
Rumah >pangkalan data >tutorial mysql >Kaedah pengoptimuman dan pengindeksan MySQL
Kaedah pengoptimuman dan pengindeksan MySQL

- PHPzke hadapan
- 2023-06-02 13:58:211154semak imbas
Pengenalan ringkas kepada indeks
Intipati indeks:
Intipati indeks MySQL atau indeks pangkalan data hubungan lain hanyalah satu ayat , bertukar ruang dengan masa.
Peranan indeks:
Pangkalan data hubungan indeks digunakan untuk mempercepatkan pengambilan data baris dalam jadual (storan cakera ) Struktur data
Klasifikasi indeks
Klasifikasi struktur data di atas:
Indeks HASH
Padanan yang sama adalah cekap
Tidak menyokong carian julat
-
Indeks pokok
Pokok binari, kaedah carian binari rekursif, kiri kecil dan kanan besar
Pokok binari seimbang, binari pokok kepada pokok binari seimbang, Sebab utama adalah kidal dan tangan kanan
Kelemahan 1, terlalu banyak kali IO
Kelemahan 2 , penggunaan IO tidak tinggi, ketepuan IO
Pokok carian seimbang berbilang hala (B-Tree)
Ciri, mengurangkan ketinggian pokok dengan banyak
Pokok B+
ciri, menggunakan kaedah perbandingan tertutup kiri
Nod sokongan nod akar tidak mempunyai kawasan data, dan hanya nod daun mengandungi kawasan data (secara terang-terangan, walaupun nod akar dan nod anak telah ditemui , ia tidak akan berhenti kerana tiada kawasan data, dan akan terus mencari nod daun.)
Apabila kita mencari data 13, kita boleh mencari kedua-dua nod akar dan nod anak, tetapi kami akan sentiasa mencari nod daun.
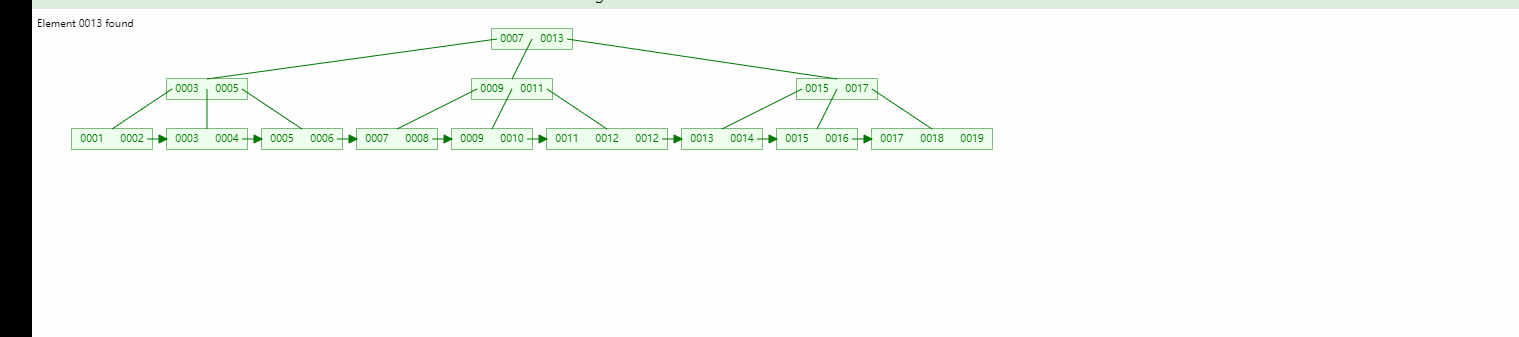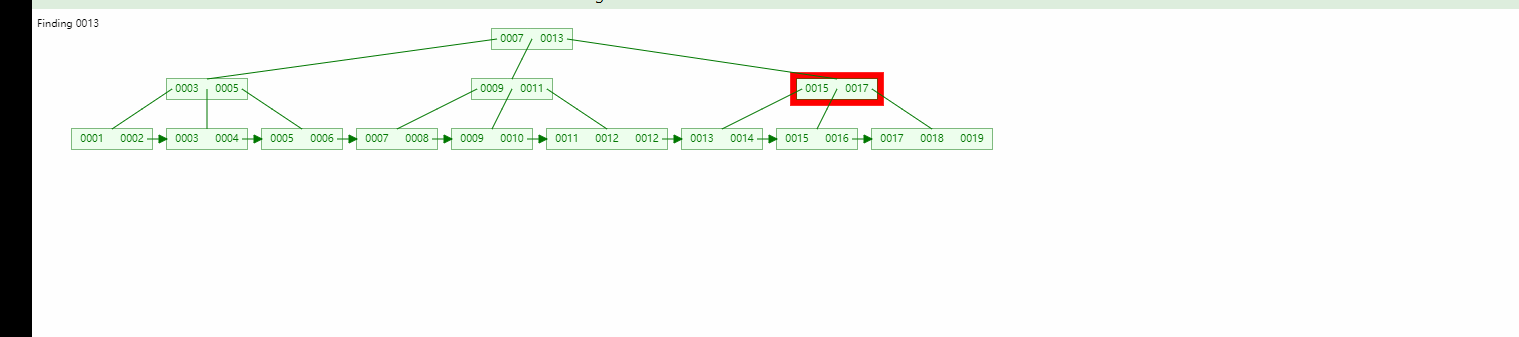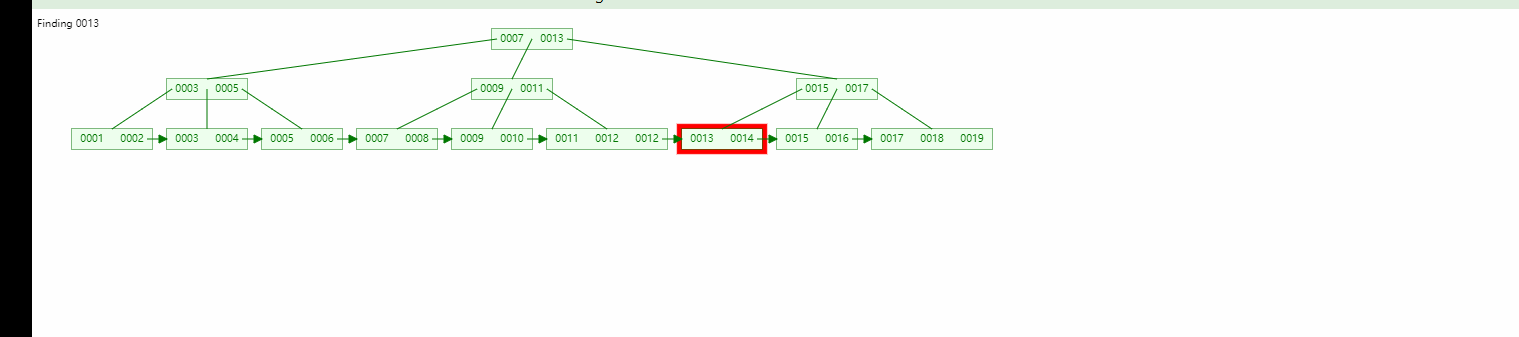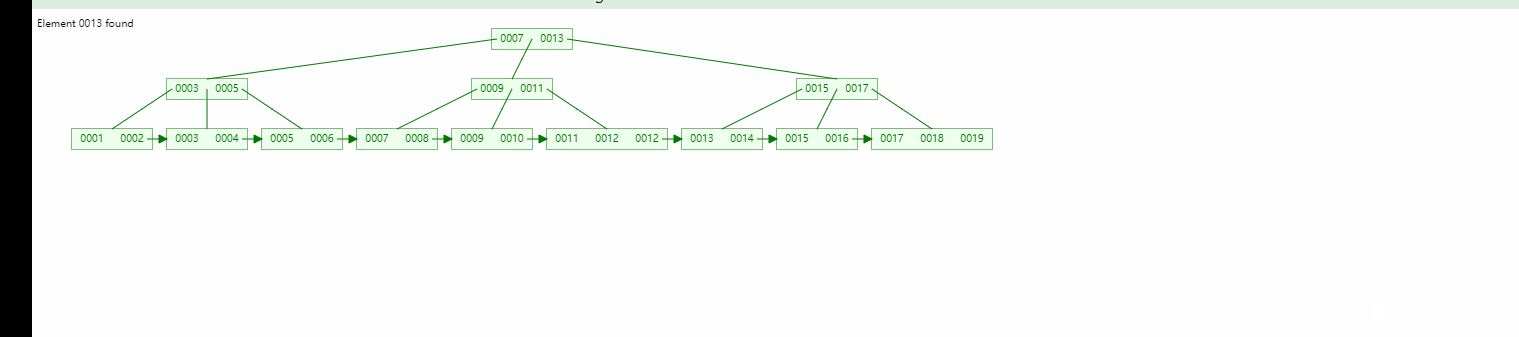
Pokok binari seimbang Pokok binari, B-pokok perbandingan:
Seperti yang ditunjukkan dalam rajah jika ia adalah kunci utama yang meningkat secara automatik Seterusnya:
Pokok binari jelas tidak sesuai untuk indeks pangkalan data hubungan (tidak berbeza dengan imbasan jadual penuh).
Bagi pokok binari seimbang, walaupun keadaan ini diselesaikan, ia juga akan menyebabkan pokok itu menjadi kurus dan tinggi, yang juga akan menyebabkan terlalu banyak pertanyaan IO dan penggunaan IO yang rendah yang disebutkan di atas.
B-tree jelas telah menyelesaikan kedua-dua masalah ini, jadi yang berikut menerangkan sebab MySQL masih menggunakan B+-tree dalam kes ini dan membuat peningkatan tersebut.

Perbandingan B-tree dan B+-tree:

Pengoptimuman B+ pokok pada B-tree:
Kecekapan IO lebih tinggi (setiap nod B-tree akan mengekalkan kawasan data, tetapi pokok B+ tidak akan. Katakan kita perlu untuk merentasi tiga lapisan untuk menanyakan sekeping data, maka Jelas sekali penggunaan IO dalam pertanyaan pepohon B+ adalah lebih kecil)
Kecekapan carian julat lebih tinggi (seperti yang ditunjukkan dalam gambar, pepohon B+ telah membentuk borang senarai terpaut semula jadi , dan hanya perlu dicari mengikut struktur rantai terakhir)

Pengimbasan data berasaskan indeks adalah lebih cekap.
Klasifikasi jenis indeks
Jenis indeks boleh dibahagikan kepada dua kategori:
Indeks kunci utama
Indeks tambahan (indeks sekunder)
Indeks unik
Indeks kompaun
Indeks biasa
Indeks tertutup
Walaupun prestasi indeks kunci utama secara relatifnya adalah yang terbaik , Biasanya dalam pengoptimuman SQL, kami akan membuat penambahbaikan dan tambahan pada indeks tambahan.
Pokok B+ dilaksanakan di peringkat enjin storan
Kami mencipta dua jadual masing-masing
test_innodb(menggunakan InnoDB sebagai enjin storan) test_myisam (menggunakan MyISAM sebagai enjin storan) Enjin storan) Rajah berikut menunjukkan fail yang berkaitan bagi dua pelaksanaan cakera jadual Kedua-dua enjin storan ini berbeza sama sekali dalam pelaksanaan cakera pokok B.
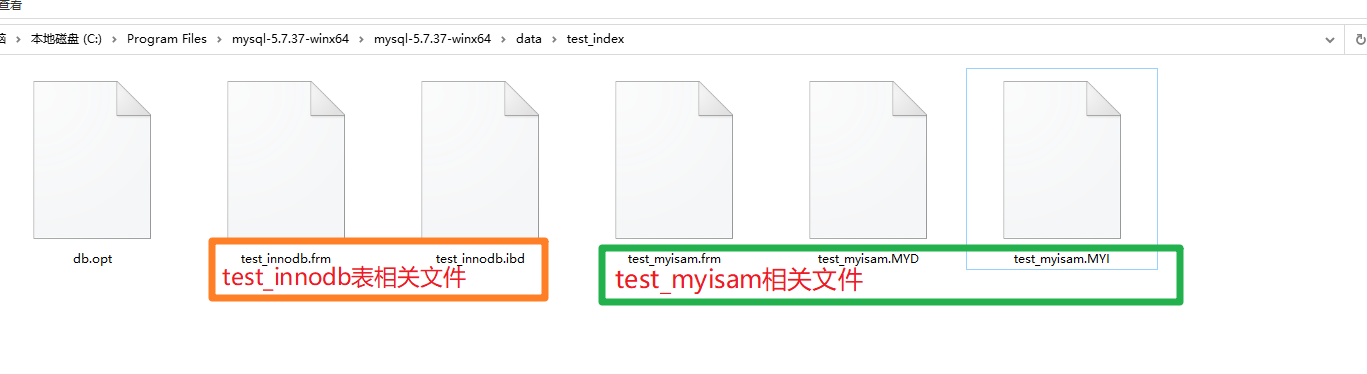
Pokok B+ dilaksanakan dalam MyISAM:
*.frm fail ialah fail rangka Jadual, seperti jenis medan nama medan id dalam jadual ini disimpan di sini
*.MYD (D=data) menyimpan data
*.MYI (I=index) menyimpan indeks

Sebagai contoh, jika anda melaksanakan perkara berikut sql statement sekarang, kemudian Dalam MyISAM, dia mula-mula mencari 103 dalam test_myisam.MYI, kemudian mendapat alamat 0x194281, dan kemudian mencari data dalam test_myisam.MYD dan mengembalikannya.
SELECT id,name from test_myisam where id =103
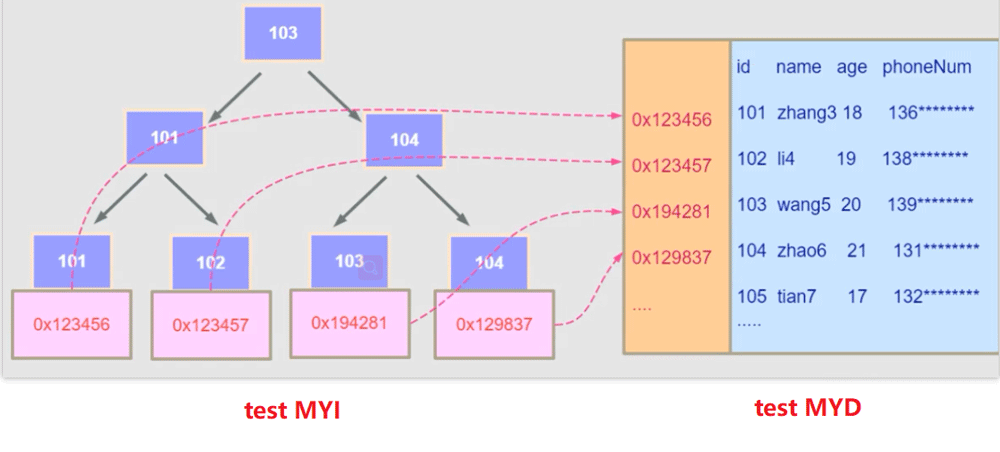
如果
test_myisam表中,id为主键索引,name也是一个索引,那么在test_myisam.MYI中则会有两个平级的B+树,这也导致MyISAM引擎中主键索引和二级索引是没有主次之分的,是平级关系。因为这种机制在MyISAM引擎中,有可能使用多个索引,在InnoDB中则不会出现这种情况。
B+树在InnoDB落地:

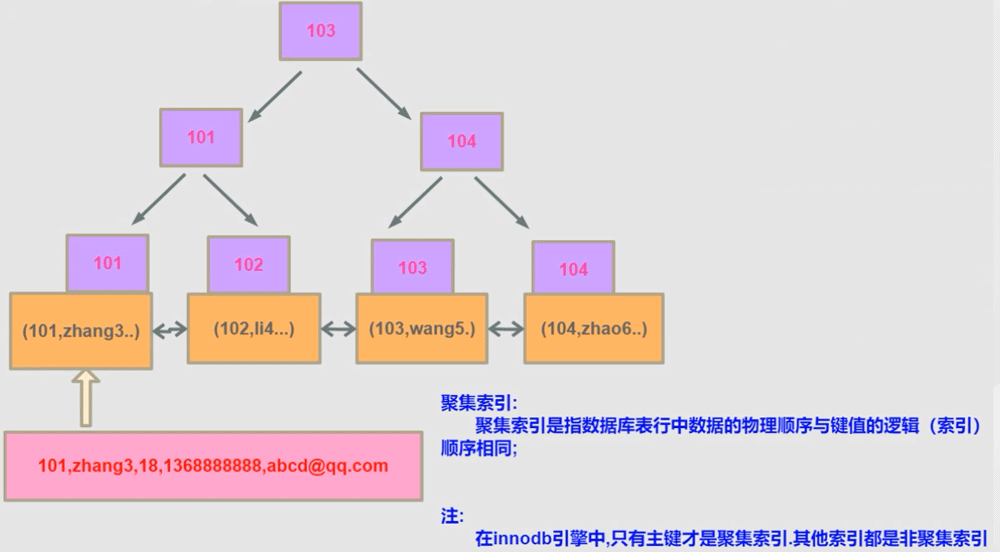
InnoDB不像MyISAM来独立一个MYD 文件来存储数据,它的数据直接存储在叶子结点关键字对应的数据区在这保存这一个id列所有行的详细记录。
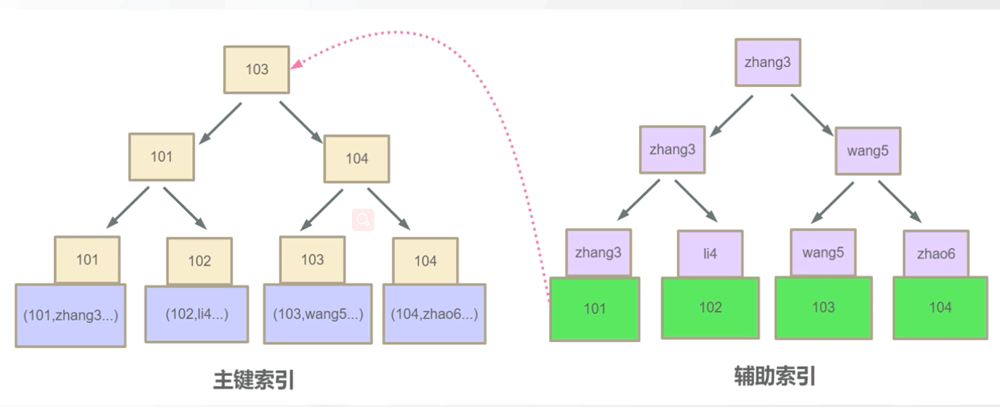
InnoDB 主键索引和辅助索引关系
我们现在执行如下SQL语句,他会先去找辅助索引,然后找到辅助索引下101的主键,再去回表(二次扫描)根据主键索引查询103这条数据将其返回。
SELECT id,name from test_myisam where name ='zhangsan'
这里就有一个问题了,为什么不像MyISAM在辅助索引下直接记录磁盘地址,而是要多此一举再去回表扫描主键索引,这个问题在下面相关面试题中回答,记一下这个问题是这里来的。
相关面试题
为什么MySQL选择B+树作为索引结构
这个就不说了,上文应该讲清楚了。
B+树在MyISAM和InnoDB落地区别。
这个可以总结一下,MyISAM落地数据储存会有三个类型文件 ,.frm文件是表骨架文件,.MYD(D=data)则储存数据 ,.MYI (I=index)则储存索引,MyISAM引擎中主键索引和二级索引平级关系,在MyISAM引擎中,有可能使用多个索引,InnoDB则相反,主键索引和二级索有严格的主次之分在InnoDB一条语句只能用一个索引要么不用。
如何判断一条sql语句是否使用了索引。
可以通过执行计划来判断 可以在sql语句前explain/ desc
set global optimizer_trace='enabled=on' 打开执行计划开关他将会把每一条查询sql执行计划记录在information_schema 库中OPTIMIZER_TRACE表中
为什么主键索引最好选择自增列?
自增列,数据插入时整个索引树是只有右边在增加的,相对来说索引树的变动更小。
为什么经常变动的列不建议使用索引?
和上一个问题原因一样,当一个索引经常发生变化,那么就意味这,这个缩印树也要经常发生变化。4
为什么说重复度高的列,不建议建立索引?
这个原因是因为离散性,比如说,一张一百万数据的表,其中一个字段代表性别,0代表男1代表女,把这字段加了索引,那么在索引树上,将会有大量的重复数据。而我们常见的索引建立一般都是驱动型的。其目的是,尽可能的删减数据的查询范围,这个显然是不匹配的。
什么是联合索引
联合索引是一个包含了多个功效的索引,他只是一个索引而不是多个,
其次,单列索引是一种特殊的联合索引
联合索引的创立要遵循最左前置原则(最常用列>离散度>占用空间小)
什么是覆盖索引
通过索引项信息可直接返回所需要查询的索引列,该索引被称之为覆盖索引,说白了就是不需要做回表操作,可以从二级索引中直接取到所需数据。
什么是ICP机制
索引下推,简单点来说就是,在sql执行过程中,面对where多条件过滤时,通过一个索引,完成数据搜索和过滤条件其,特点能减少io操作。
在InnoDB表中不可能没有主键对还是不对原因是什么?
首先这句话是对的,但是情况有三种:
bermakna apabila anda secara manual menentukan medan ini sebagai kunci utama, medan ini akan digunakan sebagai indeks berkelompok.
Terdapat dua situasi apabila kunci utama tidak dinyatakan secara eksplisit:
Dia akan mencari UK pertama (kunci unik) sebagai indeks kunci utama Atur pengindeksan.
Jika kunci utama mahupun UK tidak dinyatakan, rowId (setiap rekod dalam jadual InnoDB akan mempunyai rowId tersembunyi (6byte)) akan digunakan sebagai indeks berkelompok.
Apakah itu operasi pemulangan jadual
Kandungan berdasarkan pertanyaan indeks tambahan dalam InnoDB , tidak boleh diperolehi terus daripada indeks tambahan, dan operasi yang memerlukan imbasan sekunder berdasarkan indeks kunci primer dipanggil operasi pulangan jadual.
Mengapakah kawasan data nod daun indeks tambahan dalam InnoDB merekodkan nilai indeks kunci utama dan bukannya merekodkan alamat cakera seperti dalam MyISAM.
Alasannya sebenarnya sangat mudah, kerana struktur data indeks kunci utama sering berubah Jika alamat cakera direkodkan dalam kawasan data indeks tambahan, maka andaikan kita mempunyai 10 indeks Bantu, apabila struktur indeks kunci utama kami berubah, kami perlu memaklumkan indeks tambahan satu demi satu, dan struktur indeks kunci utama sering berubah, dan penambahan serta pemadaman mungkin menjejaskan struktur data
nya.
Atas ialah kandungan terperinci Kaedah pengoptimuman dan pengindeksan MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!