
Rumah >pangkalan data >Redis >Cara melaksanakan cache tahap kedua Caffeine+Redis berdasarkan Cache Spring
Cara melaksanakan cache tahap kedua Caffeine+Redis berdasarkan Cache Spring

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-06-01 10:13:461674semak imbas
Butirannya adalah seperti berikut:
1. Mari kita bincangkan tentang apa itu cache berkod keras?
Sebelum mempelajari Spring Cache, saya sering menggunakan caching dengan cara berkod keras.
Mari kita ambil contoh praktikal untuk meningkatkan kecekapan pertanyaan maklumat pengguna, kami menggunakan caching untuk maklumat pengguna. gaya yang serupa. Kod, gaya ini adalah selaras dengan pemikiran pengaturcaraan berorientasikan proses dan sangat mudah difahami. Tetapi ia juga mempunyai beberapa kelemahan:
Kod ini tidak cukup elegan. Logik perniagaan mempunyai empat tindakan biasa:
simpan, baca, ubah suai, padam. Setiap operasi perlu mentakrifkan Kunci cache dan memanggil API arahan cache, yang menghasilkan banyak kod berulang Gandingan kod antara operasi cache dan logik perniagaan adalah tinggi, dan ia sangat mengganggu; kepada logik perniagaan. Kecerobohan terutamanya mencerminkan dua perkara berikut:
- Semasa peringkat pembangunan dan penyahpepijatan bersama, cache perlu dialih keluar dan kod operasi cache hanya boleh diulas atau buat sementara waktu dipadam, yang juga terdedah kepada ralat
;
- Dalam sesetengah senario, komponen cache perlu diganti Setiap komponen cache mempunyai API sendiri dan kos penggantian agak tinggi
.
Ia akan menjadi lebih elegan jika ia kelihatan seperti ini.
@Autowire
private UserMapper userMapper;
@Autowire
private RedisCache redisCache;
//查询用户
public User getUserById(Long userId) {
//定义缓存key
String cacheKey = "userId_" + userId;
//先查询redis缓存
User user = redisCache.get(cacheKey);
//如果缓存中有就直接返回,不再查询数据库
if (user != null) {
return user;
}
//没有再查询数据库
user = userMapper.getUserById(userId);
//数据存入缓存,这样下次查询就能到缓存中获取
if (user != null) {
stringCommand.set(cacheKey, user);
}
return user;
}Lihat kelas pelaksanaan sekali lagi
@Mapper
public interface UserMapper {
/**
* 根据用户id获取用户信息
*
* 如果缓存中有直接返回缓存数据,如果没有那么就去数据库查询,查询完再插入缓存中,这里缓存的key前缀为cache_user_id_,+传入的用户ID
*/
@Cacheable(key = "'cache_user_id_' + #userId")
User getUserById(Long userId);
}Lihat sama ada ia dipisahkan sepenuhnya daripada cache Jika anda perlu mengalih keluar cache semasa peringkat pembangunan dan penyahpepijatan bersama, cuma komen keluar anotasi , betul tak?
Dan tidak perlu menulis keseluruhan set pelaksanaan ini secara manual Cache Spring telah mentakrifkan pemahaman dan antara muka yang berkaitan untuk saya, dan kami boleh melaksanakan fungsi di atas dengan mudah.
2. Pengenalan kepada Spring Cache
Spring Cache ialah komponen caching berasaskan anotasi yang disediakan dalam pakej Spring-context. Dengan melaksanakan antara muka ini, anda boleh menggunakan Add anotasi kepada kaedah
untuk melaksanakan caching. Ini boleh mengelakkan masalah gandingan kod caching dengan pemprosesan perniagaan.
Hanya terdapat dua antara muka teras Spring Cache:
danCacheCacheManager1 antara muka Cache
Antara muka ini mentakrifkan operasi khusus yang menyediakan caching, seperti. caching Letakkan, baca, bersihkan:
@Autowire
private UserMapper userMapper;
//查询用户
public User getUserById(Long userId) {
return userMapper.getUserById(userId);
}2. Antara muka CacheManager
terutamanya menyediakan penciptaan kacang pelaksanaan Cache Dalam setiap aplikasi, Cache boleh diasingkan melalui cacheName, dan setiap cacheName sepadan kepada pelaksanaan A Cache.
package org.Springframework.cache;
import java.util.concurrent.Callable;
public interface Cache {
// cacheName,缓存的名字,默认实现中一般是CacheManager创建Cache的bean时传入cacheName
String getName();
//得到底层使用的缓存,如Ehcache
Object getNativeCache();
// 通过key获取缓存值,注意返回的是ValueWrapper,为了兼容存储空值的情况,将返回值包装了一层,通过get方法获取实际值
ValueWrapper get(Object key);
// 通过key获取缓存值,返回的是实际值,即方法的返回值类型
<T> T get(Object key, Class<T> type);
// 通过key获取缓存值,可以使用valueLoader.call()来调使用@Cacheable注解的方法。当@Cacheable注解的sync属性配置为true时使用此方法。
// 因此方法内需要保证回源到数据库的同步性。避免在缓存失效时大量请求回源到数据库
<T> T get(Object key, Callable<T> valueLoader);
// 将@Cacheable注解方法返回的数据放入缓存中
void put(Object key, Object value);
// 当缓存中不存在key时才放入缓存。返回值是当key存在时原有的数据
ValueWrapper putIfAbsent(Object key, Object value);
// 删除缓存
void evict(Object key);
// 清空缓存
void clear();
// 缓存返回值的包装
interface ValueWrapper {
// 返回实际缓存的对象
Object get();
}
}3. Anotasi yang biasa digunakan
: Terutamanya digunakan pada kaedah pertanyaan data.package org.Springframework.cache;
import java.util.Collection;
public interface CacheManager {
// 通过cacheName创建Cache的实现bean,具体实现中需要存储已创建的Cache实现bean,避免重复创建,也避免内存缓存
//对象(如Caffeine)重新创建后原来缓存内容丢失的情况
Cache getCache(String name);
// 返回所有的cacheName
Collection<String> getCacheNames();
}@Cacheable: Kosongkan cache, terutamanya digunakan untuk memadam data. Berbanding dengan Cacheable, ia mempunyai dua lagi atribut public @interface Cacheable {
// cacheNames,CacheManager就是通过这个名称创建对应的Cache实现bean
@AliasFor("cacheNames")
String[] value() default {};
@AliasFor("value")
String[] cacheNames() default {};
// 缓存的key,支持SpEL表达式。默认是使用所有参数及其计算的hashCode包装后的对象(SimpleKey)
String key() default "";
// 缓存key生成器,默认实现是SimpleKeyGenerator
String keyGenerator() default "";
// 指定使用哪个CacheManager,如果只有一个可以不用指定
String cacheManager() default "";
// 缓存解析器
String cacheResolver() default "";
// 缓存的条件,支持SpEL表达式,当达到满足的条件时才缓存数据。在调用方法前后都会判断
String condition() default "";
// 满足条件时不更新缓存,支持SpEL表达式,只在调用方法后判断
String unless() default "";
// 回源到实际方法获取数据时,是否要保持同步,如果为false,调用的是Cache.get(key)方法;如果为true,调用的是Cache.get(key, Callable)方法
boolean sync() default false;
}@CacheEvict: dimasukkan ke dalam cache, terutamanya digunakan untuk mengemas kini data. Rujukan perihalan atribut @Cacheable@CachePut
@Caching
@EnableCaching 3. Beberapa isu yang perlu dipertimbangkan apabila menggunakan cache tahap kedua?
Kami tahu bahawa data pangkalan data relasi (Mysql) akhirnya disimpan pada cakera Jika ia dibaca dari pangkalan data setiap kali, kelajuan bacaan akan dipengaruhi oleh IO cakera itu sendiri, jadi terdapat <.>
Cache memori seperti redis. Caching memori sememangnya boleh meningkatkan kelajuan pertanyaan, tetapi jika pertanyaan yang sama mempunyai konkurensi yang sangat besar dan pertanyaan redis yang kerap, terdapat juga penggunaan IO rangkaian yang jelas, Untuk jenis ini data (kunci panas) yang sangat kerap ditanya, bolehkah kami mempertimbangkan untuk menyimpannya dalam cache dalam aplikasi, seperti kafein? Apabila cache dalam apl mempunyai data yang layak, ia boleh digunakan terus tanpa perlu mendapatkannya daripada redis melalui rangkaian, sekali gus membentuk cache dua peringkat.Cache dalam apl dipanggil cache peringkat pertama dan cache jauh (seperti redis) dipanggil cache peringkat kedua
.Keseluruhan proses adalah seperti berikut
Proses ini kelihatan sangat menyegarkan, tetapi sebenarnya terdapat banyak perkara yang perlu dipertimbangkan dalam cache tahap kedua. 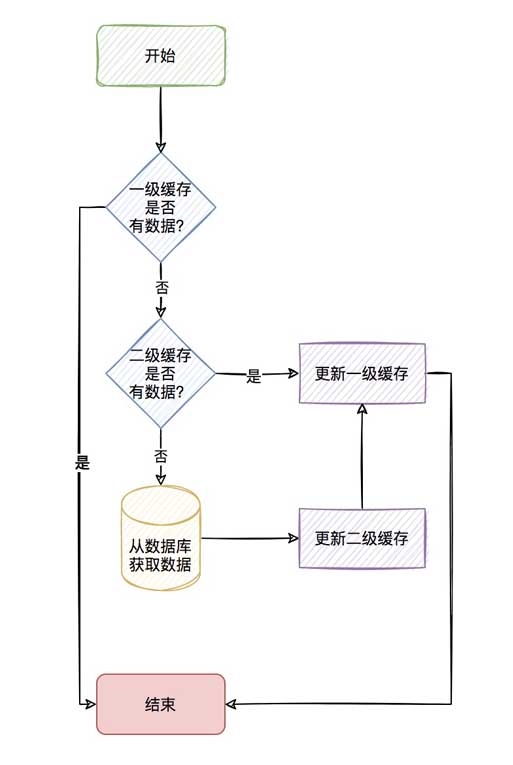
Kami mengatakan bahawa cache peringkat pertama ialah cache dalam aplikasi, jadi apabila projek anda digunakan pada berbilang nod, bagaimana untuk memastikan bahawa apabila anda mengubah suai kunci tertentu Apabila memadam, bagaimana untuk menjadikan cache peringkat pertama nod lain 如何保证分布式节点一级缓存的一致性?
Ini sememangnya satu perkara yang perlu diambil kira. Kerana jika pertanyaan tertentu tidak ada dalam cache atau pangkalan data, ia akan membawa kepada pertanyaan pangkalan data yang kerap, menyebabkan pangkalan data turun Ini juga yang sering kita 是否允许存储空值?
也就是说,我们会觉得某些key一开始就会非常的热,也就是热点数据,那么我们是否可以一开始就先存储到缓存中,避免缓存击穿。
4.一级缓存存储数量上限的考虑?
既然一级缓存是应用内缓存,那你是否考虑一级缓存存储的数据给个限定最大值,避免存储太多的一级缓存导致OOM。
5.一级缓存过期策略的考虑?
我们说redis作为二级缓存,redis是淘汰策略来管理的。具体可参考redis的8种淘汰策略。那你的一级缓存策略呢?就好比你设置一级缓存
数量最大为5000个,那当第5001个进来的时候,你是怎么处理呢?是直接不保存,还是说自定义LRU或者LFU算法去淘汰之前的数据?
6.一级缓存过期了如何清除?
我们说redis作为二级缓存,我们有它的缓存过期策略(定时、定期、惰性),那你的一级缓存呢,过期如何清除呢?
这里4、5、6小点如果说用我们传统的Map显然实现是很费劲的,但现在有更好用的一级缓存库那就是Caffeine。
四、Caffeine 简介
Caffeine,一个用于Java的高性能缓存库。
缓存和Map之间的一个根本区别是缓存会清理存储的项目。
1、写入缓存策略
Caffeine有三种缓存写入策略:手动、同步加载和异步加载。
2、缓存值的清理策略
Caffeine有三种缓存值的清理策略:基于大小、基于时间和基于引用。
基于容量:当缓存大小超过配置的大小限制时会发生回收。
基于时间:
写入后到期策略。
访问后过期策略。
到期时间由 Expiry 实现独自计算。
基于引用:启用基于缓存键值的垃圾回收。
Caffeine可以将值封装为弱引用或软引用,并且Java中还有强引用和虚引用这两种引用类型。
软引用:如果一个对象只具有软引用,则内存空间足够,垃圾回收器就不会回收它;如果内存空间不足了,就会回收这些对象的内存。
弱引用:在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会
回收它的内存。
3、统计
Caffeine提供了一种记录缓存使用统计信息的方法,可以实时监控缓存当前的状态,以评估缓存的健康程度以及缓存命中率等,方便后
续调整参数。
4、高效的缓存淘汰算法
缓存淘汰算法的目的是利用有限的资源,尽量预测哪些数据将会在短期内被频繁使用,以此来提高缓存的命中率。常用的缓存淘汰算法有
LRU、LFU、FIFO等。
FIFO:先进先出。选择最先进入的数据优先淘汰。 LRU:最近最少使用。选择最近最少使用的数据优先淘汰。 LFU:最不经常使用。选择在一段时间内被使用次数最少的数据优先淘汰。
LRU(Least Recently Used)算法认为最近访问过的数据将来被访问的几率也更高。
LRU通常使用链表来实现,如果数据添加或者被访问到则把数据移动到链表的头部,链表的头部为热数据,链表的尾部如冷数据,当
数据满时,淘汰尾部的数据。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问
的频率也更高”。根据LFU的思想,如果想要实现这个算法,需要额外的一套存储用来存每个元素的访问次数,会造成内存资源的浪费。
Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,其特点:高命中率、低内存占用。
5、其他说明
底层数据存储使用了ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突
严重时也能有良好的读性能。
五、基于Spring Cache实现二级缓存(Caffeine+Redis)
前面说了,使用了redis缓存,也会存在一定程度的网络传输上的消耗,所以会考虑应用内缓存,但有点很重要的要记住:
应用内缓存可以理解成比redis缓存更珍惜的资源,所以,caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。
当前项目针对应用都部署了多个节点,一级缓存是在应用内的缓存,所以当对数据更新和清除时,需要通知所有节点进行清理缓存的操作。
可以有多种方式来实现这种效果,比如:zookeeper、MQ等,但是既然用了redis缓存,redis本身是有支持订阅/发布功能的,所以就
不依赖其他组件了,直接使用redis的通道来通知其他节点进行清理缓存的操作。
只需通过发布订阅机制通知其他节点删除该key在本地一级缓存中的条目,即可在key更新或删除操作后实现同步。
具体具体项目代码这里就不再粘贴出来了,这样只粘贴如何引用这个starter包。
1、maven引入使用
<dependency>
<groupId>com.jincou</groupId>
<artifactId>redis-caffeine-cache-starter</artifactId>
<version>1.0.0</version>
</dependency>2、application.yml
添加二级缓存相关配置
# 二级缓存配置
# 注:caffeine 不适用于数据量大,并且缓存命中率极低的业务场景,如用户维度的缓存。请慎重选择。
l2cache:
config:
# 是否存储空值,默认true,防止缓存穿透
allowNullValues: true
# 组合缓存配置
composite:
# 是否全部启用一级缓存,默认false
l1AllOpen: false
# 是否手动启用一级缓存,默认false
l1Manual: true
# 手动配置走一级缓存的缓存key集合,针对单个key维度
l1ManualKeySet:
- userCache:user01
- userCache:user02
- userCache:user03
# 手动配置走一级缓存的缓存名字集合,针对cacheName维度
l1ManualCacheNameSet:
- userCache
- goodsCache
# 一级缓存
caffeine:
# 是否自动刷新过期缓存 true 是 false 否
autoRefreshExpireCache: false
# 缓存刷新调度线程池的大小
refreshPoolSize: 2
# 缓存刷新的频率(秒)
refreshPeriod: 10
# 写入后过期时间(秒)
expireAfterWrite: 180
# 访问后过期时间(秒)
expireAfterAccess: 180
# 初始化大小
initialCapacity: 1000
# 最大缓存对象个数,超过此数量时之前放入的缓存将失效
maximumSize: 3000
# 二级缓存
redis:
# 全局过期时间,单位毫秒,默认不过期
defaultExpiration: 300000
# 每个cacheName的过期时间,单位毫秒,优先级比defaultExpiration高
expires: {userCache: 300000,goodsCache: 50000}
# 缓存更新时通知其他节点的topic名称 默认 cache:redis:caffeine:topic
topic: cache:redis:caffeine:topic3、启动类上增加@EnableCaching
/**
* 启动类
*/
@EnableCaching
@SpringBootApplication
public class CacheApplication {
public static void main(String[] args) {
SpringApplication.run(CacheApplication.class, args);
}
}4、在需要缓存的方法上增加@Cacheable注解
/**
* 测试
*/
@Service
public class CaffeineCacheService {
private final Logger logger = LoggerFactory.getLogger(CaffeineCacheService.class);
/**
* 用于模拟db
*/
private static Map<String, UserDTO> userMap = new HashMap<>();
{
userMap.put("user01", new UserDTO("1", "张三"));
userMap.put("user02", new UserDTO("2", "李四"));
userMap.put("user03", new UserDTO("3", "王五"));
userMap.put("user04", new UserDTO("4", "赵六"));
}
/**
* 获取或加载缓存项
*/
@Cacheable(key = "'cache_user_id_' + #userId", value = "userCache")
public UserDTO queryUser(String userId) {
UserDTO userDTO = userMap.get(userId);
try {
Thread.sleep(1000);// 模拟加载数据的耗时
} catch (InterruptedException e) {
e.printStackTrace();
}
logger.info("加载数据:{}", userDTO);
return userDTO;
}
/**
* 获取或加载缓存项
* <p>
* 注:因底层是基于caffeine来实现一级缓存,所以利用的caffeine本身的同步机制来实现
* sync=true 则表示并发场景下同步加载缓存项,
* sync=true,是通过get(Object key, Callable<T> valueLoader)来获取或加载缓存项,此时valueLoader(加载缓存项的具体逻辑)会被缓存起来,所以CaffeineCache在定时刷新过期缓存时,缓存项过期则会重新加载。
* sync=false,是通过get(Object key)来获取缓存项,由于没有valueLoader(加载缓存项的具体逻辑),所以CaffeineCache在定时刷新过期缓存时,缓存项过期则会被淘汰。
* <p>
*/
@Cacheable(value = "userCache", key = "#userId", sync = true)
public List<UserDTO> queryUserSyncList(String userId) {
UserDTO userDTO = userMap.get(userId);
List<UserDTO> list = new ArrayList();
list.add(userDTO);
logger.info("加载数据:{}", list);
return list;
}
/**
* 更新缓存
*/
@CachePut(value = "userCache", key = "#userId")
public UserDTO putUser(String userId, UserDTO userDTO) {
return userDTO;
}
/**
* 淘汰缓存
*/
@CacheEvict(value = "userCache", key = "#userId")
public String evictUserSync(String userId) {
return userId;
}
}Atas ialah kandungan terperinci Cara melaksanakan cache tahap kedua Caffeine+Redis berdasarkan Cache Spring. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!