
Rumah >pangkalan data >tutorial mysql >Mengapa tidak disyorkan untuk menggunakan SELECT * dalam MySQL?
Mengapa tidak disyorkan untuk menggunakan SELECT * dalam MySQL?

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBke hadapan
- 2023-05-31 23:10:482209semak imbas
"Jangan gunakan SELECT *" hampir menjadi peraturan emas untuk MySQL Malah "Manual Pembangunan Java Alibaba" dengan jelas menyatakan bahawa * tidak dibenarkan untuk digunakan sebagai senarai medan pertanyaan, yang menjadikan ini. memerintah lebih popular.

Walau bagaimanapun, saya masih menggunakan SELECT * secara langsung semasa proses pembangunan atas dua sebab:
Oleh kerana ia mudah , kecekapan pembangunan adalah sangat tinggi, dan jika medan kerap ditambah atau diubah suai kemudian, pernyataan SQL tidak perlu diubah
Saya fikir pengoptimuman pramatang adalah tabiat buruk, melainkan ianya; dilakukan pada permulaan Anda boleh menentukan medan yang anda perlukan pada akhirnya dan mencipta indeks yang sesuai untuk mereka jika tidak, saya memilih untuk mengoptimumkan SQL apabila saya menghadapi masalah, sudah tentu dengan syarat masalah itu tidak membawa maut.
Tetapi kita sentiasa perlu tahu mengapa tidak digalakkan untuk menggunakan SELECT * secara langsung Artikel ini memberikan sebab dari 4 aspek.
1. I/O cakera yang tidak diperlukan
Kami tahu bahawa MySQL pada asasnya menyimpan rekod pengguna pada cakera, jadi operasi pertanyaan adalah tingkah laku melaksanakan cakera IO (dengan syarat Rekod yang ditanya tidak dicache dalam ingatan).
Lebih banyak medan yang anda tanya, lebih banyak kandungan yang perlu anda baca, yang akan meningkatkan overhed IO cakera. Terutama apabila sesetengah medan daripada jenis TEXT, MEDIUMTEXT atau BLOB, dsb., kesannya amat ketara.
Adakah menggunakan SELECT * menyebabkan MySQL mengambil lebih banyak memori?
Secara teorinya tidak, kerana untuk lapisan pelayan, set hasil lengkap tidak disimpan dalam memori dan kemudian dihantar kepada klien sekaligus, tetapi setiap kali satu baris diperoleh daripada enjin storan, Tulis ke ruang memori yang dipanggil net_buffer Saiz memori ini dikawal oleh pembolehubah sistem net_buffer_length lalai ialah 16KB apabila net_buffer penuh, data akan ditulis ke ruang memori tindanan rangkaian tempatan Hantar kepada pelanggan, kosongkan socket send buffer selepas berjaya menghantar (pembacaan pelanggan selesai), dan kemudian teruskan membaca dan menulis baris seterusnya. net_buffer
, dan ia tidak akan menduduki ruang memori tambahan hanya kerana beberapa medan lagi. net_buffer_length
dihantar kepada klien setiap kali, jumlah data dalam satu masa tidaklah besar dan ia Tidak dapat ditanggung. Seseorang sebenarnya menggunakan * untuk mencari medan jenis socket send buffer, TEXT atau MEDIUMTEXT Jumlah data adalah besar, yang secara langsung membawa kepada peningkatan dalam bilangan penghantaran rangkaian. BLOB
CREATE TABLE `user_innodb` ( `id` int NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `gender` tinyint(1) DEFAULT NULL, `phone` varchar(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `IDX_NAME_PHONE` (`name`,`phone`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;Kami mencipta jadual dengan enjin storan InnoDB
, dan Tetapkan user_innodb sebagai kunci utama, buat indeks bersama untuk id dan name, dan akhirnya secara rawak memulakan 500W+ keping data ke dalam jadual. phone
Ciri yang paling penting bagi pepohon B+ ini ialah nod daun mengandungi rekod pengguna yang lengkap Ia mungkin kelihatan seperti ini. id
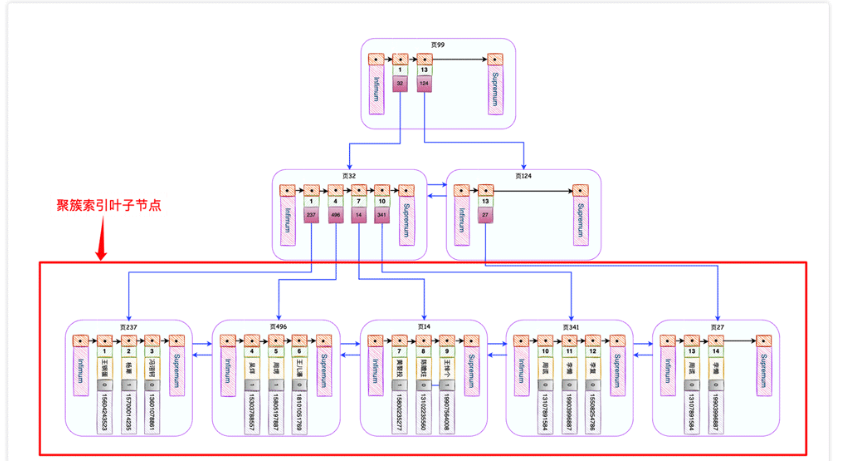
SELECT * FROM user_innodb WHERE name = '蝉沐风';Gunakan
untuk melihat pelan pelaksanaan pernyataan: EXPLAIN

, iaitu indeks sekunder. Nod daun indeks sekunder kelihatan seperti ini: IDX_NAME_PHONE
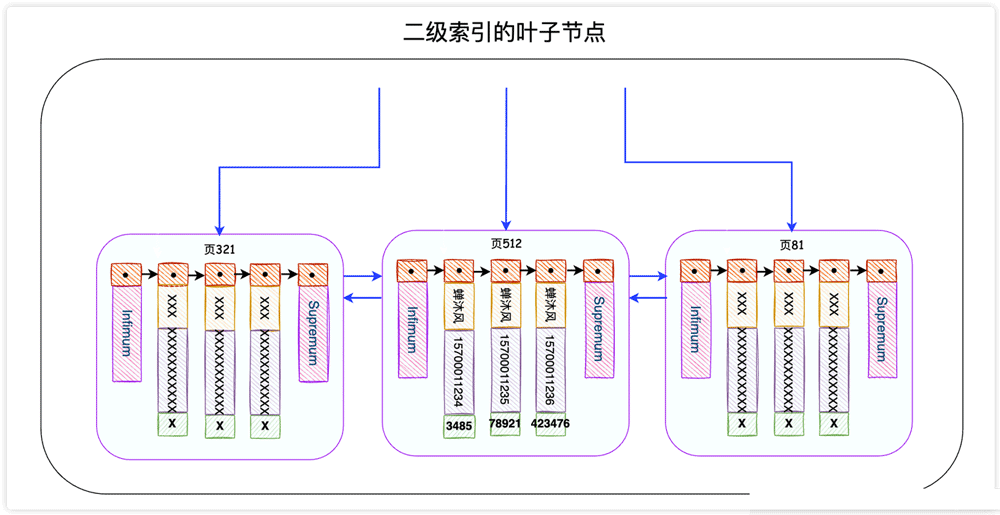
sebagai name dalam nod daun indeks sekunder berdasarkan keadaan carian, tetapi hanya medan 蝉沐风, name dan kunci utama phone direkodkan dalam indeks kedua (yang meminta kami menggunakan id), jadi InnoDB perlu menggunakan kunci utama SELECT * untuk mencari dalam indeks kunci primer Rekod lengkap ini, proses ini dipanggil idKembali ke jadual.
indeks penutup.
Sebagai contoh, kami kebetulan hanya mahu mencari, name dan medan kunci utama. phone
SELECT id, name, phone FROM user_innodb WHERE name = "蝉沐风";
使用EXPLAIN查看一下语句的执行计划:

可以看到Extra一列显示Using index,表示我们的查询列表以及搜索条件中只包含属于某个索引的列,也就是使用了覆盖索引,能够直接摒弃回表操作,大幅度提高查询效率。
4. 可能拖慢JOIN连接查询
我们创建两张表t1,t2进行连接操作来说明接下来的问题,并向t1表中插入了100条数据,向t2中插入了1000条数据。
CREATE TABLE `t1` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT; CREATE TABLE `t2` ( `id` int NOT NULL, `m` int DEFAULT NULL, `n` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT;
如果我们执行下面这条语句
SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.m = t2.m;
这里我使用了STRAIGHT_JOIN强制令
t1表作为驱动表,t2表作为被驱动表
对于连接查询而言,驱动表只会被访问一遍,而被驱动表却要被访问好多遍,具体的访问次数取决于驱动表中符合查询记录的记录条数。现在,我们来讲一下两个表连接的本质,因为驱动表和被驱动表已经被强制确定
t1作为驱动表,针对驱动表的过滤条件,执行对t1表的查询。因为没有过滤条件,也就是获取t1表的所有数据;对上一步中获取到的结果集中的每一条记录,都分别到被驱动表中,根据连接过滤条件查找匹配记录
用伪代码表示的话整个过程是这样的:
// t1Res是针对驱动表t1过滤之后的结果集
for (t1Row : t1Res){
// t2是完整的被驱动表
for(t2Row : t2){
if (满足join条件 && 满足t2的过滤条件){
发送给客户端
}
}
}这种方法最简单,但同时性能也是最差,这种方式叫做嵌套循环连接(Nested-LoopJoin,NLJ)。怎么加快连接速度呢?
其中一个办法就是创建索引,最好是在被驱动表(t2)连接条件涉及到的字段上创建索引,毕竟被驱动表需要被查询好多次,而且对被驱动表的访问本质上就是个单表查询而已(因为t1结果集定了,每次连接t2的查询条件也就定死了)。
既然使用了索引,为了避免重蹈无法使用覆盖索引的覆辙,我们也应该尽量不要直接SELECT *,而是将真正用到的字段作为查询列,并为其建立适当的索引。
但是如果我们不使用索引,MySQL就真的按照嵌套循环查询的方式进行连接查询吗?当然不是,毕竟这种嵌套循环查询实在是太慢了!
在MySQL8.0之前,MySQL提供了基于块的嵌套循环连接(Block Nested-Loop Join,BLJ)方法,MySQL8.0又推出了hash join方法,这两种方法都是为了解决一个问题而提出的,那就是尽量减少被驱动表的访问次数。
这两种方法都用到了一个叫做join buffer的固定大小的内存区域,其中存储着若干条驱动表结果集中的记录(这两种方法的区别就是存储的形式不同而已),如此一来,把被驱动表的记录加载到内存的时候,一次性和join buffer中多条驱动表中的记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价,大大减少了重复从磁盘上加载被驱动表的代价。使用join buffer的过程如下图所示:
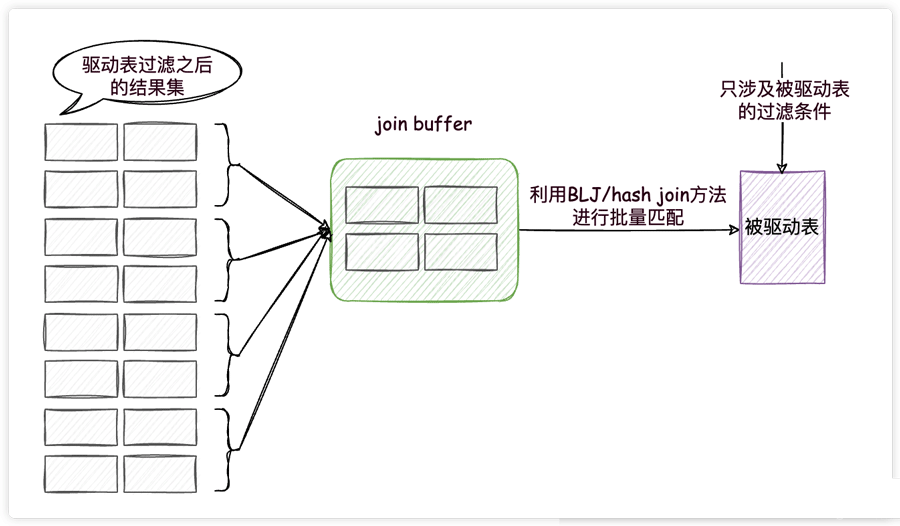
我们看一下上面的连接查询的执行计划,发现确实使用到了hash join(前提是没有为t2表的连接查询字段创建索引,否则就会使用索引,不会使用join buffer)。

最好的情况是join buffer足够大,能容纳驱动表结果集中的所有记录,这样只需要访问一次被驱动表就可以完成连接操作了。我们可以使用join_buffer_size这个系统变量进行配置,默认大小为256KB。如果还装不下,就得分批把驱动表的结果集放到join buffer中了,在内存中对比完成之后,清空join buffer再装入下一批结果集,直到连接完成为止。
重点来了!并不是驱动表记录的所有列都会被放到join buffer中,只有查询列表中的列和过滤条件中的列才会被放到join buffer中,所以再次提醒我们,最好不要把*作为查询列表,只需要把我们关心的列放到查询列表就好了,这样还可以在join buffer中放置更多的记录,减少分批的次数,也就自然减少了对被驱动表的访问次数
Atas ialah kandungan terperinci Mengapa tidak disyorkan untuk menggunakan SELECT * dalam MySQL?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!