
Rumah >pangkalan data >tutorial mysql >Contoh analisis sub-pangkalan data MySQL dan sub-jadual
Contoh analisis sub-pangkalan data MySQL dan sub-jadual

- PHPzke hadapan
- 2023-06-03 18:34:301263semak imbas
1 Mengapa sub-pangkalan data dan jadual
Evolusi seni bina pangkalan data
Pada mulanya, ia sudah cukup untuk kebanyakan projek untuk menggunakan pangkalan data mesin tunggal Memandangkan trafik pelayan semakin besar dan lebih besar, dan ia menghadapi lebih banyak permintaan, kami telah memisahkan membaca dan menulis pangkalan data, menggunakan beberapa salinan pangkalan data hamba (Slave) untuk bertanggungjawab membaca, dan menggunakan pangkalan data induk (Master) untuk bertanggungjawab untuk menulis, master dan slave kemas kini data segerak dicapai melalui replikasi master-slave untuk memastikan data konsisten. Pustaka hamba boleh dikembangkan secara mendatar, jadi lebih banyak permintaan baca tidak menjadi masalah
Tetapi apabila tahap pengguna meningkat dan terdapat lebih banyak permintaan tulis, bagaimana untuk memastikan beban pangkalan data mencukupi? Menambah Master tidak dapat menyelesaikan masalah, kerana data perlu konsisten, dan operasi tulis memerlukan penyegerakan antara dua induk, yang bersamaan dengan pendua, dan reka bentuk seni bina adalah lebih kompleks
Dalam kes ini, anda perlu menggunakan Jadual pembahagian sub-perpustakaan (sharding), menyimpan perpustakaan dan jadual pada Pelayan MySQL yang berbeza Setiap pelayan boleh mengimbangi bilangan permintaan tulis
2. Masalah yang disebabkan oleh jadual pangkalan data yang terlalu besar
.-
Pangkalan data tunggal terlalu besar: Pangkalan data tunggal mempunyai kapasiti pemprosesan yang terhad, ruang cakera tidak mencukupi pada pelayan dan menghadapi kesesakan IO Pangkalan data tunggal perlu dibahagikan kepada perpustakaan yang lebih kecil
Jadual tunggal terlalu besar: Kecekapan CURD sangat rendah, Jumlah data terlalu besar, menyebabkan fail indeks terlalu besar dan cakera IO mengambil masa untuk memuatkan indeks , mengakibatkan tamat masa pertanyaan. Jadi hanya menggunakan indeks tidak mencukupi Anda perlu membahagikan satu jadual kepada berbilang jadual dengan set data yang lebih kecil. Algoritma pemisahan jadual yang disediakan oleh MyCat semuanya dalam rule.xml, yang boleh dipecah mengikut algoritma pemisahan jadual yang berbeza, seperti pemisahan berdasarkan masa, pencincangan yang konsisten, secara langsung menggunakan kunci utama untuk memodulasi bilangan jadual pemisahan, dsb.
Jika jumlah data dalam satu jadual terlalu besar, gunakan pemisahan mendatar Pemisahan, iaitu, pemisahan data jadual kepada berbilang jadual mengikut peraturan tertentu (algoritma pemisahan jadual ditakrifkan dalam peraturan. Pertimbangkan dahulu pemisahan menegak, dan kemudian pertimbangkan pemisahan mendatar
3. Pemisahan menegak
- Sub-pangkalan data, pemecahan dan pemisahan baca-tulis boleh dijalankan bersama
-
1
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB1,USERDB2</property> </user>
dikonfigurasikan dengan dua perpustakaan logik USERDB1 dan USERDB2 -
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB1" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1" /> <!-- 两个逻辑库对应两个不同的数据节点 --> <schema name="USERDB2" checkSQLschema="false" sqlMaxLimit="100"dataNode="dn2" /> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <!-- 两个数据节点对应两个不同的物理机器 --> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- USERDB1对应mytest1,USERDB2对应mytest2 --> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0"writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>
Sepadan dengan dua nod data yang berbeza, kedua-dua nod data sepadan dengan dua mesin fizikal yang berbeza
mytest1 dan mytest2 dibahagikan kepada perpustakaan yang berbeza pada mesin yang berbeza, setiap satu mengandungi bahagian Jadual, yang pada asalnya disepadukan ke dalam satu mesin, kini dipecah secara menegak.
Pelanggan perlu menyambung ke perpustakaan logik yang berbeza digunakan mengikut operasi perniagaan
Kemudian dua perpustakaan penulisan dikonfigurasikan, dan dua mesin mengendalikan perpustakaan. . Ia dibahagikan sama rata, berkongsi tekanan mesin tunggal asal. Pecahan pangkalan data disertakan dengan pembahagian jadual, yang membahagikan jadual daripada perspektif perniagaan2. Pecahan jadual menegakPecahan jadual menegak adalah berdasarkan medan lajur. Ia biasanya digunakan untuk jadual besar dengan beratus-ratus lajur untuk mengelakkan masalah "merentas halaman" yang disebabkan oleh sejumlah besar data semasa membuat pertanyaan. Secara amnya, terdapat banyak medan dalam jadual, jadi medan yang tidak biasa digunakan, mempunyai data yang besar dan panjang (seperti medan jenis teks) dibahagikan kepada jadual lanjutan. Medan dengan kekerapan akses yang lebih tinggi diletakkan dalam jadual berasingan 4. Sub-pangkalan data dan sub-jadual mendatar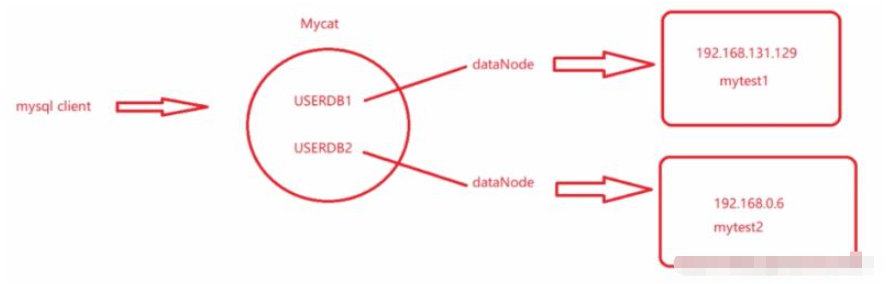 Untuk satu jadual dengan jumlah data yang besar (seperti jadual pesanan) , mengikut peraturan tertentu ( RANGE, modulus HASH, dsb.), dibahagikan kepada beberapa jadual. Tidak disyorkan kerana jadual masih dalam pangkalan data yang sama, jadi mungkin terdapat kesesakan IO dalam melaksanakan operasi terhadap keseluruhan pangkalan data
Untuk satu jadual dengan jumlah data yang besar (seperti jadual pesanan) , mengikut peraturan tertentu ( RANGE, modulus HASH, dsb.), dibahagikan kepada beberapa jadual. Tidak disyorkan kerana jadual masih dalam pangkalan data yang sama, jadi mungkin terdapat kesesakan IO dalam melaksanakan operasi terhadap keseluruhan pangkalan data
Mengedarkan data daripada satu jadual merentasi berbilang pelayan, setiap pelayan memiliki sebahagian daripada jadual dan Perpustakaan, tetapi pengumpulan data dalam jadual adalah berbeza. Penerapan teknologi sub-pangkalan data dan sub-jadual secara berkesan boleh mengurangkan kesesakan prestasi dan tekanan mesin tunggal dan pangkalan data tunggal, dan juga boleh menembusi batasan yang berkaitan dengan IO, bilangan sambungan, sumber perkakasan, dll.
Pembahagian jadual sub-pangkalan data boleh dilakukan pada masa yang sama dengan replikasi tuan-hamba, tetapi ia tidak berdasarkan replikasi tuan-hamba; pemisahan baca-tulis adalah berdasarkan replikasi tuan-hamba 
server.xml
<user name="root"> <property name="password">123456</property> <property name="schemas">USERDB</property> </user>
schema.xml
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <!-- 逻辑数据库 --> <schema name="USERDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="user" dataNode="dn1" /> <!-- 这里的user和student都是实际存在的物理表名 --> <table name="student" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2" rule="mod-long"/> </schema> <!-- 存储节点 --> <dataNode name="dn1" dataHost="node1" database="mytest1" /> <dataNode name="dn2" dataHost="node2" database="mytest2" /> <!-- 数据库主机 --> <dataHost name="node1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.131.129" url="192.168.131.129:3306" user="root" password="123456" /> </dataHost> <dataHost name="node2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native"> <heartbeat>select user()</heartbeat> <writeHost host="192.168.0.6" url="192.168.0.6:3306" user="root" password="123456" /> </dataHost> </mycat:schema>pengguna mewakili jadual biasa, yang diletakkan terus pada nod data dn1 dan diletakkan pada sebuah mesin. Jadual ini tidak perlu dipecahkan jadual pelajar Kunci utama ialah id Ia dibahagi mengikut id dan diletakkan pada dn1 dan dn2 mesin. Mereka dipisahkan secara fizikal, tetapi secara logiknya mereka masih satu jadual yang harus ditambah dalam 2 Pertanyaan pada setiap mesin dan kemudian menggabungkan operasi ini semua dilakukan oleh mycat Peraturan pemisahan adalah modulo (mod. - panjang), dan setiap sisipan menggunakan modulo id bilangan mesin yang ada padanya (2) Selain itu, algoritma pemisahan berikut perlu dikonfigurasikan dalam rule.xml
Cari algoritma mod-long Kerana kami memetakan pelajar jadual logik kepada dua hos secara berasingan, bilangan nod data yang diubah suai ialah 2

2 -table
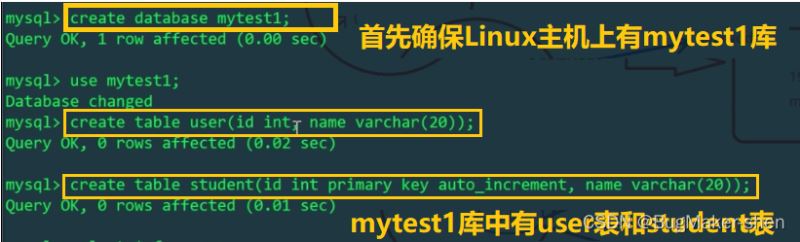
Hos Linux
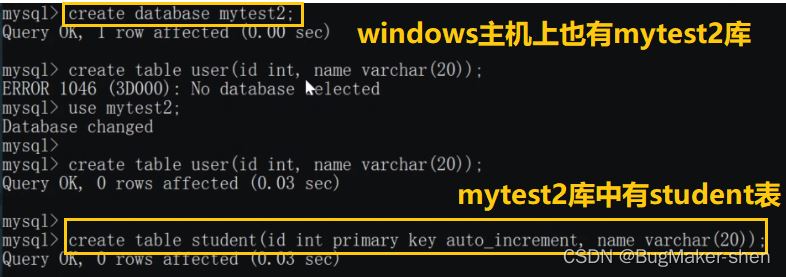
Hos Windows
Log masuk ke port 8066 mycat
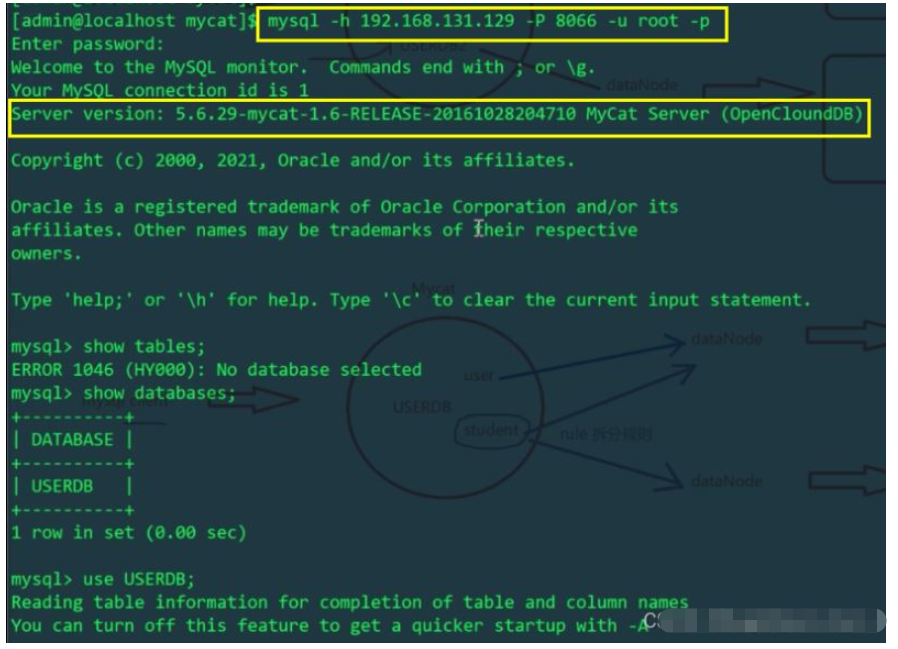
Gunakan MyCat untuk memasukkan dua keping data ke dalam jadual pengguna

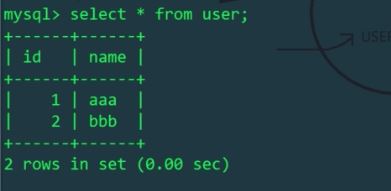
Disebabkan oleh fail konfigurasi schema.xml , pengguna jadual logik hanya dalam Ia wujud dalam perpustakaan mytest1 hos Linux Pengguna jadual logik yang dikendalikan oleh mycat akan menjejaskan jadual fizikal pada hos Linux tetapi bukan jadual pada hos Windows. Kami melihat jadual pengguna hos Linux dan Windows masing-masing:

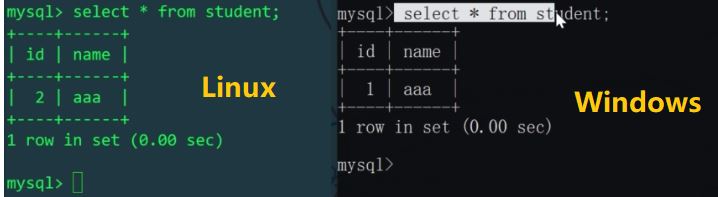
Kami kemudian memasukkan dua keping data ke dalam jadual pelajar melalui MyCat

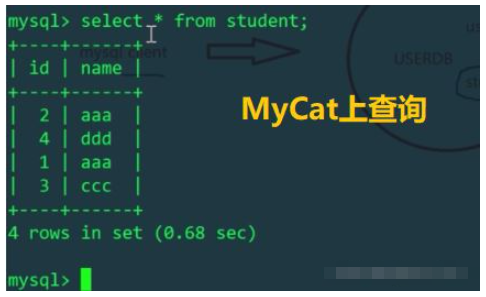
Kami tahu bahawa dalam fail konfigurasi schema.xml, pelajar jadual logik sepadan dengan dua jadual dalam dua perpustakaan mytest1 dan mytest2 pada dua hos, jadi dua bahagian daripada data yang dimasukkan ke dalam jadual logik , sebenarnya akan mempengaruhi dua jadual fizikal (gunakan id%机器数 untuk memutuskan jadual fizikal yang hendak dimasukkan ke dalam). Mari semak jadual pelajar hos Linux dan Windows masing-masing:
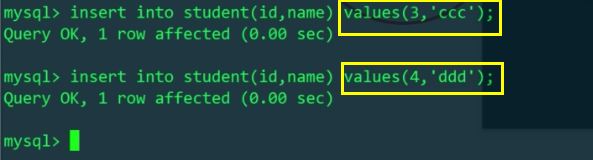
Kemudian masukkan data id=3 dan id=4 melalui MyCat, yang harus dimasukkan ke dalam jadual fizikal yang berbeza pada hos yang berbeza
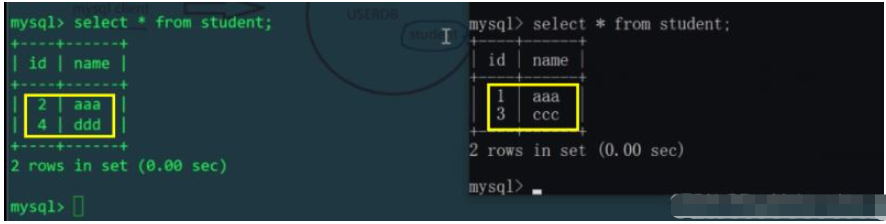
Ini sama dengan membahagikan meja pelajar secara mendatar
Apabila membuat pertanyaan melalui MyCat, ia hanya perlu biasa Hanya masukkannya. Kami mengkonfigurasi jadual untuk dipecahkan dan diletakkan pada dua nod data ini akan membuat pertanyaan dan menggabungkan data pada dua pangkalan data mengikut konfigurasi
Atas ialah kandungan terperinci Contoh analisis sub-pangkalan data MySQL dan sub-jadual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!