
Rumah >Peranti teknologi >AI >Fikir, fikir, fikir tanpa henti, Thinking Tree ToT 'Latihan Tentera' LLM
Fikir, fikir, fikir tanpa henti, Thinking Tree ToT 'Latihan Tentera' LLM

- PHPzke hadapan
- 2023-06-02 19:55:371120semak imbas
Model bahasa berskala besar seperti GPT dan PaLM semakin mahir dalam mengendalikan tugas seperti matematik, simbolik, akal sehat dan penaakulan pengetahuan. Mungkin menghairankan, asas untuk semua kemajuan ini kekal sebagai mekanisme autoregresif asal untuk menjana teks. Ia membuat keputusan dengan token dan menjana teks dalam cara kiri ke kanan. Adakah mekanisme mudah sedemikian mencukupi untuk membina model bahasa untuk penyelesai masalah umum? Jika tidak, apakah isu yang akan mencabar paradigma semasa, dan apakah mekanisme alternatif yang harus digunakan?
Sastera tentang kognisi manusia menyediakan beberapa petunjuk untuk menjawab soalan ini. Penyelidikan tentang model "proses dwi" menunjukkan bahawa orang mempunyai dua mod semasa membuat keputusan: satu mod pantas, automatik dan tidak sedarkan diri (Sistem 1), dan satu lagi mod perlahan, sengaja dan sedar (Sistem 2). . Kedua-dua corak ini sebelum ini telah dikaitkan dengan pelbagai model matematik yang digunakan dalam pembelajaran mesin. Sebagai contoh, penyelidikan tentang pembelajaran pengukuhan pada manusia dan haiwan lain meneroka sama ada mereka terlibat dalam pembelajaran "tanpa model" bersekutu atau perancangan "berasaskan model" yang lebih disengajakan. Pemilihan model bahasa peringkat token bersekutu yang mudah juga serupa dengan "Sistem 1" dan dengan itu mungkin mendapat manfaat daripada peningkatan proses perancangan "Sistem 2" yang lebih bijak yang mengekalkan dan meneroka pelbagai alternatif kepada pemilihan semasa, bukan hanya Pilih satu . Selain itu, ia menilai keadaan semasanya dan secara aktif melihat ke hadapan atau belakang untuk membuat lebih banyak keputusan global.
Untuk mereka bentuk proses perancangan sedemikian, penyelidik dari Princeton University dan Google DeepMind memilih untuk mengkaji semula asal-usul kecerdasan buatan (dan sains kognitif) dan menggunakan hasil kerja Newell, Shaw dan Simon Inspirasi untuk proses perancangan yang diterokai pada tahun 1950-an. Newell dan rakan sekerja menerangkan penyelesaian masalah sebagai pencarian ruang masalah gabungan yang diwakili sebagai pokok. Oleh itu, mereka mencadangkan rangka kerja Pokok Pemikiran (ToT) yang disesuaikan dengan model bahasa untuk penyelesaian masalah umum.

Pautan kertas: https://arxiv.org/pdf/2305.10601 .pdf
Alamat projek: https://github.com/ysymyth/tree-of-thought-llm
Seperti yang ditunjukkan dalam Rajah 1, kaedah sedia ada menyelesaikan masalah dengan mensampel urutan bahasa berterusan, manakala ToT secara aktif mengekalkan pokok pemikiran, di mana setiap pemikiran adalah urutan bahasa yang koheren, sebagai langkah Pertengahan dalam penyelesaian masalah (Jadual 1).
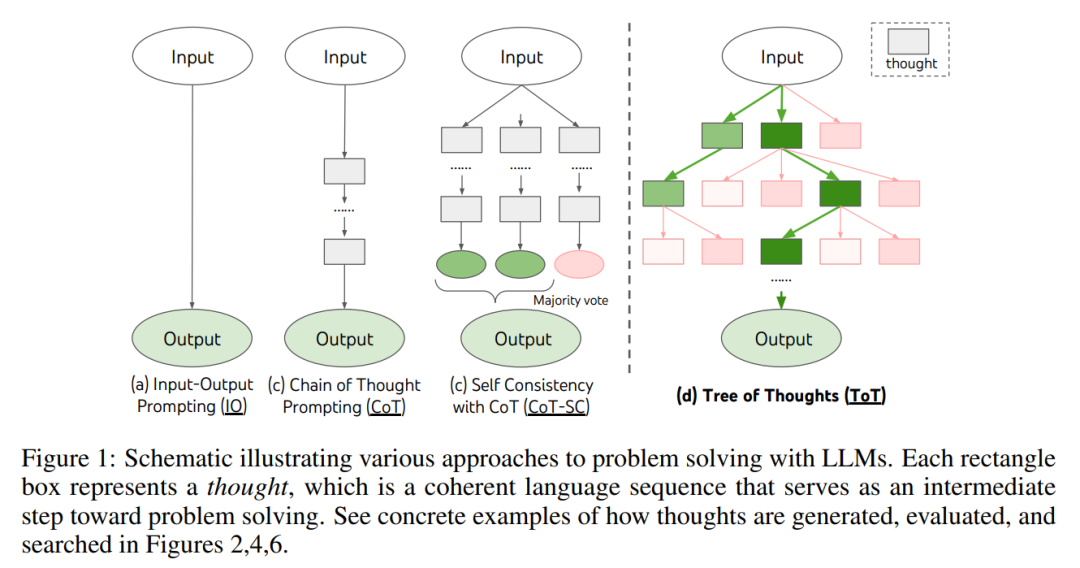

Yang ini Unit semantik lanjutan membolehkan LM menilai sendiri sumbangan pemikiran perantaraan yang berbeza kepada kemajuan penyelesaian masalah melalui proses penaakulan yang bernas (Rajah 2, 4, 6). Melaksanakan heuristik carian melalui penilaian dan pertimbangan kendiri LM adalah pendekatan baru, kerana heuristik carian sebelumnya sama ada diprogramkan atau dipelajari.


Akhir sekali, pengkaji mengasaskan ini The language's keupayaan untuk menjana dan menilai pemikiran yang pelbagai digabungkan dengan algoritma carian, seperti carian pertama luas (BFS) atau carian pertama mendalam (DFS), yang membolehkan penerokaan sistematik pokok pemikiran, dengan keupayaan melihat ke hadapan dan menjejak ke belakang.
Dalam fasa eksperimen, penyelidik menyediakan tiga tugasan iaitu permainan 24 mata, penulisan kreatif dan teka silang kata (Jadual 1 Masalah ini agak mencabar bagi kaedah inferens LM sedia ada, walaupun GPT-). 4 tidak terkecuali. Tugasan ini memerlukan deduktif, matematik, pengetahuan am, kemahiran penaakulan leksikal dan cara untuk menggabungkan perancangan atau carian yang sistematik. Keputusan eksperimen menunjukkan bahawa ToT mencapai hasil yang lebih baik pada ketiga-tiga tugasan ini kerana ia adalah serba boleh dan cukup fleksibel untuk menyokong tahap pemikiran yang berbeza, cara yang berbeza untuk menjana dan menilai pemikiran, dan menyesuaikan diri dengan jenis algoritma Carian yang berbeza. Melalui analisis ablasi eksperimen yang sistematik, penulis juga meneroka cara pilihan ini mempengaruhi prestasi model dan membincangkan arah masa depan untuk latihan dan menggunakan LM.
Thinking Trees: Memanfaatkan Model Bahasa untuk Penyelesaian Masalah Berfikiran
Proses penyelesaian masalah sebenar melibatkan penggunaan secara berulang maklumat yang tersedia untuk memulakan penerokaan, yang seterusnya mendedahkan lebih banyak maklumat, sehingga penemuan akhir dibuat Cara untuk melaksanakan penyelesaian. —— Newell et al.
Penyelidikan tentang penyelesaian masalah manusia menunjukkan bahawa manusia menyelesaikan masalah dengan mencari ruang masalah gabungan. Ini boleh dilihat sebagai pokok, di mana nod mewakili penyelesaian separa dan cawangan sepadan dengan pengendali yang mengubah suainya. Cabang mana yang dipilih ditentukan oleh heuristik yang membantu menavigasi ruang masalah dan membimbing penyelesai masalah ke arah penyelesaian. Perspektif ini menyerlahkan dua kelemahan utama pendekatan sedia ada yang menggunakan model bahasa untuk menyelesaikan masalah umum: 1) Secara tempatan, mereka tidak meneroka kesinambungan yang berbeza dalam proses pemikiran - cabang pokok. 2) Di peringkat global, mereka tidak menyertakan sebarang jenis perancangan, melihat ke hadapan atau menjejak ke belakang untuk membantu menilai pilihan yang berbeza ini—jenis carian berpandukan heuristik yang nampaknya mencirikan penyelesaian masalah manusia.
Untuk menyelesaikan masalah ini, penulis memperkenalkan pokok pemikiran (ToT), sebuah paradigma yang membolehkan model bahasa meneroka pelbagai kaedah penaakulan pada laluan berfikir (Rajah 1(c) ) )). ToT membingkai sebarang masalah sebagai carian pokok, di mana setiap nod ialah keadaan s = [x, z_1・・・i ], mewakili penyelesaian separa dengan input dan urutan pemikiran setakat ini. Contoh khusus ToT termasuk menjawab empat soalan berikut:
- 1. Bagaimana untuk memecahkan proses perantaraan kepada langkah-langkah berfikir; >2 . Bagaimana untuk menjana pemikiran yang berpotensi dari setiap keadaan; guna.
- 1. Penguraian pemikiran. Walaupun sampel CoT berfikir secara koheren tanpa penguraian eksplisit, ToT mengeksploitasi sifat masalah untuk mereka bentuk dan menguraikan langkah pemikiran pertengahan. Seperti yang ditunjukkan dalam Jadual 1, bergantung kepada masalah, pemikiran boleh berupa beberapa perkataan (teka-teki silang kata), persamaan (permainan 24 titik), atau rancangan penulisan (penulisan kreatif). Secara umumnya, pemikiran harus cukup "kecil" supaya LM boleh menjana kepelbagaian sampel yang diharapkan (seperti menghasilkan buku yang terlalu "besar" untuk menjadi koheren), tetapi pemikiran itu harus cukup "besar". LM boleh menilai prospeknya untuk menyelesaikan masalah (contohnya, menjana token biasanya terlalu kecil untuk dinilai).
- 2. Penjana pemikiran G (p_θ, s, k). Memandangkan keadaan pokok s = [x, z_1・・・i], kajian ini menggunakan dua strategi untuk menjana k calon untuk langkah pemikiran seterusnya.
- 3. Negeri penilai V (p_θ, S). Memandangkan sempadan negeri yang berbeza, penilai negeri menilai kemajuan mereka ke arah menyelesaikan masalah untuk menentukan negeri mana yang harus terus diterokai, dan dalam susunan yang mana. Walaupun heuristik ialah cara standard untuk menyelesaikan masalah carian, ia selalunya sama ada terprogram (cth. DeepBlue) atau dipelajari (cth. AlphaGo). Artikel ini mencadangkan alternatif ketiga, dengan menggunakan bahasa untuk membuat alasan secara sengaja tentang negeri. Di mana berkenaan, heuristik bernas sedemikian boleh menjadi lebih fleksibel daripada peraturan pengaturcaraan dan lebih cekap daripada model pembelajaran.
Sama seperti Penjana Pemikiran, pertimbangkan dua strategi untuk menilai keadaan secara individu atau bersama-sama:
(1) Menilai setiap negeri secara bebas
(2) Pengundian merentas negeri
Kedua-dua strategi ini boleh menggesa LM beberapa kali untuk menyepadukan nilai atau mengundi Akibatnya , masa, sumber dan kos ditukar untuk heuristik yang lebih dipercayai dan teguh.
-
4. Akhir sekali, dalam rangka kerja ToT adalah mungkin untuk memasang dan memainkan algoritma carian yang berbeza berdasarkan struktur pokok. Artikel ini meneroka dua algoritma carian yang agak mudah dan meninggalkan algoritma yang lebih maju untuk penyelidikan masa hadapan:
- (1) Breadth-First Search (BFS) (Algoritma 1 )
- (2) Depth First Search (DFS) (Algoritma 2)
Secara konseptual, ToT berfungsi sebagai model bahasa Kaedah untuk menyelesaikan masalah umum mempunyai beberapa kelebihan:
- (1) Kesejagatan. IO, CoT, CoT-sc dan penghalusan diri boleh dilihat sebagai kes khas ToT (iaitu pokok dengan kedalaman dan keluasan terhad; Rajah 1); LM asas serta proses penguraian pemikiran, penjanaan, penilaian dan carian semuanya boleh berbeza-beza secara bebas; Boleh menyesuaikan diri dengan atribut masalah yang berbeza, keupayaan LM dan kekangan sumber; Tiada latihan tambahan diperlukan, hanya LM pra-latihan sudah memadai.
- Hasil eksperimen
- Kajian itu mencadangkan tiga tugasan, walaupun menggunakan model bahasa paling maju GPT-4, melalui dorongan IO standard atau rantaian pemikiran (CoT) mendorong untuk pensampelan, tugas-tugas ini kekal mencabar.
- Permainan Matematik 24 Mata
Seperti yang ditunjukkan dalam Jadual 2, menggunakan kaedah dorongan IO, CoT dan CoT-SC berprestasi lemah dalam tugasan, hanya mencapai kadar kejayaan 7.3%, 4.0% dan 9.0%. Sebagai perbandingan, ToT dengan b(keluasan) = 1 telah mencapai kadar kejayaan sebanyak 45%, dan dengan b = 5 ia mencapai 74%. Mereka juga mempertimbangkan penetapan oracle IO/CoT untuk mengira kadar kejayaan dengan menggunakan nilai terbaik antara k sampel (1 ≤ k ≤ 100).
Untuk membandingkan IO/CoT (k hasil terbaik) dengan ToT, penyelidik mempertimbangkan untuk mengira bilangan nod pokok yang dilawati dalam setiap tugas dalam ToT, di mana b = 1・・・5, dan petakan 5 kadar kejayaan dalam Rajah 3 (a), menganggap IO/CoT (k hasil terbaik) sebagai melawati nod k dalam mesin perjudian. Tidak mengejutkan, CoT lebih berskala daripada IO, dan 100 sampel CoT terbaik mencapai kadar kejayaan 49%, yang masih jauh lebih rendah daripada meneroka lebih banyak nod dalam ToT (b > 1).
Rajah 3 (b) di bawah memecahkan sampel CoT dan ToT apabila tugas gagal . Terutama, kira-kira 60% sampel CoT telah gagal selepas langkah pertama penjanaan, bersamaan dengan menjana tiga perkataan pertama (cth. "4 + 9"). Ini menjadikan masalah penyahkodan terus dari kiri ke kanan lebih jelas.

Penulisan Kreatif
Rajah 5 (a) di bawah menunjukkan skor purata GPT-4 antara 100 tugasan, di mana ToT (7.56) menjana lebih banyak hasil daripada IO (6.19) dan CoT (6.93) perenggan koheren . Walaupun langkah automatik sedemikian boleh menjadi bising, Rajah 5(b) mengesahkan bahawa manusia lebih suka ToT daripada CoT dalam 41 daripada 100 pasangan laluan, manakala hanya 21 pasangan lebih suka CoT daripada ToT (38 pasangan lain didapati "sama koheren").Para penyelidik juga mencipta tugasan penulisan kreatif, memasukkan 4 ayat rawak dan mengeluarkan artikel koheren yang mengandungi empat perenggan, setiap satu berakhir dengan 4 ayat input. Tugas-tugas sebegini bersifat terbuka dan penerokaan, pemikiran kreatif yang mencabar dan perancangan peringkat tinggi.
Akhirnya, algoritma pengoptimuman berulang mencapai hasil yang lebih baik pada tugas bahasa semula jadi ini, dengan skor konsistensi IO meningkat daripada 6.19 kepada 7.67 dan skor konsistensi ToT meningkat daripada 7.56 kepada 7.91. Para penyelidik percaya bahawa ini boleh dilihat sebagai kaedah penjanaan pemikiran ketiga dalam kerangka ToT Pemikiran baru boleh dijana daripada pemurnian pemikiran lama dan bukannya generasi berurutan.
Mini silang kata
Dalam "24-Point Math Game" dan penulisan kreatif, ToT adalah agak mudah - ia memerlukan sehingga 3 langkah berfikir untuk mencapai output akhir. Penyelidik akan meneroka teka silang kata mini 5×5 sebagai lapisan soalan carian yang lebih sukar tentang bahasa semula jadi. Sekali lagi, matlamat kali ini bukan sekadar menyelesaikan tugas, kerana teka silang kata umum boleh diselesaikan dengan mudah oleh saluran paip NLP khusus yang memanfaatkan perolehan semula berskala besar dan bukannya LM. Sebaliknya, penyelidik bertujuan untuk meneroka had model bahasa sebagai penyelesai masalah umum, meneroka pemikirannya sendiri, dan menggunakan penaakulan yang ketat sebagai heuristik untuk membimbing penerokaannya.
Seperti yang ditunjukkan dalam Jadual 3 di bawah, kaedah dorongan IO dan CoT berprestasi lemah, dengan kadar kejayaan peringkat perkataan di bawah 16%, manakala ToT meningkatkan semua metrik dengan ketara, mencapai 60% tahap Word kadar kejayaan, 4 permainan diselesaikan daripada 20. Penambahbaikan ini tidak menghairankan memandangkan IO dan CoT kekurangan mekanisme untuk mencuba petunjuk yang berbeza, mengubah keputusan, atau mundur.




Atas ialah kandungan terperinci Fikir, fikir, fikir tanpa henti, Thinking Tree ToT 'Latihan Tentera' LLM. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI