
Rumah >pangkalan data >tutorial mysql >Apakah penyelesaian penggunaan seni bina ketersediaan tinggi yang biasa dalam MySQL?
Apakah penyelesaian penggunaan seni bina ketersediaan tinggi yang biasa dalam MySQL?

- 王林ke hadapan
- 2023-06-03 11:05:552462semak imbas
Penyelesaian pengerahan kluster dalam MySQL
Prakata
Mari kita bincangkan tentang penyelesaian penggunaan yang biasa digunakan dalam MySQL.
Replikasi MySQL
MySQL Replication ialah penyelesaian penyegerakan induk-hamba yang disediakan secara rasmi, digunakan untuk menyegerakkan satu tika MySQL ke tika lain. Replikasi telah membuat jaminan penting untuk memastikan keselamatan data dan kini merupakan penyelesaian pemulihan bencana MySQL yang paling banyak digunakan. Replikasi menggunakan dua atau lebih kejadian untuk membina kluster replikasi tuan-hamba MySQL, menyediakan penulisan satu titik dan perkhidmatan membaca berbilang titik, merealisasikan pembacaan scale out.
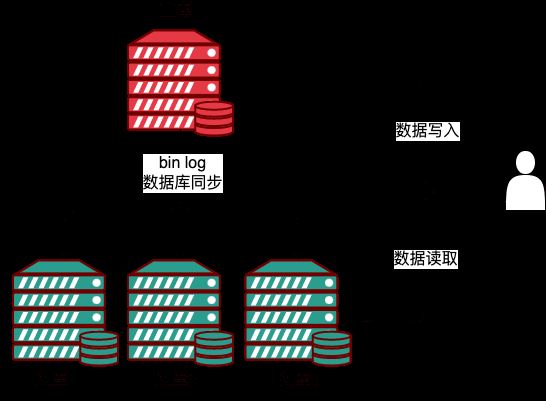
Dalam contoh di atas, terdapat satu perpustakaan induk (M) dan tiga perpustakaan hamba (S) Melalui replikasi, induk menjana binlog acara dan kemudian menghantar ia kepada hamba.
Untuk lapisan perniagaan di atas pangkalan data, kluster replikasi master-slave berdasarkan MySQL mempunyai satu titik penulisan kepada Master Selepas acara disegerakkan kepada Slave, logik baca boleh membaca data dari mana-mana Hamba untuk membaca Kaedah pemisahan tulis sangat mengurangkan beban operasi Master dan meningkatkan penggunaan sumber Hamba.
Kelebihan:
1 Keupayaan untuk mencapai pengembangan mendatar melalui pemisahan baca dan tulis dilakukan pada pelayan sumber, dan operasi membaca data dilakukan daripada pelayan meningkatkan Bilangan pelayan hamba boleh meningkatkan keupayaan membaca pangkalan data
2. Keselamatan data, kerana replika boleh menjeda proses replikasi, perkhidmatan sandaran boleh dijalankan pada replika tanpa memusnahkan sumber yang sepadan Data;
3. Ia adalah mudah untuk analisis data masa nyata boleh dibuat dalam pangkalan data penulisan.
Prinsip Pelaksanaan
Dalam replikasi induk-hamba, perpustakaan hamba menggunakan binlog pada pustaka induk untuk memainkan semula untuk mencapai penyegerakan induk-hamba dump thread,I/O thread,sql thread digunakan terutamanya dalam proses replikasi.
IO thread: Dibuat apabila perpustakaan hamba melaksanakan pernyataan start slave, bertanggungjawab untuk menyambung ke pustaka utama, meminta binlog, menerima binlog dan menulis ke relay-log; >: digunakan Pustaka induk menyegerakkan binlog ke perpustakaan hamba dan bertanggungjawab untuk membalas permintaan daripada hamba
untuk setiap sambungan pustaka hamba, dan kemudian menyegerakkan binlog ke pustaka hamba; dump threadIO threadMari kita lihat proses replikasi: dump thread
(Log relay); sql threadrelay logWalau bagaimanapun
relay log3. Pelaksanaan urus niaga besar;
Apabila transaksi berlaku, perpustakaan utama mesti menunggu urus niaga selesai sebelum ia boleh ditulis ke binlog transaksi adalah sisipan data yang sangat besar, data ini dihantar ke pangkalan data hamba, dan ia juga mengambil masa tertentu untuk menyegerakkan data ini daripada pangkalan data hamba, yang akan menyebabkan kelewatan data pada nod hamba. relay log
MySQL ReplicationBagaimana untuk menyelesaikannya?
1. Optimumkan logik perniagaan untuk mengelakkan senario serentak dengan urus niaga besar berbilang benang; 2. Meningkatkan prestasi mesin perpustakaan hamba dan mengurangkan perbezaan kecekapan antara binlog perpustakaan utama perpustakaan hamba membaca binlog ;
5. Bekerjasama dengan replikasi separa segerak separa segerak; >1. Replikasi tak segerak: lalai dalam Replikasi MySQL adalah asynchronous Pustaka induk akan mengembalikan keputusan kepada pelanggan serta-merta selepas melaksanakan transaksi yang diserahkan oleh pelanggan, dan tidak peduli sama ada perpustakaan hamba telah menerima dan memprosesnya. Masalahnya ialah jika log pangkalan data induk tidak disegerakkan ke pangkalan data hamba dalam masa, dan kemudian pangkalan data induk turun, maka failover dilakukan dan induk dipilih daripada pangkalan data hamba mungkin tidak lengkap;
2. Replikasi segerak sepenuhnya: bermakna apabila perpustakaan utama menyelesaikan transaksi dan menunggu sehingga semua perpustakaan hamba telah menyelesaikan transaksi, perpustakaan utama menyerahkan transaksi dan mengembalikan data kepada pelanggan. Kerana anda perlu menunggu semua pangkalan data hamba disegerakkan dengan data dalam pangkalan data induk sebelum mengembalikan data, ketekalan data induk-hamba boleh dijamin, tetapi prestasi pangkalan data pasti akan terjejas;
3. Replikasi separuh segerak: adalah perantaraan Ia adalah salah satu penyegerakan sepenuhnya dan tak segerak sepenuhnya Pustaka utama perlu menunggu sekurang-kurangnya satu pustaka hamba untuk menerima dan menulis ke fail tidak perlu menunggu semua perpustakaan hamba mengembalikan ACK ke perpustakaan utama. Pustaka utama menerima ACK, menunjukkan bahawa transaksi telah selesai, dan mengembalikan data kepada pelanggan. Relay Log
, MySQL menyokong replikasi separa segerak separa segerak dalam bentuk pemalam. MySQL 5.5
, dan kemudian membalas pustaka induk dengan ACK Hanya apabila perpustakaan induk menerima ACK ini, ia boleh mengesahkan penyempurnaan transaksi kepada pelanggan. Relay Log
memperkenalkan replikasi separa segerak yang dipertingkatkan. Selepas perpustakaan utama menulis data ke binlog, ia mula menunggu respons ACK daripada perpustakaan hamba sehingga sekurang-kurangnya satu perpustakaan hamba menulis MySQL 5.7, kemudian menulis data ke cakera, dan kemudian mengembalikan ACK ke perpustakaan utama untuk memberitahu perpustakaan utama bahawa operasi komit boleh dilakukan , dan kemudian pangkalan data utama menyerahkan urus niaga kepada enjin transaksi, dan hanya selepas itu aplikasi boleh melihat perubahan data. Relay Log
Replikasi Kumpulan, juga dikenali sebagai MGR. Ia merupakan penyelesaian ketersediaan tinggi dan berskala tinggi baharu yang dilancarkan oleh MySQL Group Replication pada Disember 2016 Oracle MySQL. MySQL 5.7.17
sebelum ia boleh diserahkan. (N / 2 + 1)
dua transaksi serentak yang berbeza, satu proses yang dipanggil pengesahan. Semasa pengesahan, pengesanan konflik dilakukan pada peringkat baris: jika dua transaksi serentak dilaksanakan pada ahli kumpulan berbeza mengemas kini baris data yang sama, konflik wujud. Mengikut mekanisme pengesanan pengesahan konflik, supaya transaksi pertama yang diserahkan akan dilaksanakan seperti biasa, transaksi kedua yang diserahkan akan ditarik balik pada ahli kumpulan asal tempat transaksi itu dimulakan dan ahli lain dalam kumpulan akan memadamkan transaksi tersebut. Jika dua urus niaga sering bercanggah, sebaiknya laksanakan dua urus niaga dalam ahli kumpulan yang sama, supaya mereka berpeluang untuk melakukan dengan jayanya di bawah penyelarasan pengurus kunci tempatan, dan bukan kerana mereka berada dalam dua Satu daripada urus niaga sering ditarik balik kerana pengesahan bercanggah antara ahli kumpulan yang berbeza. write set
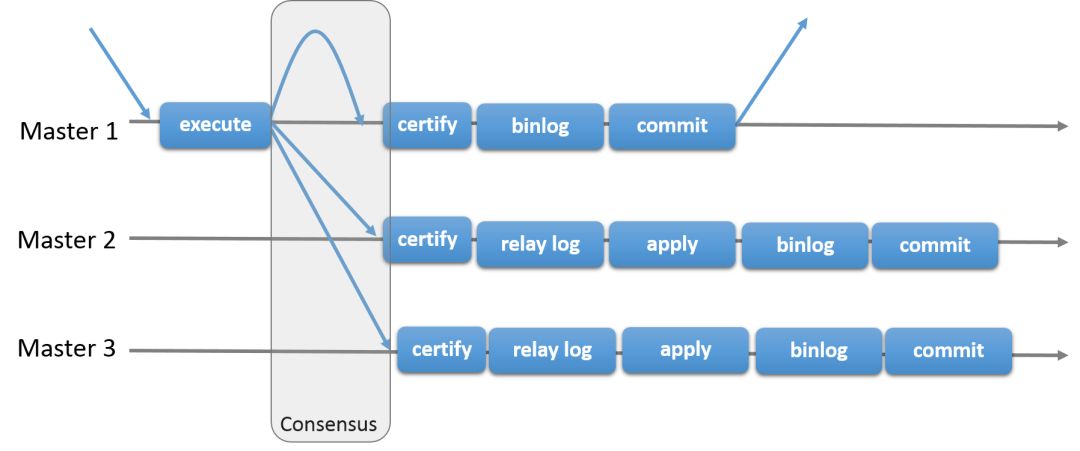
2. Jaminan ketekalan data: MGR mempunyai keupayaan redundansi yang sangat baik dan boleh memastikan bahawa Binlog Event direplikasi kepada sekurang-kurangnya separuh daripada ahli selagi tidak lebih daripada separuh daripada ahli turun pada masa yang sama , data tidak akan hilang. MGR juga memastikan bahawa selagi Binlog Event tidak dihantar kepada lebih separuh daripada ahli, ahli tempatan tidak akan menulis Binlog Event transaksi ke dalam fail Binlog dan menyerahkan transaksi, dengan itu memastikan tiada dalam talian ahli dalam kumpulan pada pelayan yang turun. Oleh itu, selepas pelayan yang diturunkan dimulakan semula, ia tidak lagi memerlukan pemprosesan khas untuk menyertai kumpulan;
3. Sokongan tulis berbilang nod: Dalam mod berbilang tulis, semua nod dalam kelompok boleh ditulis.
Senario aplikasi replikasi kumpulan
1 Replikasi elastik: persekitaran yang memerlukan infrastruktur replikasi yang sangat fleksibel, di mana bilangan Pelayan MySQL mesti ditambah atau dikurangkan secara dinamik, dan bilangan pelayan mesti dinaikkan atau dikurangkan secara dinamik Semasa proses itu, kesan sampingan perlu ada pada perniagaan yang mungkin. Contohnya, perkhidmatan pangkalan data awan;
2. Perkongsian ketersediaan tinggi: Perkongsian ialah kaedah popular untuk mencapai pengembangan tulis. Perkongsian yang sangat tersedia berdasarkan replikasi kumpulan, di mana setiap serpihan dipetakan kepada kumpulan replikasi (secara logik surat-menyurat satu dengan satu diperlukan, tetapi secara fizikal, kumpulan replikasi boleh mengehoskan berbilang serpihan; replikasi tuan-hamba: Dalam sesetengah kes, menggunakan perpustakaan induk akan menyebabkan satu titik perbalahan. Dalam sesetengah senario, menulis data kepada berbilang ahli kumpulan pada masa yang sama boleh membawa kebolehskalaan yang lebih baik kepada aplikasi
4. Sistem autonomi: Anda boleh menggunakan failover automatik terbina dalam replikasi kumpulan, data Siaran atom dan ciri ketekalan data akhirnya antara ahli kumpulan yang berbeza untuk mencapai beberapa automasi operasi.
Kluster InnoDB
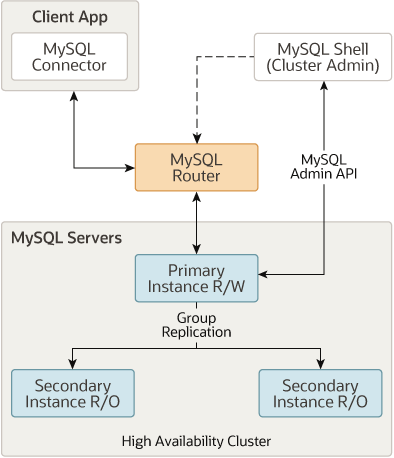
ialah penyelesaian ketersediaan tinggi rasmi Ia adalah penyelesaian ketersediaan tinggi (HA) untuk MySQL Ia merealisasikan replikasi data automatik dengan menggunakan dan tinggi ketersediaan, InnoDB Cluster biasanya mengandungi tiga komponen utama berikut: MySQL Group ReplicationInnoDB Cluster
 1
1
dan MySQL Shell membolehkan sekumpulan
menyediakan cara yang lebih boleh diprogramkan untuk mengendalikan MySQL ServerMGR3 middleware, terutamanya melaksanakan permintaan penghalaan dan permintaan laluan yang dihantar oleh klien ke nod pelayan MySQL yang berbeza. MySQLInnodb Cluster
dan menyediakan pengurusan ahli automatik, toleransi kesalahan, keupayaan failover automatik, dsb. MySQL Router Biasanya berjalan dalam mod induk tunggal, dengan satu tika baca-tulis dan berbilang tika baca sahaja. Walau bagaimanapun, anda juga boleh memilih mod berbilang induk.
Kelebihan: MySQL ServerMySQL Group Replication1 Ketersediaan tinggi: Melalui InnoDB Cluster,
Menyediakan antara muka pengurusan yang ringkas dan mudah digunakan, membolehkan pentadbir menggunakan dan mengurus kluster dengan cepat; mendiagnosis kesilapan, dan melakukan kegagalan yang diperlukan supaya data boleh terus tersedia. MySQL Group ReplicationInnoDB ClusterKelemahan:
1 Kerumitan: Penggunaan dan pengurusan InnoDB Cluster agak rumit dan memerlukan pemahaman tertentu tentang prinsip kerja MySQL
2 impak : Disebabkan oleh keperluan replikasi automatik dan ketersediaan yang tinggi, InnoDB Cluster mungkin mempunyai kesan tertentu pada prestasi MySQL
3 Had: Fungsi
mungkin tidak cukup fleksibel untuk sesetengah orang senario aplikasi khas dan perlu dikemas kini Banyak penyesuaian.InnoDB ClusterInnoDB ClusterSet
InnoDB Cluster menyediakan pemulihan bencana untuk penempatan
utama dengan satu atau lebih replikanya di lokasi ganti (seperti pusat data yang berbeza) kebolehan. InnoDB Cluster
Urus replikasi secara automatik daripada gugusan induk kepada replika menggunakan saluran replikasi ClusterSet khusus. Jika kluster utama menjadi tidak tersedia kerana kerosakan pusat data atau kehilangan sambungan rangkaian, pengguna boleh mengaktifkan kluster replika untuk memulihkan ketersediaan perkhidmatan.
MySQL InnoDB ClusterSetInnoDB ClusterInnoDB ClusterCiri InnoDB ClusterSet:
1 Failover kecemasan antara kluster utama dan kluster replika boleh dilakukan oleh pentadbir melalui InnoDB ClusterSet, menggunakan AdminAPI. Laksanakan operasi;
2. Tiada had yang ditetapkan pada bilangan gugusan replika yang boleh dimiliki dalam pengerahan InnoDB ClusterSet;
3. Saluran replikasi tak segerak mereplikasi urus niaga daripada kelompok utama kepada kelompok replika. clusterset_replication Semasa InnoDB ClusterSet penciptaan, saluran replikasi bernama ClusterSet disediakan pada setiap kluster, yang digunakan untuk mereplikasi transaksi daripada kluster induk apabila kluster ialah replika. Teknologi replikasi kumpulan asas mengurus saluran dan memastikan replikasi sentiasa berada di antara pelayan induk kluster induk (sebagai penghantar) dan pelayan induk kluster replika (sebagai penerima
4 InnoDB ClusterSet kluster , hanya kluster utama boleh menerima permintaan tulis, dan kebanyakan trafik permintaan baca juga akan dihalakan ke kluster utama, tetapi permintaan baca juga boleh ditentukan kepada kluster lain
Sekatan InnoDB ClusterSet:
1. InnoDB ClusterSet hanya menyokong replikasi tak segerak, replikasi separa segerak tidak boleh digunakan dan kecacatan replikasi tak segerak tidak dapat dielakkan: kelewatan data, ketekalan data, dll.; Set Kluster hanya menyokong mod induk tunggal Contoh Kluster , tidak menyokong mod berbilang induk. Iaitu, ia hanya boleh mengandungi satu kluster induk baca-tulis, dan semua kluster replika adalah tetapan aktif-aktif dengan berbilang kluster induk tidak dibenarkan kerana konsistensi data tidak boleh dijamin apabila kluster gagal >3 , Kluster InnoDB sedia ada tidak boleh digunakan sebagai kluster replika dalam penempatan InnoDB ClusterSet. Untuk mencipta kluster InnoDB baharu, kluster replika mesti dimulakan daripada contoh pelayan tunggal
4. Hanya MySQL 8.0 disokong.
InnoDB ReplicaSet
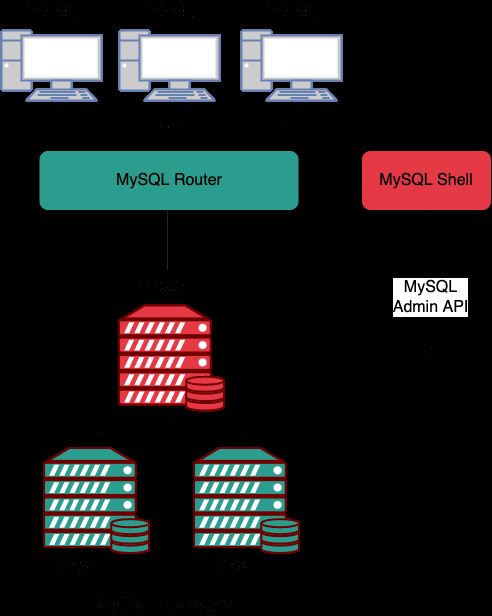
ialah produk yang dilancarkan oleh pasukan MySQL pada tahun 2020 untuk membantu pengguna menggunakan dan mengurus replikasi master-slave dengan pantas masih digunakan dalam lapisan pangkalan data Replication teknologi. terdiri daripada satu nod primer dan berbilang nod sekunder (secara tradisinya dipanggil sumber dan replika replikasi MySQL). InnoDB ReplicaSet
, InnoDB ReplicaSet menyokong but terhadap
boleh dikonfigurasikan secara automatik untuk menggunakan InnoDB cluster tanpa memerlukan fail konfigurasi manual. Ini menjadikan MySQL Router Cara yang cepat dan mudah untuk menyediakan dan menjalankan replikasi MySQL, sesuai untuk menskalakan bacaan dan menyediakan keupayaan failover manual dalam kes penggunaan yang tidak memerlukan ketersediaan tinggi yang disediakan oleh kluster InnoDB. Had InnoDB ReplicaSetMySQL RouterInnoDB ReplicaSetInnoDB ReplicaSetMySQL Router
 1. Apabila nod induk tidak tersedia, anda perlu menggunakan AdminAPI untuk mencetuskan secara manual failover , sebelum membuat sebarang perubahan lagi. Walau bagaimanapun, contoh tambahan masih boleh digunakan untuk membaca; >3 , tidak dapat mengelakkan ketidakkonsistenan selepas keluar yang tidak dijangka atau tidak tersedia. Jika failover manual mempromosikan tika sekunder semasa tika utama sebelumnya masih tersedia, contohnya, disebabkan oleh partition rangkaian, situasi otak berpecah mungkin menyebabkan ketidakkonsistenan data
1. Apabila nod induk tidak tersedia, anda perlu menggunakan AdminAPI untuk mencetuskan secara manual failover , sebelum membuat sebarang perubahan lagi. Walau bagaimanapun, contoh tambahan masih boleh digunakan untuk membaca; >3 , tidak dapat mengelakkan ketidakkonsistenan selepas keluar yang tidak dijangka atau tidak tersedia. Jika failover manual mempromosikan tika sekunder semasa tika utama sebelumnya masih tersedia, contohnya, disebabkan oleh partition rangkaian, situasi otak berpecah mungkin menyebabkan ketidakkonsistenan data
4 -mod induk. Topologi replikasi klasik yang membenarkan penulisan kepada semua ahli tidak dapat menjamin ketekalan data InnoDB ReplicaSet
adalah berdasarkan replikasi tak segerak, jadi kawalan aliran tidak boleh dilaraskan seperti
; Menyokong satu atau lebih alat bantu. Walaupun tiada had pada bilangan nod sekunder yang boleh ditambah pada ReplicaSet, setiap Penghala MySQL yang disambungkan ke ReplicaSet mesti memantau setiap kejadian. Oleh itu, lebih banyak kejadian ditambahkan pada ReplicaSet, lebih banyak pemantauan diperlukan. Sebab utama untuk menggunakanialah anda mempunyai prestasi penulisan yang lebih baik. Satu lagi sebab untuk menggunakan
ialah mereka membenarkan penggunaan pada rangkaian yang tidak stabil atau perlahan, manakalatidak.
MMMInnoDB ReplicaSetGroup ReplicationMMM (pengurus replikasi Master-Master untuk MySQL) ialah satu set skrip yang menyokong failover dwi-induk dan pengurusan harian dwi-induk. MMM dibangunkan menggunakan bahasa Perl dan digunakan terutamanya untuk memantau dan mengurus replikasi
InnoDB ReplicaSetsMMM menggunakan mekanisme VIP (IP maya) untuk memastikan ketersediaan tinggi kluster. Dalam keseluruhan kluster, nod induk akan menyediakan alamat VIP untuk menyediakan perkhidmatan membaca dan menulis data Apabila kegagalan berlaku, VIP akan dipindahkan daripada nod induk asal ke nod lain, dan nod lain akan menyediakan perkhidmatan. InnoDB ReplicaSetsInnoDB Cluster
Kebaikan dan keburukan MMM
Kelebihan: ketersediaan tinggi, kebolehskalaan yang baik, pensuisan automatik sekiranya berlaku kegagalan, untuk penyegerakan induk-induk, hanya satu operasi menulis pangkalan data disediakan pada masa yang sama untuk memastikan ketekalan data .
Kelemahan: Ketekalan data tidak dapat dijamin sepenuhnya. Adalah disyorkan untuk menggunakan replikasi separa segerak untuk mengurangkan kebarangkalian kegagalan pada masa ini, komuniti MMM telah kekurangan penyelenggaraan dan tidak menyokong replikasi berasaskan GTID.
Senario terpakai:
Senario terpakai untuk MMM ialah senario di mana akses pangkalan data adalah besar, pertumbuhan perniagaan pantas dan pengasingan membaca dan menulis boleh dicapai.
MHA
Kuasai Pengurus Ketersediaan Tinggi dan Alat untuk MySQL, dirujuk sebagai MHA. Ini adalah set perisian ketersediaan tinggi yang sangat baik untuk promosi failover dan tuan-hamba dalam persekitaran ketersediaan tinggi MySQL.
Alat ini digunakan khas untuk memantau status pangkalan data utama Apabila nod induk didapati rosak, ia akan secara automatik mempromosikan nod hamba dengan data baharu untuk menjadi nod induk baharu dalam tempoh ini , MHA akan lulus hamba lain Nod mendapatkan maklumat tambahan untuk mengelakkan isu konsistensi data. MHA juga menyediakan fungsi untuk menukar nod Master-Slave dalam talian, yang boleh ditukar mengikut keperluan. MHA boleh melaksanakan failover dalam masa 30 saat sambil memastikan konsistensi data pada tahap yang terbaik.
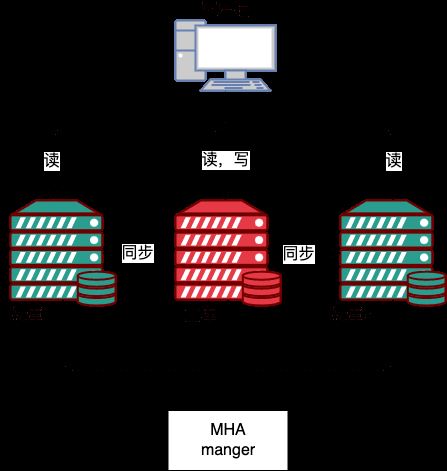
MHA terdiri daripada dua bahagian;
Pengurus MHA (nod pengurusan) dan Nod MHA (nod data).
MHA Manager Ia boleh digunakan pada mesin bebas untuk mengurus berbilang kluster induk-hamba, atau ia boleh digunakan pada nod hamba. MHA Node Berjalan pada setiap pelayan MySQL, MHA Manager akan sentiasa mengesan nod induk dalam kluster Apabila induk gagal, ia secara automatik boleh mempromosikan hamba dengan data terkini kepada induk baharu, dan kemudian memulakan semula semua hamba yang lain kepada tuan baru.
Keseluruhan proses failover adalah telus sepenuhnya kepada aplikasi.
Semasa proses failover automatik MHA, MHA cuba menyimpan log perduaan daripada pelayan utama yang diturunkan ke tahap yang terbaik untuk memastikan data tidak hilang sepenuhnya, tetapi ini tidak selalu dapat dilaksanakan. Contohnya, jika perkakasan pelayan induk gagal atau tidak boleh diakses melalui ssh, MHA tidak boleh menyimpan log binari dan hanya gagal dan kehilangan data terkini.
Gunakan MySQL 5.5 untuk mula mencari replikasi separa segerak yang disokong, yang boleh mengurangkan risiko kehilangan data dengan banyak. MHA boleh digabungkan dengan replikasi separa segerak. Jika hanya seorang hamba telah menerima log binari terkini, MHA boleh menggunakan log binari terkini pada semua pelayan hamba lain, dengan itu memastikan ketekalan data pada semua nod.
Pada masa ini, MHA menyokong seni bina satu induk, berbilang hamba Untuk membina MHA, gugusan replikasi mesti mempunyai sekurang-kurangnya tiga pelayan pangkalan data, satu induk dan dua hamba, iaitu satu induk dan satu hidangan. sebagai tuan sandaran Selain itu, Satu pelayan bertindak sebagai hamba kerana sekurang-kurangnya tiga pelayan diperlukan.
Prinsip kerja MHA diringkaskan seperti berikut:
1 Simpan peristiwa log binari (peristiwa binlog) daripada tuan yang ranap
2 ;
3. Gunakan log geganti pembezaan kepada hamba yang lain; >
6. Gunakan hamba lain untuk menyambung kepada tuan baharu untuk replikasi. Kelebihan: 1 Boleh menyokong mod replikasi berasaskan GTID; 2. Nod pemantauan yang sama boleh memantau berbilang kelompok. Kelemahan: 1 Anda perlu menulis skrip atau menggunakan alat pihak ketiga untuk mengkonfigurasi VIP 2 ;3. Ia memerlukan konfigurasi tanpa pengesahan berdasarkan SSH, yang mempunyai risiko keselamatan tertentu. Kluster Galeraialah kluster berbilang induk MySQL yang dibangunkan oleh Codership Ia disertakan dalam MariaDB dan menyokong
Ia adalah ketersediaan tinggi yang mudah digunakan penyelesaian untuk data Prestasi yang boleh diterima dari segi kesempurnaan, kebolehskalaan dan prestasi tinggi. sendiri mempunyai ciri berbilang induk dan menyokong penulisan berbilang titik Setiap kejadian dalamadalah rakan-ke-rakan, tuan-hamba antara satu sama lain. Apabila pelanggan membaca dan menulis data, ia boleh memilih mana-mana contoh MySQL Untuk operasi baca, data yang dibaca oleh setiap contoh adalah sama. Untuk operasi tulis, apabila data ditulis pada nod, kluster akan menyegerakkannya ke nod lain. Seni bina ini tidak berkongsi sebarang data dan merupakan seni bina yang sangat berlebihan.
Galera ClusterPercona xtradb、MySQL
Galera Cluster1. Replikasi segerak;
2 pangkalan data pada masa yang sama ; Replikasi selari benar, Tahap; 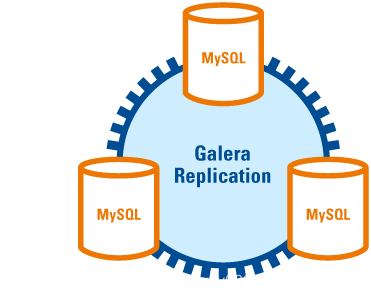
1. Ketekalan data: Replikasi segerak memastikan ketekalan data keseluruhan kluster Setiap kali pertanyaan pilihan yang sama dilaksanakan pada mana-mana nod, hasilnya akan sama
2 data pada semua nod Konsisten, satu ranap nod tidak memerlukan failover yang rumit dan memakan masa, dan juga tidak akan menyebabkan kehilangan data atau gangguan perkhidmatan; 3. Peningkatan prestasi: Replikasi segerak membolehkan transaksi dilaksanakan dalam selari pada semua nod dalam kelompok, Dengan itu meningkatkan prestasi baca dan tulis;
4.
Analisis prinsip
Replikasi segerak digunakan terutamanya dalam satu transaksi kemas kini dalam pangkalan data induk perlu dikemas kini secara serentak dalam semua pangkalan data hamba apabila pangkalan data induk melakukan transaksi. semua hamba dalam data Nod kluster kekal konsisten. Replikasi tak segerak, pangkalan data induk menyebarkan kemas kini data ke pangkalan data hamba dan serta-merta melakukan transaksi, tidak kira sama ada pangkalan data hamba berjaya membaca atau memainkan semula perubahan data, jadi replikasi tak segerak akan mempunyai jangka pendek, induk- situasi ketidakkonsistenan penyegerakan data hamba berlaku.Galera ClusterWalau bagaimanapun, kelemahan replikasi segerak juga jelas Protokol replikasi segerak biasanya menggunakan kunci komit dua fasa atau diedarkan untuk menyelaraskan operasi nod yang berbeza lebih banyak nod perlu diselaraskan, jadi Kebarangkalian konflik transaksi dan kebuntuan juga akan meningkat.
Kami tahu bahawa pengenalan replikasi kumpulan MGR juga adalah untuk menyelesaikan masalah ketidakkonsistenan data yang mungkin berlaku dalam replikasi tak segerak dan replikasi separa segerak dalam MGR adalah berdasarkan protokol Paxos , penyerahan transaksi adalah terutamanya untuk kebanyakan nod ACK boleh diserahkan. Penyegerakan dalam
perlu menyegerakkan data ke semua nod untuk memastikan semua nod berjaya. Berdasarkan sistem kumpulan komunikasi proprietari GCommon, semua nod mesti mempunyai ACK. Replikasi Galera ialah sejenis replikasi berasaskan pengesahan menggunakan teknologi komunikasi dan pengisihan untuk mencapai replikasi segerak, dan menyelaraskan penyerahan transaksi dengan menyiarkan jumlah pesanan global yang ditetapkan antara transaksi serentak. Ringkasnya, urus niaga mesti digunakan untuk semua keadaan dalam susunan yang sama.Galera ClusterTransaksi kini dilaksanakan secara setempat, dan kemudian dihantar ke nod lain untuk pengesahan konflik Apabila tiada konflik, semua nod melakukan transaksi, jika tidak, ia akan digulung semula pada semua nod.
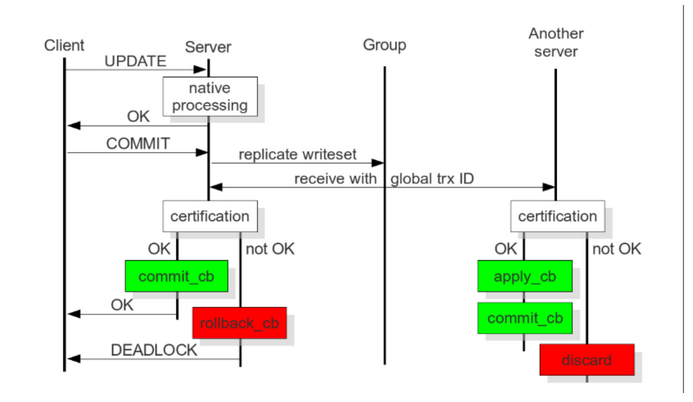 Nod membandingkan kunci utama dalam set tulis dengan kunci utama dalam semua set tulis transaksi yang belum selesai dalam nod semasa untuk menentukan sama ada nod boleh menyerahkan transaksi Jika tiga syarat berikut dipenuhi pada pada masa yang sama, tugas akan bercanggah dan pengesahan akan gagal:
Nod membandingkan kunci utama dalam set tulis dengan kunci utama dalam semua set tulis transaksi yang belum selesai dalam nod semasa untuk menentukan sama ada nod boleh menyerahkan transaksi Jika tiga syarat berikut dipenuhi pada pada masa yang sama, tugas akan bercanggah dan pengesahan akan gagal:
1 Kedua-dua transaksi berasal dari nod yang berbeza
2 🎜>3. Transaksi lama tidak kelihatan kepada transaksi baru, iaitu transaksi lama Tidak diserahkan sehingga selesai. Persempadanan urus niaga baharu dan lama bergantung pada jumlah pesanan global, iaitu GTID.
Setiap nod melakukan pengesahan secara bebas, jika pengesahan gagal, nod akan memadam set tulis dan melancarkan semula transaksi asal, semua nod akan melakukan operasi yang sama. Semua nod menerima transaksi dalam susunan yang sama, menyebabkan mereka semua membuat keputusan hasil yang sama, sama ada semuanya berjaya atau semua gagal. Selepas kejayaan, ia akan diserahkan secara semula jadi, dan semua nod akan mencapai keadaan konsisten data sekali lagi. Tiada maklumat tentang "konflik" ditukar antara nod, dan setiap nod memproses transaksi secara bebas dan tak segerak.
Kluster MySQL
ialah pangkalan data masa nyata yang sangat berskala yang serasi dengan urus niaga ACID Ia berdasarkan seni bina yang diedarkan dan tidak mempunyai satu titik kegagalanmenyokong automatik pengembangan mendatar, dan Boleh melakukan pengimbangan beban baca dan tulis automatik.
Menggunakan enjin storan dalam memori yang dipanggil NDB untuk menyepadukan berbilang tika MySQL dan menyediakan kluster perkhidmatan bersatu.MySQL ClusterNDB ialah enjin storan memori menggunakan seni bina Sharding-Nothing. Sarding-Nothing bermakna setiap nod mempunyai pemproses, cakera dan memori bebas Tiada sumber yang dikongsi antara nod dan ia benar-benar bebas dan tidak mengganggu satu sama lain Nod dihimpunkan bersama-sama setiap nod pangkalan data yang kecil, menyimpan beberapa data. Kelebihan seni bina ini ialah ia boleh menggunakan pengedaran nod untuk memproses data secara selari dan meningkatkan prestasi keseluruhan Ia juga mempunyai prestasi pengembangan mendatar yang tinggi dengan hanya menambah nod boleh meningkatkan keupayaan pemprosesan data. MySQL Cluster
MySQL Cluster
mengandungi tiga jenis nod iaitu management nod (NDB Management Server), data nod (Data Nodes) dan SQL query nod (SQL Nodes).
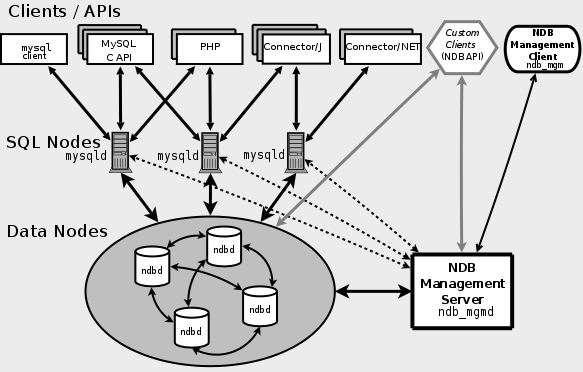 ialah antara muka program aplikasi Seperti perkhidmatan mysqld biasa, ia menerima input SQL pengguna, melaksanakan dan mengembalikan hasilnya.
ialah antara muka program aplikasi Seperti perkhidmatan mysqld biasa, ia menerima input SQL pengguna, melaksanakan dan mengembalikan hasilnya.
digunakan untuk mengurus setiap nod dalam gugusan. MySql Cluster
Nod data akan menyimpan partition data dan salinan partition dalam gugusan Mari kita lihat cara MySql Cluster melakukan operasi sharding pada data Pertama, mari kita fahami konsep berikut
nod Kumpulan : Koleksi nod data. Bilangan kumpulan nod = 节点数 / 副本数;
Contohnya, jika terdapat 4 nod dalam kelompok dan bilangan replika ialah 2 (bersamaan dengan tetapan NoOfReplicas), maka bilangan kumpulan nod ialah 2 .
Selain itu, dari segi ketersediaan, salinan data diedarkan secara silang dalam kumpulan Hanya satu mesin dalam kumpulan nod tersedia untuk memastikan integriti data keseluruhan kluster dan mencapai ketersediaan perkhidmatan keseluruhan.
Partition: MySql Cluster ialah sistem storan teragih Data dibahagikan kepada beberapa bahagian mengikut partition dan disimpan dalam setiap nod data Bilangan partition dikira secara automatik oleh sistem, 分区数 = 数据节点数 / LDM 线程数; >
, partition dan salinan yang sepadan dengan data asal biasanya disimpan dalam. berbeza Pada hos, lakukan sandaran silang dalam kumpulan nod. MySql Cluster
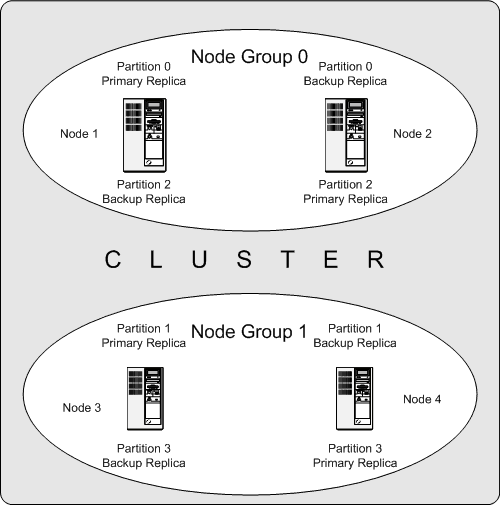
tidak normal, maka
boleh menyediakan perkhidmatan dengan segera untuk mencapai ketersediaan data yang tinggi. KelebihanPrimary ReplicaBackup Replica1. 99.999% ketersediaan tinggi;
2 titik kegagalan; mysql cluster
Kelemahan
1. Terdapat banyak sekatan, seperti: tiada kunci asing disokong dan baris data tidak boleh melebihi 8K (tidak termasuk data dalam BLOB dan teks); >
2. Penggunaan, pengurusan, dan konfigurasi adalah rumit; >5. Apabila dimulakan semula, nod data mengambil masa yang lama untuk memuatkan data ke dalam memori.
MySQL Fabric
mysql cluster akan menyusun berbilang pangkalan data MySQL dan menyebarkan data besar ke dalam berbilang pangkalan data, iaitu, pemecahan data
Ciri-ciri:
1. Ketersediaan tinggi
2. Penyambung
menyimpan maklumat penghalaan yang diperoleh daripadadalam cache dan menggunakan maklumat tersebut untuk menghantar transaksi atau pertanyaan ke pelayan MySQL yang betul.
Pada masa yang sama, setiap kumpulan sharding boleh terdiri daripada berbilang pelayan untuk membentuk struktur master-slave Apabila pangkalan data induk ditutup, pangkalan data induk akan dipilih daripada pangkalan data hamba sekali lagi. Pastikan ketersediaan tinggi nod. MySQL Fabric(Data Shard)
sentiasa tersedia dan replikasi data asasnya dilaksanakan berdasarkan MySQL Fabric.
MySQL Fabric-awareTransaksi dan pertanyaan hanya disokong dalam serpihan yang sama Data yang dikemas kini dalam urus niaga tidak boleh merentas serpihan, dan data yang dikembalikan oleh pertanyaan pernyataan tidak boleh Tidak boleh menyeberangi serpihan. MySQL Fabric
Atas ialah kandungan terperinci Apakah penyelesaian penggunaan seni bina ketersediaan tinggi yang biasa dalam MySQL?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!