
Rumah >Peranti teknologi >AI >Kelas ChatGPT Andrew Ng menjadi viral: AI berhenti menulis perkataan ke belakang, tetapi memahami seluruh dunia
Kelas ChatGPT Andrew Ng menjadi viral: AI berhenti menulis perkataan ke belakang, tetapi memahami seluruh dunia

- 王林ke hadapan
- 2023-06-03 21:27:21979semak imbas
Saya tidak sangka ChatGPT masih akan melakukan kesilapan bodoh sehingga hari ini?
Cikgu Andrew Ng menunjukkannya pada kelas terkini:
ChatGPT tidak menterbalikkan perkataan!
Sebagai contoh, jika anda membalikkan perkataan lollipop, outputnya adalah pilollol, yang benar-benar mengelirukan.

Oh, ini memang agak mengejutkan.
Sehingga selepas netizen menyiarkan siaran itu di Reddit, ia serta-merta menarik sebilangan besar penonton, dan siaran itu dengan cepat mencapai 6k tontonan.
Dan ini bukan pepijat yang tidak disengajakan. Netizen mendapati bahawa ChatGPT tidak dapat menyelesaikan tugasan ini, dan keputusan ujian peribadi kami juga sama.

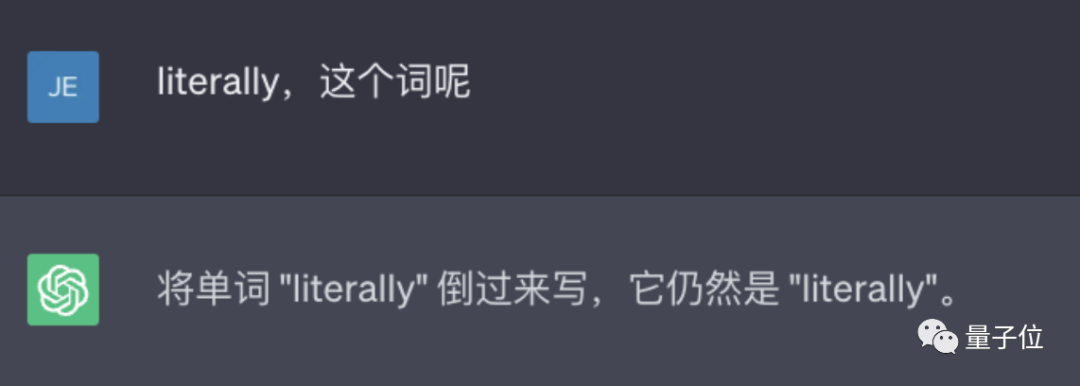
△Sembang SebenarGPT (GPT-3.5)
Malah produk termasuk Bard, Bing, Wen Xinyiyan, dll. tidak berfungsi.
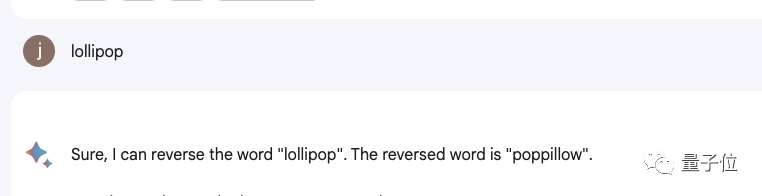
△Ukuran sebenar Bard

△Ukuran sebenar Bunshinichi Yan
Sesetengah orang membuat susulan dan mengadu bahawa ChatGPT sangat teruk dalam mengendalikan tugas perkataan mudah ini.
Sebagai contoh, bermain permainan perkataan popular Wordle adalah satu bencana dan tidak pernah melakukannya dengan betul.
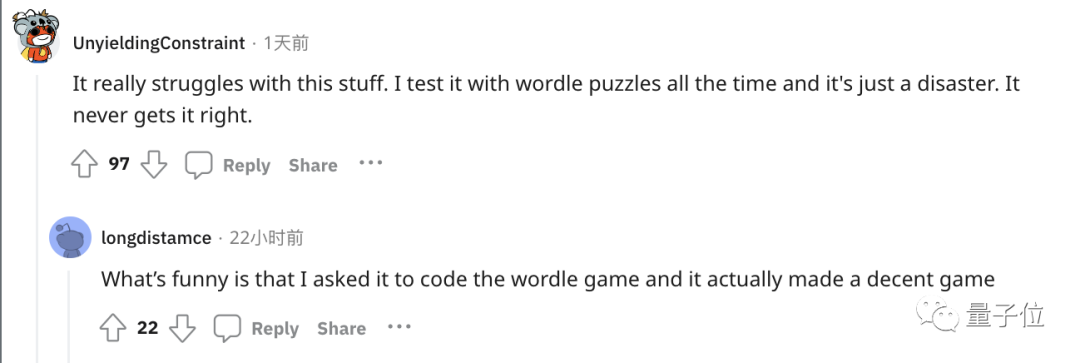
Eh? kenapa ni?
Kuncinya terletak pada token
Kunci kepada fenomena ini terletak pada token. Model besar sering menggunakan token untuk memproses teks kerana token ialah urutan aksara yang paling biasa dalam teks.
Ia boleh menjadi keseluruhan perkataan atau serpihan perkataan. Model besar sudah biasa dengan hubungan statistik antara token ini dan boleh menjana token seterusnya dengan mahir.
Jadi apabila menangani tugas kecil pembalikan perkataan, ia mungkin hanya membalikkan setiap token dan bukannya huruf.

Ini lebih jelas lagi dalam konteks Cina: perkataan ialah token, atau perkataan ialah token.

Mengenai contoh pada mulanya, seseorang cuba memahami proses penaakulan ChatGPT.
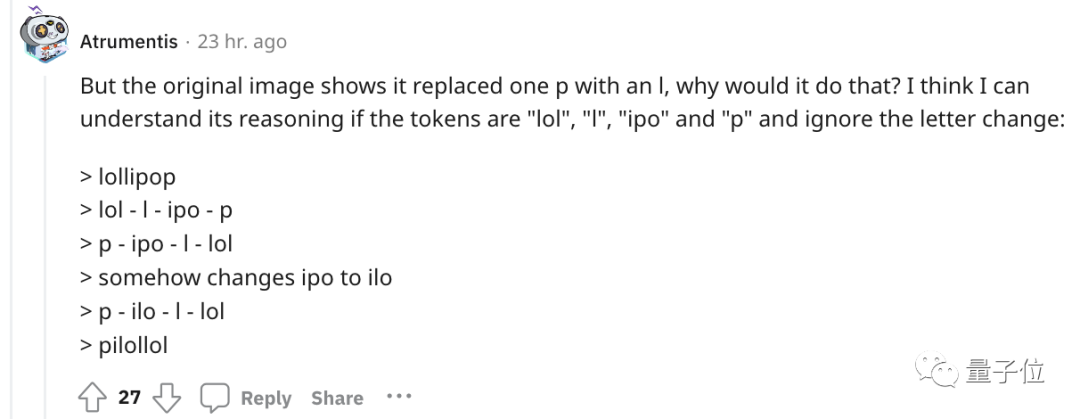
Untuk pemahaman yang lebih intuitif, OpenAI malah mengeluarkan GPT-3 Tokenizer.
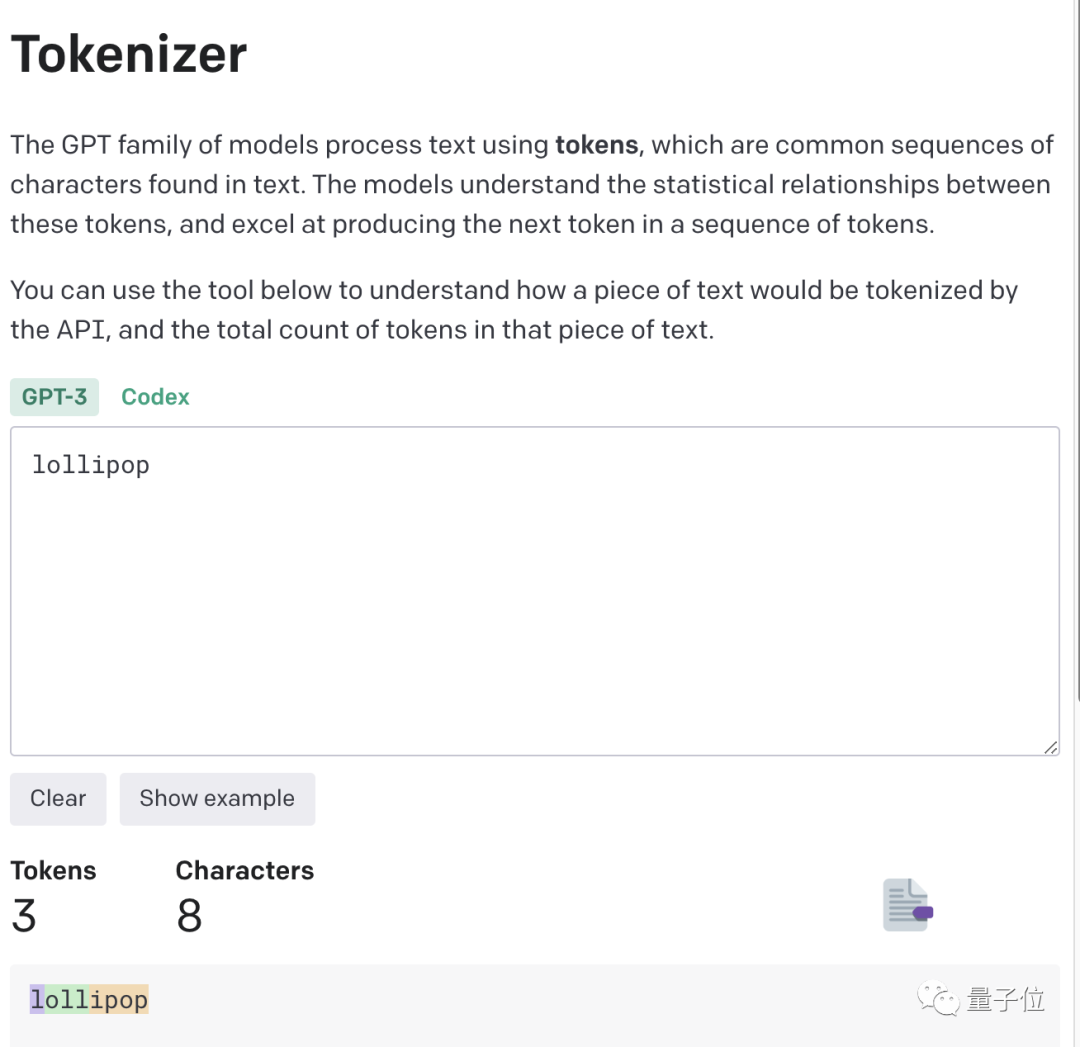
Sebagai contoh, perkataan lollipop akan difahami oleh GPT-3 sebagai tiga bahagian: I, oll dan ipop.
Berdasarkan ringkasan pengalaman, beberapa peraturan tidak bertulis telah dilahirkan.
- 1 token≈4 aksara Inggeris≈tiga perempat daripada satu perkataan; > Seperenggan≈100 token, 1500 perkataan≈2048 token;
- Cara perkataan dibahagikan juga bergantung pada bahasa. Seseorang sebelum ini telah mengira bahawa bilangan token yang digunakan dalam bahasa Cina ialah 1.2 hingga 2.7 kali ganda daripada dalam bahasa Inggeris.
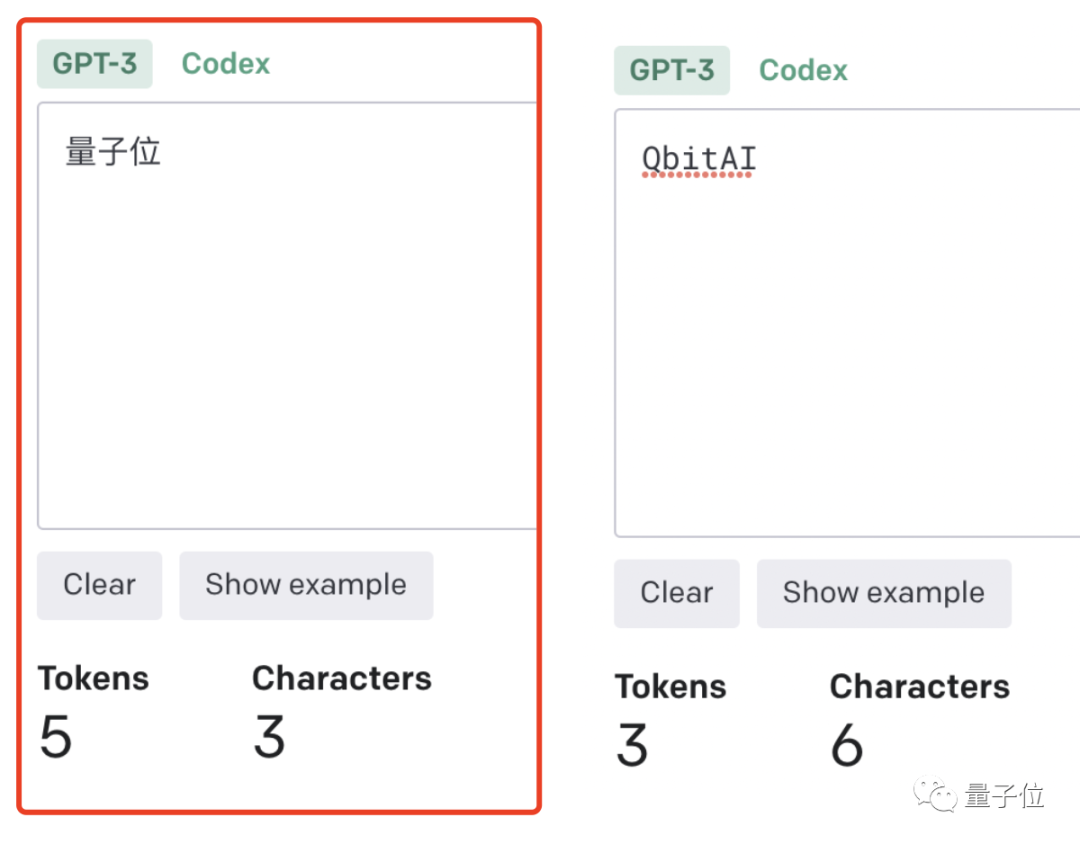
Semakin tinggi nisbah token-to-char, semakin tinggi kos pemprosesan. Oleh itu, pemprosesan tokenize Cina adalah lebih mahal daripada bahasa Inggeris.
Boleh difahami bahawa token ialah cara model besar untuk memahami dunia sebenar manusia. Ia sangat mudah dan sangat mengurangkan memori dan kerumitan masa.
Tetapi terdapat masalah dengan perkataan token, yang menyukarkan model untuk mempelajari perwakilan input yang bermakna. Perwakilan yang paling intuitif ialah ia tidak dapat memahami makna perkataan.
Pada masa itu, Transformers telah dioptimumkan dengan sewajarnya, contohnya, perkataan yang kompleks dan tidak biasa dibahagikan kepada token yang bermakna dan token bebas.
Sama seperti "mengganggu" dibahagikan kepada dua bahagian: "menjengkelkan" dan "ly", yang pertama mengekalkan maknanya sendiri, manakala yang kedua adalah lebih biasa.
Ini juga telah menghasilkan kesan menakjubkan ChatGPT dan produk model besar yang lain hari ini, yang boleh memahami bahasa manusia dengan baik.
Bagi ketidakupayaan untuk mengendalikan tugas kecil seperti pembalikan perkataan, sudah tentu ada penyelesaiannya.
Cara paling mudah dan langsung ialah memisahkan perkataan itu sendiri~

Atau anda boleh biarkan ChatGPT melakukannya langkah demi langkah , mula-mula tandakan setiap huruf.

Atau biarkan ia menulis atur cara yang membalikkan huruf, dan keputusan atur cara itu akan betul. (Kepala Anjing)

Walau bagaimanapun, GPT-4 juga boleh digunakan, dan tiada masalah sedemikian dalam ujian sebenar.

△ Diukur GPT-4
Ringkasnya, token ialah asas pemahaman AI tentang bahasa semula jadi.
Sebagai jambatan untuk AI memahami bahasa semula jadi manusia, kepentingan token telah menjadi semakin jelas.
Ia telah menjadi penentu utama prestasi model AI dan standard pengebilan untuk model besar.
Malah terdapat kesusasteraan token
Seperti yang dinyatakan di atas, token boleh memudahkan model menangkap maklumat semantik yang lebih halus, seperti makna perkataan, susunan perkataan, struktur tatabahasa, dsb. Dalam tugas pemodelan jujukan (seperti pemodelan bahasa, terjemahan mesin, penjanaan teks, dll.), kedudukan dan susunan adalah sangat penting untuk pembinaan model.
Hanya apabila model memahami dengan tepat kedudukan dan konteks setiap token dalam jujukan, ia boleh meramalkan kandungan dengan lebih baik dan betul serta memberikan output yang munasabah.
Oleh itu, kualiti dan kuantiti token mempunyai kesan langsung ke atas kesan model.
Mulai tahun ini, apabila semakin banyak model besar dikeluarkan, bilangan token akan dititikberatkan Sebagai contoh, butiran pendedahan Google PaLM 2 menyebut bahawa ia menggunakan 3.6 trilion token untuk latihan.
dan ramai pemimpin industri juga mengatakan bahawa token adalah sangat penting!
Andrej Karpathy, seorang saintis AI yang beralih daripada Tesla kepada OpenAI tahun ini, berkata dalam ucapannya:
Lebih banyak token boleh membolehkan model Berfikir lebih baik.

Dan beliau menekankan bahawa prestasi model bukan sahaja ditentukan oleh saiz parameter.
Sebagai contoh, saiz parameter LLaMA jauh lebih kecil daripada GPT-3 (65B lwn 175B), tetapi kerana ia menggunakan lebih banyak token untuk latihan (1.4T lwn 300B), LLaMA lebih berkuasa.
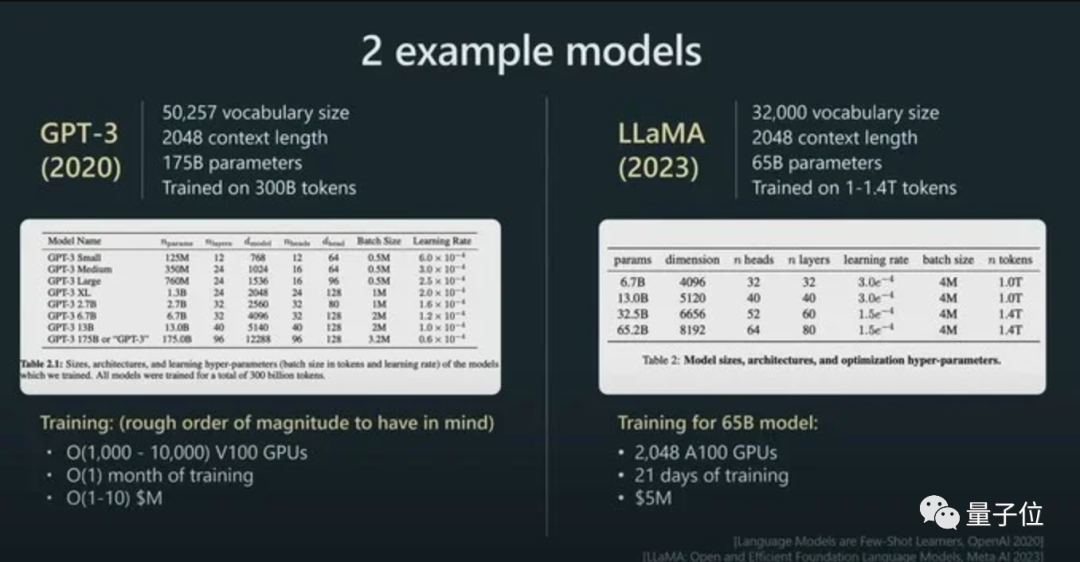
Dengan kesan langsungnya terhadap prestasi model, token juga merupakan standard pengebilan untuk model AI.
Ambil standard harga OpenAI sebagai contoh. Mereka mengenakan bayaran dalam unit token 1K Model yang berbeza dan jenis token yang berbeza mempunyai harga yang berbeza.
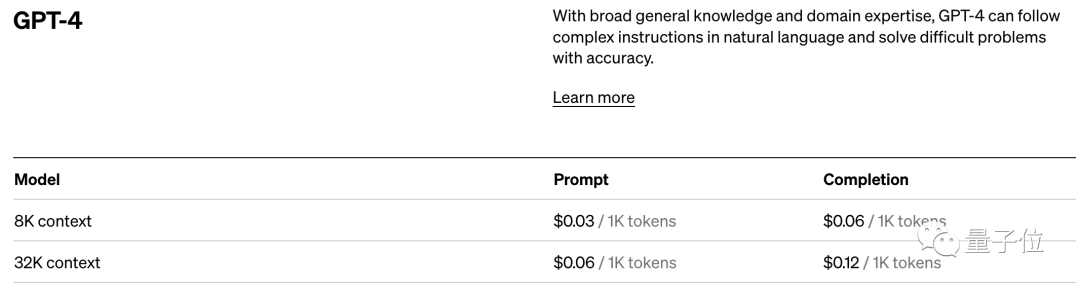
Ringkasnya, sebaik sahaja anda melangkah ke bidang model besar AI, anda akan mendapati bahawa token adalah titik pengetahuan yang tidak dapat dielakkan.
Nah, ia juga melahirkan kesusasteraan token...
Tetapi patut disebut, apakah peranan yang dimainkan oleh token dalam bahasa Cina dunia? Apa yang sepatutnya diterjemahkan masih belum diputuskan sepenuhnya.
Terjemahan literal "token" sentiasa agak pelik.
GPT-4 berpendapat lebih baik untuk memanggilnya sebagai "unsur perkataan" atau "tag", apakah pendapat anda?

Pautan rujukan:
[1]https://www.reddit.com/r/ChatGPT/comments/13xxehx/chatgpt_is_unable_to_reverse_words/
[2]https://help.openai.com/ms/articles/4936856-what-are-tokens-and-how-to-count-them
[3]https://openai.com /harga
Atas ialah kandungan terperinci Kelas ChatGPT Andrew Ng menjadi viral: AI berhenti menulis perkataan ke belakang, tetapi memahami seluruh dunia. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI