
Rumah >pembangunan bahagian belakang >Tutorial Python >Apakah kaedah untuk memproses ciri kategori dalam pembelajaran mesin Python?
Apakah kaedah untuk memproses ciri kategori dalam pembelajaran mesin Python?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-03 10:45:131610semak imbas
Ciri kategori merujuk kepada ciri dengan nilai yang termasuk dalam set kategori terhingga, seperti pekerjaan dan jenis darah.. Input asalnya biasanya dalam bentuk rentetan Kebanyakan model algoritma tidak menerima input ciri kategori berangka akan dianggap sebagai ciri berangka, menyebabkan ralat dalam model terlatih.
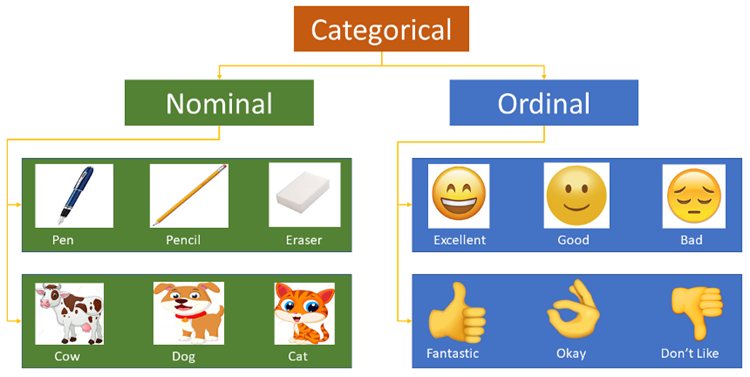
Pengekodan label
Pengekodan Label menggunakan kamus untuk mengaitkan setiap label kategori dengan integer yang semakin meningkat, iaitu, menghasilkan kelas yang dipanggil Indeks ke dalam tatasusunan contoh daripada _.
Pengekod Label dalam Scikit-learn digunakan untuk mengekod nilai ciri kategori, iaitu, untuk mengekod nilai atau teks terputus. Ia termasuk kaedah biasa berikut:
fit(y): fit boleh dianggap sebagai kamus kosong dan y boleh dianggap sebagai perkataan yang diperkukuh ke dalam kamus.
fit_transform(y): Ia bersamaan dengan pemasangan dahulu dan kemudian berubah, iaitu, meletakkan y ke dalam kamus dan kemudian mengubah untuk mendapatkan nilai indeks.
inverse_transform(y): Dapatkan data asal berdasarkan nilai indeks y.
transform(y): Tukarkan y kepada nilai indeks.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
Kaedah pengekodan data berbilang lajur:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
d = {}
le = LabelEncoder()
cols_to_encode = ['pets', 'owner', 'location']
for col in cols_to_encode:
df_train[col] = le.fit_transform(df_train[col])
d[col] = le.classes_Pandas’ factorize() boleh merujuk kepada pemetaan data nominal dalam Siri sebagai set nombor yang sama Peta jenis panggilan ke nombor yang sama. Pemfaktoran fungsi mengembalikan tuple yang mengandungi dua elemen. Elemen pertama ialah tatasusunan, elemen-elemennya ialah nombor yang dipetakan oleh elemen nominal;
import numpy as np import pandas as pd df = pd.DataFrame(['green','bule','red','bule','green'],columns=['color']) pd.factorize(df['color']) #(array([0, 1, 2, 1, 0], dtype=int64),Index(['green', 'bule', 'red'], dtype='object')) pd.factorize(df['color'])[0] #array([0, 1, 2, 1, 0], dtype=int64) pd.factorize(df['color'])[1] #Index(['green', 'bule', 'red'], dtype='object')
Pengekodan Label hanya menukar teks kepada nilai berangka dan tidak menyelesaikan masalah ciri teks: semua label menjadi nombor, dan model algoritma akan secara langsung mempertimbangkan nombor yang serupa berdasarkan jaraknya, tanpa mengira label makna khusus. Data yang diproses oleh kaedah ini boleh digunakan pada model algoritma yang menyokong atribut kategori, seperti LightGBM.
Pengekodan Ordinal
Pengekodan Ordinal ialah idea paling mudah Untuk Ciri dengan kategori m, kami memetakannya kepada [0,m-1 ] ialah integer. Sudah tentu, Pengekodan Ordinal lebih sesuai untuk Ciri Ordinal, iaitu, setiap ciri mempunyai susunan yang wujud. Contohnya, untuk kategori seperti "Pendidikan", "Sarjana Muda", "Sarjana", dan "Ph.D." Tetapi untuk kategori seperti "warna", adalah tidak munasabah untuk mengekod "biru", "hijau" dan "merah" masing-masing ke dalam [0,2], kerana kita tidak mempunyai sebab untuk berfikir bahawa "biru" dan "hijau" Jurang antara "biru" dan "merah" mempunyai kesan yang berbeza pada ciri.
ord_map = {'Gen 1': 1, 'Gen 2': 2, 'Gen 3': 3, 'Gen 4': 4, 'Gen 5': 5, 'Gen 6': 6}
df['GenerationLabel'] = df['Generation'].map(gord_map)Pengekodan Satu-Hot
Dalam tugasan aplikasi pembelajaran mesin sebenar, ciri kadangkala tidak sentiasa nilai berterusan dan mungkin beberapa nilai kategori, seperti Jantina boleh dibahagikan kepada lelaki dan perempuan. Dalam tugasan pembelajaran mesin, untuk ciri tersebut, kita biasanya perlu mendigitalkannya Contohnya, terdapat tiga atribut ciri berikut:
Jantina: ["lelaki", "perempuan" ]
Wilayah: ["Eropah","AS","Asia"]
Pelayar: ["Firefox","Chrome ", "Safari","Internet Explorer"]
Untuk sampel tertentu, seperti ["lelaki", "AS", "Internet Explorer"], kita perlu mengklasifikasikan nilai ini kaedah yang paling langsung untuk mendigitalkan ciri ialah bersiri: [0,1,3]. Walaupun data ditukar kepada bentuk berangka, pengelas kami tidak boleh menggunakan data di atas secara langsung. Kerana pengelas selalunya lalai kepada data yang berterusan dan teratur. Menurut perwakilan di atas, nombor tidak disusun, tetapi diberikan secara rawak. Pemprosesan ciri sedemikian tidak boleh dimasukkan terus ke dalam algoritma pembelajaran mesin.
Untuk menyelesaikan masalah di atas, menggunakan One-Hot Encoding adalah salah satu penyelesaian yang mungkin. Pengekodan satu panas, juga dikenali sebagai pengekodan cekap satu bit. Kaedahnya ialah menggunakan daftar status N-bit untuk mengekod keadaan N Setiap negeri mempunyai bit daftar bebasnya sendiri, dan pada bila-bila masa, hanya satu daripadanya yang sah. Pengekodan satu panas menukarkan setiap ciri kepada ciri binari m, dengan m ialah bilangan nilai yang mungkin untuk ciri tersebut. Selain itu, ciri ini adalah saling eksklusif dan hanya satu yang aktif pada satu masa. Oleh itu, data menjadi jarang.
Untuk masalah di atas, atribut jantina adalah dua dimensi Begitu juga, rantau ini adalah tiga dimensi dan penyemak imbas adalah empat dimensi Dengan cara ini, kita boleh menggunakan pengekodan One-Hot untuk mengekod perkara di atas contoh pengekodan [ "lelaki", "AS", "Internet Explorer"], lelaki sepadan dengan [1, 0], begitu juga AS sepadan dengan [0, 1, 0] dan Internet Explorer sepadan dengan [0, 0, 0, 1 ]. Hasil pendigitalan ciri lengkap ialah: [1,0,0,1,0,0,0,0,1].
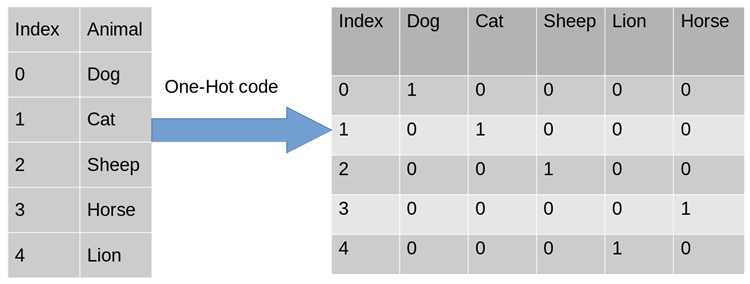
Mengapa saya boleh menggunakan Pengekodan One-Hot?
使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
使用One-Hot编码对离散型特征进行处理可以使得特征之间的距离计算更加准确。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。在实际应用中,One-Hot Encoding与PCA结合的方法也非常实用。
One-Hot Encoding的使用场景
独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
树结构方法,如随机森林、Bagging和Boosting等,在特征处理方面不需要进行标准化操作。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念。
基于Scikit-learn 的one hot encoding
LabelBinarizer:将对应的数据转换为二进制型,类似于onehot编码,这里有几点不同:
可以处理数值型和类别型数据
输入必须为1D数组
可以自己设置正类和父类的表示方式
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() city_list = ["paris", "paris", "tokyo", "amsterdam"] lb.fit(city_list) print(lb.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = lb.transform(city_list) # 进行Encode print(city_list_le) # 输出为: # [[0 1 0] # [0 1 0] # [0 0 1] # [1 0 0]] city_list_new = lb.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
OneHotEncoder只能对数值型数据进行处理,需要先将文本转化为数值(Label encoding)后才能使用,只接受2D数组:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
def LabelOneHotEncoder(data, categorical_features):
d_num = np.array([])
for f in data.columns:
if f in categorical_features:
le, ohe = LabelEncoder(), OneHotEncoder()
data[f] = le.fit_transform(data[f])
if len(d_num) == 0:
d_num = np.array(ohe.fit_transform(data[[f]]))
else:
d_num = np.hstack((d_num, ohe.fit_transform(data[[f]]).A))
else:
if len(d_num) == 0:
d_num = np.array(data[[f]])
else:
d_num = np.hstack((d_num, data[[f]]))
return d_num
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_new = LabelOneHotEncoder(df, ['color', 'make', 'year'])基于Pandas的one hot encoding
其实如果我们跳出 scikit-learn, 在 pandas 中可以很好地解决这个问题,用 pandas 自带的get_dummies函数即可
import pandas as pd
df = pd.DataFrame([
['green', 'Chevrolet', 2017],
['blue', 'BMW', 2015],
['yellow', 'Lexus', 2018],
])
df.columns = ['color', 'make', 'year']
df_processed = pd.get_dummies(df, prefix_sep="_", columns=df.columns[:-1])
print(df_processed)get_dummies的优势在于:
本身就是 pandas 的模块,所以对 DataFrame 类型兼容很好
不管你列是数值型还是字符串型,都可以进行二值化编码
能够根据指令,自动生成二值化编码后的变量名
get_dummies虽然有这么多优点,但毕竟不是 sklearn 里的transformer类型,所以得到的结果得手动输入到 sklearn 里的相应模块,也无法像 sklearn 的transformer一样可以输入到pipeline中进行流程化地机器学习过程。
频数编码(Frequency Encoding/Count Encoding)
将类别特征替换为训练集中的计数(一般是根据训练集来进行计数,属于统计编码的一种,统计编码,就是用类别的统计特征来代替原始类别,比如类别A在训练集中出现了100次则编码为100)。这个方法对离群值很敏感,所以结果可以归一化或者转换一下(例如使用对数变换)。未知类别可以替换为1。
频数编码使用频次替换类别。有些变量的频次可能是一样的,这将导致碰撞。尽管可能性不是非常大,没法说这是否会导致模型退化,不过原则上我们不希望出现这种情况。
import pandas as pd
data_count = data.groupby('城市')['城市'].agg({'频数':'size'}).reset_index()
data = pd.merge(data, data_count, on = '城市', how = 'left')目标编码(Target Encoding/Mean Encoding)
目标编码(target encoding),亦称均值编码(mean encoding)、似然编码(likelihood encoding)、效应编码(impact encoding),是一种能够对高基数(high cardinality)自变量进行编码的方法 (Micci-Barreca 2001) 。
如果某一个特征是定性的(categorical),而这个特征的可能值非常多(高基数),那么目标编码(Target encoding)是一种高效的编码方式。在实际应用中,这类特征工程能极大提升模型的性能。
一般情况下,针对定性特征,我们只需要使用sklearn的OneHotEncoder或LabelEncoder进行编码。
LabelEncoder boleh menerima lajur ciri tidak teratur dan menukarnya kepada nilai integer dari 0 hingga n-1 (dengan mengandaikan terdapat n kategori berbeza secara keseluruhannya boleh menghasilkan m*n melalui pengekodan dummy matriks Jarang (dengan mengandaikan data mempunyai m baris dalam jumlah, sama ada format matriks keluaran khusus adalah jarang boleh dikawal oleh parameter jarang).
"Kardinaliti" ciri kualitatif merujuk kepada jumlah bilangan nilai mungkin berbeza yang boleh diambil oleh ciri itu.. Dalam menghadapi ciri kualitatif kardinaliti tinggi, kaedah prapemprosesan data ini sering gagal mencapai hasil yang memuaskan.
Contoh ciri kualitatif berkardinaliti tinggi: alamat IP, nama domain e-mel, nama bandar, alamat rumah, jalan, nombor produk. | berkenaan dengan y. Menggunakan model mudah terdedah kepada kekurangan dan tidak dapat menangkap sepenuhnya perbezaan antara kategori yang berbeza menggunakan model yang kompleks terdedah kepada pemasangan berlebihan di tempat lain.
OneHotEncoder mengekod ciri kualitatif kardinaliti tinggi, yang pasti akan menghasilkan matriks jarang dengan puluhan ribu lajur, dengan mudah memakan banyak memori dan masa latihan, melainkan algoritma itu sendiri mempunyai pengoptimuman yang berkaitan (contohnya: SVM).
Jika kardinaliti ciri kategori tertentu agak rendah (ciri kardinaliti rendah), iaitu bilangan elemen dalam set yang terdiri daripada semua nilai ciri selepas penyahduaan agak kecil, secara amnya gunakan One- Kaedah pengekodan panas menukarkan ciri kepada jenis berangka. Pengekodan satu panas boleh dilengkapkan semasa prapemprosesan data atau semasa latihan model Dari perspektif masa latihan, kaedah terakhir CatBoost juga menggunakan kaedah yang terakhir untuk jenis realisasi yang rendah.
Jelas sekali, antara ciri kardinaliti tinggi, seperti ID pengguna, kaedah pengekodan ini akan menjana sejumlah besar ciri baharu, menyebabkan bencana dimensi. Kaedah kompromi adalah untuk mengumpulkan kategori ke dalam bilangan kumpulan yang terhad dan kemudian melakukan pengekodan One-hot. Kaedah yang biasa digunakan ialah mengumpulkan mengikut statistik pembolehubah sasaran (Statistik Sasaran, selepas ini dirujuk sebagai TS), yang digunakan untuk menganggarkan nilai jangkaan pembolehubah sasaran bagi setiap kategori. Sesetengah orang secara langsung menggunakan TS sebagai pembolehubah berangka baharu untuk menggantikan pembolehubah kategori asal. Yang penting, dengan menetapkan ambang untuk ciri berangka TS, berdasarkan kehilangan logaritma, pekali Gini atau ralat min kuasa dua, kita boleh memperoleh yang optimum di antara semua bahagian yang mungkin yang membahagikan kategori kepada dua untuk set latihan. Dalam LightGBM, ciri kategori diwakili oleh Statistik Gradien (GS) pada setiap langkah peningkatan kecerunan. Walaupun ia menyediakan maklumat penting untuk pembinaan pokok, kaedah ini mempunyai dua kelemahan berikut: - Meningkatkan masa pengiraan, kerana ia memerlukan setiap ciri kategori pada setiap langkah lelaran dikira
untuk meningkatkan keperluan storan Untuk pembolehubah kategori, kategori setiap nod perlu disimpan setiap kali
Untuk mengatasi kelemahan ini, LightGBM mengklasifikasikan semua kategori ekor panjang ke dalam satu kategori dengan kos kehilangan beberapa maklumat Penulis mendakwa bahawa kaedah ini jauh lebih baik daripada pengekodan One-hot apabila memproses ciri kategori kardinaliti tinggi. Menggunakan ciri TS, hanya satu nombor bagi setiap kategori dikira dan disimpan. Oleh itu, menggunakan TS sebagai ciri berangka baharu untuk memproses ciri kategori adalah yang paling berkesan dan boleh meminimumkan kehilangan maklumat. TS juga digunakan secara meluas dalam tugas ramalan klik Ciri kategori dalam senario ini termasuk pengguna, wilayah, iklan, penerbit iklan, dsb. Dalam perbincangan berikut, kami akan menumpukan pada TS dan mengetepikan pengekodan One-hot dan GS buat masa ini.
- Berikut ialah formula pengiraan: di mana n mewakili bilangan nilai ciri tertentu dan
mewakili nilai ciri tertentu Nombor yang lebih rendah ialah bilangan Label positif ialah ambang minimum Kategori ciri dengan nombor sampel kurang daripada nilai ini akan diabaikan. Ambil perhatian bahawa jika anda menghadapi masalah regresi, ia boleh diproses menjadi purata/maks nilai label di bawah ciri yang sepadan. Untuk masalah klasifikasi k, ciri k-1 yang sepadan akan dihasilkan.
Kaedah ini juga terdedah kepada overfitting Kaedah berikut digunakan untuk mengelakkan overfitting:
Tingkatkan saiz istilah biasa a<.>
Tambahkan bunyi pada lajur set latihan ini
- Gunakan pengesahan silang
- Sasaran pengekodan diawasi Kaedah pengekodan, jika digunakan dengan betul, boleh meningkatkan ketepatan model ramalan dengan berkesan (Pargent, Bischl, dan Thomas 2019 dan kunci kepada ini adalah untuk memperkenalkan penyelarasan dalam proses pengekodan untuk mengelakkan masalah terlalu sesuai. Sebagai contoh, kategori A sepadan dengan 200 teg 1, 300 teg 2 dan 500 teg 3, yang boleh dikodkan sebagai: 2/10, 3/10, 3/6. Perkara yang paling penting di tengah-tengah ialah bagaimana untuk mengelakkan overfitting (pengekodan sasaran asal secara langsung mengekod semua data dan label set latihan, yang akan menyebabkan hasil pengekodan yang diperoleh terlalu bergantung pada set latihan Penyelesaian biasa adalah menggunakan 2). tahap Pengesahan Silang mencari min sasaran Ideanya adalah seperti berikut:
把train data划分为20-folds (举例:infold: fold #2-20, out of fold: fold #1)
计算 10-folds的 inner out of folds值 (举例:使用inner_infold #2-10 的target的均值,来作为inner_oof #1的预测值)
对10个inner out of folds 值取平均,得到 inner_oof_mean
将每一个 infold (fold #2-20) 再次划分为10-folds (举例:inner_infold: fold #2-10, Inner_oof: fold #1)
计算oof_mean (举例:使用 infold #2-20的inner_oof_mean 来预测 out of fold #1的oof_mean
将train data 的 oof_mean 映射到test data完成编码
比如划分为10折,每次对9折进行标签编码然后用得到的标签编码模型预测第10折的特征得到结果,其实就是常说的均值编码。
目标编码尝试对分类特征中每个级别的目标总体平均值进行测量。当数据量较少时,每个级别的数据量减少意味着估计的均值与真实均值之间的差距增加,方差也会更大。
from category_encoders import TargetEncoder import pandas as pd from sklearn.datasets import load_boston # prepare some data bunch = load_boston() y_train = bunch.target[0:250] y_test = bunch.target[250:506] X_train = pd.DataFrame(bunch.data[0:250], columns=bunch.feature_names) X_test = pd.DataFrame(bunch.data[250:506], columns=bunch.feature_names) # use target encoding to encode two categorical features enc = TargetEncoder(cols=['CHAS', 'RAD']) # transform the datasets training_numeric_dataset = enc.fit_transform(X_train, y_train) testing_numeric_dataset = enc.transform(X_test)
Beta Target Encoding
Kaggle竞赛Avito Demand Prediction Challenge 第14名的solution分享:14th Place Solution: The Almost Golden Defenders。和target encoding 一样,beta target encoding 也采用 target mean value (among each category) 来给categorical feature做编码。不同之处在于,为了进一步减少target variable leak,beta target encoding发生在在5-fold CV内部,而不是在5-fold CV之前:
把train data划分为5-folds (5-fold cross validation)
target encoding based on infold data
train model
get out of fold prediction
同时beta target encoding 加入了smoothing term,用 bayesian mean 来代替mean。Bayesian mean (Bayesian average) 的思路:某一个category如果数据量较少( 另外,对于target encoding和beta target encoding,不一定要用target mean (or bayesian mean),也可以用其他的统计值包括 medium, frqequency, mode, variance, skewness, and kurtosis — 或任何与target有correlation的统计值。 M-Estimate Encoding 相当于 一个简化版的Target Encoding: 其中????+代表所有正Label的个数,m是一个调参的参数,m越大过拟合的程度就会越小,同样的在处理连续值时????+可以换成label的求和,????+换成所有label的求和。 一种基于目标的算法是 James-Stein 编码。算法的思想很简单,对于特征的每个取值 k 可以根据下面的公式获得: 其中B由以下公式估计: 但是它有一个要求是target必须符合正态分布,这对于分类问题是不可能的,因此可以把y先转化成概率的形式。在实际操作中,可以使用网格搜索方法来选择一个较优的B值。 Weight Of Evidence 同样是基于target的方法。 使用WOE作为变量,第i类的WOE等于: WOE特别合适逻辑回归,因为Logit=log(odds)。WOE编码的变量被编码为统一的维度(是一个被标准化过的值),变量之间直接比较系数即可。 这个方法类似于SUM的方法,只是在计算训练集每个样本的特征值转换时都要把该样本排除(消除特征某取值下样本太少导致的严重过拟合),在计算测试集每个样本特征值转换时与SUM相同。可见以下公式: 使用二进制编码对每一类进行编号,使用具有log2N维的向量对N类进行编码。以 (0,0) 为例,它表示第一类,而 (0,1) 表示第二类,(1,0) 表示第三类,(1,1) 则表示第四类 类似于One-hot encoding,但是通过hash函数映射到一个低维空间,并且使得两个类对应向量的空间距离基本保持一致。使用低维空间来降低了表示向量的维度。 特征哈希可能会导致要素之间发生冲突。一个哈希编码的好处是不需要指定或维护原变量与新变量之间的映射关系。因此,哈希编码器的大小及复杂程度不随数据类别的增多而增多。 和WOE相似,只是去掉了log,即: Jumlah mengekod ciri tertentu dengan membandingkan nilai min label (atau pembolehubah lain yang berkaitan) di bawah nilai ciri dengan nilai min perbezaan label keseluruhan antara mereka untuk mengekod ciri. Jika perincian tidak dilakukan dengan baik, kaedah ini sangat terdedah kepada overfitting, jadi ia perlu digabungkan dengan kaedah leave-one-out atau validasi silang lima kali ganda untuk mengekod ciri. Terdapat juga kaedah untuk menambah tempoh penalti berdasarkan varians untuk mengelakkan overfitting. Pengekodan Helmert biasanya digunakan dalam ekonometrik. Selepas pengekodan Helmert (setiap nilai dalam ciri kategori sepadan dengan baris dalam matriks Helmert), pekali pembolehubah yang dikodkan dalam model linear boleh mencerminkan nilai min pembolehubah bersandar diberi nilai kategori tertentu bagi pembolehubah kategori cara pembolehubah bersandar diberi nilai untuk kategori lain dalam kategori itu. Pengekodan topi keledar ialah kaedah pengekodan yang paling banyak digunakan selepas Pengekodan Satu Panas dan Pengekod Sum Berbeza daripada Pengekod Sum, ia membandingkan label yang sepadan (atau pembolehubah lain yang berkaitan) di bawah nilai ciri tertentu). min ciri-ciri sebelumnya, bukannya min semua ciri. Ciri ini juga terdedah kepada overfitting. Untuk pembolehubah kategori yang bilangan nilai yang mungkin lebih besar daripada nombor maksimum satu panas, CatBoost menggunakan kaedah pengekodan yang sangat berkesan, yang serupa dengan pengekodan min ia boleh mengurangkan overfitting. Kaedah pelaksanaan khususnya adalah seperti berikut: Isih set sampel input secara rawak dan jana berbilang kumpulan susunan rawak. Tukar titik terapung atau teg nilai atribut kepada integer. Tukar semua hasil nilai ciri pengelasan kepada hasil berangka mengikut formula berikut. Di mana CountInClass mewakili bilangan sampel yang mempunyai nilai markah 1 dalam nilai ciri pengelasan semasa ialah nilai awal molekul, ditentukan berdasarkan parameter awal. TotalCount mewakili bilangan semua sampel dengan nilai ciri klasifikasi yang sama seperti sampel semasa, termasuk sampel semasa itu sendiri. Ringkasan pemprosesan CatBoost Ciri kategori: Pertama, mereka akan mengira statistik beberapa data. Kira kekerapan kejadian kategori, tambah hiperparameter dan jana ciri berangka baharu. Strategi ini memerlukan data dengan label yang sama tidak boleh disusun bersama-sama (iaitu, semua 0s dahulu dan kemudian semua 1s), dan set data perlu dikacau sebelum latihan. Kedua, gunakan pilih atur data yang berbeza (sebenarnya 4). Sebelum membina pokok setiap pusingan, satu pusingan dadu dilemparkan untuk menentukan susunan yang akan digunakan untuk membina pokok itu. Perkara ketiga ialah mempertimbangkan untuk mencuba kombinasi ciri kategori yang berbeza. Contohnya, warna dan jenis boleh digabungkan untuk membentuk ciri yang serupa dengan anjing biru. Apabila bilangan ciri kategori yang perlu digabungkan meningkat, catboost hanya mempertimbangkan beberapa kombinasi. Apabila memilih nod pertama, hanya satu ciri, seperti A, dipertimbangkan. Apabila menjana nod kedua, pertimbangkan gabungan A dan mana-mana ciri kategori dan pilih yang terbaik. Dengan cara ini, algoritma tamak digunakan untuk menghasilkan kombinasi. Keempat, melainkan jika dimensinya sangat kecil seperti jantina, tidak disyorkan untuk menjana vektor satu-panas sendiri Sebaik-baiknya menyerahkannya kepada algoritma. # train -> training dataframe
# test -> test dataframe
# N_min -> smoothing term, minimum sample size, if sample size is less than N_min, add up to N_min
# target_col -> target column
# cat_cols -> categorical colums
# Step 1: fill NA in train and test dataframe
# Step 2: 5-fold CV (beta target encoding within each fold)
kf = KFold(n_splits=5, shuffle=True, random_state=0)
for i, (dev_index, val_index) in enumerate(kf.split(train.index.values)):
# split data into dev set and validation set
dev = train.loc[dev_index].reset_index(drop=True)
val = train.loc[val_index].reset_index(drop=True)
feature_cols = []
for var_name in cat_cols:
feature_name = f'{var_name}_mean'
feature_cols.append(feature_name)
prior_mean = np.mean(dev[target_col])
stats = dev[[target_col, var_name]].groupby(var_name).agg(['sum', 'count'])[target_col].reset_index()
### beta target encoding by Bayesian average for dev set
df_stats = pd.merge(dev[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
dev[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for val set
df_stats = pd.merge(val[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
val[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
### beta target encoding by Bayesian average for test set
df_stats = pd.merge(test[[var_name]], stats, how='left')
df_stats['sum'].fillna(value = prior_mean, inplace = True)
df_stats['count'].fillna(value = 1.0, inplace = True)
N_prior = np.maximum(N_min - df_stats['count'].values, 0) # prior parameters
test[feature_name] = (prior_mean * N_prior + df_stats['sum']) / (N_prior + df_stats['count']) # Bayesian mean
# Bayesian mean is equivalent to adding N_prior data points of value prior_mean to the data set.
del df_stats, stats
# Step 3: train model (K-fold CV), get oof predictioM-Estimate Encoding
James-Stein Encoding
Weight of Evidence Encoder
Leave-one-out Encoder (LOO or LOOE)
Binary Encoding
Hashing Encoding
Probability Ratio Encoding
Pengekod Jumlah (Pengekod Sisihan, Pengekod Kesan)
Pengekodan Helmert
Pengekodan CatBoost
Atas ialah kandungan terperinci Apakah kaedah untuk memproses ciri kategori dalam pembelajaran mesin Python?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!