
Rumah >pangkalan data >tutorial mysql >Apakah situasi di mana pengoptimuman indeks MySQL sesuai untuk membina indeks?
Apakah situasi di mana pengoptimuman indeks MySQL sesuai untuk membina indeks?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-02 21:08:411432semak imbas
Kesimpulan
Buat indeks pada medan penapis selepas tempat (di mana selepas pilih/kemas kini/padam boleh digunakan), gunakan indeks untuk mempercepatkan kecekapan penapisan, tanpa perlu lakukan keseluruhan jadual Imbas
untuk menambah indeks unik pada medan dengan keperluan unik untuk mempercepatkan kecekapan pertanyaan Jika ditemui, anda boleh terus mengembalikan
kumpulan mengikut atau perintah Tambahkan indeks pada medan selepas oleh Memandangkan indeks diisih, mewujudkan indeks adalah sama dengan mengisihnya sebelum membuat pertanyaan (di sini anda perlu memberi perhatian kepada susunan medan dalam penubuhan indeks bersama, yang mana boleh digabungkan dengan senario kes tertentu 7 Kajian)
Tambahkan indeks pada medan selepas DISTINCT (medan deduplikasi Memandangkan indeks diwujudkan, data yang sama berada di sebelah satu sama lain). supaya anda boleh mengalih keluarnya dengan cepat. Ulangi operasi, jika tidak, anda mungkin perlu mencari data yang sama dan melakukan operasi penyahduplikasian
Apabila menyertai berbilang jadual, buat indeks pada medan yang disambungkan ( meja kecil memacu meja besar )
Ambil awalan tertentu rentetan untuk mencipta indeks (jangan gunakan keseluruhan rentetan sebagai indeks, jika tidak, ia akan mengambil terlalu banyak ruang)
Buat indeks pada lajur yang kerap digunakan (indeks bersama boleh dibina dan medan yang paling kerap digunakan hendaklah berada di sebelah kiri indeks bersama, prinsip paling kiri)
dalam kecemerlangan tinggi Cipta indeks pada lajur (kunci utama mempunyai perbezaan tertinggi, kerana semua kunci adalah unik)
Senario mencipta indeks
Senario 1: di belakang medan tempat Medan diindeks
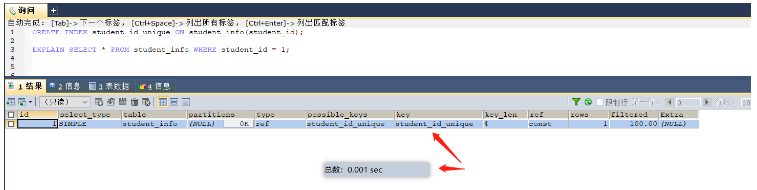
-- 描述:当where中有多个条件需要进行匹配的时候,那么可以创建联合索引,这样所有的条件都可以使用索引,大大提高了检索的效率 select * from student_info where student_id = 1; -- 当然数据量比较大的时候给where后面的字段添加索引 create index student_id_index on student_info (student_id)
Sebelum menambah indeks, ia mengambil masa 0.383 saat, pada asasnya melintasi seluruh jadual

Selepas menambah indeks, ia mengambil masa 0.001 saat, dan indeks telah digunakan (Tetapi ia akan mengambil masa tertentu untuk mencipta indeks)
Dalam perniagaan yang kerap pertanyaan, anda boleh membuat indeks pada medan yang ditapis mengikut tempat Jika terdapat berbilang medan ditapis mengikut tempat Anda juga boleh membina indeks bersama
Senario 2: Buat indeks unik pada medan dengan kekangan unik (cari. sasaran dan kembali tanpa terus mencari)
select * from student_info where id = 1001; -- 因为学号是唯一的,所以可以在学号这个字段上添加唯一所用 create index id_unique on student_info(id);
Pada medan dengan kekangan unik Anda boleh mencipta indeks unik Walaupun mewujudkan indeks unik akan memberi kesan tertentu pada operasi sisipan (anda perlu menentukan sama ada data yang baru ditambah sudah ada dalam jadual), mewujudkan indeks unik akan meningkatkan kecekapan pertanyaan dengan ketara Sebagai contoh, dalam contoh di atas, Kerana indeks unik ditubuhkan, apabila maklumat pelajar dengan ID 1001 ditemui, terdapat. tidak perlu menentukan sama ada terdapat pelajar lain dengan ID bersamaan dengan 1001 dalam pangkalan data (hanya terdapat satu salinan), dan maklumat boleh dikembalikan secara langsung Jika tiada indeks ditetapkan, maka Imbasan jadual penuh diperlukan
Senario 3: Indeks sering dibuat pada medan kumpulan mengikut dan tertib mengikut (kerana indeks itu sendiri diisih, yang bersamaan dengan mengisih sebelum pertanyaan)
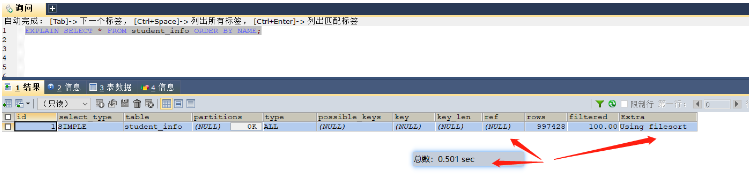
select * from student_info order by name; -- 这里就可以给name字段进行索引的添加 select * from student_info group by class_id; -- 这里就可以给class_id字段添加索引
Sebelum pengindeksan, ia mengambil masa 0.501 saat. Semua data diisih dalam ingatan
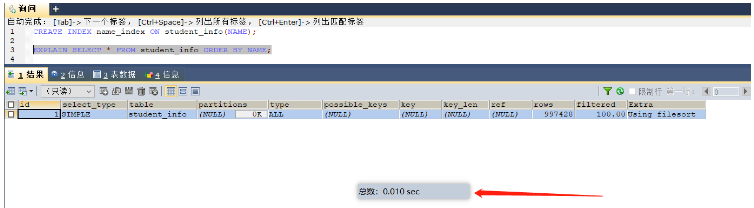
Selepas pengindeksan, ia mengambil masa 0.01 saat
Senario 4: Tambahkan indeks ke medan selepas DISTINCT (indeks telah mengisih medan yang sama, dan kecekapan penyahduplikasian lebih tinggi)
select distinct(student_id) from student_info; -- 这里就可以根据student_id字段建立索引 create index student_id_index on student_info;
telah menetapkan indeks, maka lalainya adalah untuk mengikuti Jika medan indeks disusun dalam tertib menaik, maka medan dengan nilai yang sama akan disusun bersama, dan penyahduplikasian akan menjadi mudah dan cekap
Senario 5: Mewujudkan medan gabungan dalam sambungan gabungan berbilang jadual dalam jadual besar Sebelum mengindeks
SELECT s.course_id,NAME,s.student_id,c.course_name FROM student_info s JOIN course c ON s.`course_id` = c.`course_id` WHERE NAME = 'xiaoyuanhao'; -- 根据大表驱动小表的原则需要在student_info表的course_id字段上建立索引
, ia mengambil masa 0.697s tanpa mengindeks
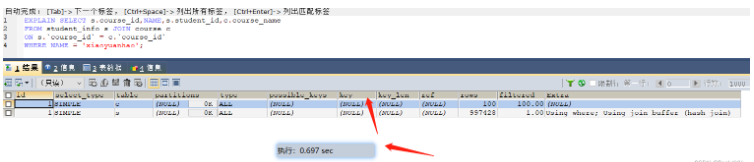
, selepas mengindeks, ia mengambil masa 0.003s
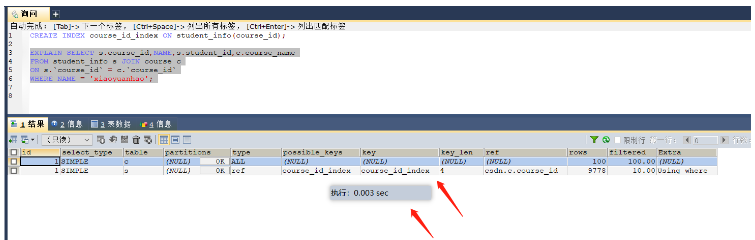
Meja kecil memacu meja besar:
Dengan merentasi jadual kecil satu demi satu dan mengindeks medan sambungan dalam jadual besar, anda boleh mempercepatkan pertanyaan Dalam kes ini, setiap kali course_id dalam jadual kursus dan course_id pelajar dalam pelajar jadual dikeluarkan dan disambungkan, dan course_id diindeks dalam jadual pelajar
Senario 6: Gunakan awalan rentetan untuk mencipta indeks
create table shop(address varchar(120) not null); alter table shop add index(address(12)); --这里只是对表中的address的前12个字符建立了索引,而不是整个字符串建立索引
Sebab pengindeksan awalan:
Memandangkan beberapa rentetan adalah sangat panjang, jika keseluruhan rentetan diindeks, indeks akan mengambil banyak ruang
Memandangkan keseluruhan rentetan perlu disimpan, item data akan menjadi sangat besar, jadi kedalaman pepohon indeks akan diperdalam, dan kelajuan perolehan akan berkurangan
Walaupun ia mungkin muncul dalam indeks Kedua-dua rentetan adalah sama, tetapi operasi pemulangan jadual berdasarkan kunci utama masih lebih cekap
如何确定前缀索引中前缀的长度呢?(也就是如果前缀的长度太短,那么索引的区分度就很低,从多个字符串截取的前缀数据可能都是一样的,但是如果前缀索引的前缀过长,那么前缀索引的优点就消失了)
引入了区别度的概念,select count(distinct left(索引字段,前缀索引长度) / count(*) from xxx),该值越接近1,那么区分度就越明显,那么该索引长度就是所求的前缀索引长度
场景七:在频繁使用的列上建立索引或联合索引(频繁使用的字段应该在索引的左侧)
select * from xiaoyuanhao where age = 18; select * from xiaoyuanhao where age = 19 and sex = 'man'; select * from xiaoyuanhao where age = 10 and sex = 'man' and password = '123456'; -- 在这里实际上就可以建立age,sex,password的联合索引,只需要建立一个索引,这三个查询都是可以使用的 create index age_sex_password_index on xiaoyuanhao(age,sex,password); select * from student_info group by class_id order by name; -- 在这里可以建立class_id和name的联合索引,但是一定要注意索引的顺序,一定是要class_id在前,name在后,因为在select语句中执行的顺序是先group by 之后才是 order by 索引如果索引的字段顺序是相反的,那么就无法使用索引 create index class_id_name_index on student(class_id,name);
索引建立需要符合顺序的原因:
索引字段的顺序如果是错误的,那么索引就会失效,因为索引实际上是排好序的,如果索引建立的时候是现根据name排好序之后在根据class_id进行排序,那么在面对需要先根据class_id排序再根据name排序的业务就无法进行使用
补充:
在select * from xxx where age = 19 and sex = ‘man’ and password = '123456’这里索引建立的顺序不一定是(age,sex,password)因为在实际执行的过程中,优化器会优化执行步骤会按照索引的顺序进行查询,但是group by 和 order by的执行顺序是无法改变的,索引必须严格的按照顺序建立索引,否则索引失效
Atas ialah kandungan terperinci Apakah situasi di mana pengoptimuman indeks MySQL sesuai untuk membina indeks?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!