
Rumah >pangkalan data >tutorial mysql >Apakah perbezaan antara on, in, as, dan where dalam Mysql?
Apakah perbezaan antara on, in, as, dan where dalam Mysql?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-03 11:37:201864semak imbas
Perbezaan antara Mysql on, in, as, dan where
Jawapan: Di mana keadaan pertanyaan, on digunakan semasa menyambung secara dalaman dan luaran, seperti yang digunakan sebagai alias, dalam pertanyaan sama ada nilai tertentu adalah dalam keadaan tertentu
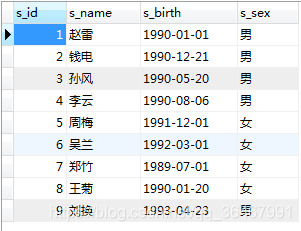
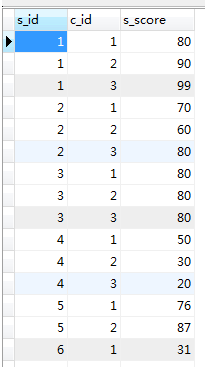
Cipta 2 jadual: pelajar, skor
pelajar:
skor :
di mana
SELECT * FROM student WHERE s_sex='男'
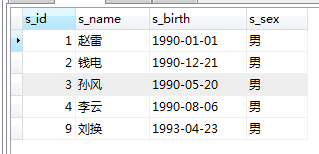
Contohnya: pada
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id;
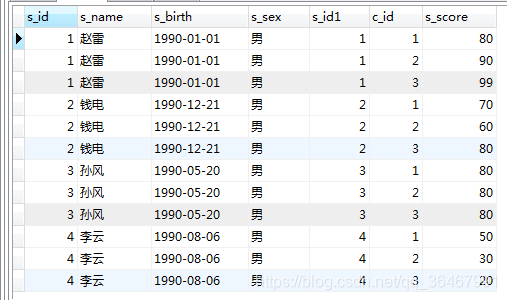
pada dan di mana kombinasi:
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id WHERE s_name='赵雷'
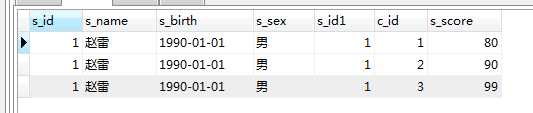
Contohnya : dalam
SELECT * FROM score WHERE s_id in (SELECT s_id FROM student WHERE s_name='赵雷')
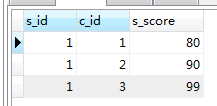
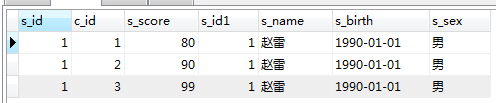
sebagai
select * from score as a LEFT JOIN student as b on a.s_id=b.s_id where s_name='赵雷'
Penyelesaian masalah pernyataan MySQL
1. Masalah penapisan data gabungan kiri
Keadaan selepas on hanya boleh menapis jadual di sebelah kanan gabungan kiri Jika jadual kiri tidak boleh sepadan dengan data jadual kanan, nol akan dipaparkan pada kedudukan jadual kanan asal Data jadual di sebelah kiri gabungan kiri tidak akan dikekang Hidup Selepas syarat terakhir ditambahkan ke tempat, semua data akan ditapis.
2. Masalah penapisan berulang dan penggunaan data yang sama
with <name> as()
Anda boleh menggunakan sebagai untuk menjana jadual sementara dalam mysql,
with arc as(
select id,arc.title,update_time,is_top,cId,pid,name_id from article arc where is_del = 0
)
select * from arcdengan...as hanya berlangsung untuk satu pelaksanaan sql, dan ia tidak lagi wujud selepas pelaksanaan Menurut contoh, kita sepatutnya memproses jadual artikel, tetapi bukan semua data dalam jadual adalah apa yang kita perlukan, jadi kita menapis dan menciptanya dahulu Arka jadual sementara, kita akan beroperasi pada arka. Jika ia hanya operasi mudah dalam contoh di atas, tidak perlu menggunakan dengan...as, tetapi apabila kita perlu untuk menyertai atau menyarangkan jadual artikel dengan jadual lain, kita perlu lakukan is_del = beberapa kali 0 penghakiman, pernyataan SQL akhir mungkin sangat kompleks dan terdedah kepada ralat, tetapi menggunakan arka tidak memerlukan penapisan data berulang. Sql dengan...sebagai contoh, terdapat nama_id dalam jadual artikel, tetapi lebih kerap kita mahu menggunakan nama maju dan kemudian gunakannya. Gunakan jadual sementara untuk melaksanakan operasi lain. 3 Isih mengikut medan tertentu dan ambil tiga data terakhir atau tiga data pertama bagi setiap kategori Ini adalah masalah yang agak klasik dan saya hanya tahu satu cara menyelesaikan masalah, tetapi saya akan cuba yang terbaik untuk menjadikannya mudah dan popular. Contoh: select * from (
select cId,title,content(
select count(*)+1 from arc a1 where (a1.cId = a2.cId) and a1.updateTime > a2.updateTime
)updateTimeSort from arc a2
) a3
where updateTimeSort <= 3 order by cId,updateTime descDalam contoh, cId ialah id kategori dan masa kemas kini ialah masa kemas kini Penyelesaian masalah ialah memilih tiga keping data terkini untuk setiap kategori dalam arka , sama seperti halaman utama berita Pilih tiga item berita terkini untuk setiap kategori Menurut data dalam pangkalan data, kita boleh menggunakan pesanan mengikut cId, updateTime desc untuk mengisih data mengikut kategori dan masa kemas kini, tetapi untuk mengambil. kepingan data tertentu untuk setiap kategori, pangkalan data sedia ada tidak boleh berbuat demikian, jadi kami boleh menambah medan sementara. kemas kiniTimeSort Ia mewakili pengisihan setiap sub-item dalam setiap kategori dalam kategori ini Dalam masalah semasa, medan sementara ini harus dikaitkan dengan masa kemas kini medan, yang berdasarkan masa kemas kini untuk setiap sub-. item dalam kategori. Seperti yang ditunjukkan dalam kod sampel, kita boleh mencari dua jadual a1 dan a2 Kedua-duanya adalah alias untuk jadual arka Mereka digabungkan dalam bentuk subkueri, terutamanya a2, untuk mencari kategori dan jumlah dalam jadual a1 Data semasa a2 adalah sama, dan masa kemas kini adalah lebih lewat daripada data semasa a2 Anda boleh melihat count(*)+1, yang bermaksud bilangannya meningkat satu ia dengan satu, hanya apabila sekeping data dikemas kini dalam kategori ia berada. Nilai count(*) ialah 0 pada masa terkini Jika kita menggunakan count(*)+1, kita boleh mengisih data bermula dari 1. Akhirnya, kita hanya perlu memilih data dengan updateTimeSort a1.updateTime > a2.updateTime ditukar kepada a1.updateTime Anda boleh melihat bahawa terdapat satu lagi jadual a3 dalam kod sampel, yang sebenarnya jadual sementara. Kami belajar tentang dengan ..sebagaimana boleh menjana jadual sementara Seperti yang dapat dilihat dari kod ini, jadual sementara juga boleh wujud dalam bentuk lain Dengan... kerana kita hanya menggunakannya apabila sql adalah kompleks Secara umumnya, Kaedah seperti ini boleh membantu kami menyelesaikan banyak masalah, masing-masing mempunyai kelebihan dan kekurangannya sendiri, dan anda harus menggunakannya mengikut situasi.
4、业务逻辑书写位置问题
接触sql多了会发现,sql其实能帮我们解决一定的业务问题,明显的有sql的存储过程和方法,对sql语句的批量处理其实在一定程度上帮我们解决一定的业务问题,但缺点也很明显,当新手接触这个项目时他很难搞清楚某个功能到底是如何实现的,不利于维护。
一般来说我们解决业务是在server层,有时会使用sql解决一些问题,但很少,在sever处理受制于计算机硬件,在数据库处理受制于数据库性能,相比之下,计算机硬件更易于扩展,因此还是不推荐大量使用sql解决问题的。
例如上个问题:根据某个字段排序取每个类别最后三条数据或前三条数据问题,虽然问题基本解决但让存在一些 ‘bug’,例如排序时会产生1、2、3、3、4这种排序,这是因为同个类别内有两条数据更新时间重复了,那我们直观想法(还是要看个人经验值)应该是,既然问题出在数据库,那应该在数据库查询的时候就解决这个问题,但事实上,让数据库去解决并不好解决,数据库的强项在于各种搜索算法,不在于逻辑处理,因此我们就要转移到server层处理,会有不少人陷于这个坑,花费大量时间去找办法让数据库去处理这类问题,但其实就算数据库处理得了,它也不一定有server层处理的效率高,当然如果是为了学习更多东西,这些时间也是值得花的,但是这种解题思路还是要改变下的。将1、2、3、3、4问题交给server处理也就是利用java等高级语言处理这种问题,相信熟用这些语言的开发者解决这些问题都是小case了。
5、查找另一表内和本表相关字段的数量
先复习下知识:用过count函数的人都清楚一旦使用count这类聚合函数,不做其他处理数据就会归为一行数据,但很多时候我们并不期望这样的结果,以此就要想些办法能用聚合函数,也能获取很多数据,我常用的是利用group by分组。
回归问题,现有(现不讨论表是否合理)文章表(id,title,content)有文章id,标题,文章内容三个字段,点赞收藏表(id,arc_id,fav,like)有表id,文章id,收藏字段(0未收藏,1收藏),点赞字段(0未点赞,1点赞),现要查询文章表内每篇文章的点赞收藏数,sql语句:
select art.title,art.content, count(case afl.fav when 1 then 1 end) as collectNum, count(case afl.like when 1 then 1 end) as likeNum from article art left join article_favor_like afl on afl.arc_id = art.id group by afl.arc_id //这是关键
如果没有group by afl.arc_id 后果就是,查出来一行数据,数据还牛头不对马嘴,但通过对文章收藏表中的文章id进行分组就可以针对每个文章id查询数据,这样left join时右表就有每个文章id对相应的收藏数与点赞数,而不是表内所有点赞数和收藏数,最终数据也是我们所需的。
6、关于union的使用
例子:
select id,title,content,1 isArc from arc union select id,name,content,0 isArc from news
使用union进行的是上下整合
被联合的数据列数要求一致
列数相同,数据类型不同会自动进行数据类型转换
联合后的列的名字由联合中第一次出现的列名为依据,即使后续被联合数据有自己的列名也不会使用,在例子中最终列名为:id,title,content,name等列名不会使用,因此使用union一般配合别名使用统一结果。
有时候会区分数据是哪个表的,可以通过附加额外的字段来区别,就像例子中的isArc字段,news表中的isArc可以不写,原因也就是第4条,最终列名由第一次出现的列名决定,后续数据列名有没有都可以。
7、limit的巧用
limit一般用于分页,功能是获取指定区间内的数据,因此我们也可以用它来减少数据库的查询,例子:
select * from arc where id = 12 limit 1
数据库查询由索引还好,没有索引是要遍历数据库的,有些数据经由条件筛选在逻辑上应该是唯一的,使用limit 1可以使数据库查询到该数据时不再搜索,减少数据库搜索次数,但这种方法仅是一种技巧,想大幅度优化sql还要另想办法。
8、update ignore和insert ignore的使用
//标题是唯一索引,'新标题'存在则更新操作不执行 update ignore arc set title = '新标题' //标题是唯一索引,'标题1号'存在则插入操作不执行 insert ignore into arc values(null,'标题1号','文章内容')
有这种需求,数据存在时不执行任何操作,不存在则更新或插入,一个办法是使用ingore,它会忽略数据库报错,而数据库执行原子操作时报错是会回滚的,因此只要我们给数据加上主键或唯一索引,当被更新字段或插入字段与原有数据冲突时会报错,但因为ingore会忽视这种报错,后端也就不会报错,sql也未执行,达到了目的,有人会对报错敏感,其实也没什么,报错也是在检查数据是发现不合理之处给的一个提醒或警告,对数据库无害的。
9、mysql存在更新,不存在则插入
区别于上面那个需求,这个是当插入的数据存在时更新数据,不再是不做任何操作,例子:
//本例子中title不是唯一索引,id是主键 insert into arc values(1,'标题1号','文章内容') on duplicate key update title='标题1号' //若要更新多个字段使用','隔开,例:title='标题1号',content='文章内容'
在例子中,当id为1的数据存在时,更新标题和内容,不存在则插入,如果执行更新操作,未设置新值的字段保持原来的值。
还有一个REPLACE INTO也可以达到这种效果,区别在于,REPLACE INTO更新时是先删除后插入会破坏原有索引,id为3的数据更新时会删除插入id为4的数据,未更新新值的字段设置为默认值或null。
无论是两个中的哪种方式判断数据是否存在的依据都是主键和唯一索引。
Atas ialah kandungan terperinci Apakah perbezaan antara on, in, as, dan where dalam Mysql?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!