
Rumah >Peranti teknologi >AI >Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini
Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini

- 王林ke hadapan
- 2023-06-02 22:24:291759semak imbas
Lajur Jantung Mesin
Jabatan Editorial Jantung Mesin
Kadar kejayaan penipuan AI adalah sangat tinggi Beberapa hari yang lalu, "4.3 juta ditipu dalam 10 minit" adalah topik carian hangat. Membina model bahasa besar yang paling hangat, penyelidik baru-baru ini meneroka kaedah pengecaman.
Dengan kemajuan berterusan model generatif besar, korpus yang mereka hasilkan secara beransur-ansur menghampiri manusia. Walaupun model besar membebaskan tangan kerani yang tidak terkira banyaknya, keupayaan kuat mereka untuk memalsukan yang palsu juga telah digunakan oleh beberapa penjenayah, menyebabkan beberapa siri masalah sosial:



Penyelidik dari Universiti Peking dan Huawei telah mencadangkan pengesan teks yang boleh dipercayai untuk mengenal pasti pelbagai korpora yang dijana AI. Mengikut ciri berbeza teks panjang dan pendek, kaedah latihan pengesan teks yang dijana AI berbilang skala berdasarkan pembelajaran PU dicadangkan. Dengan menambah baik proses latihan pengesan, peningkatan besar dalam keupayaan pengesanan pada korpus ChatGPT panjang dan pendek boleh dicapai di bawah keadaan yang sama, menyelesaikan titik kesakitan ketepatan rendah pengecaman teks pendek oleh pengesan semasa.

Alamat kertas:
https://arxiv.org/abs/2305.18149
Alamat kod (MindSpore):
https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
Alamat kod (PyTorch):
https://github.com/YuchuanTian/AIGC_text_detector
Pengenalan
Memandangkan kesan penjanaan model bahasa besar menjadi semakin realistik, pelbagai industri memerlukan pengesan teks janaan AI yang boleh dipercayai dengan segera. Walau bagaimanapun, industri yang berbeza mempunyai keperluan yang berbeza untuk korpus pengesanan Sebagai contoh, dalam akademik, secara amnya perlu untuk mengesan teks akademik yang besar dan lengkap pada platform sosial, berita palsu yang agak pendek dan berpecah-belah perlu dikesan. Walau bagaimanapun, pengesan sedia ada selalunya tidak dapat memenuhi pelbagai keperluan. Sebagai contoh, sesetengah pengesan teks AI arus perdana umumnya mempunyai keupayaan ramalan yang lemah untuk korpus yang lebih pendek.
Mengenai kesan pengesanan berbeza korpus dengan panjang yang berbeza, penulis memerhatikan bahawa mungkin terdapat beberapa "ketidakpastian" dalam atribusi teks yang dijana AI yang lebih pendek atau secara lebih terang, kerana beberapa ayat pendek yang dijana AI adalah selalunya juga Ia digunakan oleh manusia, jadi sukar untuk menentukan sama ada teks pendek yang dihasilkan oleh AI berasal dari manusia atau AI. Berikut ialah beberapa contoh manusia dan AI yang menjawab soalan yang sama:

Seperti yang dapat dilihat daripada contoh-contoh ini, sukar untuk mengenal pasti jawapan ringkas yang dijana oleh AI: perbezaan antara jenis korpus ini dan manusia adalah terlalu kecil, dan sukar untuk menilai dengan ketat sifat-sifatnya yang sebenar. Oleh itu, adalah tidak wajar untuk hanya menganotasi teks pendek sebagai manusia/AI dan melakukan pengesanan teks mengikut masalah pengelasan binari tradisional.
Untuk menangani masalah ini, kajian ini mengubah bahagian pengesanan klasifikasi binari manusia/AI kepada masalah pembelajaran PU (Positif-Tidak Berlabel) separa, iaitu, dalam ayat yang lebih pendek, bahasa manusia adalah positif (Positif), dan mesin Bahasa ini adalah Tidak Berlabel, yang meningkatkan fungsi kehilangan latihan. Peningkatan ini dengan ketara meningkatkan prestasi pengelasan pengesan pada pelbagai korpora.
Butiran algoritma
Di bawah tetapan pembelajaran PU tradisional, model klasifikasi binari hanya boleh belajar berdasarkan sampel latihan positif dan sampel latihan tidak berlabel. Kaedah pembelajaran PU yang biasa digunakan adalah untuk menganggarkan kerugian klasifikasi binari yang sepadan dengan sampel negatif dengan merumuskan kehilangan PU:
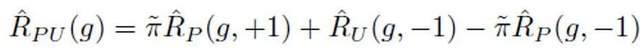
Antaranya, mewakili kerugian klasifikasi binari yang dikira dengan menganggap sampel positif dan label positif mewakili kerugian klasifikasi binari yang dikira dengan menganggap semua sampel tidak berlabel sebagai label negatif mewakili kerugian klasifikasi binari yang dikira dengan menganggap sampel positif sebagai label negatif; mewakili Kebarangkalian sampel positif terdahulu ialah anggaran bahagian sampel positif dalam semua sampel PU. Dalam pembelajaran PU tradisional, prior biasanya ditetapkan kepada hiperparameter tetap. Walau bagaimanapun, dalam senario pengesanan teks, pengesan perlu memproses pelbagai teks dengan panjang yang berbeza, anggaran nisbah sampel positif antara semua sampel PU yang sama panjang dengan sampel juga berbeza. Oleh itu, kajian ini menambah baik PU Loss dan mencadangkan fungsi kehilangan PU (MPU) berskala sensitif panjang.
Secara khusus, kajian ini mencadangkan model berulang abstrak untuk memodelkan pengesanan teks yang lebih pendek. Apabila model NLP tradisional memproses jujukan, mereka biasanya mempunyai struktur rantai Markov, seperti RNN, LSTM, dsb. Proses model kitaran jenis ini biasanya boleh difahami sebagai proses berulang secara beransur-ansur, iaitu, ramalan setiap keluaran token diperoleh dengan mengubah dan menggabungkan hasil ramalan token sebelumnya dan urutan sebelumnya dengan hasil ramalan ini. token. Itulah proses berikut:
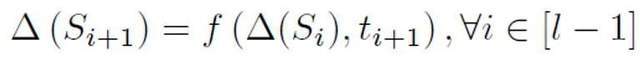
Untuk menganggarkan kebarangkalian terdahulu berdasarkan model abstrak ini, adalah perlu untuk menganggap bahawa output model adalah keyakinan bahawa ayat tertentu adalah positif, iaitu kebarangkalian ia dinilai sebagai sampel dituturkan oleh seseorang. Diandaikan bahawa saiz sumbangan setiap token ialah perkadaran songsang bagi panjang token ayat, ia adalah positif, iaitu, tidak berlabel, dan kebarangkalian untuk tidak dilabel adalah jauh lebih besar daripada kebarangkalian untuk menjadi positif. Kerana apabila perbendaharaan kata model besar secara beransur-ansur menghampiri manusia, kebanyakan perkataan akan muncul dalam kedua-dua AI dan korpora manusia. Berdasarkan model yang dipermudahkan ini dan kebarangkalian token positif yang ditetapkan, anggaran akhir terakhir diperoleh dengan mencari jumlah jangkaan keyakinan output model di bawah keadaan input yang berbeza.
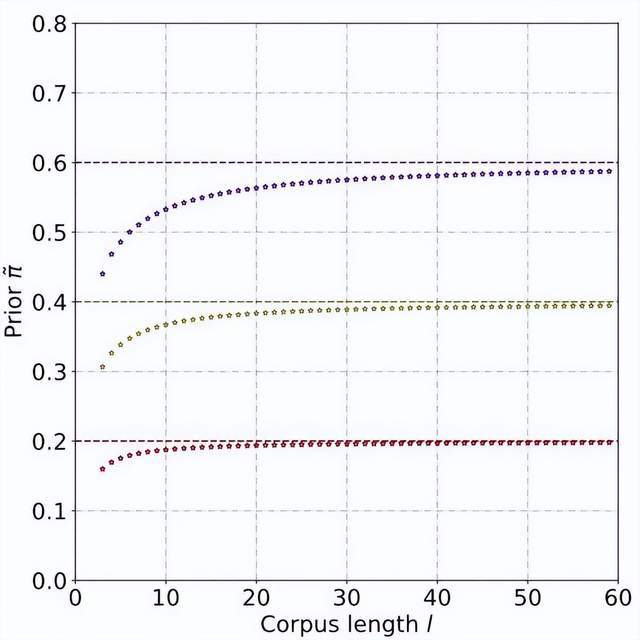
Melalui terbitan teori dan eksperimen, dianggarkan bahawa kebarangkalian terdahulu meningkat apabila panjang teks bertambah, dan akhirnya menjadi stabil. Fenomena ini juga dijangka, kerana apabila teks menjadi lebih panjang, pengesan boleh menangkap lebih banyak maklumat dan "ketidakpastian sumber" teks secara beransur-ansur melemah:
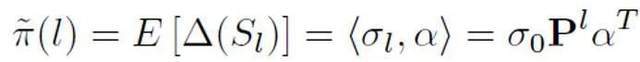
Selepas itu, bagi setiap sampel positif, kehilangan PU dikira berdasarkan sebelumnya unik yang diperoleh daripada panjang sampelnya. Akhir sekali, memandangkan teks yang lebih pendek hanya mempunyai beberapa "ketidakpastian" (iaitu, teks yang lebih pendek juga akan mengandungi ciri teks sesetengah orang atau AI), kehilangan binari dan kehilangan MPU boleh ditimbang dan ditambah sebagai matlamat pengoptimuman akhir:
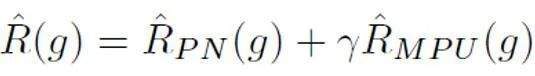
Selain itu, perlu diingatkan bahawa kehilangan MPU menyesuaikan diri dengan korpus latihan pelbagai panjang. Jika data latihan sedia ada jelas homogen dan kebanyakan korpus terdiri daripada teks yang panjang dan panjang, kaedah MPU tidak dapat melaksanakan keberkesanannya sepenuhnya. Bagi menjadikan panjang korpus latihan lebih pelbagai, kajian ini turut memperkenalkan modul multi-skala pada peringkat ayat. Modul ini secara rawak merangkumi beberapa ayat dalam korpus latihan dan menyusun semula ayat yang tinggal sambil mengekalkan susunan asal. Selepas operasi berbilang skala korpus latihan, teks latihan telah diperkaya panjangnya, dengan itu menggunakan sepenuhnya pembelajaran PU untuk latihan pengesan teks AI.
Hasil percubaan

Seperti yang ditunjukkan dalam jadual di atas, penulis mula-mula menguji kesan kehilangan MPU pada set data korpus janaan AI yang lebih pendek Tweep-Fake. Korpus dalam set data ini semuanya adalah segmen yang agak pendek di Twitter. Penulis juga menggantikan kehilangan dua kategori tradisional dengan matlamat pengoptimuman yang mengandungi kehilangan MPU berdasarkan penalaan halus model bahasa tradisional. Pengesan model bahasa yang dipertingkatkan adalah lebih berkesan dan mengatasi algoritma garis dasar yang lain.
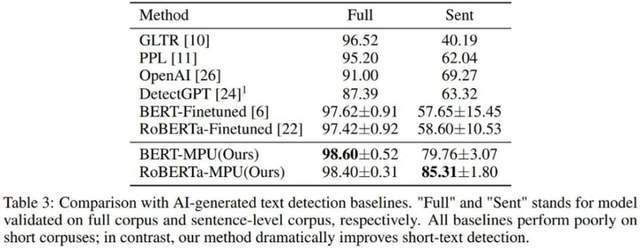
Pengarang juga menguji teks yang dijana oleh chatGPT Pengesan model bahasa yang diperolehi melalui penalaan halus tradisional berprestasi buruk pada ayat pendek yang dilatih dalam keadaan yang sama melalui kaedah MPU berprestasi baik pada ayat pendek, dan Pada masa yang sama , ia boleh mencapai peningkatan prestasi yang besar pada korpus lengkap, dengan skor F1 meningkat sebanyak 1%, mengatasi algoritma SOTA seperti OpenAI dan DetectGPT.
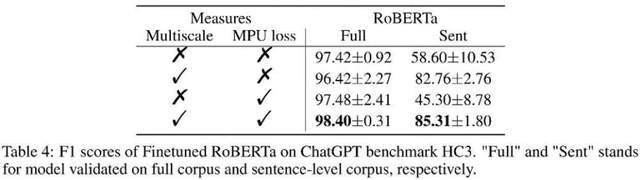
Seperti yang ditunjukkan dalam jadual di atas, penulis memerhatikan keuntungan kesan yang dibawa oleh setiap bahagian dalam eksperimen ablasi. Kehilangan MPU meningkatkan kesan pengelasan bahan panjang dan pendek.

Pengarang juga membandingkan PU tradisional dan PU Berbilang Skala (MPU). Dapat dilihat daripada jadual di atas bahawa kesan MPU adalah lebih baik dan boleh menyesuaikan diri dengan tugas pengesanan teks pelbagai skala AI.
Ringkasan
Pengarang menyelesaikan masalah pengecaman ayat pendek oleh pengesan teks dengan mencadangkan penyelesaian berdasarkan pembelajaran PU berskala besar Dengan percambahan model generasi AIGC pada masa hadapan, pengesanan kandungan jenis ini akan menjadi semakin penting. Penyelidikan ini telah mengambil langkah yang kukuh ke hadapan dalam isu pengesanan teks AI Diharapkan akan ada lebih banyak penyelidikan serupa pada masa hadapan untuk mengawal kandungan AIGC dengan lebih baik dan mencegah penyalahgunaan kandungan yang dihasilkan oleh AI.
Atas ialah kandungan terperinci Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI