
Rumah >Peranti teknologi >AI >Pengaturcara Java mempelajari LangChain dari awal—komponen model
Pengaturcara Java mempelajari LangChain dari awal—komponen model

- PHPzke hadapan
- 2023-06-03 20:23:491745semak imbas
Artikel sebelum ini memperkenalkan anda kepada beberapa pengetahuan asas tentang LangChain yang belum melihatnya boleh klik di sini untuk melihat Hari ini, kami akan memperkenalkan kepada anda model komponen penting LangChain, Model.
Perhatikan bahawa model yang dinyatakan di sini merujuk kepada komponen model LangChain, bukan model bahasa yang serupa dengan OpenAI Sebab mengapa LangChain mempunyai komponen model adalah kerana terdapat terlalu banyak model bahasa dalam industri, kecuali untuk syarikat OpenAI Selain model bahasa, terdapat banyak lagi model lain.
LangChain mempunyai tiga jenis komponen model iaitu LLM Large Language Model, Chat Model dan Text Embedding Models.
Model Bahasa Besar LLM
LLM ialah komponen model paling asas kedua-dua input dan output hanya menyokong rentetan, yang boleh memenuhi keperluan kita dalam kebanyakan senario. Kami boleh menulis kod Python terus pada Colab([https://colab.research.google.com)
Contohnya
Berikut ialah satu kes Pasang dependensi dahulu, dan kemudian laksanakan kod berikut.
pip install openaipip install langchainrrree
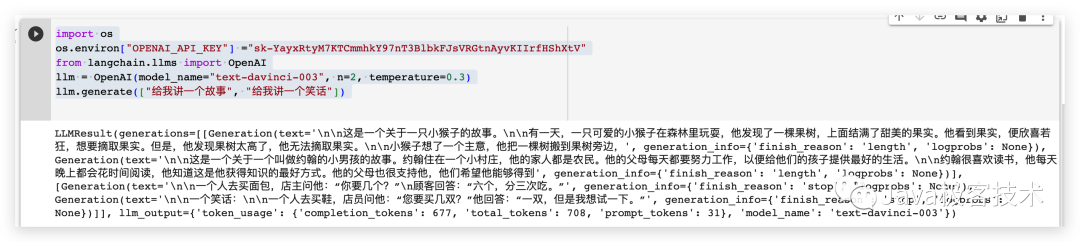
Keputusan yang dijalankan adalah seperti berikut
Model Sembang Model Sembang
Model Sembang adalah berdasarkan Model LLM Cuma input dan output antara komponen Model Sembang lebih berstruktur daripada model LLM Jenis parameter input dan output ialah Model Sembang, bukan rentetan ringkas. Jenis Model Sembang yang biasa digunakan termasuk yang berikut
- AIMessage: digunakan untuk menyimpan respons LLM supaya maklumat ini boleh dihantar semula ke LLM semasa permintaan seterusnya.
- HumanMessage: Mesej gesaan dihantar ke LLM, seperti "Laksanakan kaedah isihan pantas"
- Mesej Sistem: Tetapkan gelagat dan matlamat model LLM. Anda boleh memberikan arahan khusus di sini, seperti "Jadilah pakar pengekodan", atau "Return json format".
- ChatMessage: ChatMessage boleh menerima nilai dalam sebarang bentuk, tetapi selalunya, kita harus menggunakan tiga jenis di atas.
Sebagai contoh
import os# 配置OpenAI 的 API KEYos.environ["OPENAI_API_KEY"] ="sk-xxx"# 从 LangChain 中导入 OpenAI 的模型from langchain.llms import OpenAI# 三个参数分别代表OpenAI 的模型名称,执行的次数和随机性,数值越大越发散llm = OpenAI(model_name="text-davinci-003", n=2, temperature=0.3)llm.generate(["给我讲一个故事", "给我讲一个笑话"])
Rentetan kandungan yang dijana adalah dalam bentuk berikut
Algoritma carian separuh ialah carian yang digunakan untuk mencari elemen tertentu dalam tatasusunan tertib Algoritma, juga dikenali sebagai algoritma carian binari. Kerumitan masa algoritma ini ialah O(log n). nnBerikut ialah kod untuk melaksanakan algoritma carian binari dalam Java: nnjavanpublic class BinarySearch {n public static int binarySearch(int[] arr, int target) {n int left = 0;n int right = arr.length - 1;n manakala (kiri <= kanan) {n int pertengahan = (kiri + kanan) / 2;n jika (arr[pertengahan] == sasaran) {n kembali pertengahan;n } jika tidak (arr[pertengahan] < sasaran) {n kiri = pertengahan + 1;n } lain {n kanan = pertengahan - 1;n }n }n kembali -1;n }nn public static void main(String[] args) {n int[] arr = {1 , 3, 5, 7, 9};n sasaran int = 5;n indeks int = carian binari(arr, sasaran);n jika (indeks != -1) {n System.out.println("elemen sasaran" + sasaran + " dalam Subskrip dalam tatasusunan ialah " + indeks n } else {n System.out.println("elemen sasaran" + sasaran + " tiada dalam tatasusunan"); kod di atas, kaedah Carian binari Menerima tatasusunan diisih dan elemen sasaran, mengembalikan subskrip elemen sasaran dalam tatasusunan, atau -1 jika elemen sasaran tiada dalam tatasusunan. nnDalam kaedah Carian binari, gunakan dua penunjuk kiri dan kanan untuk menunjuk ke hujung kiri dan kanan tatasusunan masing-masing, dan kemudian teruskan menyempitkan julat carian dalam gelung sementara sehingga elemen sasaran ditemui atau julat carian kosong. Dalam setiap gelung, pertengahan kedudukan tengah dikira, dan kemudian elemen sasaran dibandingkan dengan elemen di kedudukan tengah Jika ia sama, subskrip kedudukan tengah dikembalikan jika elemen sasaran lebih besar daripada elemen dalam kedudukan tengah, penunjuk kiri dialihkan ke Ke kanan kedudukan tengah jika elemen sasaran lebih kecil daripada elemen kedudukan tengah, gerakkan penunjuk kanan ke kiri kedudukan tengah. ' additional_kwargs={} example=False
Ekstrak kandungan dalam kandungan dan paparkannya menggunakan sintaks markdown seperti ini
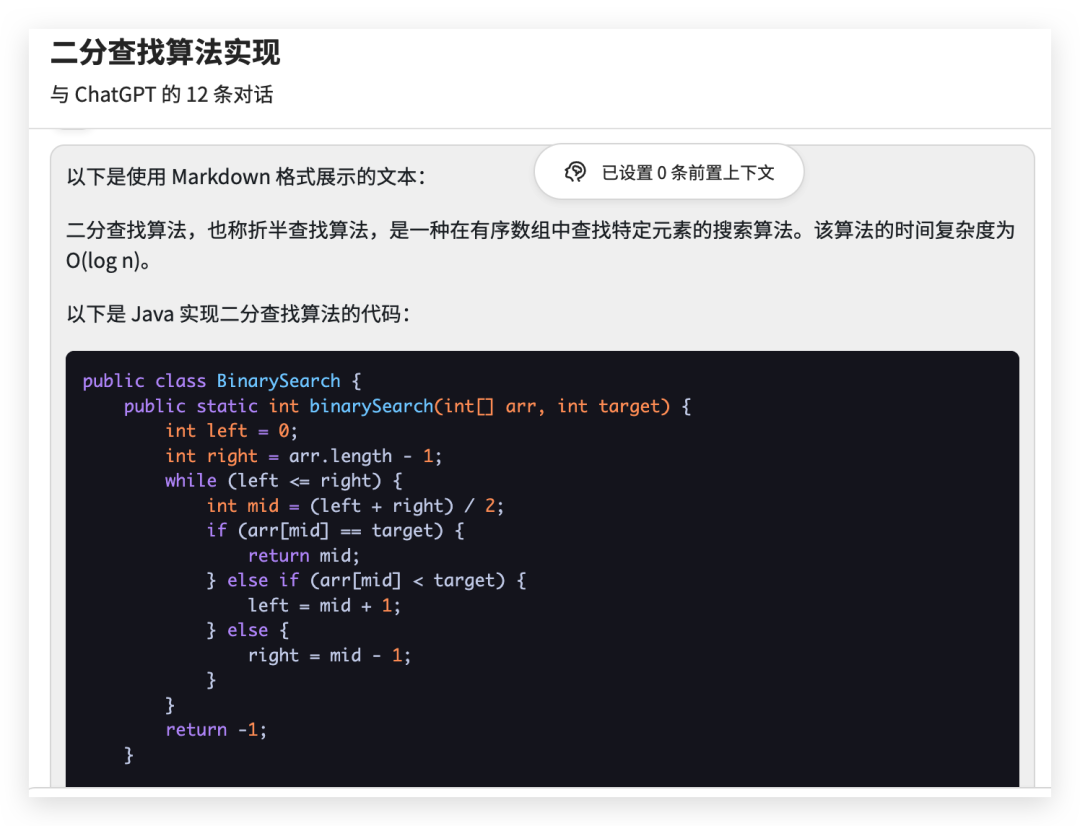
Gunakan komponen model ini, Anda boleh pratetap beberapa peranan dan kemudian menyesuaikan soalan dan jawapan yang diperibadikan.
Templat gesaan
from langchain.chat_models import ChatOpenAIfrom langchain.schema import (AIMessage,HumanMessage,SystemMessage)chat = ChatOpenAI(temperature=0)messages = [SystemMessage(cnotallow="返回的数据markdown 语法进行展示,代码使用代码块包裹"),HumanMessage(cnotallow="用 Java 实现一个二分查找算法")]print(chat(messages))
output
messages=[SystemMessage(cnotallow='Anda ialah pembantu yang menterjemah bahasa Inggeris ke bahasa Cina', additional_kwargs= { }), HumanMessage(cnotallow='Saya suka pengaturcaraan.', additional_kwargs={}, contoh=False)] cnotallow='Saya suka pengaturcaraan.' example=False, additional_kwargs={}
文本嵌入模型 Text Embedding Models
文本嵌入模型组件相对比较难理解,这个组件接收的是一个字符串,返回的是一个浮点数的列表。在 NLP 领域中 Embedding 是一个很常用的技术,Embedding 是将高维特征压缩成低维特征的一种方法,常用于自然语言处理任务中,如文本分类、机器翻译、推荐系统等。它将文本中的离散数据如单词、短语、句子等,映射为实数向量,以更好地进行神经网络处理和学习。通过 Embedding,文本数据可以被更好地表示和理解,提高了模型的表现力和泛化能力。
举个栗子
from langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings()text = "hello world"query_result = embeddings.embed_query(text)doc_result = embeddings.embed_documents([text])print(query_result)print(doc_result)
output
[-0.01491016335785389, 0.0013780705630779266, -0.018519161269068718, -0.031111136078834534, -0.02430146001279354, 0.007488010451197624,0.011340680532157421, 此处省略 .......
总结
今天给大家介绍了一下 LangChain 的模型组件,有了模型组件我们就可以更加方便的跟各种 LLMs 进行交互了。
参考资料
官方文档:https://python.langchain.com/en/latest/modules/models.html
Atas ialah kandungan terperinci Pengaturcara Java mempelajari LangChain dari awal—komponen model. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI