
Rumah >pangkalan data >Redis >Kaedah pemprosesan data Python Redis
Kaedah pemprosesan data Python Redis

- 王林ke hadapan
- 2023-06-02 20:19:251382semak imbas
1. Kata Pengantar
Redis: Pelayan Kamus Jauh, iaitu: perkhidmatan kamus jauh Lapisan bawah Redis ditulis dalam bahasa C Ia adalah pangkalan data NoSql berasaskan memori
Kerana Redis Prestasi jauh melebihi pangkalan data lain, dan ia menyokong pengelompokan, pengedaran, penyegerakan tuan-hamba dan kelebihan lain, jadi ia sering digunakan dalam senario seperti data caching, membaca dan menulis berkelajuan tinggi2. PersediaanKami akan menggunakan Cloud Server Centos 7.8 Memasang Redis-Server sebagai contohPertama, pasang pangkalan data Redis pada pelayan awan# 下载epel仓库 yum install epel-release # 安装redis yum install redisKemudian, ubah suai fail konfigurasi Redis melalui arahan vim, buka sambungan jauh dan tetapkan kata laluan sambunganDirektori fail konfigurasi: /etc/redis.conf
- bind ditukar kepada 0.0.0.0, membenarkan akses rangkaian luaran
- requirepass Tetapkan kata laluan akses
# vim /etc/redis.conf # 1、bing从127.0.0.1修改为:0.0.0.0,开放远程连接 bind 0.0.0.0 # 2、设置密码 requirepass 123456Perlu diingatkan bahawa mengikut urutan untuk memastikan keselamatan data pelayan awan, apabila Redis membuka akses jauh, kata laluan mesti diperkukuhkanKemudian, mulakan perkhidmatan Redis, buka firewall dan port, konfigurasikan kumpulan keselamatan pelayan awan Secara lalai, nombor port yang digunakan oleh perkhidmatan Redis ialah 6379Selain itu, anda perlu mengkonfigurasi kumpulan keselamatan pelayan awan untuk memastikan pangkalan data Redis Boleh menyambung secara normal
# 启动Redis服务,默认redis端口号是6379 systemctl start redis # 打开防火墙 systemctl start firewalld.service # 开放6379端口 firewall-cmd --zone=public --add-port=6379/tcp --permanent # 配置立即生效 firewall-cmd --reloadSelepas melengkapkan operasi di atas, kita boleh menyambung melalui alat klien Redis-CLI atau RedisAkhir sekali, untuk menggunakan Python untuk mengendalikan Redis, kita perlu menggunakan pip untuk memasang pergantungan
# 安装依赖,便于操作redis pip3 install redis3 🎜>
Sebelum mengendalikan data dalam Redis, kami perlu menggunakan Hos, nombor port dan kata laluan untuk membuat seketika objek sambungan Redis
from redis import Redis
class RedisF(object):
def __init__(self):
# 实例化Redis对象
# decode_responses=True,如果不加则写入的为字节类型
# host:远程连接地址
# port:Redis端口号
# password:Redis授权密码
self.redis_obj = Redis(host='139.199.**.**',port=6379,password='123456',decode_responses=True,charset='UTF-8', encoding='UTF-8')Seterusnya kami menggunakan Mengambil operasi rentetan, senarai, koleksi set , koleksi zset, jadual cincang dan urus niaga sebagai contoh, mari kita bincangkan tentang kaedah mengendalikan data ini dalam Python
1 Operasi Rentetan
Terdapat dua cara untuk mengendalikan rentetan Dengan cara ini, iaitu. kaedah operasi ialah: set() dan mset()
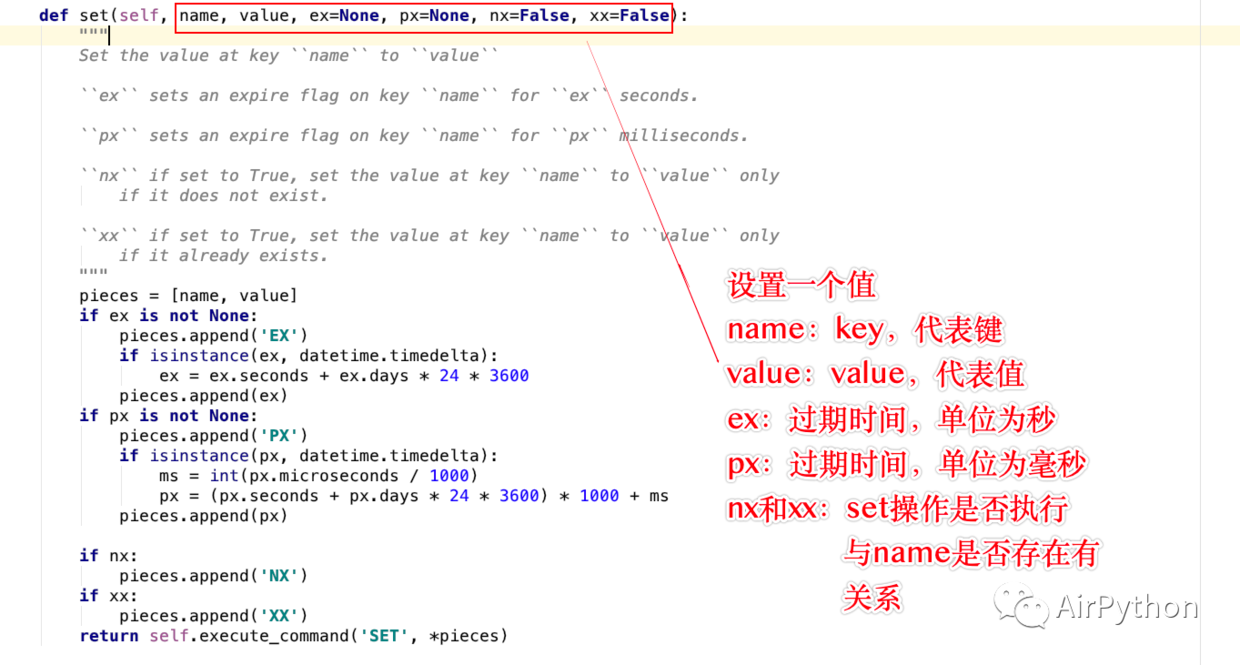
Antaranya: set() hanya boleh menyimpan satu nilai pada satu masa, maksud parameter adalah seperti berikut
- nama: kunci, mewakili kunci
- nilai: nilai, nilai yang hendak disimpan
- cth: masa tamat tempoh, dalam saat, jika tidak ditetapkan, maka ia tidak akan tamat tempoh; jika tidak, ia akan dipadamkan jika ia tamat tempoh
- px: masa tamat tempoh, dalam milisaat
- nx/ xx: sama ada operasi yang ditetapkan adalah Perlaksanaan berkaitan sama ada kekunci nama wujud
 Kaedah operasi untuk mendapatkan dan memadam nilai ialah: dapatkan (Key), delete(Key or Keys)
Kaedah operasi untuk mendapatkan dan memadam nilai ialah: dapatkan (Key), delete(Key or Keys)
# set():单字符串操作 # 添加一个值,并设置超时时间为120s self.redis_obj.set('name', 'airpython', ex=120) # get():获取这个值 print(self.redis_obj.get('name')) # delete():删除一个值或多个值 self.redis_obj.delete('name') print(self.redis_obj.get('name'))
Untuk penetapan data berbilang nilai, anda hanya perlu memanggil kaedah mset() dan menggunakan pasangan nilai kunci untuk membentuk kamus sebagai parameter untuk data yang akan dimasukkan
Begitu juga, Redis menyediakan Kaedah mget() boleh memperoleh nilai berbilang kunci sekaligus
# mset():设置多个值
self.redis_obj.mset({"foo": "foo1", "zoo": "zoo1"})
# mget():获取多个值
result = self.redis_obj.mget("foo", "zoo")
print(result)2 >Redis menyediakan banyak kaedah untuk mengendalikan senarai, antaranya yang lebih biasa adalah seperti berikut:
lpush/rpush: Masukkan satu atau lebih nilai ke dalam kepala atau ekor senarai , dengan lpush mewakili sisipan kepala; rpush mewakili sisipan ekor data
lset: Masukkan nilai ke dalam kedudukan yang sepadan dalam senarai melalui indeks
linsert: Sisipkan data sebelum atau selepas elemen senarai
lindex : Dapatkan elemen dalam senarai melalui indeks, dengan 0 mewakili elemen pertama
julat: Dengan menyatakan kedudukan permulaan dan kedudukan penamat, daripada Dapatkan nilai kawasan yang ditentukan dalam senarai
llen: Dapatkan panjang senarai. Jika senarai yang sepadan dengan Kunci tidak wujud, kembalikan 0
lpop: Alih keluar dan kembalikan elemen pertama dalam senarai
rpop: Alih keluar dan kembalikan elemen terakhir dalam senarai
-
Kod contoh adalah seperti berikut :
def manage_list(self): """ 操作列表 :return: """ # 1、新增一个列表,并左边插入一个数据 # 注意:可以一次加入多个元素,也可以一个个元素的加入 self.redis_obj.lpush('company', '阿里', '腾讯', '百度') # 2、移除第一个元素 self.redis_obj.lpop("company") # 3、右边插入数据 self.redis_obj.rpush('company', '字节跳动', '小米') # 4、移除最后一个元素 self.redis_obj.rpop("company") # 5、获取列表的长度 self.redis_obj.llen("company") # 6、通过索引,获取列表中的某一个元素(第二个元素) print('列表中第二个元素是:', self.redis_obj.lindex("company", 1)) # 7、根据范围,查看列表中所有的值 print(self.redis_obj.lrange('company', 0, -1))3 Set Operasi
Set ialah koleksi elemen yang tidak teratur Elemen dalam set tidak boleh diulang Redis juga menyediakan banyak kaedah untuk memudahkan operasi koleksi Set
Antaranya, kaedah yang lebih biasa digunakan adalah seperti berikut:
sedih: Tambahkan elemen pada koleksi Elemen yang sudah ada dalam koleksi akan diabaikan. : Mengembalikan bilangan elemen dalam set
smembers: Mengembalikan semua elemen dalam set
srem : Keluarkan satu atau lebih elemen daripada set, abaikan jika elemen tidak wujud
sinter: Kembalikan persilangan dua set, hasilnya masih menjadi set
sunion: Mengembalikan gabungan dua set
sdiff: Menggunakan parameter set pertama sebagai standard, mengembalikan perbezaan dua set
sunionstore: Kira gabungan dua set dan simpan ke set baharu
sismember: Tentukan sama ada unsur wujud dalam set
spop: Padam secara rawak elemen dalam set dan kembalikan
-
Kod contoh khusus adalah seperti berikut:
def manage_set(self): """ 操作set集合 :return: """ self.redis_obj.delete("fruit") # 1、sadd:新增元素到集合中 # 添加一个元素:香蕉 self.redis_obj.sadd('fruit', '香蕉') # 再添加两个元素 self.redis_obj.sadd('fruit', '苹果', '桔子') # 2、集合元素的数量 print('集合元素数量:', self.redis_obj.scard('fruit')) # 3、移除一个元素 self.redis_obj.srem("fruit", "桔子") # 再定义一个集合 self.redis_obj.sadd("fruit_other", "香蕉", "葡萄", "柚子") # 4、获取两个集合的交集 result = self.redis_obj.sinter("fruit", "fruit_other") print(type(result)) print('交集为:', result) # 5、获取两个集合的并集 result = self.redis_obj.sunion("fruit", "fruit_other") print(type(result)) print('并集为:', result) # 6、差集,以第一个集合为标准 result = self.redis_obj.sdiff("fruit", "fruit_other") print(type(result)) print('差集为:', result) # 7、合并保存到新的集合中 self.redis_obj.sunionstore("fruit_new", "fruit", "fruit_other") print('新的集合为:', self.redis_obj.smembers('fruit_new')) # 8、判断元素是否存在集合中 result = self.redis_obj.sismember("fruit", "苹果") print('苹果是否存在于集合中', result) # 9、随机从集合中删除一个元素,然后返回 result = self.redis_obj.spop("fruit") print('删除的元素是:', result) # 3、集合中所有元素 result = self.redis_obj.smembers('fruit') print("最后fruit集合包含的元素是:", result)4 Operasi koleksi zset -
Koleksi Zset dipesan dibandingkan kepada koleksi set biasa Elemen dalam koleksi zset termasuk: nilai dan skor, di mana markah digunakan untuk mengisih
其中,比较常用的方法如下:
zadd:往集合中新增元素,如果集合不存在,则新建一个集合,然后再插入数据
zrange:通过起始点和结束点,返回集合中的元素值(不包含分数);如果设置withscores=True,则返回结果会带上分数
zscore:获取某一个元素对应的分数
zcard:获取集合中元素个数
zrank:获取元素在集合中的索引
zrem:删除集合中的元素
zcount:通过最小值和最大值,判断分数在这个范围内的元素个数
实践代码如下:
def manage_zset(self): """ 操作zset集合 :return: """ self.redis_obj.delete("fruit") # 往集合中新增元素:zadd() # 三个元素分别是:"banana", 1/"apple", 2/"pear", 3 self.redis_obj.zadd("fruit", "banana", 1, "apple", 2, "pear", 3) # 查看集合中所有元素(不带分数) result = self.redis_obj.zrange("fruit", 0, -1) # ['banana', 'apple', 'pear'] print('集合中的元素(不带分数)有:', result) # 查看集合中所有元素(带分数) result = self.redis_obj.zrange("fruit", 0, -1, withscores=True) # [('banana', 1.0), ('apple', 2.0), ('pear', 3.0)] print('集合中的元素(带分数)有:', result) # 获取集合中某一个元素的分数 result = self.redis_obj.zscore("fruit", "apple") print("apple对应的分数为:", result) # 通过最小值和最大值,判断分数在这个范围内的元素个数 result = self.redis_obj.zcount("fruit", 1, 2) print("集合中分数大于1,小于2的元素个数有:", result) # 获取集合中元素个数 count = self.redis_obj.zcard("fruit") print('集合元素格式:', count) # 获取元素的值获取索引号 index = self.redis_obj.zrank("fruit", "apple") print('apple元素的索引为:', index) # 删除集合中的元素:zrem self.redis_obj.zrem("fruit", "apple") print('删除apple元素后,剩余元素为:', self.redis_obj.zrange("fruit", 0, -1))4、操作哈希
哈希表中包含很多键值对,并且每一个键都是唯一的
Redis 操作哈希表,下面这些方法比较常用:
hset:往哈希表中添加一个键值对值
hmset:往哈希表中添加多个键值对值
hget:获取哈希表中单个键的值
hmget:获取哈希表中多个键的值列表
hgetall:获取哈希表中种所有的键值对
hkeys:获取哈希表中所有的键列表
hvals:获取哈表表中所有的值列表
hexists:判断哈希表中,某个键是否存在
hdel:删除哈希表中某一个键值对
hlen:返回哈希表中键值对个数
对应的操作代码如下:
def manage_hash(self): """ 操作哈希表 哈希:一个键对应一个值,并且键不容许重复 :return: """ self.redis_obj.delete("website") # 1、新建一个key为website的哈希表 # 往里面加入数据:baidu(field),www.baidu.com(value) self.redis_obj.hset('website', 'baidu', 'www.alibababaidu.com') self.redis_obj.hset('website', 'google', 'www.google.com') # 2、往哈希表中添加多个键值对 self.redis_obj.hmset("website", {"tencent": "www.qq.com", "alibaba": "www.taobao.com"}) # 3、获取某一个键的值 result = self.redis_obj.hget("website", 'baidu') print("键为baidu的值为:", result) # 4、获取多个键的值 result = self.redis_obj.hmget("website", "baidu", "alibaba") print("多个键的值为:", result) # 5、查看hash表中的所有值 result = self.redis_obj.hgetall('website') print("哈希表中所有的键值对为:", result) # 6、哈希表中所有键列表 # ['baidu', 'google', 'tencent', 'alibaba'] result = self.redis_obj.hkeys("website") print("哈希表,所有的键(列表)为:", result) # 7、哈希表中所有的值列表 # ['www.alibababaidu.com', 'www.google.com', 'www.qq.com', 'www.taobao.com'] result = self.redis_obj.hvals("website") print("哈希表,所有的值(列表)为:", result) # 8、判断某一个键是否存在 result = self.redis_obj.hexists("website", "alibaba") print('alibaba这个键是否存在:', result) # 9、删除某一个键值对 self.redis_obj.hdel("website", 'baidu') print('删除baidu键值对后,哈希表的数据包含:', self.redis_obj.hgetall('website')) # 10、哈希表中键值对个数 count = self.redis_obj.hlen("website") print('哈希表键值对一共有:', count)5、操作事务管道
Redis 支持事务管道操作,能够将几个操作统一提交执行
操作步骤是:
首先,定义一个事务管道
然后通过事务对象去执行一系列操作
提交事务操作,结束事务操作
下面通过一个简单的例子来说明:
def manage_steps(self): """ 执行事务操作 :return: """ # 1、定义一个事务管道 self.pip = self.redis_obj.pipeline() # 定义一系列操作 self.pip.set('age', 18) # 增加一岁 self.pip.incr('age') # 减少一岁 self.pip.decr('age') # 执行上面定义3个步骤的事务操作 self.pip.execute() # 判断 print('通过上面一些列操作,年龄变成:', self.redis_obj.get('age'))
Atas ialah kandungan terperinci Kaedah pemprosesan data Python Redis. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!