
Rumah >Peranti teknologi >AI >Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.
Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.

- 王林ke hadapan
- 2023-06-05 16:03:33841semak imbas
Baru-baru ini, model bahasa tanpa pengawasan yang dilatih pada set data besar telah memperoleh keupayaan yang mengejutkan. Walau bagaimanapun, model ini dilatih mengenai data yang dijana oleh manusia dengan pelbagai matlamat, keutamaan dan set kemahiran, beberapa daripadanya tidak semestinya diharapkan untuk ditiru.
Memilih tindak balas dan gelagat yang dikehendaki model daripada pengetahuan dan keupayaannya yang sangat luas adalah penting untuk membina sistem AI yang selamat, berprestasi tinggi dan boleh dikawal. Banyak kaedah sedia ada menanamkan tingkah laku yang diingini ke dalam model bahasa dengan menggunakan set keutamaan manusia yang disusun dengan teliti yang mewakili jenis tingkah laku yang dianggap selamat dan bermanfaat oleh manusia Peringkat pembelajaran keutamaan ini berlaku pada set data teks yang besar Selepas fasa awal pra tanpa pengawasan -latihan.
Walaupun kaedah pembelajaran keutamaan yang paling mudah diselia penalaan halus bagi respons berkualiti tinggi yang ditunjukkan oleh manusia, kelas kaedah yang agak popular baru-baru ini adalah daripada maklum balas manusia (atau kecerdasan buatan) Laksanakan pembelajaran pengukuhan (RLHF/RLAIF). Kaedah RLHF memadankan model ganjaran kepada set data keutamaan manusia dan kemudian menggunakan RL untuk mengoptimumkan dasar model bahasa untuk menghasilkan respons yang memberikan ganjaran tinggi tanpa menyimpang secara berlebihan daripada model asal.
Sementara RLHF menghasilkan model dengan keupayaan perbualan dan pengekodan yang mengagumkan, saluran paip RLHF adalah jauh lebih kompleks daripada pembelajaran diselia, melibatkan latihan pelbagai model bahasa dan gelung melalui latihan Persampelan daripada dasar model bahasa menimbulkan kos pengiraan yang besar.
Dan satu kajian baru-baru ini menunjukkan bahawa: Objektif berasaskan RL yang digunakan oleh kaedah sedia ada boleh dioptimumkan dengan tepat dengan objektif rentas entropi binari yang mudah, dengan itu sangat Dipermudahkan saluran paip pembelajaran keutamaan. Iaitu, adalah mustahil untuk mengoptimumkan model bahasa secara langsung untuk mematuhi pilihan manusia tanpa memerlukan model ganjaran yang jelas atau pembelajaran pengukuhan.

Pautan kertas: https://arxiv.org/pdf/2305.18290 .pdf
Penyelidik dari Universiti Stanford dan institusi lain mencadangkan Pengoptimuman Keutamaan Langsung (DPO) Algoritma ini secara tersirat mengoptimumkan algoritma RLHF yang sedia ada (pemaksimumkan ganjaran dengan KL - divergence kekangan), tetapi mudah untuk dilaksanakan dan mudah untuk dilatih.
Eksperimen menunjukkan bahawa DPO sekurang-kurangnya berkesan seperti kaedah sedia ada, termasuk yang berdasarkan RLHF PPO.
Algoritma DPO
Seperti algoritma sedia ada, DPO juga bergantung pada model keutamaan teori (seperti model Bradley-Terry) untuk mengukur Seberapa baik fungsi ganjaran sesuai dengan data keutamaan empirikal. Walau bagaimanapun, kaedah sedia ada menggunakan model keutamaan untuk menentukan kehilangan keutamaan untuk melatih model ganjaran dan kemudian melatih dasar yang mengoptimumkan model ganjaran yang dipelajari, manakala DPO menggunakan perubahan dalam pembolehubah untuk mentakrifkan kehilangan keutamaan secara langsung sebagai fungsi dasar. Memandangkan set data keutamaan manusia untuk tindak balas model, DPO oleh itu boleh mengoptimumkan dasar menggunakan objektif rentas entropi perduaan mudah tanpa perlu mempelajari secara eksplisit fungsi ganjaran atau sampel daripada dasar semasa latihan.
Kemas kini DPO meningkatkan kebarangkalian log relatif bagi tindak balas pilihan kepada tindak balas bukan pilihan, tetapi ia termasuk berat kepentingan setiap sampel yang dinamik untuk mengelakkan kemerosotan model, Para penyelidik mendapati bahawa kemerosotan ini berlaku untuk sasaran nisbah kebarangkalian naif.
Untuk memahami DPO secara mekanikal, adalah berguna untuk menganalisis kecerunan fungsi kehilangan  . Kecerunan berkenaan dengan parameter θ boleh ditulis sebagai:
. Kecerunan berkenaan dengan parameter θ boleh ditulis sebagai:
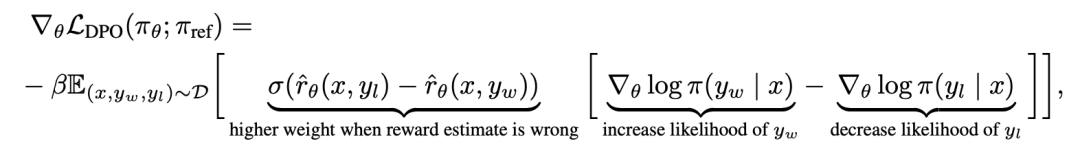
di mana 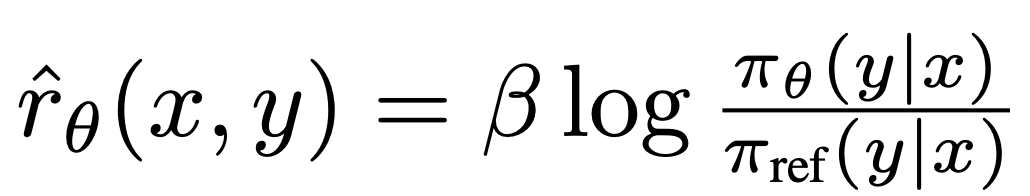 ialah ganjaran yang ditakrifkan secara tersirat oleh model bahasa
ialah ganjaran yang ditakrifkan secara tersirat oleh model bahasa 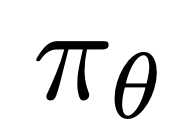 dan model rujukan
dan model rujukan 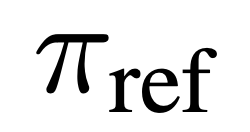 . Secara intuitif, kecerunan fungsi kehilangan
. Secara intuitif, kecerunan fungsi kehilangan  meningkatkan kemungkinan penyiapan pilihan y_w dan mengurangkan kemungkinan penyiapan bukan pilihan y_l.
meningkatkan kemungkinan penyiapan pilihan y_w dan mengurangkan kemungkinan penyiapan bukan pilihan y_l.
Yang penting, berat sampel ini ditentukan oleh model ganjaran tersirat 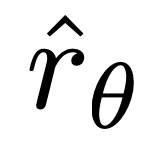 penilaian tahap penyiapan yang tidak disukai, dengan β ialah skala, iaitu, betapa tidak betulnya model ganjaran tersirat dalam kedudukan tahap penyiapan, yang juga mencerminkan kekuatan kekangan KL. Eksperimen menunjukkan kepentingan pemberat ini, kerana versi naif kaedah ini tanpa pekali pemberat membawa kepada kemerosotan model bahasa (Lampiran Jadual 2).
penilaian tahap penyiapan yang tidak disukai, dengan β ialah skala, iaitu, betapa tidak betulnya model ganjaran tersirat dalam kedudukan tahap penyiapan, yang juga mencerminkan kekuatan kekangan KL. Eksperimen menunjukkan kepentingan pemberat ini, kerana versi naif kaedah ini tanpa pekali pemberat membawa kepada kemerosotan model bahasa (Lampiran Jadual 2).
Dalam Bab 5 kertas kerja, penyelidik menjelaskan lagi kaedah DPO, memberikan sokongan teori, dan membandingkan kelebihan DPO dengan algoritma Actor-Critic untuk RLHF ( Seperti PPO) isu. Butiran khusus boleh didapati dalam kertas asal.
Eksperimen
Dalam percubaan, penyelidik menilai keupayaan DPO untuk melatih dasar secara langsung berdasarkan keutamaan.
Pertama, dalam persekitaran penjanaan teks yang dikawal dengan baik, mereka mempertimbangkan soalan: Berbanding dengan algoritma pembelajaran keutamaan biasa seperti PPO, DPO menukar pemaksimum ganjaran dalam dasar rujukan Sejauh manakah kecekapan KL-divergence minimization? Kami kemudian menilai prestasi DPO pada model yang lebih besar dan tugas RLHF yang lebih sukar, termasuk ringkasan dan dialog.
Akhirnya didapati bahawa dengan sedikit penalaan hiperparameter, DPO sering dilakukan serta, atau lebih baik daripada, garis dasar yang berkuasa seperti RLHF dengan PPO, sambil belajar ganjaran Fungsi mengembalikan yang terbaik Hasil trajektori pensampelan N.
Dari segi tugas, penyelidik meneroka tiga tugas penjanaan teks terbuka yang berbeza. Dalam semua percubaan, algoritma mempelajari dasar daripada set data keutamaan 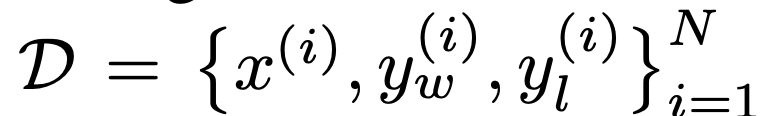 .
.
Dalam penjanaan emosi terkawal, x ialah awalan ulasan filem daripada set data IMDb dan dasar mesti menjana y dengan emosi positif. Untuk penilaian perbandingan, percubaan menggunakan pengelas sentimen yang telah dilatih untuk menjana pasangan pilihan, di mana 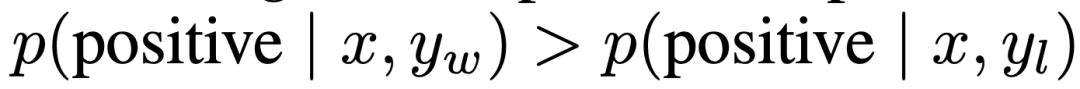 .
.
Untuk SFT, penyelidik memperhalusi GPT-2-besar sehingga ia menumpu kepada ulasan mengenai pembahagian latihan set data IMDB. Ringkasnya, x ialah siaran forum daripada Reddit, dan strategi mesti menjana ringkasan perkara utama dalam siaran. Berdasarkan kerja sebelumnya, eksperimen menggunakan set data ringkasan Reddit TL;DR dan pilihan manusia yang dikumpulkan oleh Stiennon et al. Percubaan juga menggunakan model SFT yang diperhalusi berdasarkan ringkasan artikel forum tulisan manusia 2 dan rangka kerja TRLX RLHF. Dataset keutamaan manusia ialah sampel yang dikumpul daripada model SFT yang berbeza tetapi terlatih serupa oleh Stiennon et al.
Akhir sekali, dalam perbualan satu pusingan, x ialah soalan manusia yang boleh menjadi apa-apa daripada astrofizik kepada nasihat perhubungan. Dasar mesti memberikan respons yang menarik dan membantu kepada pertanyaan pengguna; dasar mesti memberikan respons yang menarik dan membantu kepada pertanyaan pengguna, percubaan menggunakan set perbualan Anthropic Bermanfaat dan Tidak Memudaratkan, yang mengandungi 170 ribu perbualan antara pembantu manusia dan automatik. Setiap teks berakhir dengan sepasang respons yang dijana oleh model bahasa yang besar (walaupun tidak diketahui) dan label pilihan yang mewakili respons pilihan manusia. Dalam kes ini, tiada model SFT terlatih tersedia. Oleh itu, percubaan memperhalusi model bahasa luar hanya pada pelengkap pilihan untuk membentuk model SFT.
Para penyelidik menggunakan dua kaedah penilaian. Untuk menganalisis kecekapan setiap algoritma dalam mengoptimumkan matlamat memaksimumkan ganjaran yang terhad, eksperimen menilai setiap algoritma mengikut hadnya untuk mencapai ganjaran dan perbezaan KL daripada strategi rujukan dalam persekitaran penjanaan emosi terkawal. Percubaan boleh menggunakan fungsi ganjaran ground-truth (pengelas sentimen), jadi terikat ini boleh dikira. Tetapi sebenarnya, fungsi ganjaran kebenaran asas tidak diketahui. Oleh itu, kami menilai kadar kemenangan algoritma mengikut kadar kemenangan strategi garis dasar, dan menggunakan GPT-4 sebagai proksi untuk penilaian manusia terhadap kualiti ringkasan dan kegunaan tindak balas dalam ringkasan dan tetapan dialog pusingan tunggal. Untuk abstrak, eksperimen menggunakan abstrak rujukan dalam mesin ujian sebagai had untuk dialog, respons pilihan dalam set data ujian dipilih sebagai garis dasar. Walaupun penyelidikan sedia ada mencadangkan bahawa model bahasa boleh menjadi penilai automatik yang lebih baik daripada metrik sedia ada, para penyelidik menjalankan kajian manusia yang menunjukkan kebolehlaksanaan menggunakan GPT-4 untuk penilaian yang kuat dengan manusia secara amnya serupa atau lebih tinggi daripada perjanjian antara anotasi manusia.
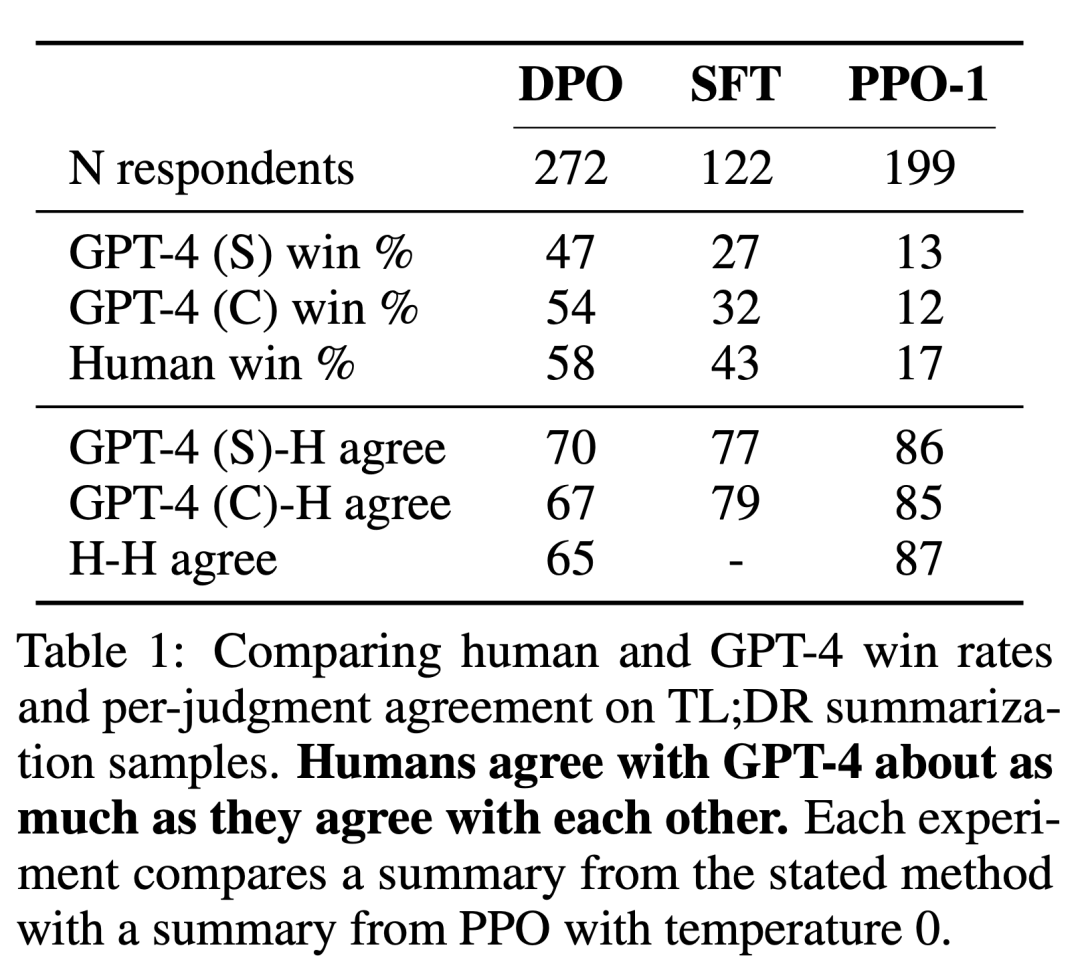
Selain DPO, penyelidik juga menilai beberapa model bahasa latihan sedia ada untuk mengekalkan konsistensi dengan keutamaan manusia yang konsisten. Pada yang paling mudah, percubaan meneroka gesaan sifar pukulan GPT-J pada tugas ringkasan dan gesaan 2 pukulan Pythia-2.8B pada tugas perbualan. Selain itu, eksperimen menilai model SFT dan Preferred-FT. Preferred-FT ialah model yang diperhalusi melalui pembelajaran terselia pada penyiapan y_w dipilih daripada model SFT (sentimen terkawal dan ringkasan) atau model bahasa umum (dialog satu pusingan). Satu lagi kaedah seliaan pseudo ialah Unlikelihood, yang hanya mengoptimumkan dasar untuk memaksimumkan kebarangkalian yang diberikan kepada y_w dan meminimumkan kebarangkalian yang diberikan kepada y_l. Percubaan menggunakan pekali pilihan α∈[0,1] pada "Ketidaksamaan". Mereka juga menganggap PPO, menggunakan fungsi ganjaran yang dipelajari daripada data keutamaan, dan PPO-GT. PPO-GT ialah oracle yang dipelajari daripada fungsi ganjaran kebenaran tanah yang tersedia dalam tetapan emosi terkawal. Dalam percubaan emosi mereka, pasukan menggunakan dua pelaksanaan PPO-GT, versi luar biasa dan versi diubah suai. Yang terakhir ini menormalkan ganjaran dan terus menala hiperparameter untuk meningkatkan prestasi (percubaan juga menggunakan pengubahsuaian ini apabila menjalankan PPO "Biasa" dengan ganjaran pembelajaran). Akhir sekali, kami mempertimbangkan garis dasar N yang terbaik, sampel respons N daripada model SFT (atau Preferred-FT dalam istilah perbualan), dan mengembalikan respons pemarkahan tertinggi berdasarkan fungsi ganjaran yang dipelajari daripada set data keutamaan. Pendekatan berprestasi tinggi ini memisahkan kualiti model ganjaran daripada pengoptimuman PPO, tetapi secara pengiraan tidak praktikal walaupun untuk N sederhana kerana ia memerlukan N pelengkapan sampel setiap pertanyaan pada masa ujian.
Rajah 2 menunjukkan ganjaran sempadan KL untuk pelbagai algoritma dalam tetapan emosi.
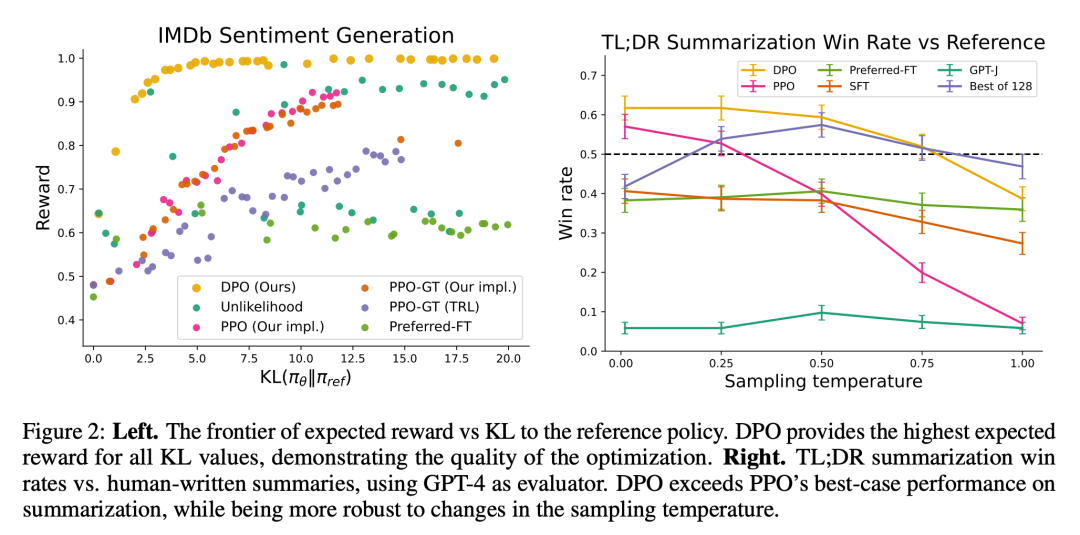
Rajah 3 menunjukkan bahawa DPO menumpu kepada prestasi optimumnya secara relatif cepat.
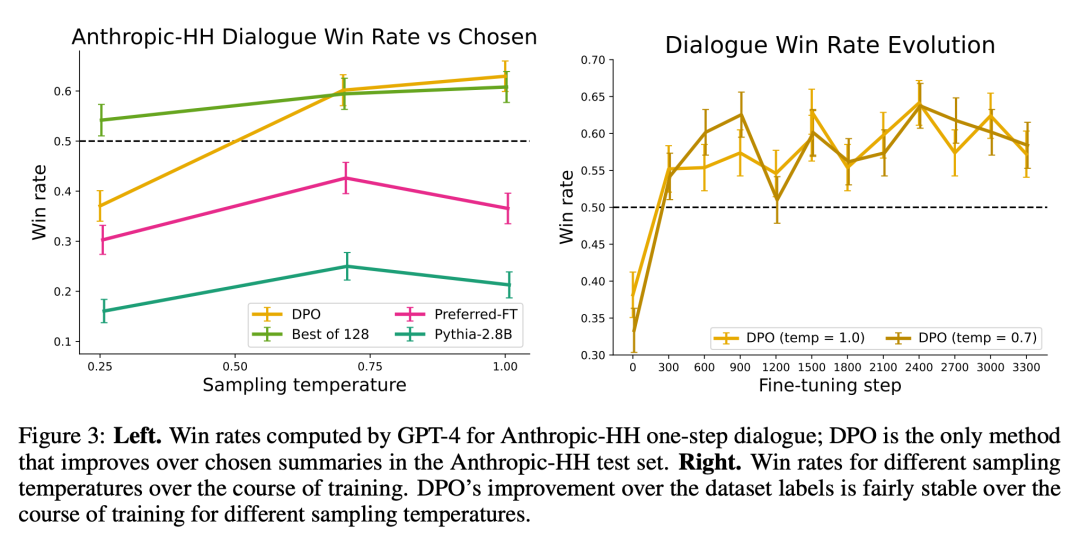
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI