ayat . Dengan cara ini, input BERT terdiri daripada penambahan tiga bahagian: vektor perkataan, vektor kedudukan dan vektor segmen. Selain itu, kedua-dua ayat itu dibezakan menggunakan tag Rajah Pra-Latihan keseluruhan adalah seperti berikut: Peringkat Penalaan Halus Peringkat Penalaan Halus BERT tidak jauh berbeza dengan GPT. Kerana penggunaan Transformer dua hala, sasaran latihan tambahan yang digunakan oleh GPT dalam peringkat Penalaan Halus, iaitu model bahasa, ditinggalkan. Selain itu, vektor keluaran untuk ramalan pengelasan ditukar daripada kedudukan keluaran perkataan terakhir GPT kepada kedudukan Pautan GitHub: https://github.com/google -research/bert Post Scriptum Secara peribadi, saya rasa BERT hanyalah pertukaran model GPT Dalam kedua-dua peringkat, maklumat konteks ayat boleh diperolehi secara serentak, menggunakan model Transformer dua arah. Tetapi untuk ini, kita perlu membayar harga kehilangan model bahasa tradisional, dan sebaliknya menggunakan kaedah yang lebih kompleks seperti MLM+NSP untuk pra-latihan. Model berbilang tugas - MT-DNN MT-DNN (Rangkaian Neural Dalam Pelbagai Tugas) masih menggunakan kaedah latihan dua peringkat BERT dan Transformer dwiarah. Dalam peringkat Pra-Latihan, MT-DNN hampir sama dengan BERT, tetapi dalam peringkat Penalaan Halus, MT-DNN menggunakan kaedah penalaan halus berbilang tugas. Pada masa yang sama, output Embedding konteks oleh Transformer digunakan untuk latihan tentang tugasan seperti klasifikasi ayat tunggal, persamaan pasangan teks, klasifikasi pasangan teks dan soal jawab. Keseluruhan struktur ditunjukkan di bawah: Pautan GitHub: https://github.com/namisan/mt-dnn GPT-2 terus menggunakan model Transformer sehala yang asalnya digunakan dalam GPT, dan tujuan artikel ini Ia adalah untuk memanfaatkan Transformer sehala sebanyak mungkin dan melakukan sesuatu yang tidak dapat dilakukan oleh Transformer dua hala yang digunakan oleh BERT. Iaitu untuk menjana teks berikut daripada di atas. Idea GPT-2 adalah untuk meninggalkan sepenuhnya proses Penalaan Halus dan sebaliknya menggunakan kapasiti yang lebih besar, latihan tanpa pengawasan dan model bahasa yang lebih umum untuk menyelesaikan pelbagai tugas . Kita tidak perlu menentukan tugas yang harus dilakukan oleh model ini sama sekali, kerana maklumat yang terkandung dalam banyak teg wujud dalam korpus. Sama seperti jika seseorang membaca banyak buku, dia boleh secara automatik merumuskan, menjawab soalan dan terus menulis artikel berdasarkan kandungan yang telah dibacanya. Tegasnya, GPT-2 mungkin bukan model berbilang tugas, tetapi ia menggunakan model yang sama dan parameter yang sama untuk menyelesaikan tugasan yang berbeza. Biasanya kami melatih model khusus untuk tugasan tertentu Memandangkan input, kami boleh mengembalikan output tugasan yang sepadan, iaitu, <.> Jadi jika kita ingin mereka bentuk model umum, yang memerlukan input yang diberikan dan jenis tugasan yang diberikan, dan kemudian membuat output yang sepadan berdasarkan input dan tugas yang diberikan, maka modelnya ialah Ia boleh diungkapkan seperti berikut Ia seperti jika saya perlu menterjemah ayat, saya perlu mereka bentuk model terjemahan, dan jika saya mahu soalan dan sistem jawapan, saya perlu mereka bentuknya secara khusus. Tetapi jika model cukup pintar dan boleh menjana konteks berdasarkan konteks anda, maka kami boleh membezakan pelbagai masalah dengan menambahkan beberapa pengecam pada input. Sebagai contoh, kita boleh bertanya kepadanya secara langsung: (‘Pemprosesan Bahasa Asli’, terjemahan bahasa Cina) untuk mendapatkan hasil yang kita perlukan Pemprosesan Bahasa Alam. Pada pemahaman saya, GPT-2 lebih seperti sistem soalan dan jawapan yang serba tahu Dengan memaklumkan pengecam tugasan yang diberikan, ia boleh membuat jawapan yang sesuai untuk soalan dan jawapan dalam pelbagai bidang dan tugas. GPT-2 memenuhi tetapan sifar pukulan Tidak perlu memberitahunya tugas yang perlu diselesaikan semasa proses latihan, dan ramalan juga boleh memberikan jawapan yang lebih munasabah. Jadi apakah yang telah GPT-2 lakukan untuk memenuhi keperluan di atas? Meluaskan dan besarkan set data Perkara pertama ialah membuat model dibaca dengan baik, jika sampel latihan tidak mencukupi Jika terlalu banyak, maka bagaimana kita boleh membuat alasan? Kerja sebelumnya tertumpu pada masalah tertentu, jadi set data agak berat sebelah. GPT-2 mengumpul set data yang lebih besar dan lebih luas. Pada masa yang sama, kami mesti memastikan kualiti set data ini dan mengekalkan halaman web dengan kandungan berkualiti tinggi. Akhirnya, 8 juta teks, set data 40G WebText telah dibentuk. Meluaskan kapasiti rangkaian Jika anda mempunyai terlalu banyak buku, anda perlu membawa bersama anda, jika tidak, anda tidak akan dapat mengingati mereka. Untuk meningkatkan kapasiti rangkaian dan menjadikannya mempunyai potensi pembelajaran yang lebih kuat, GPT-2 meningkatkan bilangan lapisan tindanan Transformer kepada 48 lapisan, dimensi lapisan tersembunyi ialah 1600, dan bilangan parameter mencapai 1.5 bilion. Laraskan struktur rangkaian GPT-2 meningkatkan perbendaharaan kata kepada 50257, saiz konteks maksimum ) telah meningkat daripada GPT 512 kepada 1024, dan saiz kelompok telah ditingkatkan daripada 512 kepada 1024. Di samping itu, pelarasan kecil telah dibuat pada Transformer Lapisan normalisasi diletakkan sebelum setiap sub-blok, dan lapisan normalisasi telah ditambah selepas Perhatian kendiri terakhir diubah, dsb. Pautan GitHub: https://github.com/openai/gpt-2 Siaran Scriptum Malah, perkara yang paling menakjubkan tentang GPT-2 ialah keupayaan penjanaan yang sangat kuat, dan keupayaan penjanaan yang berkuasa itu terutamanya disebabkan oleh kualiti data dan bilangan yang menakjubkan parameter dan saiz Data. Bilangan parameter GPT-2 adalah sangat besar sehingga model yang digunakan untuk eksperimen masih dalam keadaan kurang sesuai Jika ia dilatih lagi, kesannya boleh dipertingkatkan lagi. Sebagai ringkasan pembangunan kerja Transformer di atas, saya juga telah menyusun beberapa pemikiran peribadi tentang trend pembangunan pembelajaran mendalam: 1. Model diselia berkembang ke arah separa diselia atau bahkan tidak diselia Kadar pertumbuhan skala data jauh melebihi anotasi kelajuan data, yang juga membawa kepada penjanaan sejumlah besar data tidak berlabel. Data tidak berlabel ini bukan tanpa nilai Sebaliknya, jika anda menemui "alkimia" yang betul, anda akan dapat memperoleh nilai yang tidak dijangka daripada data besar ini. Cara menggunakan data tidak berlabel ini untuk meningkatkan prestasi tugas telah menjadi isu yang semakin penting yang tidak boleh diabaikan. 2 Daripada model yang kompleks dengan jumlah data yang kecil kepada model yang ringkas dengan jumlah data yang banyak <.>Keupayaan pemasangan rangkaian saraf dalam sangat Sangat berkuasa sehingga model rangkaian saraf yang ringkas sudah cukup untuk memuatkan sebarang fungsi. Walau bagaimanapun, sukar untuk menggunakan struktur rangkaian yang lebih mudah untuk menyelesaikan tugas yang sama, dan keperluan untuk volum data juga lebih tinggi. Lebih banyak jumlah data meningkat dan kualiti data bertambah baik, lebih kerap keperluan untuk model akan berkurangan. Lebih besar jumlah data, lebih mudah model untuk menangkap ciri yang konsisten dengan pengedaran dunia sebenar. Word2Vec ialah satu contoh Fungsi objektif yang digunakan adalah sangat mudah, tetapi kerana sejumlah besar teks digunakan, vektor perkataan terlatih mengandungi banyak ciri menarik. 3 Pembangunan daripada model khusus kepada model umum GPT, BERT, MT-DNN, GPT-2. Mereka semua menggunakan model am yang telah dilatih untuk meneruskan tugas pembelajaran mesin hiliran, dan tidak perlu membuat terlalu banyak pengubahsuaian pada model itu sendiri. Jika keupayaan ekspresif model cukup kuat dan jumlah data yang digunakan semasa latihan cukup besar, maka model itu akan menjadi lebih serba boleh dan tidak perlu diubah suai terlalu banyak untuk tugasan tertentu. Kes yang paling ekstrem adalah seperti GPT-2, yang boleh melatih model pelbagai tugas umum tanpa mengetahui tugas hiliran seterusnya semasa latihan. 4. Peningkatan keperluan untuk skala dan kualiti data Walaupun GPT, BERT, MT-DNN dan GPT-2 telah berturut-turut mendahului senarai, saya berpendapat bahawa dalam peningkatan prestasi, peningkatan skala data menyumbang bahagian yang lebih besar daripada pelarasan struktur. Dengan generalisasi dan penyederhanaan model, untuk meningkatkan prestasi model, perhatian yang lebih akan beralih daripada cara mereka bentuk model yang kompleks dan khusus kepada cara mendapatkan, membersihkan dan memperhalusi sejumlah besar model dengan kualiti unggul data tersebut. Kesan pelarasan kaedah pemprosesan data akan lebih besar daripada kesan pelarasan struktur model. Ringkasnya, pertandingan DL lambat laun akan menjadi persaingan antara pengeluar utama untuk sumber dan kuasa pengkomputeran. Topik baharu mungkin muncul dalam masa beberapa tahun: AI hijau, AI rendah karbon, AI mampan, dsb. 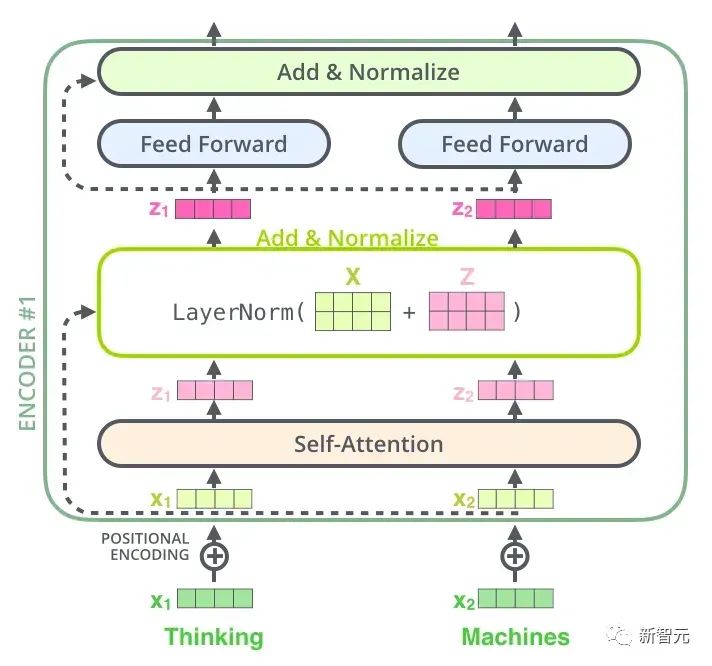
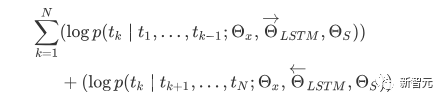
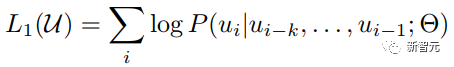
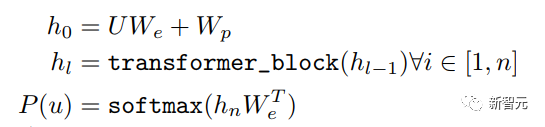
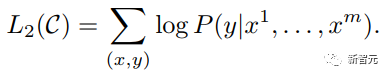
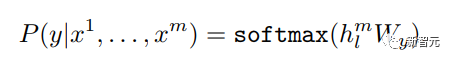
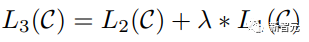
Model umum sehala - GPT-2
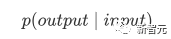
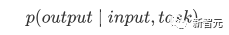
Ringkasan
Atas ialah kandungan terperinci Penjelasan terperinci tentang struktur Transformer dan aplikasinya - GPT, BERT, MT-DNN, GPT-2. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI