
Rumah >pangkalan data >Redis >Bagaimana untuk menyelesaikan masalah konsistensi dua tulis antara Redis dan MySQL
Bagaimana untuk menyelesaikan masalah konsistensi dua tulis antara Redis dan MySQL

- 王林ke hadapan
- 2023-06-03 12:28:101440semak imbas
Ketekalan tulis dua kali antara Redis dan MySQL merujuk kepada senario di mana cache dan pangkalan data digunakan untuk menyimpan data pada masa yang sama (terutamanya apabila terdapat konkurensi tinggi) , Bagaimana untuk memastikan ketekalan data antara kedua-duanya (kandungan adalah sama atau sedekat mungkin) .
Proses perniagaan biasa:
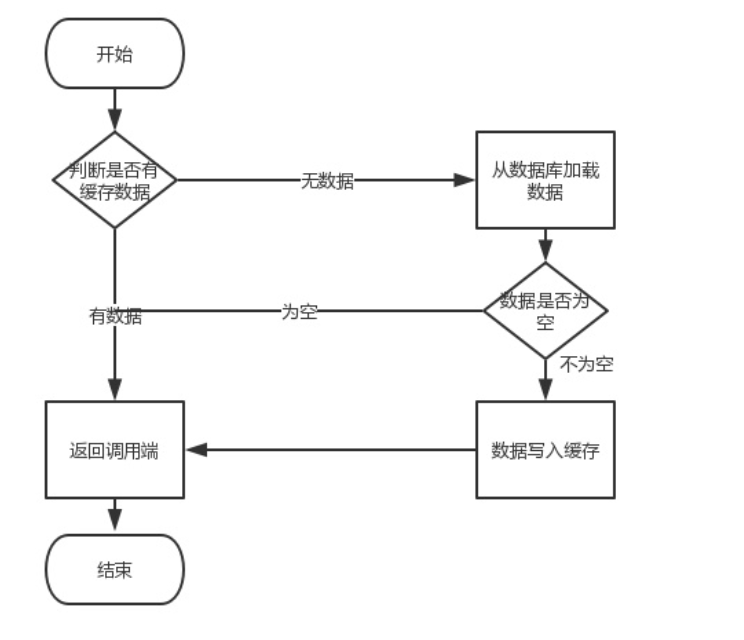
Membaca bukan masalah, masalahnya ialah operasi tulis (kemas kini). Beberapa masalah mungkin timbul pada masa ini Kami perlu mengemas kini pangkalan data terlebih dahulu dan kemudian melakukan operasi caching. Apabila berurusan dengan cache, anda harus mempertimbangkan sama ada untuk mengemas kini cache atau memadam cache, atau mengemas kini cache dahulu dan kemudian mengemas kini pangkalan data
Untuk meringkaskan, sekiranya anda mengendalikan cache dahulu dan kemudian pangkalan data, atau mengendalikan pangkalan data dahulu dan kemudian cache?
Mari teruskan dengan soalan ini.
Pertama sekali, mari bercakap tentang cache operasi, yang merangkumi dua jenis: kemas kini cache dan padam cache Bagaimana untuk memilih?
Kemas kini cache? Padamkan cache?
Anggapkan bahawa pangkalan data dikemas kini terlebih dahulu (kerana mengendalikan cache dahulu dan kemudian mengendalikan pangkalan data adalah masalah besar, yang akan dibincangkan kemudian)
-
Kemas kini cache
Kemas kini pangkalan data dahulu, kemudian kemas kini cache.
Apabila dua permintaan mengubah suai data yang sama pada masa yang sama, data lama mungkin wujud dalam cache kerana susunannya mungkin diterbalikkan. Permintaan baca seterusnya akan membaca data lama, dan hanya apabila cache tidak sah boleh nilai yang betul diperoleh daripada pangkalan data.
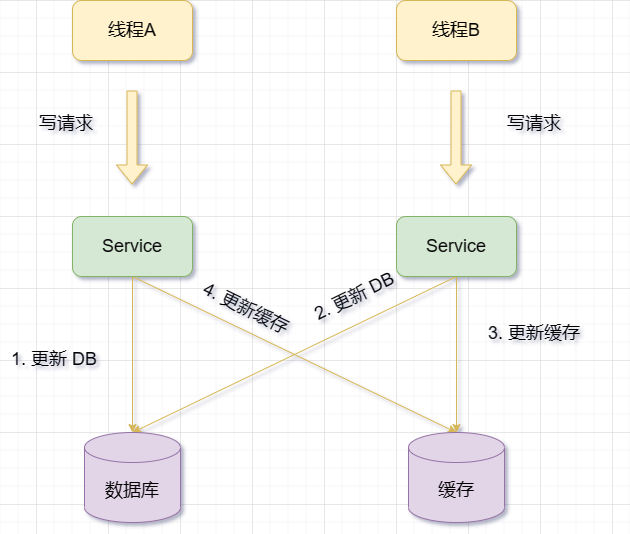
Padam cache
Kemas kini pangkalan data dahulu, kemudian padamkan cache .
Apabila cache gagal, permintaan B boleh menanyakan data daripada pangkalan data dan mendapatkan nilai lama. Pada masa ini, A diminta untuk mengemas kini pangkalan data, menulis nilai baharu pada pangkalan data dan memadam cache. Permintaan B menulis nilai lama ke dalam cache, mengakibatkan data kotor
Dapat dilihat dari di atas bahawa keperluan untuk data kotor adalah lebih daripada keperluan untuk mengemas kini cache, dan yang berikut mesti dipenuhi Beberapa syarat:
Pembatalan cache
Permintaan baca + tulis request concurrency
-
Mengemas kini pangkalan data + memadamkan cache mengambil masa kurang daripada membaca pangkalan data + menulis cache
Dua yang pertama sangat memuaskan hati.
Pangkalan data biasanya dikunci semasa mengemas kini, dan operasi baca adalah lebih pantas daripada operasi tulis, jadi kebarangkalian titik ketiga berlaku adalah sangat rendah (sudah tentu ia mungkin berlaku)
Nota: Saya tidak begitu memahami perkara ini, secara ringkasnya, kebarangkalian kejadian adalah rendah, tetapi jika terdapat kelewatan rangkaian, dsb., bukankah ia juga akan berlaku? Saya harap seseorang yang mempunyai niat yang baik dapat menyelesaikan kekeliruan, tetapi saya tidak memahaminya.
Oleh itu, apabila memilih untuk memadam cache, anda juga perlu menggabungkan teknologi lain untuk mengoptimumkan prestasi dan konsistensi. Contohnya:
Gunakan baris gilir mesej untuk memadam atau mengemas kini cache secara tidak segerak untuk mengelak daripada menyekat urutan utama atau kehilangan mesej.
Gunakan pemadaman berganda tertunda untuk meningkatkan kadar kejayaan pemadaman dan mengurangkan tetingkap masa yang tidak konsisten. Iaitu, cache dikosongkan sekali sejurus selepas pangkalan data dikemas kini, dan kemudian dikosongkan semula selepas selang masa tertentu.
Perbandingan
Dalam mengemas kini cache, cache dikemas kini setiap kali, tetapi data dalam cache mungkin tidak dibaca serta-merta oleh Mengambil akan menyebabkan banyak data yang jarang diakses disimpan dalam cache, yang membazirkan sumber cache. Dan dalam banyak kes, nilai yang ditulis pada cache tidak sepadan satu-dengan-satu dengan nilai dalam pangkalan data Kemungkinan besar pangkalan data pertama kali ditanya, dan kemudian nilai diperoleh melalui satu siri "pengiraan". sebelum nilai ditulis ke dalam cache.
Dapat dilihat bahawa skim kemas kini cache ini bukan sahaja mempunyai penggunaan cache yang rendah, tetapi juga menyebabkan pembaziran prestasi mesin. Jadi kami biasanya mempertimbangkan padam cache
kemas kini cache dahulu dan kemudian kemas kini pangkalan data
Apabila mengemas kini data, tulis data baharu ke dalam cache dahulu (Redis ) , dan kemudian tulis data baharu ke dalam pangkalan data (MySQL)
Tetapi ada masalah:
Kemas kini cache ialah berjaya, tetapi kemas kini pangkalan data gagal, mengakibatkan ketidakkonsistenan data
Contoh: Pengguna mengubah suai nama panggilannya dahulu Sistem menulis nama panggilan baharu ke dalam cache dan kemudian mengemas kini pangkalan data. Walau bagaimanapun, semasa proses mengemas kini pangkalan data, situasi tidak normal seperti kegagalan rangkaian atau masa henti pangkalan data berlaku, menyebabkan nama panggilan dalam pangkalan data tidak diubah suai. Dengan cara ini, nama panggilan dalam cache akan tidak konsisten dengan nama panggilan dalam pangkalan data.
Kemas kini cache berjaya, tetapi kemas kini pangkalan data ditangguhkan, menyebabkan permintaan lain membaca data lama
Contoh: Pengguna membuat pesanan untuk produk Sistem mula-mula menulis status pesanan ke cache dan kemudian mengemas kini pangkalan data. Walau bagaimanapun, semasa proses mengemas kini pangkalan data, disebabkan oleh konkurensi yang besar atau sebab lain, kelajuan penulisan pangkalan data adalah lebih perlahan daripada kelajuan penulisan cache. Dengan cara ini, permintaan lain akan membaca status pesanan sebagai berbayar daripada cache, dan membaca status pesanan sebagai tidak dibayar daripada pangkalan data.
Kemas kini cache berjaya, tetapi permintaan lain menanyakan cache dan pangkalan data sebelum kemas kini pangkalan data, dan data lama ditulis semula ke cache, menimpa data baharu
Contoh: Pengguna A mengubah suai avatarnya dan memuat naiknya ke pelayan. Sistem mula-mula menulis alamat avatar baharu ke dalam cache dan mengembalikannya kepada pengguna A untuk paparan. Kemudian kemas kini alamat avatar baharu ke pangkalan data. Tetapi semasa proses ini, pengguna B melawat halaman utama peribadi pengguna A dan membaca alamat avatar baharu daripada cache. Ketidaksahihan cache mungkin disebabkan oleh dasar tamat tempoh cache atau sebab lain, seperti memulakan semula operasi, menyebabkan cache dikosongkan atau tamat tempoh. Pada masa ini, pengguna B melawat halaman utama peribadi pengguna A sekali lagi, membaca alamat avatar lama daripada pangkalan data dan menulisnya kembali ke cache. Ini boleh menyebabkan alamat avatar dalam cache tidak sepadan dengan alamat dalam pangkalan data.
Banyak yang telah diperkatakan di atas, tetapi ringkasannya ialah kemas kini cache berjaya, tetapi pangkalan data tidak dikemas kini (kemas kini gagal) , mengakibatkan cache menyimpan nilai terkini dan inventori data yang menyimpan nilai lama. Jika cache gagal, nilai lama dalam pangkalan data akan diperolehi.
Saya juga keliru kemudiannya Memandangkan masalah itu disebabkan oleh kegagalan kemas kini pangkalan data, bolehkah saya menyelesaikan masalah ketidakkonsistenan data dengan hanya memastikan kemas kini pangkalan data berjaya? , Teruskan mencuba semula untuk mengemas kini pangkalan data sehingga kemas kini pangkalan data selesai.
Kemudian saya mendapati bahawa saya terlalu naif, dan terdapat banyak masalah, seperti:
Jika sebab kegagalan kemas kini pangkalan data ialah masa henti pangkalan data atau kegagalan rangkaian , kemudian anda teruskan Mencuba semula untuk mengemas kini pangkalan data boleh menyebabkan lebih banyak tekanan dan kelewatan, atau bahkan menyukarkan pemulihan pangkalan data.
Jika kemas kini pangkalan data gagal disebabkan oleh konflik data atau ralat logik perniagaan, maka percubaan berterusan anda untuk mengemas kini pangkalan data boleh menyebabkan kehilangan data atau kekeliruan data, malah menjejaskan data pengguna lain .
Jika anda terus mencuba semula untuk mengemas kini pangkalan data, maka anda perlu mempertimbangkan cara untuk memastikan ketidakupayaan dan susunan percubaan semula, dan cara mengendalikan pengecualian yang berlaku semasa percubaan semula.
Jadi, kaedah ini bukanlah penyelesaian yang baik.
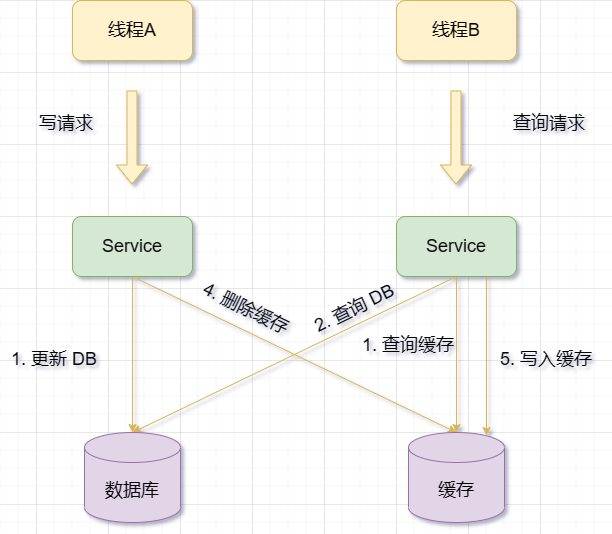
Kemas kini pangkalan data dahulu, kemudian kemas kini cache
Apabila terdapat operasi kemas kini, kemas kini data pangkalan data dahulu, dan kemudian kemas kini data cache yang sepadan
Walau bagaimanapun, penyelesaian ini juga mempunyai beberapa masalah dan risiko, seperti:
Jika pangkalan data berjaya dikemas kini, tetapi kemas kini cache gagal, data lama akan disimpan dalam cache. Sudah ada data baru dalam pangkalan data, iaitu data kotor.
Jika permintaan lain menanyakan data yang sama antara mengemas kini pangkalan data dan mengemas kini cache, dan cache didapati wujud, data lama akan dibaca daripada cache. Ini juga akan menyebabkan ketidakkonsistenan antara cache dan pangkalan data.
Oleh itu, apabila menggunakan operasi cache kemas kini, tidak kira siapa yang datang dahulu, jika pengecualian berlaku pada yang terakhir, ia akan memberi kesan kepada perniagaan . (Masih gambar di atas)
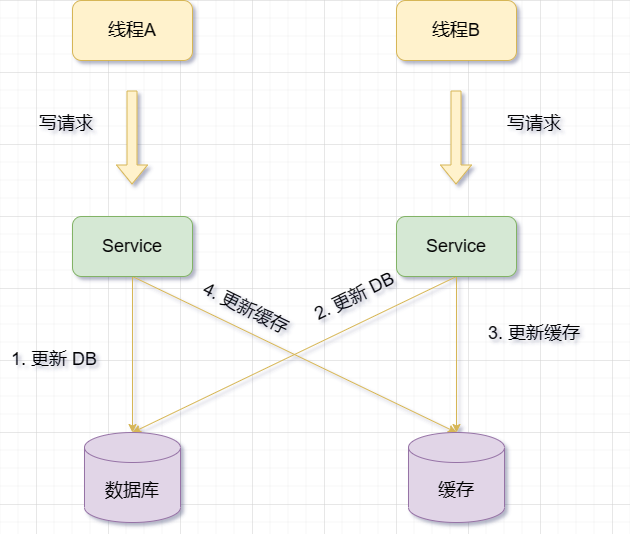
Jadi bagaimana untuk mengendalikan pengecualian untuk memastikan ketekalan data
Sumber daripada masalah ini disebabkan oleh konkurensi berbilang benang, jadi kaedah paling mudah ialah menambah kunci (kunci teragih). Jika dua utas ingin mengubah suai data yang sama, setiap utas mesti memohon kunci yang diedarkan sebelum membuat perubahan Hanya utas yang telah memperoleh kunci dibenarkan untuk mengemas kini pangkalan data dan cache tunggu percubaan semula seterusnya. Sebab untuk ini adalah untuk mengehadkan hanya satu utas kepada data operasi dan cache untuk mengelakkan isu konkurensi.
Tetapi penguncian memakan masa dan intensif buruh, jadi pastinya tidak digalakkan. Selain itu, setiap kali cache dikemas kini, data dalam cache mungkin tidak dibaca serta-merta Ini akan menyebabkan banyak data yang jarang diakses disimpan dalam cache, yang membazirkan sumber cache. Dan dalam banyak kes, nilai yang ditulis pada cache tidak sepadan satu-dengan-satu dengan nilai dalam pangkalan data Kemungkinan besar pangkalan data pertama kali ditanya, dan kemudian nilai diperoleh melalui satu siri "pengiraan". sebelum nilai ditulis ke dalam cache.
Ia boleh dilihat bahawa penyelesaian mengemas kini pangkalan data + mengemas kini cache ini bukan sahaja mempunyai penggunaan cache yang rendah, tetapi juga menyebabkan pembaziran prestasi mesin.
Jadi pada masa ini kita perlu mempertimbangkan pilihan lain: Padam cache
Padam cache dahulu dan kemudian kemas kini pangkalan data
Apabila terdapat operasi kemas kini, padamkan data cache yang sepadan dahulu, dan kemudian kemas kini data pangkalan data
Walau bagaimanapun, penyelesaian ini juga mempunyai beberapa masalah dan risiko, seperti:
Jika kemas kini pangkalan data gagal selepas memadamkan cache, cache akan hilang dan data perlu dimuat semula daripada pangkalan data semasa pertanyaan seterusnya, yang meningkatkan tekanan pangkalan data dan masa tindak balas.
Jika antara memadam cache dan mengemas kini pangkalan data, terdapat permintaan lain untuk data yang sama dan didapati bahawa cache tidak wujud, maka data lama akan dibaca dari pangkalan data dan Tulis ke cache. Ini akan menyebabkan ketidakkonsistenan antara cache dan pangkalan data.
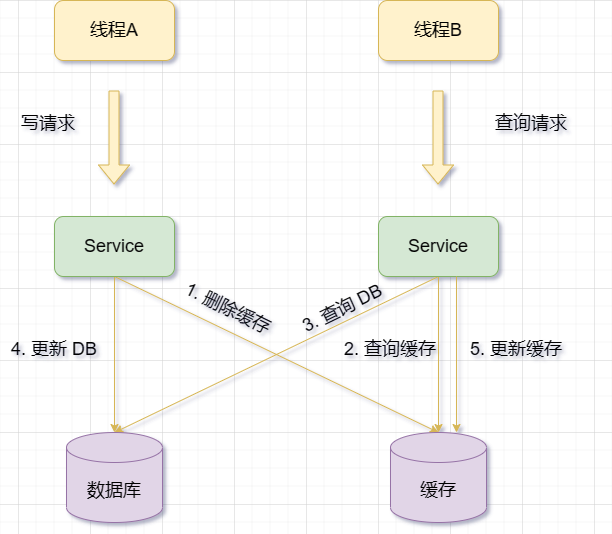
Kemas kini pangkalan data dahulu, kemudian padamkan cache
Apabila terdapat operasi kemas kini, kemas kini data pangkalan data pertama, dan kemudian Padam cache
Saya sebenarnya mengatakannya di atas, biar saya ulangi sekali lagi
Apabila cache gagal, minta B boleh menanyakan data daripada pangkalan data dan dapatkan nilai lama . Pada masa ini, A diminta untuk mengemas kini pangkalan data, menulis nilai baharu pada pangkalan data dan memadam cache. Permintaan B menulis nilai lama ke dalam cache, mengakibatkan data kotor
Dapat dilihat dari di atas bahawa keperluan untuk data kotor adalah lebih daripada keperluan untuk mengemas kini cache, dan yang berikut mesti dipenuhi Beberapa syarat:
Pembatalan cache
Permintaan baca + tulis request concurrency
-
Mengemas kini pangkalan data + memadamkan cache mengambil masa kurang daripada membaca pangkalan data + menulis cache
Dua yang pertama sangat memuaskan hati.
Pangkalan data secara amnya dikunci semasa mengemas kini, dan operasi baca adalah lebih pantas daripada operasi tulis, jadi kebarangkalian titik ketiga berlaku adalah sangat rendah
Penyelesaian yang lebih sesuai untuk dua kali ganda. -masalah tulis Penyelesaiannya ialah memadam cache selepas mengemas kini pangkalan data Sudah tentu, situasi khusus memerlukan analisis khusus dan tidak boleh digeneralisasikan.
Terangkan masalah yang akan berlaku selepas operasi ini, jadi bagaimana untuk mengelakkan masalah ini?
Padam cache dahulu dan kemudian kemas kini pangkalan data, kemudian gunakan urutan tak segerak atau baris gilir mesej untuk membina semula cache.
Kemas kini pangkalan data dahulu dan kemudian padamkan cache, dan tetapkan masa tamat tempoh yang munasabah untuk memastikan keberkesanan cache.
Gunakan kunci teragih atau kunci optimistik untuk mengawal akses serentak dan pastikan hanya satu permintaan boleh mengendalikan cache dan pangkalan data pada satu masa
&hellip ; …
Berikut ialah beberapa kaedah biasa untuk memastikan konsistensi penulisan dua kali
Penyelesaian
Cuba lagi
Sebagai yang disebutkan di atas, apabila langkah kedua gagal, saya akan cuba lagi dan cuba memperbaikinya sebanyak mungkin, tetapi kos mencuba semula adalah terlalu tinggi, jadi saya tidak akan mengulangi apa yang saya katakan di atas.
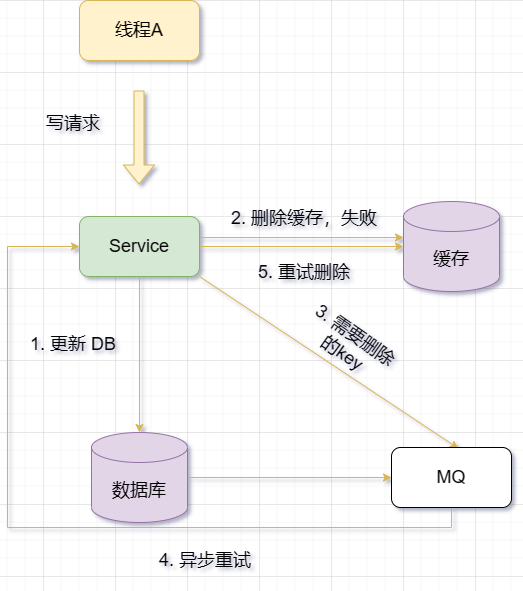
2. Cuba semula tak segerak
Memandangkan kaedah cuba semula mengambil sumber, saya akan melakukannya secara tidak segerak. Apabila memadam atau mengemas kini cache, jika operasi gagal, ralat tidak dikembalikan dengan serta-merta, sebaliknya, operasi cuba semula cache dicetuskan melalui beberapa mekanisme (seperti baris gilir mesej, tugas berjadual, langganan binlog, dll.). Walaupun kaedah ini boleh mengelakkan kehilangan prestasi dan masalah sekatan apabila mencuba semula cache secara serentak, ia akan memanjangkan masa apabila data cache dan pangkalan data tidak konsisten.
2.1 Gunakan baris gilir mesej untuk melaksanakan percubaan semula
Baris gilir mesej memastikan kebolehpercayaan: Mesej yang ditulis pada baris gilir tidak akan hilang sehingga ia berjaya digunakan . (Jangan risau tentang memulakan semula projek)
Baris gilir mesej memastikan penghantaran mesej berjaya: Bahagian hiliran menarik mesej daripada baris gilir dan memadam mesej hanya selepas penggunaan berjaya, jika tidak, ia akan Teruskan menyampaikan mesej kepada pengguna (selaras dengan keperluan cuba semula kami)

Gunakan baris gilir mesej untuk mencuba semula secara tak segerak Situasi caching bermakna apabila maklumat berubah, pangkalan data dikemas kini dahulu, dan kemudian cache dipadamkan Jika pemadaman berjaya, semua orang gembira Jika pemadaman gagal, kuncinya yang perlu dipadam dihantar ke baris gilir mesej. Di samping itu, urutan pengguna akan mendapatkan semula kunci untuk dipadamkan daripada baris gilir mesej dan memadam atau mengemas kini cache Redis berdasarkan kekunci. Jika operasi gagal, ia dihantar semula ke baris gilir mesej dan dicuba semula.
Nota: Anda juga boleh menghantarnya terus ke baris gilir mesej tanpa cuba memadamkannya terlebih dahulu, supaya mesej itu beratur
Sebagai contoh, jika ada ialah jadual maklumat pengguna, Ingin menyimpan maklumat pengguna dalam Redis. Berikut ialah langkah-langkah yang boleh dilakukan, mengambil penyelesaian menggunakan caching percubaan semula tak segerak barisan mesej sebagai contoh:
Apabila maklumat pengguna berubah, kemas kini pangkalan data dahulu dan kembalikan hasil yang berjaya ke bahagian hadapan.
Cuba padamkan cache Jika ia berjaya, operasi akan tamat Jika ia gagal, mesej akan dihasilkan untuk operasi memadam atau mengemas kini cache (contohnya, termasuk. kunci dan jenis operasi) dan dihantar ke baris gilir mesej ( Seperti menggunakan Kafka atau RabbitMQ).
Satu lagi urutan pengguna melanggan dan mendapatkan mesej ini daripada baris gilir mesej dan memadam atau mengemas kini maklumat yang sepadan dalam Redis berdasarkan kandungan mesej.
Jika cache berjaya dipadamkan atau dikemas kini, mesej akan dialih keluar (dibuang) daripada baris gilir mesej untuk mengelakkan operasi berulang.
Jika pemadaman atau pengemaskinian cache gagal, laksanakan strategi kegagalan, seperti menetapkan masa tunda atau had cuba semula, dan kemudian hantar semula mesej ke baris gilir mesej untuk cuba semula.
Jika percubaan semula gagal lebih daripada beberapa kali, mesej ralat akan dihantar ke lapisan perniagaan dan dilog.
2.2 Binlog melaksanakan pemadaman cuba semula tak segerak
Idea asas menggunakan binlog untuk mencapai konsistensi ialah menggunakan log binlog untuk merekodkan operasi perubahan pangkalan data, dan kemudian gunakan utama Segerakkan atau pulihkan data daripada replikasi atau sandaran tambahan.
Sebagai contoh, jika kita mempunyai pangkalan data induk dan pangkalan data hamba, kita boleh mendayakan binlog pada pangkalan data induk dan menetapkan pangkalan data hamba sebagai nod replikasinya. Dengan cara ini, apabila sebarang operasi perubahan berlaku pada pangkalan data induk, ia akan menghantar log binlog yang sepadan ke pangkalan data hamba, dan pangkalan data hamba akan melakukan operasi yang sama berdasarkan log binlog untuk memastikan konsistensi data.
Selain itu, jika kita perlu memulihkan data sebelum masa tertentu, kita juga boleh menggunakan log binlog untuk mencapainya. Pertama, kita perlu mencari fail sandaran penuh terbaharu sebelum titik masa yang sepadan dan memulihkannya ke pangkalan data sasaran. Kemudian, kita perlu mencari semua fail sandaran tambahan (iaitu fail log binlog) sebelum titik masa yang sepadan dan menggunakannya pada pangkalan data sasaran mengikut urutan. Dengan cara ini, kita boleh memulihkan keadaan data sebelum titik masa sasaran.
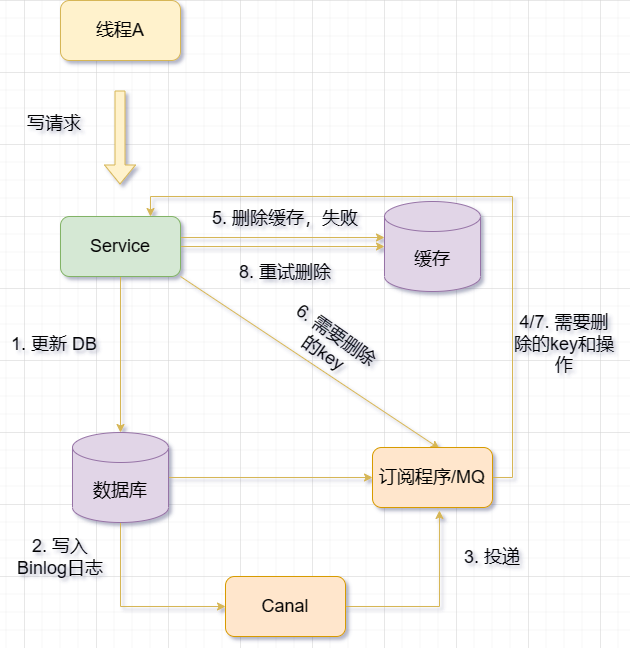
Gunakan Binlog untuk mengemas kini/memadam cache Redis dalam masa nyata. Menggunakan Canal, perkhidmatan yang bertanggungjawab untuk mengemas kini cache menyamar sebagai nod hamba MySQL, menerima Binlog daripada MySQL, menghuraikan Binlog, mendapatkan maklumat perubahan data masa nyata, dan kemudian mengemas kini/memadam cache Redis berdasarkan maklumat perubahan
Strategi MQ+Canal, menghantar terus data Binlog yang diterima oleh Canal Server kepada MQ untuk penyahgandingan, dan menggunakan MQ untuk menggunakan log Binlog secara tidak segerak untuk penyegerakan data; >
Log binlog MySQL merekodkan operasi perubahan pangkalan data, seperti sisipan, kemas kini, pemadaman, dsb. Log binlog mempunyai dua fungsi utama, satu ialah replikasi tuan-hamba, dan satu lagi ialah sandaran tambahan.
Replikasi induk-hamba ialah proses mencapai penyegerakan data dengan menyegerakkan data daripada pangkalan data induk kepada satu atau lebih pangkalan data hamba. Pangkalan data induk akan menghantar log binlog sendiri ke pangkalan data hamba, dan pangkalan data hamba akan melakukan operasi yang sama berdasarkan log binlog untuk memastikan konsistensi data. Dengan melaksanakan pendekatan ini, ketersediaan dan kebolehpercayaan data boleh dipertingkatkan, dan pengimbangan beban dan pemulihan kegagalan boleh dicapai. Sandaran tambahan merujuk kepada sandaran tetap bagi perubahan pangkalan data berdasarkan sandaran penuh. Sandaran penuh merujuk kepada menyandarkan sepenuhnya seluruh data pangkalan data ke fail. Tujuannya adalah untuk menggabungkan perubahan terkini dalam pangkalan data dengan sandaran sebelumnya untuk memulihkan kepada keadaan terkini. Melakukannya bukan sahaja dapat menjimatkan ruang dan masa yang diduduki oleh sandaran, tetapi juga memudahkan untuk memulihkan data ke mana-mana masa.
3. Pemadaman berganda tertundaFokus kami adalah untuk mengemas kini pangkalan data dahulu dan kemudian memadamkan cache. Bagaimana jika saya ingin memadam cache dahulu dan kemudian mengemas kini pangkalan data? Melihat kembali apa yang saya katakan sebelum ini, padamkan cache dahulu dan kemudian kemas kini pangkalan data Ia akan menyebabkan nilai lama menimpa cache Itu mudah untuk dikendalikan. Pemadaman berganda tertunda Inilah prinsipnya: Padam cache dahuluPada ketika ini, kita boleh membuat kesimpulan bahawa untuk memastikan ketekalan pangkalan data dan cache, adalah disyorkan untuk menggunakan penyelesaian "kemas kini pangkalan data dahulu, kemudian padam cache" dan bekerjasama. dengan cara "Baris Gilir Mesej" atau "Langgan Log Perubahan" ” untuk melakukannya.
- dan kemudian kemas kini pangkalan data
- Tidur untuk tempoh masa (ditentukan mengikut keadaan sistem)
- Padam cache sekali lagi
- Dalam untuk mengelakkannya selepas mengemas kini pangkalan data, utas lain akan membaca Langkah ini diambil dengan tamat tempoh data cache dan menulisnya kembali ke cache yang mengakibatkan ketidakkonsistenan data.
- Thread B mahu Kurangkan 50 mata untuk pengguna
Jika strategi pemadaman berganda tertunda digunakan, proses pelaksanaan benang A dan B mungkin seperti berikut:
Benang A terlebih dahulu memadam maklumat pengguna dalam cache
Thread A kemudian membaca maklumat pengguna daripada pangkalan data dan mendapati bahawa mata pengguna ialah 1000
Thread A menambah 100 kepada mata pengguna, yang menjadi 1100 dan mengemas kini kepada pangkalan data
Thread A tidur selama 5 saat (dengan mengandaikan masa ini cukup untuk pangkalan data menyegerak)
Thread A memadamkan cache sekali lagi Maklumat pengguna dalam
Thread B terlebih dahulu memadam maklumat pengguna dalam cache
Thread B kemudian membaca maklumat pengguna daripada pangkalan data dan mencari pengguna Matanya ialah 1100 (kerana benang A telah dikemas kini)
Benang B menolak 50 daripada mata pengguna kepada 1050, dan mengemas kininya ke pangkalan data
-
Thread B tidur selama 5 saat (dengan andaian masa ini sudah cukup untuk pangkalan data menyegerak)
Thread B memadamkan pengguna maklumat dalam cache sekali lagi
Keputusan akhir ialah: mata pengguna dalam pangkalan data ialah 1050, dan tiada maklumat pengguna dalam cache. Pada kali seterusnya maklumat pengguna ditanya, ia akan dibaca daripada cache terlebih dahulu, bukannya diperoleh daripada pangkalan data dan ditulis ke cache. Ini memastikan ketekalan data.
Pemadaman berganda tertunda sesuai untuk senario serentak tinggi, terutamanya untuk senario dengan operasi pengubahsuaian data yang kerap dan operasi pertanyaan yang sedikit. Ini boleh mengurangkan tekanan pada pangkalan data dan meningkatkan prestasi sambil memastikan ketekalan data akhirnya. Pemadaman berganda tertunda juga sesuai untuk senario di mana pangkalan data mempunyai kelewatan penyegerakan induk-hamba, kerana ia boleh mengelakkan membaca data cache lama dan menulisnya kembali ke cache selepas mengemas kini pangkalan data dan sebelum penyegerakan selesai daripada pangkalan data hamba.
Nota: Masa tidur ini = masa yang diperlukan untuk membaca data logik perniagaan + beberapa ratus milisaat. Untuk memastikan permintaan baca tamat, permintaan tulis boleh memadamkan data kotor cache yang mungkin dibawa oleh permintaan baca.
Atas ialah kandungan terperinci Bagaimana untuk menyelesaikan masalah konsistensi dua tulis antara Redis dan MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!