
Rumah >pangkalan data >Redis >Cara menggunakan Gaussian Redis untuk melaksanakan indeks sekunder
Cara menggunakan Gaussian Redis untuk melaksanakan indeks sekunder

- PHPzke hadapan
- 2023-06-02 18:53:231378semak imbas
1. Latar Belakang
Apabila berkaitan dengan pengindeksan, tanggapan pertama ialah istilah pangkalan data, tetapi Gaussian Redis juga boleh melaksanakan pengindeksan sekunder! ! ! Indeks sekunder dalam Gaussian Redis biasanya dilaksanakan menggunakan zset. Gaussian Redis mempunyai kestabilan dan kelebihan kos yang lebih tinggi daripada Redis sumber terbuka Menggunakan Gaussian Redis zset untuk melaksanakan indeks sekunder perniagaan boleh mencapai situasi menang-menang dalam prestasi dan kos.
Intipati indeks ialah menggunakan struktur tersusun untuk mempercepatkan pertanyaan, jadi melalui struktur Zset Gaussian Redis boleh melaksanakan indeks jenis berangka dan jenis aksara dengan mudah.
• Indeks jenis angka (zset diisih mengikut pecahan):
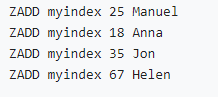

• berdasarkan Pada masa yang sama, zset diisih mengikut leksikografi):


Mari kita potong kepada dua jenis senario perniagaan klasik dan lihat cara menggunakan Gaussian Redis untuk membina sistem pengindeksan sekunder yang stabil dan boleh dipercayai.
2. Senario 1: Penyiapan kamus
Apabila menaip pertanyaan dalam penyemak imbas, penyemak imbas biasanya mengesyorkan carian dengan awalan yang sama mengikut kebarangkalian dalam senario ini, Gaussian Redis 2 boleh digunakan Fungsi indeks tahap dilaksanakan.

2.1 Penyelesaian Asas
Kaedah paling mudah ialah menambah setiap pertanyaan pengguna pada indeks. Jika anda perlu memberikan gesaan penyelesaian kepada pengguna, anda boleh menggunakan ZRANGEBYLEX untuk melaksanakan pertanyaan julat. Untuk mengurangkan bilangan keputusan, menggunakan pilihan LIMIT ialah kaedah yang disokong oleh Gaussian Redis.
• Tambahkan pisang carian pengguna pada indeks:
ZADD myindex 0 banana:1
• " .
ZRANGEBYLEX myindex "[bit" "[bit\xff"
Iaitu, gunakan ZRANGEBYLEX untuk melaksanakan pertanyaan julat Julat pertanyaan ialah rentetan yang dimasukkan oleh pengguna sekarang dan rentetan yang sama ditambah bait tertinggal 255 (xff). Kita boleh menggunakan kaedah ini untuk mendapatkan semua rentetan yang diawali oleh rentetan yang dimasukkan oleh pengguna.
2.2 Penyiapan kamus yang berkaitan dengan kekerapan
Dalam aplikasi praktikal, orang biasanya ingin mengisih entri penyiapan secara automatik untuk menyesuaikan dengan kekerapan kejadian dan mengalih keluar entri yang tidak lagi popular semasa menyesuaikan diri input masa hadapan. Kita masih boleh menggunakan struktur ZSet Gaussian Redis untuk mencapai matlamat ini, tetapi dalam struktur indeks, bukan sahaja istilah carian perlu disimpan, tetapi juga frekuensi yang dikaitkan dengannya perlu disimpan.
• Tambahkan pisang carian pengguna pada indeks
• kekerapan
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• Dengan mengandaikan pisang wujud, kekerapan perlu ditingkatkan
Jika kekerapan dikembalikan dalam ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1 ialah 1
1) Padamkan Entri lama:
ZADD myindex 0 banana:1
2) Kekerapan tambah satu Sertai semula:
ZREM myindex 0 banana:1
Sila ambil perhatian bahawa memandangkan mungkin terdapat kemas kini serentak, ketiga-tiga arahan di atas hendaklah dihantar melalui Lua skrip, dan yang lama harus diperoleh secara automatik dengan skrip Lua Tambah semula entri selepas mengira dan meningkatkan markah.
Jika pengguna memasukkan "pisang" dalam borang carian, kami berharap dapat menyediakan kata kunci carian yang berkaitan. Isih mengikut kekerapan selepas mendapat hasil melalui ZRANGEBYLEX.
ZADD myindex 0 banana:2
• Gunakan algoritma penstriman untuk membersihkan input yang tidak biasa. Pilih entri yang dikembalikan secara rawak dan tolak satu daripada skornya, kemudian tambahkannya semula dengan skor yang dikemas kini. Walau bagaimanapun, jika skor baharu ialah 0, kami perlu mengalih keluar masukan daripada senarai.
• Jika kekerapan penyertaan yang dipilih secara rawak ialah 1, seperti banaooo:1
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
• 🎜>
ZREM myindex 0 banaooo:1Dalam jangka panjang, indeks akan menyertakan carian popular dan menyesuaikan secara automatik jika carian popular berubah dari semasa ke semasa. 3. Senario 2: Indeks berbilang dimensi Gaussian Redis bukan sahaja menyokong pertanyaan dalam satu dimensi, tetapi juga boleh mendapatkan semula dalam data berbilang dimensi. Contohnya, cari orang yang memenuhi kriteria berikut: umur antara 50 dan 55 tahun dan gaji antara 70,000 dan 85,000. Menukar pengekodan data dua dimensi kepada data satu dimensi, dan kemudian menggunakan storan Redis zset teragih Gaussian, ialah kaedah penting untuk melaksanakan indeks sekunder berbilang dimensi. Mewakili indeks dua dimensi dari perspektif visual. Dalam ruang ini, terdapat beberapa titik sampel data yang diwakili sebagai koordinat (x, y), dan nilai maksimum kedua-dua pembolehubah x dan y dalam koordinat ini ialah 400. Kotak biru dalam imej mewakili pertanyaan kami. Kami ingin mencari semua titik dengan koordinat x antara 50 dan 100 dan y antara 100 dan 300.
3.1 Pengekodan data
2)交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。

同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3)使用二进制
如果将数据表示为二进制,就可以获得更细的粒度,而在数字替换时,每次都将搜索范围扩大两倍。如果我们使用二进制表示法数字,每个变量最多需要9位(表示最多400个值),那么我们将得到:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGEBYLEX query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGEBYLEX myindex [#{s} [#{e}"
}
}
end
spacequery(50,100,100,300,6)Atas ialah kandungan terperinci Cara menggunakan Gaussian Redis untuk melaksanakan indeks sekunder. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!