
Rumah >Peranti teknologi >AI >Pasukan Sains China melancarkan 'Koleksi Rantaian Pemikiran' untuk menilai secara menyeluruh keupayaan penaakulan kompleks model besar
Pasukan Sains China melancarkan 'Koleksi Rantaian Pemikiran' untuk menilai secara menyeluruh keupayaan penaakulan kompleks model besar

- 王林ke hadapan
- 2023-06-05 13:22:29942semak imbas
Keupayaan model yang besar muncul. Lebih besar skala parameter, lebih baik?
Walau bagaimanapun, semakin ramai penyelidik mendakwa bahawa model yang lebih kecil daripada 10B juga boleh mencapai prestasi yang setanding dengan GPT-3.5.
Adakah begitu?
Dalam blog OpenAI yang mengeluarkan GPT-4, disebutkan:
Dalam perbualan santai, GPT-3.5 dan GPT-4 The perbezaan mungkin sangat halus. Perbezaan muncul apabila kerumitan tugasan mencapai ambang yang mencukupi—GPT-4 lebih dipercayai, lebih kreatif dan mampu mengendalikan arahan yang lebih bernuansa daripada GPT-3.5.
Pembangun Google juga membuat pemerhatian yang serupa tentang model PaLM Mereka mendapati bahawa keupayaan penaakulan rantaian pemikiran model besar adalah jauh lebih kuat daripada model kecil.
Pemerhatian ini menunjukkan bahawa keupayaan untuk melaksanakan tugas yang kompleks adalah kunci untuk menjelmakan keupayaan model besar.
Sama seperti pepatah lama, model dan pengaturcara adalah sama, "berhenti bercakap kosong dan tunjukkan kepada saya alasan".

Penyelidik dari University of Edinburgh, University of Washington dan Allen AI Institute percaya bahawa keupayaan penaakulan yang kompleks adalah kunci kepada model besar Asas untuk pembangunan selanjutnya ke arah alat yang lebih pintar pada masa hadapan.
Keupayaan ringkasan teks asas, pelaksanaan model besar sememangnya "pembunuhan ayam".
Penilaian kebolehan asas ini nampaknya agak tidak profesional untuk mengkaji pembangunan masa depan model besar.
Alamat kertas: https://arxiv.org/pdf/2305.17306.pdf
Syarikat manakah yang mempunyai model besar terbaik keupayaan penaakulan?
Itulah sebabnya penyelidik menyusun senarai tugas inferens yang kompleks, Hab Rantaian Pemikiran, untuk mengukur prestasi model dalam tugasan inferens yang mencabar.
Item ujian termasuk matematik (GSM8K)), sains (MATH, teorem QA), simbol (BBH), pengetahuan (MMLU, C-Eval) dan pengekodan (HumanEval).
Projek ujian atau set data ini semuanya bertujuan untuk keupayaan penaakulan yang kompleks bagi model besar. Tiada tugas mudah yang boleh dijawab oleh sesiapa sahaja.
Penyelidik masih menggunakan kaedah gesaan rantaian pemikiran (COT Prompt) untuk menilai keupayaan penaakulan model.
Untuk ujian keupayaan penaakulan, penyelidik hanya menggunakan prestasi jawapan akhir sebagai satu-satunya kriteria pengukuran, dan langkah penaakulan pertengahan tidak digunakan sebagai asas untuk penghakiman.
Seperti yang ditunjukkan dalam rajah di bawah, prestasi model arus perdana semasa pada tugas penaakulan yang berbeza.
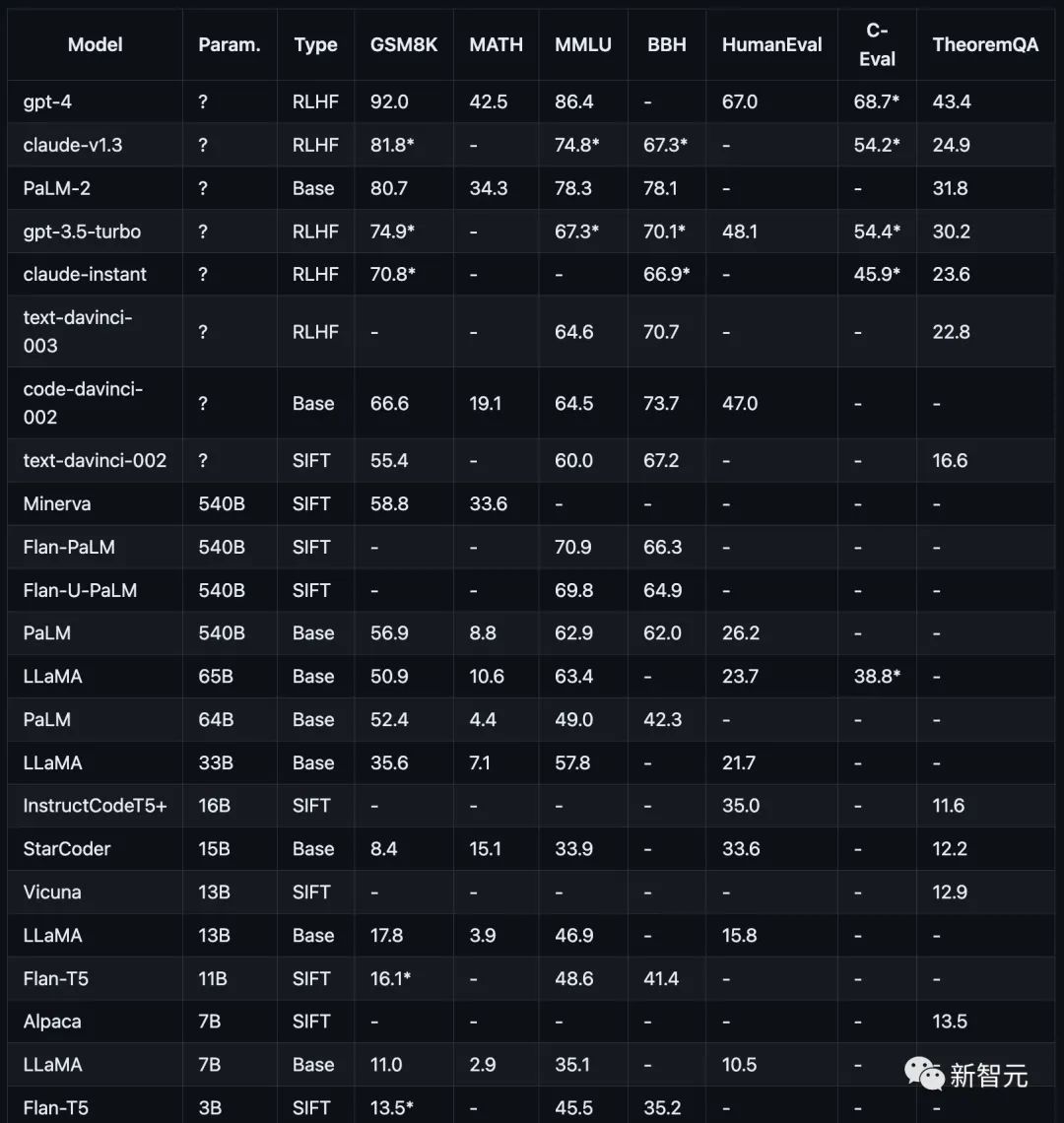
Keputusan ujian: Semakin besar model, semakin kuat keupayaan penaakulan
Penyelidikan penyelidik menumpukan pada model Popular semasa, termasuk keluarga model GPT, Claude, PaLM, LLaMA dan T5, khususnya:
OpenAI GPT termasuk GPT-4 (pada masa ini yang paling kuat), GPT3.5- Turbo (lebih pantas, tetapi kurang berkuasa), text-davinci-003, text-davinci-002, dan code-davinci-002 (versi penting sebelum Turbo).

Anthropic Claude termasuk claude-v1.3 (lebih perlahan tetapi lebih berkebolehan) dan claude-instant-v1. lebih pantas tetapi kurang berkemampuan).
Google PaLM, termasuk PaLM, PaLM-2 dan versi pelarasan arahannya (FLan-PaLM dan Flan-UPaLM), asas kukuh dan model pelarasan perintah.

Meta LLaMA, termasuk varian 7B, 13B, 33B dan 65B, model asas sumber terbuka yang penting.
GPT-4 dengan ketara mengatasi semua model lain pada GSM8K dan MMLU, manakala Claude adalah satu-satunya yang setanding dengan siri GPT.
Model yang lebih kecil seperti FlanT5 11B dan LLaMA 7B ketinggalan jauh.
Melalui eksperimen, penyelidik mendapati bahawa prestasi model biasanya berkaitan dengan skala, menunjukkan aliran linear logaritma secara kasar.
Model yang tidak mendedahkan skala parameter umumnya berprestasi lebih baik daripada model yang mendedahkan maklumat skala.
Keupayaan inferens LLaMA-65B hampir dengan ChatGPT
Selain itu, penyelidik menegaskan bahawa komuniti sumber terbuka mungkin masih perlu meneroka "parit" mengenai skala dan RLHF untuk penambahbaikan selanjutnya.
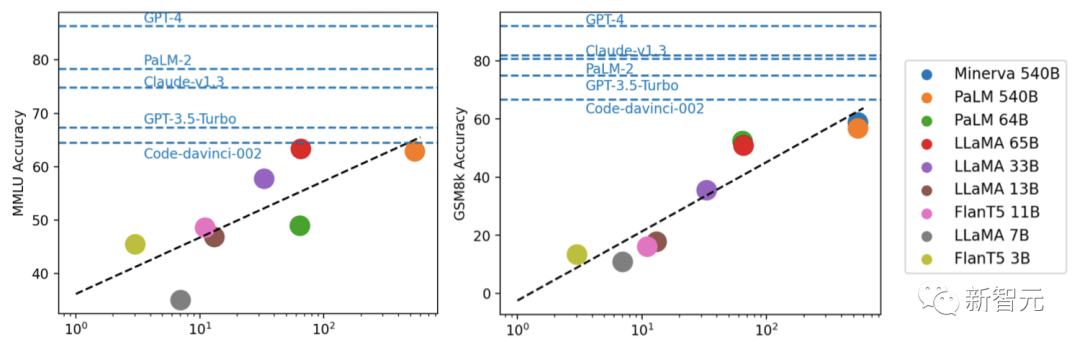
Fu Yao, pengarang pertama kertas kerja, membuat kesimpulan:
1 perbezaan yang jelas antara sumber terbuka dan jurang tertutup.
2. Kebanyakan model arus perdana kedudukan teratas ialah RLHF
3 , GPT -3.5 model asas
4. Berdasarkan perkara di atas, hala tuju yang paling menjanjikan ialah "Menjalankan RLHF pada LLaMA 65B".

Untuk projek ini, penulis menerangkan pengoptimuman selanjutnya pada masa hadapan:
Set data penaakulan yang dipilih dengan lebih teliti akan ditambah pada masa hadapan, terutamanya set data yang mengukur penaakulan akal dan teorem matematik.
dan keupayaan untuk memanggil API luaran.
Apa yang lebih penting ialah memasukkan lebih banyak model bahasa, seperti model penalaan halus arahan berdasarkan LLaMA, seperti Vicuna7 dan model sumber terbuka yang lain.
Anda juga boleh mengakses keupayaan model seperti PaLM-2 melalui API seperti Cohere 8.
Ringkasnya, penulis percaya bahawa projek ini boleh memainkan peranan yang besar sebagai kemudahan kebajikan awam untuk menilai dan membimbing pembangunan model bahasa besar sumber terbuka.
Atas ialah kandungan terperinci Pasukan Sains China melancarkan 'Koleksi Rantaian Pemikiran' untuk menilai secara menyeluruh keupayaan penaakulan kompleks model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI