
Rumah >Peranti teknologi >AI >Amerika Syarikat telah membelanjakan 2.6 bilion dolar AS untuk kecerdasan buatan...Ia dijangka menyiapkan pembinaan NAIRR dalam tempoh 6 tahun
Amerika Syarikat telah membelanjakan 2.6 bilion dolar AS untuk kecerdasan buatan...Ia dijangka menyiapkan pembinaan NAIRR dalam tempoh 6 tahun

- 王林ke hadapan
- 2023-06-03 17:36:071330semak imbas
Kecerdasan buatan ialah teknologi strategik yang menerajui pusingan baharu revolusi teknologi dan perubahan industri. Hasil penyelidikan dan data berbilang menunjukkan bahawa Amerika Syarikat mendahului dunia dalam penyelidikan saintifik asas, inovasi teknologi, dan aplikasi industri kecerdasan buatan Petunjuk seperti kertas kecerdasan buatan peringkat tinggi, bilangan cendekiawan terkemuka, bilangan perusahaan kecerdasan buatan. , dan skala pelaburan semuanya mendahului negara lain.
Kerajaan A.S. sangat mementingkan inovasi dan pembangunan teknologi kecerdasan buatan. Menurut Akta Inisiatif AI Kebangsaan 2020, Kongres memerlukan Yayasan Sains Kebangsaan (NSF) dan Pejabat Dasar Sains dan Teknologi (OSTP) Rumah Putih untuk membentuk kumpulan kerja untuk mengkaji dan merumuskan Amerika Syarikat pada Januari 2023. The National Pelan halatuju pembinaan infrastruktur Sumber Penyelidikan Kecerdasan Buatan (NAIRR) menyatukan kelebihan daya saing Amerika Syarikat dalam bidang kecerdasan buatan, meluaskan peluang untuk semua pihak di Amerika Syarikat untuk mendapatkan kecerdasan buatan dan sumber pendidikan utama, dan seterusnya memacu inovasi dan kecerdasan buatan A.S. kemakmuran ekonomi.
Latar belakang dan kepentingan pembinaan NAIRR di Amerika Syarikat
Latar belakang pembinaan
Kerajaan A.S. percaya bahawa kelebihan utamanya dalam bidang kecerdasan buatan sedang dicabar dan kelebihan daya saingnya berisiko lemah. Terdapat dua masalah utama: Pertama, pelaburan dalam R&D kecerdasan buatan dan sumber pendidikan diagihkan secara tidak sekata. Data penyelidikan menunjukkan bahawa dari perspektif pelaburan, jumlah pelaburan kecerdasan buatan daripada sektor swasta di Amerika Syarikat meningkat lebih daripada dua kali ganda dari 2020 hingga 2021, tetapi bilangan syarikat kecerdasan buatan baharu semakin berkurangan dari perspektif bakat, demografi kaum graduan kedoktoran kecerdasan buatan A.S. Taburan, taburan jantina dan bahagian sebenar populasi adalah agak berbeza, yang akan menyekat inovasi dan pembangunan kecerdasan buatan. Kedua, institusi penyelidikan saintifik mempunyai sumber pengkomputeran dan sumber data yang tidak mencukupi. Dari perspektif kuasa pengkomputeran, platform kuasa pengkomputeran yang paling maju dimiliki oleh institusi swasta yang menerajui industri, dan institusi penyelidikan saintifik kekurangan platform kuasa pengkomputeran untuk menyokong penyelidikan dan pembangunan kecerdasan buatan dari perspektif sumber data, sumber data utama untuk latihan model kecerdasan buatan dimiliki oleh institusi swasta dan semua platform Internet berskala besar Walaupun kerajaan A.S. terus membuka data, ia masih tidak mencukupi untuk penyelidikan kecerdasan buatan.
Kumpulan kerja menegaskan bahawa kekurangan sumber penyelidikan kecerdasan buatan yang mencukupi akan mengehadkan ekosistem inovasi kecerdasan buatan A.S., yang membawa kepada penumpuan bakat terkemuka daripada institusi penyelidikan akademik kepada sebilangan kecil perusahaan yang kaya dengan sumber Jika trend ini bertahan dalam jangka panjang, ia akan menjejaskan daya saing dan daya saing Amerika Syarikat. Pada Januari 2023, selepas 18 bulan meminta pendapat dan perbincangan awam, kumpulan kerja secara rasmi mencadangkan pelan pembinaan dan merancang untuk memohon dana pembinaan dan operasi dan penyelenggaraan AS$2.6 bilion ia merancang untuk menyiapkan kerja pembinaan NAIRR dalam empat fasa dalam tempoh 6 tahun, memfokuskan untuk mencapai empat Matlamat utama: Mengumpul sumber untuk menggalakkan inovasi penyelidikan, meningkatkan kepelbagaian bakat, meningkatkan keupayaan sumber asas dan menggalakkan pembangunan kecerdasan buatan yang dipercayai.
Kepentingan
Sebagai infrastruktur penyelidikan kecerdasan buatan, NAIRR terbuka kepada sekolah penyelidikan Amerika, pelajar, organisasi bukan untung dan institusi lain, menyediakan sumber pengkomputeran, data berkualiti tinggi, alat pendidikan dan sumber penyelidikan asas yang lain menjadi kerjasama penyelidikan kecerdasan buatan A.S. sebagai hab utama untuk menyatukan kelebihan daya saing antarabangsanya.
Dari segi pembinaan ekologi, kerajaan A.S. akan bergantung kepada NAIRR untuk menyatukan jabatan kerajaan dalaman yang berkaitan dan institusi penyelidikan saintifik untuk bersama-sama menjalankan penyelidikan koperasi dan pembinaan sumber dalam bidang kecerdasan buatan bagi membentuk ekosistem koperasi yang luas. Perkhidmatan dan fungsi NAIRR ditunjukkan dalam Rajah 1.
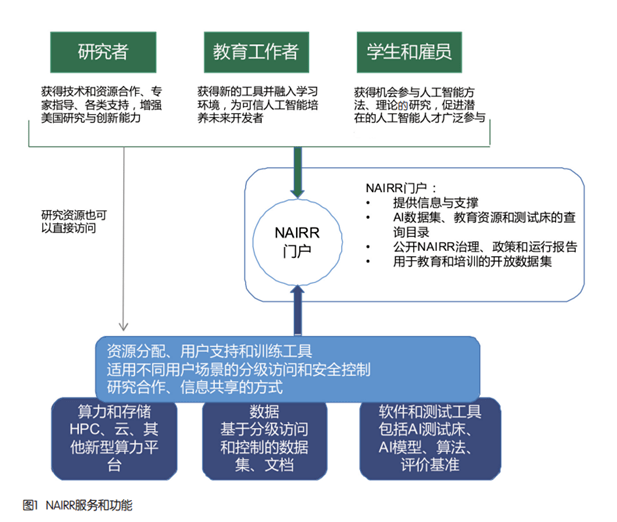
Dari segi data, NAIRR akan mengagregatkan data daripada jabatan kerajaan persekutuan dan menjalankan kerjasama perkhidmatan data dengan pelbagai institusi dalam industri. Yang pertama adalah untuk menggalakkan pengagregatan, pembangunan dan penggunaan sumber data kecerdasan buatan berskala besar Ia akan mengumpulkan dan menghubungkan sumber data berskala besar yang telah sumber terbuka oleh agensi persekutuan AS, institusi penyelidikan akademik dan gergasi teknologi untuk menjadi. platform perkhidmatan sumber data kecerdasan buatan terbesar di Amerika Syarikat. Sebagai contoh, Institut Kesihatan Kebangsaan AS telah mengeluarkan lebih daripada 36PB data penjujukan gen, dan Pentadbiran Lautan dan Atmosfera AS telah mengeluarkan lebih daripada 10PB data cuaca dan persekitaran. Yang kedua adalah untuk menggalakkan peningkatan pengurusan data kecerdasan buatan dan keupayaan tadbir urus. Set data kecerdasan buatan sangat berpecah-belah Setiap set data menyokong tugas khusus dan bidang penyelidikan Terdapat kekurangan piawaian bersatu untuk anotasi data dan tadbir urus data. NAIRR akan menggalakkan penubuhan piawaian bersatu untuk pengagregatan data, menyeragamkan format penerangan data dan mempromosikan pengagregatan sumber data berbilang pihak. Yang ketiga adalah untuk menggalakkan pembangunan dan penggunaan sumber data melalui kerjasama pelbagai pihak. Entiti yang beroperasi akan mengendalikan komuniti set data kecerdasan buatan dan menggalakkan komuniti untuk secara aktif membangun dan membina sumber data yang berharga untuk digunakan oleh NAIRR. Entiti pengendalian juga akan menyediakan perkhidmatan carian data untuk memudahkan pertanyaan data terbuka agensi persekutuan dan sumber data daripada penyedia perkhidmatan pihak ketiga.
Dari segi kuasa pengkomputeran, NAIRR akan bergabung tenaga dengan syarikat platform awan pengkomputeran kecerdasan buatan utama A.S. untuk membina platform kuasa pengkomputeran, dan merancang untuk berhubung dengan platform awan gergasi teknologi seperti Google, Microsoft dan Amazon, sebagai serta Yayasan Sains Semula Jadi A.S., Institut Kesihatan Kebangsaan A.S., dsb. Platform awan untuk agensi persekutuan. Platform ini menyediakan tahap model perkhidmatan dan kandungan yang berbeza untuk universiti, institusi penyelidikan, pelajar dan syarikat baru, termasuk pelbagai perkhidmatan dan sumber seperti data, kuasa pengkomputeran, katil ujian dan alatan perisian. Selepas selesai, sumber pengkomputeran NAIRR akan termasuk superkomputer yang menyokong sekurang-kurangnya satu trilion latihan model pembelajaran mesin skala parameter, serta sumber pengkomputeran awan, CPU, GPU dan rangkaian berkelajuan tinggi.
Selepas infrastruktur NAIRR diwujudkan dan beroperasi dengan stabil, di satu pihak, ia akan terus mengembangkan kerjasama dengan jabatan kerajaan dan institusi swasta, meluaskan skop perkhidmatan dan pengguna platform, dan sebaliknya mempromosikan pengalaman yang berjaya; platform itu akan menggalakkan penggubalan piawaian dan spesifikasi yang berkaitan, mengambil bahagian dalam pertukaran dan kerjasama antarabangsa, berfungsi sebagai platform asas untuk Amerika Syarikat dan sekutu serta rakan kongsinya, dan menggalakkan penyelidikan koperasi dan perkongsian data.
Rancangan Pembinaan NAIRR Amerika
Amerika Syarikat merancang untuk menggunakan pendekatan sistematik untuk menggerakkan kerajaan persekutuan dan institusi swasta untuk bekerjasama mewujudkan infrastruktur sumber penyelidikan kecerdasan buatan untuk penyelidikan akademik.
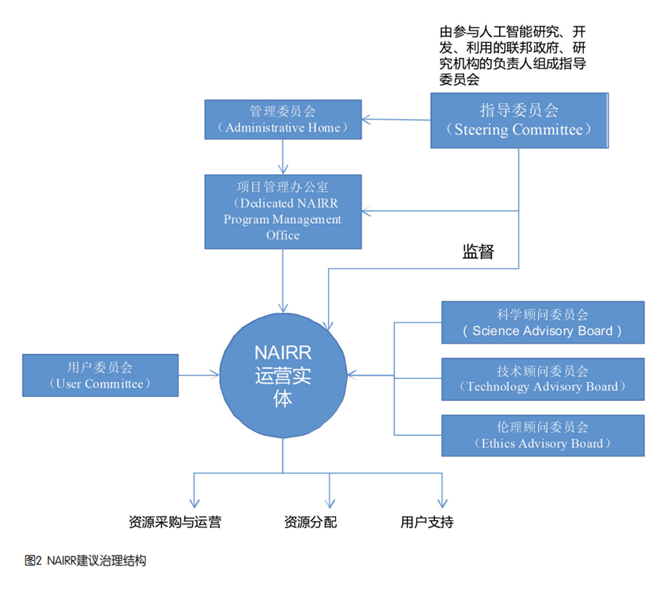
Pertama ialah merancang dan membina sistem tadbir urus platform dengan penyertaan berbilang parti. Struktur tadbir urus yang dicadangkan NAIRR ditunjukkan dalam Rajah 2. Pelan ini mengesyorkan mewujudkan sistem tadbir urus dengan penyertaan pelbagai pihak daripada jabatan kerajaan, dan menubuhkan satu siri organisasi yang bertanggungjawab seperti jawatankuasa pemandu, jawatankuasa pengurusan, pejabat pengurusan projek, entiti operasi, dan jawatankuasa penasihat untuk menyelaraskan kerjasama. Menubuhkan Jawatankuasa Pemandu, terdiri daripada wakil-wakil daripada pelbagai jabatan dan agensi kerajaan persekutuan Ia merupakan badan pembuat keputusan tertinggi di peringkat kebangsaan untuk keseluruhan perancangan dan matlamat strategik untuk NAIRR Ia mewakili pelbagai jabatan untuk mempromosikan pelaburan sumber negara daripada kecerdasan buatan. Jawatankuasa pengurusan ditubuhkan untuk membimbing dan mengurus entiti operasi platform, serta menyediakan dana dan sumber berkaitan. Pelan itu mencadangkan agar NSF memikul tanggungjawab jawatankuasa pengurusan. Menubuhkan pejabat pengurusan projek untuk bekerjasama dengan jawatankuasa pemandu dalam pengurusan harian dan penilaian entiti operasi. Kongres A.S. telah meluluskan pembiayaan untuk Pejabat Pengurusan Projek untuk menyokong pengurusan projek yang berkaitan, pembangunan dan penempatan portal, sokongan bersama, latihan dan sokongan pengguna. Menubuhkan entiti operasi yang bebas daripada jabatan kerajaan dan bertanggungjawab untuk merumuskan matlamat pembangunan khusus untuk NAIRR, mengatur pembinaan platform dan pengurusan operasi harian, dan merumuskan sistem peruntukan sumber yang telus, adil dan munasabah untuk memenuhi keperluan pelbagai institusi penyelidikan kecerdasan buatan. dan pengguna. Jawatankuasa saintifik, jawatankuasa teknikal, jawatankuasa etika dan jawatankuasa pengguna yang terdiri daripada pakar dalam pelbagai bidang telah ditubuhkan untuk menyediakan sokongan membuat keputusan bagi pembinaan NAIRR.
Yang kedua ialah menyediakan dana khusus untuk operasi dan pembinaan infrastruktur NAIRR. Pelan pembinaan itu bercadang untuk memohon pembiayaan AS$2.6 bilion dalam tempoh enam tahun, yang mana AS$2.25 bilion akan digunakan untuk membeli kuasa pengkomputeran platform, alatan perisian dan sumber data daripada pembekal perkhidmatan Perbelanjaan harian organisasi operasi ialah AS$370 juta, dan tambahan AS$30 juta akan digunakan untuk operasi infrastruktur. Semua agensi persekutuan yang terlibat dalam penyelidikan dan pembangunan kecerdasan buatan harus mengambil bahagian dalam pengurusan projek NAIRR. Pelaburan R&D oleh jabatan persekutuan dalam bidang kecerdasan buatan masih boleh dibeli dan dibangunkan oleh setiap agensi secara bersendirian atau secara kerjasama, tetapi ia harus diurus dan disediakan melalui infrastruktur NAIRR.
Yang ketiga ialah membina infrastruktur NAIRR secara berperingkat, mengembangkan sumber pengkomputeran mengikut keperluan, dan menggalakkan pengagregatan sumber data. Pembinaan platform dibahagikan kepada empat peringkat: permulaan projek, pembinaan, operasi percubaan dan operasi berterusan. Fasa operasi percubaan akan dapat menyokong 50,000 pengguna dan boleh mengagregat serta menggunakan data agensi persekutuan sedia ada dan data agensi swasta. Selepas operasi yang stabil, ia akan menyokong 150,000 pengguna dan mewujudkan komuniti kerjasama sumber data yang lebih luas. NAIRR akan membangunkan sumber data untuk memudahkan penggunaan data dengan merumuskan piawaian pengagregatan data, pembangunan koperasi data, dan menyediakan perkhidmatan carian data.
Di bawah situasi baharu, kepentingan membina sumber penyelidikan asas untuk kecerdasan buatan telah menjadi semakin menonjol
Pada masa ini, teknologi baharu dan aplikasi kecerdasan buatan sentiasa muncul Penyelidikan dan latihan generasi baharu model kecerdasan buatan besar yang diwakili oleh model bahasa besar ChatGPT memerlukan sokongan sumber pengkomputeran dan sumber data berskala besar. satu pelaburan R&D telah meningkat dengan ketara. Ambang platform kuasa pengkomputeran untuk latihan model kecerdasan buatan yang besar adalah sangat tinggi, dan institusi biasa tidak mampu membayar perbelanjaan R&D dan perbelanjaan operasi yang besar. Penyelidikan OpenAI menunjukkan bahawa kuasa pengkomputeran yang diperlukan untuk melatih model AI telah meningkat secara eksponen Dari 2012 hingga 2018, kuasa pengkomputeran yang digunakan dalam latihan model AI meningkat sebanyak 300,000 kali. Kuasa pengkomputeran yang diperlukan untuk melatih GPT3 mencapai 3640pfsday (iaitu, kecekapan 1PetaFLOP/s berjalan selama 3640 hari), dan kos latihan dijangka mencecah AS$1.4 juta setiap kali Sesetengah organisasi menganggarkan bahawa kos pelaburan awal ChatGPT adalah kira-kira AS $800 juta.
Dari segi set data kecerdasan buatan, dengan penyelidikan dan pembangunan model pra-latihan yang besar, saiz set data yang diperlukan untuk latihan telah meningkat dengan ketara Saiz data telah meningkat daripada berjuta-juta atau berpuluh-puluh juta dalam melepasi ratusan juta. Set data semasa yang digunakan dalam latihan model besar terutamanya datang dari Internet, termasuk pangkalan data seperti Wikipedia, tapak rangkaian sosial, jurnal awam, buku, kertas kerja dan kod. Beberapa kajian telah menunjukkan bahawa "data latihan akan menjadi salah satu kekangan terbesar kepada perindustrian model besar. Dari perspektif yang lebih mendalam, model besar masih mempunyai pelbagai isu tadbir urus dari segi data latihan, seperti pengumpulan data dan pelabelan iaitu masa -memakan, susah payah dan mahal, dan kualiti data adalah sukar Terdapat jaminan yang tidak mencukupi dan kepelbagaian data untuk menampung "ekor panjang" dan kes tepi, dan terdapat isu seperti perlindungan privasi dan berat sebelah data dalam pemerolehan, penggunaan dan perkongsian khusus data. "Para sarjana asing percaya bahawa skala keseluruhan data bahasa berkembang pada kadar 7%. ; Pertumbuhan data bahasa berkualiti tinggi tertakluk kepada faktor seperti saiz populasi dan pembangunan ekonomi, berkembang pada kadar 4% kepada 5%. Data berkualiti tinggi untuk melatih model bahasa besar akan "habis" menjelang 2027.
Ringkasan
Kuasa pengkomputeran dan sumber data ialah elemen sokongan asas untuk penyelidikan teknologi kecerdasan buatan. Apabila kecerdasan buatan memasuki era "model besar", kuasa pengkomputeran dan keupayaan data telah menjadi faktor pengehad untuk penyelidikan dan latihan model algoritma. Infrastruktur NAIRR yang sedang dibina di Amerika Syarikat adalah kondusif untuk menyelesaikan cabaran baharu yang dihadapi oleh inovasi semasa dan pembangunan teknologi kecerdasan buatan, dan mempunyai kepentingan rujukan tertentu untuk negara saya harus mengukuhkan perancangan dan penyelarasan keseluruhan, mempercepatkan pembinaan infrastruktur pengkomputeran dan sumber asas data, dan membangunkan pasaran elemen data , menggalakkan pengumpulan dan peredaran sumber data, dan menggalakkan penyelidikan teknologi asas dan inovasi aplikasi kecerdasan buatan.
TAMAT
Pengarang: Lu Yapeng, Wang Weiguo, Pusat Penyelidikan Data Akademi Teknologi Maklumat dan Komunikasi China
Editor/Pemformat: Gai Beibei
Pengulas: Shu Wenqiong
Penerbit: Liu Qicheng
Suka dan tontonan semua ada di sini
Atas ialah kandungan terperinci Amerika Syarikat telah membelanjakan 2.6 bilion dolar AS untuk kecerdasan buatan...Ia dijangka menyiapkan pembinaan NAIRR dalam tempoh 6 tahun. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI