
Rumah >pangkalan data >Redis >Bagaimana untuk menyelesaikan masalah berkaitan Redis
Bagaimana untuk menyelesaikan masalah berkaitan Redis

- PHPzke hadapan
- 2023-06-04 08:33:021288semak imbas
Mekanisme kegigihan Redis
Redis ialah pangkalan data dalam memori yang menyokong kegigihan Ia menyegerakkan data dalam ingatan ke fail cakera keras melalui mekanisme kegigihan untuk memastikan kegigihan data. Apabila Redis dimulakan semula, data boleh dipulihkan dengan memuat semula fail cakera keras ke dalam memori.
Pelaksanaan: Cipta proses anak fork() secara berasingan, salin data pangkalan data proses induk semasa ke memori proses anak, dan kemudian tulis pada fail sementara oleh proses anak Selepas proses kegigihan selesai , gunakan sementara ini Fail menggantikan fail syot kilat terakhir, kemudian proses anak keluar dan ingatan dilepaskan.
RDB ialah kaedah kegigihan lalai Redis. Mengikut strategi tempoh masa tertentu, data memori disimpan ke fail binari cakera keras dalam bentuk syot kilat. Iaitu, storan syot kilat syot kilat, fail data terjana yang sepadan ialah dump.rdb, dan kitaran syot kilat ditakrifkan melalui parameter simpan dalam fail konfigurasi. (Syot kilat boleh menjadi salinan data yang diwakilinya, atau salinan data.)
AOF: Redis akan menambahkan setiap arahan tulis yang diterima pada Pada akhir fail, ia adalah serupa dengan binlog MySQL. Apabila Redis dimulakan semula, kandungan keseluruhan pangkalan data akan dibina semula dalam ingatan dengan melaksanakan semula arahan tulis yang disimpan dalam fail.
Apabila kedua-dua kaedah didayakan pada masa yang sama, pemulihan data Redis akan memberi keutamaan kepada pemulihan AOF.
Cache avalanche, cache penetrasi, cache preheating, cache update, cache degradation and other issues
Cache avalancheKami boleh memahaminya sebagai: disebabkan kegagalan cache asal , semasa tempoh cache baharu belum tamat tempoh
(contohnya: kami menggunakan masa tamat tempoh yang sama semasa menetapkan cache, dan kawasan besar cache tamat tempoh pada masa yang sama), semua permintaan yang sepatutnya telah mengakses cache pergi untuk menanyakan pangkalan data, dan pangkalan data Ini menyebabkan tekanan besar pada CPU dan memori, dan dalam kes yang teruk boleh menyebabkan masa henti pangkalan data. Ini mewujudkan satu siri tindak balas berantai, menyebabkan keseluruhan sistem runtuh.
Penyelesaian:
Kebanyakan pereka bentuk sistem mempertimbangkan untuk menggunakan penguncian (penyelesaian yang paling biasa) atau baris gilir untuk memastikan bahawa tidak akan terdapat sejumlah besar utas membaca dan menulis ke pangkalan data pada satu masa , dengan itu mengelakkan sejumlah besar permintaan serentak daripada jatuh pada sistem storan asas semasa kegagalan. Satu lagi penyelesaian mudah ialah menyebarkan masa tamat tempoh cache.
2. Penembusan cache
Penembusan cache bermakna pengguna menanyakan data yang tiada dalam pangkalan data dan secara semula jadi tidak akan berada dalam cache. Ini akan menyebabkan pengguna tidak menemuinya dalam cache semasa membuat pertanyaan, dan perlu pergi ke pangkalan data untuk bertanya semula setiap kali, dan kemudian kembali kosong (bersamaan dengan dua pertanyaan tidak berguna). Dengan cara ini, permintaan memintas cache dan terus menyemak pangkalan data Ini juga merupakan isu kadar hit cache yang sering dibangkitkan.
Penyelesaian;
Yang paling biasa ialah menggunakan Bloom filter untuk mencincang semua data yang mungkin menjadi bitmap yang cukup besar, Data tertentu yang tidak wujud akan dipintas oleh peta bit ini, dengan itu mengelakkan tekanan pertanyaan pada sistem storan asas.
Terdapat juga kaedah yang lebih mudah dan kasar Jika data yang dikembalikan oleh pertanyaan kosong (sama ada data tidak wujud atau sistem gagal), kami masih akan menyimpan hasil kosong, tetapi. ia Masa tamat tempoh akan menjadi sangat singkat, tidak lebih daripada lima minit paling banyak. Nilai lalai yang ditetapkan secara langsung disimpan dalam cache, supaya nilai diperoleh kali kedua dalam cache tanpa terus mengakses pangkalan data Kaedah ini adalah yang paling mudah dan paling kasar.
Pemacu keras 5TB penuh dengan data Sila tulis algoritma untuk menyahduplikasi data. Bagaimana untuk menyelesaikan masalah ini jika data bersaiz 32bit? Bagaimana jika ia adalah 64bit?
Penggunaan ruang muktamad ialah Bitmap dan Penapis Bloom.
Bitmap: Yang biasa ialah jadual hash
Kelemahannya ialah Bitmap hanya boleh merekodkan 1 bit maklumat untuk setiap elemen Jika anda ingin melengkapkan fungsi tambahan, saya khuatir anda hanya boleh melakukannya dengan mengorbankan lebih banyak ruang dan masa.
Penapis Bloom (disyorkan)
Ia memperkenalkan k(k>1)k(k>1) fungsi cincang bebas untuk memastikan bahawa dalam ruang tertentu, ralat Di bawah kadar penghakiman, proses pertimbangan berat unsur selesai.
Kelebihannya ialah kecekapan ruang dan masa pertanyaan jauh lebih tinggi daripada algoritma umum Kelemahannya ialah ia mempunyai kadar salah pengecaman dan kesukaran pemadaman.
Idea teras algoritma Bloom-Filter ialah menggunakan berbilang fungsi Hash yang berbeza untuk menyelesaikan "konflik".
Hash mempunyai masalah konflik (perlanggaran) Nilai dua URL yang diperoleh dengan menggunakan Hash yang sama mungkin sama. Untuk mengurangkan konflik, kita boleh memperkenalkan beberapa lagi cincangan Jika kita menyimpulkan bahawa elemen tiada dalam set melalui salah satu nilai cincang, maka elemen itu pastinya tiada dalam set. Hanya apabila semua fungsi Hash memberitahu kita bahawa elemen itu berada dalam set, kita boleh memastikan bahawa elemen itu wujud dalam set. Ini adalah idea asas Bloom-Filter.
Bloom-Filter biasanya digunakan untuk menentukan sama ada unsur wujud dalam set data yang besar.
Ditambah dengan peringatan: Perbezaan antara penembusan cache dan pecahan cache
Pecahan cache: merujuk kepada kunci yang sangat panas dan konkurensi besar tertumpu pada mengakses ini kunci. Apabila kunci tamat tempoh, akses serentak besar yang berterusan akan menembusi cache dan meminta pangkalan data secara langsung.
Penyelesaian; Sebelum mengakses kekunci, gunakan SETNX (tetapkan jika tidak wujud) untuk menetapkan kunci jangka pendek lain untuk mengunci akses kepada kunci semasa, dan kemudian padamkan kunci jangka pendek selepas akses.
3. Pemanasan awal cache
Pemanasan awal cache sepatutnya menjadi konsep yang agak biasa data cache dimuatkan terus ke dalam sistem cache. Dengan cara ini, anda boleh mengelakkan masalah menanyakan pangkalan data terlebih dahulu dan kemudian menyimpan data apabila pengguna memintanya! Pengguna terus bertanya data cache yang telah dipanaskan!
Penyelesaian:
1. Terus tulis halaman penyegaran cache dan lakukan secara manual apabila pergi dalam talian
2. Jumlah data tidak besar dan boleh dimuatkan secara automatik apabila projek bermula; . Masa Refresh cache;
Kemas kini cache Sebagai tambahan kepada strategi pembatalan cache yang disertakan dengan pelayan cache (Redis mempunyai 6 strategi untuk dipilih secara lalai), kami juga boleh menggunakan Terdapat dua strategi biasa untuk menyesuaikan penghapusan cache berdasarkan keperluan perniagaan tertentu:
(1) Bersihkan cache yang telah tamat tempoh dengan kerap
(2) Apabila pengguna membuat permintaan, tentukan cache yang digunakan untuk permintaan ini . Sama ada cache tamat tempoh, jika ia tamat tempoh, pergi ke sistem asas untuk mendapatkan data baharu dan mengemas kini cache.
Kedua-duanya mempunyai kelebihan dan kekurangan masing-masing. Kelemahan yang pertama adalah lebih menyusahkan untuk mengekalkan sejumlah besar kunci cache dinilai sebagai tidak sah, dan logiknya agak rumit! Penyelesaian yang mana untuk digunakan secara khusus boleh ditimbang berdasarkan senario aplikasi anda sendiri.
5.
Turun taraf cache Apabila bilangan lawatan meningkat dengan mendadak, masalah perkhidmatan berlaku (seperti masa tindak balas yang perlahan atau tiada respons), atau perkhidmatan bukan teras menjejaskan prestasi proses teras, ia masih perlu untuk memastikan perkhidmatan Masih tersedia, walaupun dengan perkhidmatan terjejas. Sistem boleh menurunkan taraf secara automatik berdasarkan beberapa data utama, atau mengkonfigurasi suis untuk mencapai penurunan taraf manual.
Matlamat utama penurunan taraf adalah untuk memastikan perkhidmatan teras tersedia, walaupun ia rugi. Dan sesetengah perkhidmatan tidak boleh diturunkan taraf (seperti menambah ke troli beli-belah, daftar keluar).
Tetapkan pelan berdasarkan tahap log rujukan:
(1) Umum: Contohnya, sesetengah perkhidmatan kadang-kadang tamat masa disebabkan kegelisahan rangkaian atau perkhidmatan sedang dalam talian, dan boleh diturunkan secara automatik
(; 2) Amaran: Sesetengah perkhidmatan mungkin tamat dalam tempoh masa Jika kadar kejayaan berubah-ubah (seperti antara 95~100%), anda boleh menurunkan taraf atau menurunkan taraf secara automatik, dan menghantar penggera
(3) Ralat : Sebagai contoh, kadar ketersediaan adalah lebih rendah daripada 90%, atau kumpulan sambungan pangkalan data telah habis , atau bilangan lawatan tiba-tiba melonjak ke ambang maksimum yang boleh ditahan oleh sistem Pada masa ini, ia boleh diturunkan secara automatik atau diturunkan secara manual mengikut situasi;
(4) Ralat serius: Contohnya, data adalah salah kerana sebab-sebab khas, dan penurunan taraf manual kecemasan diperlukan pada masa ini.
Apakah itu data panas dan data sejuk
Data panas hanya berharga apabila dicache
Untuk data sejuk, kebanyakan data mungkin telah diperah daripada ingatan sebelum ia diakses semula, yang bukan sahaja mengambil ingatan, dan tidak banyak nilai. Untuk data yang kerap diubah suai, pertimbangkan untuk menggunakan caching bergantung pada situasi
Untuk dua contoh di atas, senarai panjang umur dan maklumat navigasi kedua-duanya mempunyai ciri, iaitu kekerapan pengubahsuaian maklumat tidak tinggi dan bacaan biasanya sangat tinggi.
Untuk data hangat, seperti salah satu produk IM kami, modul ucapan hari lahir dan senarai hari lahir pada hari itu, cache boleh dibaca ratusan ribu kali. Untuk contoh lain, dalam produk navigasi, kami menyimpan maklumat navigasi dan mungkin membacanya berjuta-juta kali pada masa hadapan.
**Cache hanya masuk akal jika data dibaca sekurang-kurangnya dua kali sebelum dikemas kini. Ini adalah strategi paling asas Jika cache gagal sebelum ia berkuat kuasa, ia tidak akan mempunyai banyak nilai.
Bagaimana pula dengan senario di mana cache tidak wujud, kekerapan pengubahsuaian adalah sangat tinggi, tetapi caching perlu dipertimbangkan? mempunyai! Sebagai contoh, antara muka bacaan ini memberi banyak tekanan pada pangkalan data, tetapi ia juga merupakan data panas Pada masa ini, anda perlu mempertimbangkan kaedah caching untuk mengurangkan tekanan pada pangkalan data, seperti bilangan suka, koleksi dan. saham salah satu produk pembantu kami Ini adalah data panas yang sangat tipikal, tetapi pada masa ini, data perlu disimpan ke cache Redis secara serentak untuk mengurangkan tekanan pada pangkalan data.
Apakah perbezaan antara Memcache dan Redis?
1). Kaedah storan Memecache menyimpan semua data dalam memori Ia akan ditutup selepas kegagalan kuasa Data tidak boleh melebihi saiz memori. Sebahagian daripada Redis disimpan pada cakera keras, dan redis boleh mengekalkan datanya
2). struktur data seperti set, zset, cincang dll.
3). Model asas yang digunakan adalah berbeza, kaedah pelaksanaan asas dan protokol aplikasi untuk komunikasi dengan pelanggan adalah berbeza. Redis secara langsung membina mekanisme VMnya sendiri, kerana jika sistem umum memanggil fungsi sistem, ia akan membuang masa tertentu untuk bergerak dan meminta.
4). Saiz nilai nilai adalah berbeza: Redis boleh mencapai maksimum 512M hanya 1mb;
5) Kelajuan redis jauh lebih pantas daripada memcached
6) Redis menyokong sandaran data, iaitu sandaran data dalam mod tuan-hamba.
Mengapa redis satu benang begitu pantas
(1) Operasi memori tulen
(2) Operasi satu benang, mengelakkan penukaran konteks yang kerap
(3) Menggunakan bukan- Menyekat mekanisme pemultipleksan I/O
Jenis data Redis, dan senario penggunaan setiap jenis data
Jawapan: Terdapat lima jenis kesemuanya
(1) Rentetan
Ini Sebenarnya , tiada apa-apa untuk dikatakan Untuk operasi set/dapat yang paling biasa, nilai boleh sama ada String atau nombor. Secara amnya, beberapa fungsi pengiraan kompleks dicache.
(2) cincang
Nilai di sini menyimpan objek berstruktur dan lebih mudah untuk mengendalikan medan tertentu di dalamnya. Apabila blogger melakukan log masuk tunggal, mereka menggunakan struktur data ini untuk menyimpan maklumat pengguna, menggunakan cookieId sebagai kunci dan menetapkan 30 minit sebagai masa tamat tempoh cache, yang boleh mensimulasikan kesan seperti sesi dengan baik.
(3) senarai
Menggunakan struktur data Senarai, anda boleh melaksanakan fungsi baris gilir mesej ringkas. Perkara lain ialah anda boleh menggunakan perintah lrange untuk melaksanakan fungsi paging berasaskan redis, yang mempunyai prestasi cemerlang dan pengalaman pengguna yang baik. Saya juga menggunakan senario yang sangat sesuai—mendapatkan maklumat pasaran. Ia juga merupakan adegan pengeluar dan pengguna. LIST boleh melaksanakan prinsip beratur dan keluar dahulu dengan baik.
(4) set
Kerana set ialah koleksi nilai unik. Oleh itu, fungsi deduplikasi global boleh dilaksanakan. Mengapa tidak menggunakan Set yang disertakan dengan JVM untuk penyahduplikasian? Kerana sistem kami biasanya digunakan dalam kelompok, adalah menyusahkan untuk menggunakan Set yang disertakan dengan JVM Adakah terlalu menyusahkan untuk menyediakan perkhidmatan awam hanya untuk melakukan penduaan global?
Selain itu, dengan menggunakan operasi seperti persilangan, kesatuan dan perbezaan, anda boleh mengira pilihan biasa, semua pilihan dan pilihan unik anda sendiri.
(5) set diisih
set diisih mempunyai skor parameter berat tambahan, dan elemen dalam set boleh disusun mengikut skor. Anda boleh membuat aplikasi ranking dan mengambil operasi TOP N.
Redis struktur dalaman
dikt pada asasnya untuk menyelesaikan masalah carian (Searching) dalam algoritma Ia adalah struktur data yang digunakan untuk mengekalkan hubungan pemetaan antara kunci dan Nilai peta atau kamus dalam banyak bahasa adalah serupa. Pada asasnya, ia adalah untuk menyelesaikan masalah carian dalam algoritma (Searching)
sds sds bersamaan dengan char * Ia boleh menyimpan sebarang data binari dan tidak boleh diwakili oleh aksara seperti bahasa C rentetan.
Strategi tamat tempoh Redis dan mekanisme penghapusan ingatan
Redis mengamalkan strategi pemadaman biasa + pemadaman malas.
Mengapa tidak menggunakan strategi pemadaman berjadual
Pemadaman berjadual menggunakan pemasa untuk memantau kunci, dan ia akan dipadamkan secara automatik apabila ia tamat tempoh. Walaupun memori dikeluarkan dalam masa, ia menggunakan banyak sumber CPU. Di bawah permintaan serentak yang besar, CPU perlu menggunakan masa untuk memproses permintaan dan bukannya memadamkan kunci, jadi strategi ini tidak diguna pakai
Bagaimanakah pemadaman biasa + pemadaman malas berfungsi
Padam dengan kerap. Redis menyemak setiap 100ms secara lalai untuk melihat sama ada terdapat kunci tamat tempoh Jika terdapat kunci tamat tempoh, padamkannya. Perlu diingat bahawa redis tidak menyemak semua kekunci setiap 100ms, tetapi memilihnya secara rawak untuk pemeriksaan (jika semua kekunci disemak setiap 100ms, bukankah redis akan tersekat)? Oleh itu, jika anda hanya menggunakan strategi pemadaman biasa, banyak kunci tidak akan dipadamkan pada masa itu.
Jadi, pemadaman malas berguna. Maksudnya, apabila anda mendapat kunci, redis akan menyemak sama ada kunci telah tamat tempoh jika ia mempunyai masa tamat tempoh yang ditetapkan? Jika ia tamat tempoh, ia akan dipadamkan pada masa ini.
Adakah tiada masalah lain jika anda menggunakan pemadaman biasa + pemadaman malas
Tidak, jika pemadaman biasa tidak memadamkan kunci? Kemudian anda tidak meminta kunci serta-merta, yang bermaksud pemadaman malas tidak berkuat kuasa. Dengan cara ini, ingatan redis akan menjadi lebih tinggi dan lebih tinggi. Kemudian mekanisme penghapusan ingatan harus diguna pakai.
Terdapat baris konfigurasi dalam redis.conf
maxmemory-policy volatile-lru
Konfigurasi ini dikonfigurasikan dengan strategi penghapusan memori (apa, anda belum mengkonfigurasinya? Renungkan diri anda)
volatile- lru: Pilih data yang paling kurang digunakan baru-baru ini daripada set data (server.db[i].expires) dengan masa tamat tempoh ditetapkan untuk menghapuskan
volatile-ttl: Pilih data yang paling kurang digunakan baru-baru ini daripada set data dengan set masa tamat. set data (server.db[i].luput) dengan set masa tamat tempoh Pilih penyingkiran data secara rawak dalam
allkeys-lru: Pilih data yang paling kurang digunakan baru-baru ini daripada set data (server.db [i].dict) untuk menghapuskan
allkeys-random: Sewenang-wenangnya pilih data untuk dihapuskan daripada set data (server.db[i].dict)
no-enviction (pengusiran): melarang pengusiran data, operasi tulis baharu akan melaporkan ralat
ps : Jika kunci tamat tempoh tidak ditetapkan dan prasyarat tidak dipenuhi maka kelakuan volatile-lru, volatile-random dan volatile -ttl strategi pada asasnya sama seperti noeviction (tiada pemadaman). Mengapakah Redis berbenang tunggal
1 ) Kebanyakan permintaan adalah operasi memori tulen (sangat pantas) 2) Berbenang tunggal, mengelakkan suis konteks dan keadaan perlumbaan yang tidak perlu
3) Kelebihan IO tidak menyekat: 1. Cepat kerana data Wujud dalam ingatan, serupa dengan HashMap, kelebihan HashMap ialah kerumitan masa carian dan operasi ialah O(1)
2. Menyokong jenis data yang kaya, menyokong rentetan, senarai, set, set diisih, hash
3 .Urus niaga dan operasi sokongan semuanya bersifat atom Apa yang dipanggil atomicity bermakna semua perubahan pada data sama ada dilaksanakan atau tidak dilaksanakan
4. Ciri yang kaya: boleh digunakan untuk caching, pemesejan dan tetapan. masa tamat tempoh mengikut kunci. Selepas tamat tempoh Akan dipadamkan secara automatik Cara menyelesaikan masalah persaingan kunci serentak redis
Terdapat berbilang subsistem menetapkan kunci pada masa yang sama. Apakah yang perlu kita perhatikan pada masa ini? Ia tidak disyorkan untuk menggunakan mekanisme transaksi redis. Oleh kerana persekitaran pengeluaran kami pada asasnya ialah persekitaran kluster redis, operasi perkongsian data dilakukan. Apabila anda mempunyai berbilang operasi utama yang terlibat dalam transaksi, berbilang kunci ini tidak semestinya disimpan pada pelayan semula yang sama. Oleh itu, mekanisme transaksi redis sangat tidak berguna.
(1) Jika anda mengendalikan kunci ini, pesanan tidak diperlukan: sediakan kunci yang diedarkan, semua orang ambil kunci, dan lakukan sahaja operasi yang ditetapkan selepas mengambil kunci
(3) Menggunakan baris gilir untuk menukar kaedah yang ditetapkan kepada akses bersiri juga boleh membolehkan redis menghadapi konkurensi yang tinggi Jika ketekalan kekunci membaca dan menulis dipastikan
Semua operasi pada redis adalah atom dan selamat untuk benang operasi, anda tidak perlu mempertimbangkan isu konkurensi Redis telah pun mengendalikan isu konkurensi untuk anda secara dalaman.
Apakah yang perlu dilakukan dengan penyelesaian kluster Redis? Apakah rancangannya?
1. twemproxy, konsep umum ialah ia serupa dengan kaedah proksi Apabila digunakan, tempat di mana redis perlu disambungkan kepada twemproxy Ia akan menerima permintaan sebagai proksi dan menggunakan a algoritma hash yang konsisten , pindahkan permintaan kepada redis tertentu, dan kembalikan hasilnya kepada twemproxy.
Kelemahan: Disebabkan tekanan instance port tunggal twemproxy sendiri, selepas menggunakan pencincangan yang konsisten, nilai yang dikira berubah apabila bilangan nod redis berubah dan data tidak boleh dialihkan secara automatik ke nod baharu.
2.codis, penyelesaian kluster yang paling biasa digunakan pada masa ini, pada asasnya mempunyai kesan yang sama seperti twemproxy, tetapi ia menyokong pemulihan data nod lama kepada nod cincang baharu apabila bilangan nod berubah
3. Ciri kluster yang disertakan dengan kluster redis3.0 ialah algoritma pengedarannya bukan pencincangan yang konsisten, tetapi konsep slot cincang, dan ia menyokong nod hamba tetapan nod. Lihat dokumentasi rasmi untuk butiran.
Sudahkah anda cuba menggunakan redis pada berbilang mesin? Bagaimana untuk memastikan konsistensi data?
Replikasi tuan-hamba, pengasingan membaca dan menulis
Satu adalah pangkalan data induk (tuan) dan satu lagi pangkalan data hamba (hamba) Pangkalan data induk boleh melakukan operasi baca dan tulis Apabila a operasi tulis berlaku, data akan dipindahkan secara automatik ke pangkalan data hamba Segerakkan ke pangkalan data hamba, dan pangkalan data hamba biasanya baca sahaja dan menerima data yang disegerakkan daripada pangkalan data induk boleh mempunyai beberapa pangkalan data hamba pangkalan data hamba hanya boleh mempunyai satu pangkalan data induk.
Cara mengendalikan sebilangan besar permintaan
Redis ialah program satu utas, yang bermaksud bahawa ia hanya boleh mengendalikan satu permintaan pelanggan pada masa yang sama
redis dimultiplekskan IO Gunakan (pilih, epoll, kqueue, pelaksanaan berbeza mengikut platform berbeza) untuk mengendalikan berbilang permintaan pelanggan
Selesaikan semula masalah dan penyelesaian prestasi biasa?
(1) Master sebaiknya tidak melakukan apa-apa kerja berterusan, seperti petikan memori RDB dan fail log AOF
(2) Jika data penting, Slave mendayakan data sandaran AOF dan dasar ditetapkan kepada setiap Segerakkan sekali setiap saat
(3) Untuk kelajuan replikasi tuan-hamba dan kestabilan sambungan, sebaiknya Tuan dan Hamba berada dalam LAN yang sama
(4) Cuba untuk elakkan menambah perpustakaan hamba pada perpustakaan induk yang berada di bawah tekanan besar
(5) Jangan gunakan struktur graf untuk replikasi induk-hamba Adalah lebih stabil untuk menggunakan struktur senarai terpaut sehala, iaitu: Master < ;- Slave1 Slave3…
penjelasan Di bawah model benang Redis
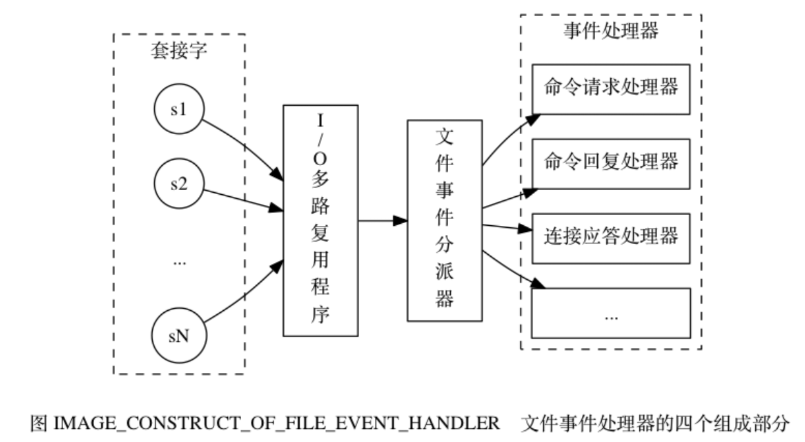
pengendali acara fail termasuk soket, pemultipleks I/O, penghantar acara fail (penghantar), dan pengendali acara . Gunakan pemultipleks I/O untuk mendengar berbilang soket pada masa yang sama dan mengaitkan pengendali acara yang berbeza dengan soket berdasarkan tugas yang sedang mereka lakukan. Apabila soket yang dipantau bersedia untuk melakukan operasi seperti tindak balas sambungan (terima), baca (baca), tulis (tulis), tutup (tutup), dan lain-lain, acara fail yang sepadan dengan operasi akan dihasilkan Pada masa ini, fail Pengendali acara akan memanggil pengendali acara yang dikaitkan dengan soket sebelum ini untuk mengendalikan acara ini.
Pemultipleks I/O bertanggungjawab untuk mendengar berbilang soket dan menghantar soket tersebut yang menjana acara kepada penghantar acara fail.
Prinsip kerja:
1) Pemultipleks I/O bertanggungjawab untuk mendengar berbilang soket dan menghantar soket tersebut yang menjana peristiwa kepada penghantar acara fail.
Walaupun berbilang peristiwa fail mungkin berlaku serentak, pemultipleks I/O akan sentiasa memasukkan semua soket penjana peristiwa ke dalam baris gilir, dan kemudian melalui baris gilir ini untuk membuat pesanan (Sequentially), serentak (synchronously), satu soket pada satu masa dihantar ke penghantar acara fail: Selepas peristiwa yang dijana oleh soket sebelumnya diproses (soket dikaitkan dengan peristiwa) pengendali acara dilaksanakan), pemultipleks I/O akan terus menghantar soket seterusnya kepada penghantar acara fail . Jika soket boleh dibaca dan boleh ditulis, maka pelayan akan membaca soket terlebih dahulu dan kemudian menulis soket.
Mengapa operasi Redis bersifat atom?
Untuk Redis, keatomisan perintah bermakna operasi tidak boleh dibahagikan dan operasi itu sama ada dilaksanakan atau tidak.
Sebab mengapa operasi Redis adalah atom adalah kerana Redis adalah satu benang.
Semua API yang disediakan oleh Redis sendiri adalah operasi atom dalam Redis sebenarnya memastikan keatoman operasi kelompok.
Adakah berbilang arahan juga beratom secara serentak?
Tidak semestinya, tukar dapatkan dan tetapkan kepada operasi arahan tunggal, incr. Gunakan transaksi Redis, atau gunakan Redis+Lua==.
Transaksi Redis
Fungsi transaksi Redis dilaksanakan melalui empat primitif MULTI, EXEC, DISCARD dan WATCH
Redis akan menyerikan semua arahan dalam transaksi dan kemudian melaksanakannya mengikut urutan.
1. redis tidak menyokong rollback "Redis tidak membuat rollback apabila transaksi gagal, tetapi terus melaksanakan perintah yang tinggal", jadi dalaman Redis boleh kekal mudah dan pantas.
2. Jika ralat berlaku dalam perintah dalam transaksi, maka semua arahan tidak akan dilaksanakan
3. Jika ralat berlaku dalam transaksi Ralat menjalankan, kemudian perintah yang betul akan dilaksanakan.
Nota: pembuangan redis hanya menamatkan urus niaga ini, dan kesan perintah yang betul masih wujud
1) Perintah MULTI digunakan untuk memulakan urus niaga, dan ia sentiasa kembali OK. Selepas MULTI dilaksanakan, pelanggan boleh terus menghantar sebarang bilangan arahan kepada pelayan Arahan ini tidak akan dilaksanakan serta-merta, tetapi akan diletakkan dalam barisan Apabila perintah EXEC dipanggil, semua arahan dalam baris gilir akan dilaksanakan .
2) EXEC: Laksanakan arahan dalam semua blok transaksi. Mengembalikan nilai pulangan semua arahan dalam blok transaksi, disusun dalam susunan pelaksanaan perintah. Apabila operasi terganggu, nilai kosong sifar dikembalikan.
3) Dengan memanggil DISCARD, pelanggan boleh mengosongkan baris gilir transaksi dan berhenti melaksanakan transaksi, dan pelanggan akan keluar dari keadaan transaksi.
4) Perintah WATCH boleh menyediakan gelagat semak dan tetapkan (CAS) untuk transaksi Redis. Satu atau lebih kunci boleh dipantau Setelah salah satu kunci diubah suai (atau dipadamkan), urus niaga berikutnya tidak akan dilaksanakan dan pemantauan diteruskan sehingga perintah EXEC.
Redis melaksanakan kunci teragih
Redis ialah mod satu utas satu proses Ia menggunakan mod gilir untuk menukar akses serentak kepada akses bersiri, dan tiada persaingan antara sambungan berbilang pelanggan Redis Anda boleh menggunakan arahan SETNX dalam Redis untuk melaksanakan kunci yang diedarkan.
Tetapkan nilai kunci kepada nilai jika dan hanya jika kunci tidak wujud. Jika kunci yang diberikan sudah wujud, SETNX tidak akan mengambil sebarang tindakan
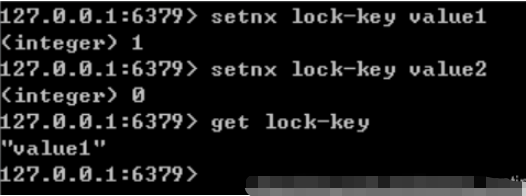
Membuka kunci: Gunakan perintah kekunci del untuk melepaskan kunci
Selesaikan kebuntuan:
1) Melalui Redis Dalam expire(), tetapkan masa pegangan maksimum untuk kunci Jika melebihi, Redis akan membantu kami melepaskan kunci.
2) Ini boleh dicapai dengan menggunakan kombinasi arahan kekunci setnx "masa sistem semasa + masa memegang kunci" dan kunci getset "masa sistem semasa + masa memegang kunci".
Atas ialah kandungan terperinci Bagaimana untuk menyelesaikan masalah berkaitan Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!