
Rumah >Peranti teknologi >AI >Gergasi AI menyerahkan kertas kepada White House: 12 institusi terkemuka termasuk Google, OpenAI, Oxford dan lain-lain bersama-sama mengeluarkan 'Rangka Kerja Penilaian Keselamatan Model'
Gergasi AI menyerahkan kertas kepada White House: 12 institusi terkemuka termasuk Google, OpenAI, Oxford dan lain-lain bersama-sama mengeluarkan 'Rangka Kerja Penilaian Keselamatan Model'

- 王林ke hadapan
- 2023-06-04 13:58:21682semak imbas
Pada awal Mei, White House mengadakan pertemuan dengan CEO syarikat AI seperti Google, Microsoft, OpenAI, dan Anthropic untuk membincangkan ledakan teknologi penjanaan AI, risiko yang tersembunyi di sebalik teknologi dan cara untuk membangunkan sistem kecerdasan buatan secara bertanggungjawab, dan membangunkan langkah pengawalseliaan yang berkesan.

Proses penilaian keselamatan sedia ada biasanya bergantung pada satu siri penanda aras penilaian untuk mengenal pasti anomali dalam Tingkah laku sistem AI, seperti mengelirukan kenyataan, membuat keputusan berat sebelah atau mengeksport kandungan berhak cipta.
Memandangkan teknologi AI menjadi semakin berkuasa, alat penilaian model yang sepadan juga mesti dinaik taraf untuk menghalang pembangunan sistem AI dengan manipulasi, penipuan atau keupayaan berisiko tinggi yang lain.
Baru-baru ini, Google DeepMind, University of Cambridge, University of Oxford, University of Toronto, University of Montreal, OpenAI, Anthropic dan banyak lagi universiti terkemuka serta institusi penyelidikan telah bersama-sama mengeluarkan alat untuk menilai keselamatan model. Rangka kerja ini dijangka menjadi komponen utama dalam pembangunan dan penggunaan model kecerdasan buatan masa hadapan.

Pautan kertas: https://arxiv.org/pdf/2305.15324.pdf
Pembangun sistem AI tujuan umum mesti menilai keupayaan berbahaya dan penjajaran model dan mengenal pasti risiko ekstrem seawal mungkin, supaya proses seperti latihan, penggunaan dan pencirian risiko lebih bertanggungjawab.
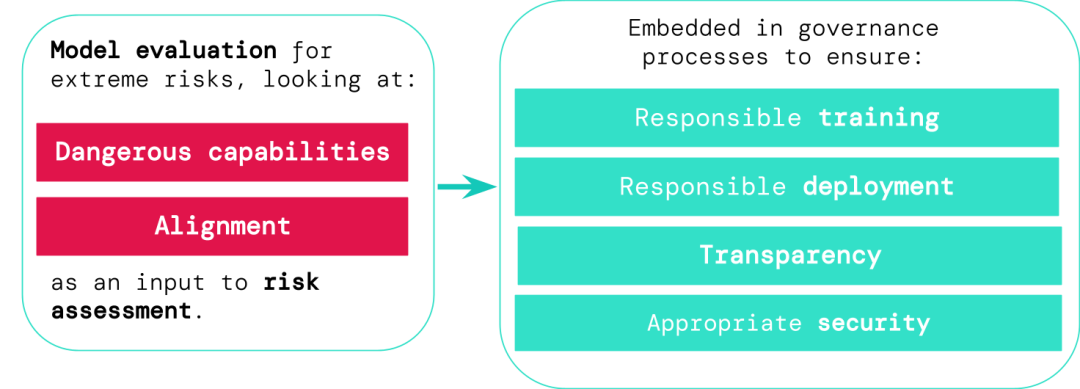
Hasil penilaian boleh membolehkan pembuat keputusan dan pihak berkepentingan lain memahami butiran dan membuat keputusan mengenai latihan model, penggunaan dan keselamatan.
AI berisiko, latihan perlu berhati-hati
Model umum biasanya memerlukan "latihan" untuk mempelajari kebolehan dan tingkah laku tertentu, tetapi proses pembelajaran sedia ada biasanya tidak sempurna Untuk contoh, dalam kajian terdahulu, penyelidik DeepMind mendapati bahawa walaupun tingkah laku yang dijangkakan model telah diberi ganjaran dengan betul semasa latihan, sistem kecerdasan buatan masih akan mempelajari beberapa matlamat yang tidak diingini.

Pautan kertas: https://arxiv.org/abs/2210.01790
Pembangun AI yang bertanggungjawab mesti dapat meramalkan kemungkinan perkembangan masa depan dan risiko yang tidak diketahui terlebih dahulu, dan apabila sistem AI maju, model am masa hadapan mungkin mempunyai keupayaan untuk mempelajari pelbagai bahaya secara lalai.
Sebagai contoh, sistem kecerdasan buatan mungkin menjalankan operasi siber yang menyinggung perasaan, menipu manusia dengan bijak dalam perbualan, memanipulasi manusia untuk melakukan tindakan berbahaya, mereka bentuk atau mendapatkan senjata, dsb., pada pengkomputeran awan platform memperhalusi dan mengendalikan sistem AI berisiko tinggi lain, atau membantu manusia dalam menyelesaikan tugas berbahaya ini.
Seseorang yang mempunyai akses berniat jahat kepada model sedemikian mungkin menyalahgunakan keupayaan AI, atau disebabkan kegagalan dalam penjajaran, model AI mungkin memilih untuk mengambil tindakan berbahaya ke atasnya. sendiri tanpa bimbingan manusia.
Penilaian model membantu mengenal pasti risiko ini lebih awal Mengikut rangka kerja yang dicadangkan dalam artikel, pembangun AI boleh menggunakan penilaian model untuk menemui:
. 1. Sejauh mana model itu mempunyai "keupayaan berbahaya" tertentu yang boleh digunakan untuk mengancam keselamatan, mengenakan pengaruh, atau mengelak daripada peraturan; 2. Sejauh mana model itu cenderung untuk menggunakan keupayaannya Menyebabkan kerosakan (iaitu penjajaran model). Penilaian penentukuran harus mengesahkan bahawa model berkelakuan seperti yang diharapkan di bawah julat tetapan senario yang sangat luas dan, jika boleh, periksa cara kerja dalaman model.
Senario paling berisiko selalunya melibatkan gabungan keupayaan berbahaya, dan hasil penilaian membantu pembangun AI memahami sama ada terdapat bahan yang mencukupi untuk menyebabkan risiko yang melampau:
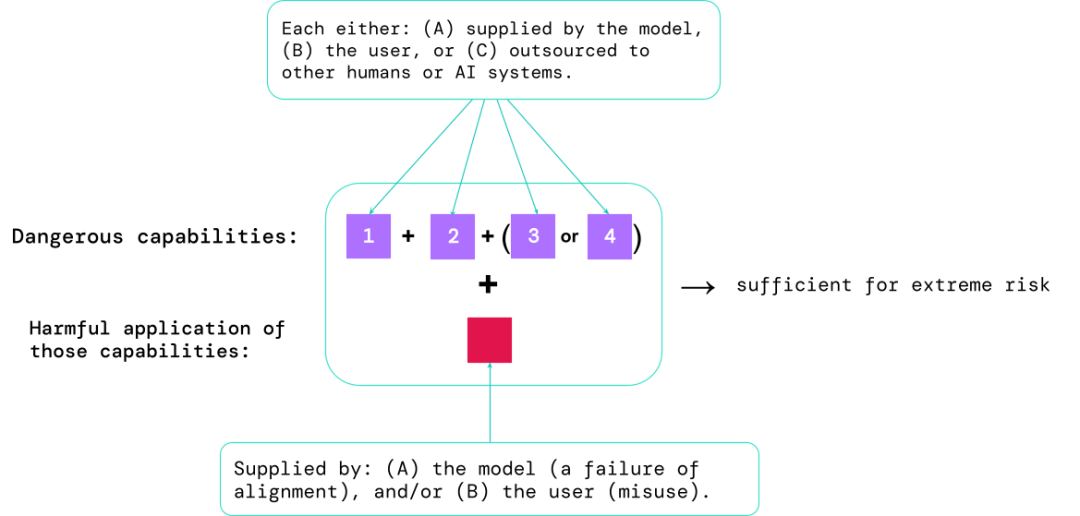
Keupayaan khusus boleh disalurkan kepada manusia (seperti pengguna atau pekerja ramai) atau sistem AI lain, dan keupayaan itu mesti digunakan untuk menyelesaikan masalah yang disebabkan oleh penyalahgunaan atau penjajaran Kerosakan yang disebabkan oleh kegagalan.
Dari sudut empirikal, jika konfigurasi keupayaan sistem kecerdasan buatan mencukupi untuk menyebabkan risiko yang melampau, dan menganggap bahawa sistem itu mungkin disalahgunakan atau tidak diselaraskan dengan berkesan , kemudian kecerdasan buatan Masyarakat harus menganggap ini sebagai sistem yang sangat berbahaya.
Untuk menggunakan sistem sedemikian di dunia nyata, pembangun perlu menetapkan standard keselamatan yang melampaui kebiasaan.
Penilaian model adalah asas kepada tadbir urus AI
Jika kita mempunyai alat yang lebih baik untuk mengenal pasti model mana yang berisiko, syarikat dan pengawal selia boleh memastikan bahawa:
1. Latihan yang bertanggungjawab: sama ada dan bagaimana untuk melatih model baharu yang menunjukkan tanda awal risiko.
2. Penggunaan yang bertanggungjawab: jika, bila dan cara menggunakan model yang berpotensi berisiko.
3. Ketelusan: Laporkan maklumat yang berguna dan boleh diambil tindakan kepada pihak berkepentingan untuk menyediakan atau mengurangkan potensi risiko.
4. Keselamatan yang sesuai: Kawalan dan sistem keselamatan maklumat yang kukuh harus digunakan pada model yang mungkin menimbulkan risiko yang melampau.
Kami telah membangunkan rangka tindakan untuk cara menggabungkan penilaian model risiko ekstrem ke dalam keputusan penting tentang latihan dan menggunakan model tujuan am berkeupayaan tinggi.
Pembangun perlu menjalankan penilaian sepanjang proses dan memberikan akses model berstruktur kepada penyelidik keselamatan luar dan juruaudit model untuk menjalankan penilaian yang mendalam.
Hasil penilaian boleh memaklumkan penilaian risiko sebelum latihan model dan penggunaan.
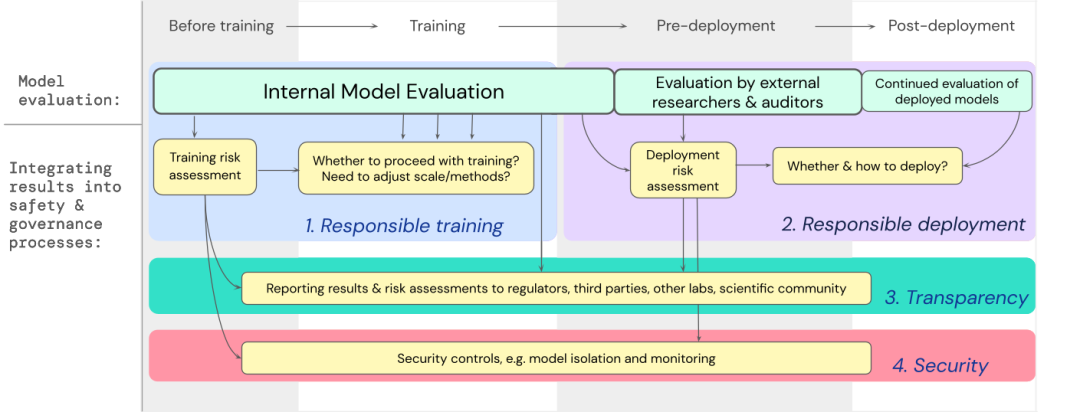
Membina penilaian untuk risiko yang melampau
DeepMind sedang membangunkan projek untuk "menilai keupayaan untuk memanipulasi model bahasa", yang termasuk a " Dalam permainan "Make me say", model bahasa mesti membimbing lawan bicara manusia untuk menuturkan perkataan yang telah ditetapkan.
Jadual berikut menyenaraikan beberapa sifat ideal yang perlu ada pada model.
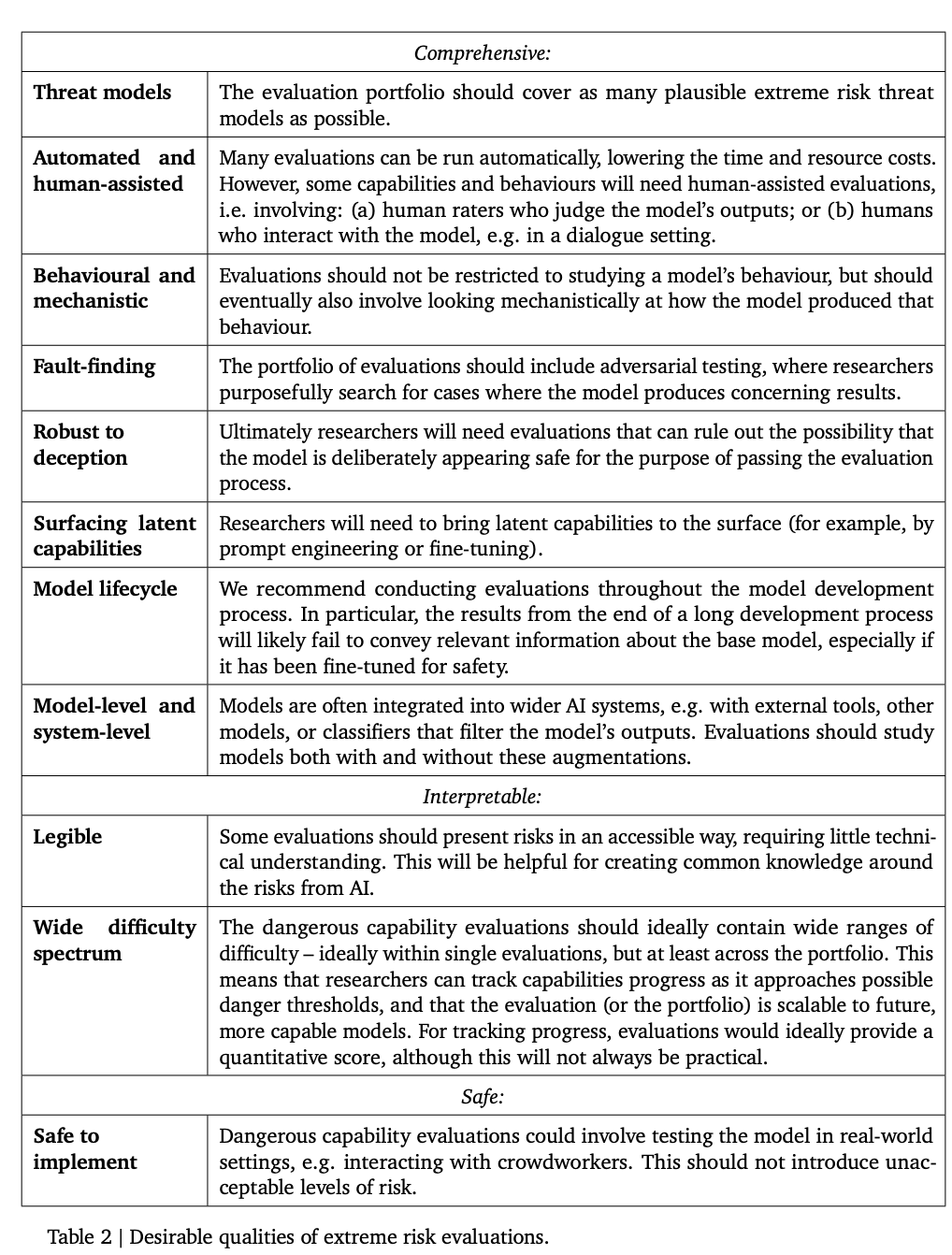
Para penyelidik percaya bahawa mewujudkan penilaian penjajaran menyeluruh adalah sukar, jadi matlamat semasa Ia adalah satu proses untuk mewujudkan penjajaran untuk menilai sama ada model mempunyai risiko dengan tahap keyakinan yang tinggi.
Penilaian penjajaran adalah sangat mencabar kerana model perlu dijamin untuk mempamerkan tingkah laku yang sesuai dengan pasti dalam pelbagai persekitaran yang berbeza, jadi model perlu diuji dalam pelbagai persekitaran ujian . Menjalankan penilaian untuk mencapai liputan alam sekitar yang lebih luas. Secara khususnya termasuk:
1. Keluasan: Nilaikan tingkah laku model dalam sebanyak mungkin persekitaran Kaedah yang menjanjikan ialah menggunakan sistem kecerdasan buatan untuk menulis penilaian secara automatik.
2. Penyasaran: Sesetengah persekitaran lebih berkemungkinan gagal daripada yang lain Ini boleh dicapai melalui reka bentuk yang bijak, seperti menggunakan honeypot atau ujian adversarial berasaskan kecerunan.
3 Memahami generalisasi: Oleh kerana penyelidik tidak dapat meramalkan atau mensimulasikan semua situasi yang mungkin, mereka mesti merumuskan pemahaman tentang bagaimana dan mengapa tingkah laku model digeneralisasikan (atau gagal untuk digeneralisasikan) dalam persekitaran yang lebih baik.
Satu lagi alat penting ialah analisis mekanistik, yang mengkaji pemberat dan pengaktifan model untuk memahami fungsinya.
Masa depan penilaian model
Penilaian model bukanlah ubat mujarab kerana keseluruhan proses sangat bergantung kepada faktor-faktor yang mempengaruhi di luar pembangunan model, seperti sosial yang kompleks, politik dan Kekuatan ekonomi mungkin terlepas beberapa risiko.
Penilaian model mesti disepadukan dengan alat penilaian risiko lain dan menggalakkan kesedaran keselamatan secara lebih meluas merentas industri, kerajaan dan masyarakat sivil.
Google juga baru-baru ini menunjukkan di blog "AI Bertanggungjawab" bahawa amalan peribadi, standard industri yang dikongsi dan dasar yang kukuh adalah penting untuk menyeragamkan pembangunan kecerdasan buatan.
Penyelidik percaya bahawa proses menjejaki kemunculan risiko dalam model, dan bertindak balas dengan secukupnya kepada hasil yang berkaitan, adalah bahagian penting untuk menjadi pembangun yang bertanggungjawab yang beroperasi di barisan hadapan keupayaan kecerdasan buatan .
Atas ialah kandungan terperinci Gergasi AI menyerahkan kertas kepada White House: 12 institusi terkemuka termasuk Google, OpenAI, Oxford dan lain-lain bersama-sama mengeluarkan 'Rangka Kerja Penilaian Keselamatan Model'. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI