
Rumah >pangkalan data >tutorial mysql >Apakah sebab mengapa indeks mysql pantas?
Apakah sebab mengapa indeks mysql pantas?

- PHPzke hadapan
- 2023-05-31 20:58:101997semak imbas
Dengan pra-isih, indeks boleh dicari menggunakan algoritma yang cekap seperti carian binari. Kerumitan carian berurutan am ialah O(n), manakala kerumitan carian binari ialah O(log2n); apabila n adalah sangat besar, perbezaan kecekapan antara keduanya adalah besar.
Mysql ialah pangkalan data yang sangat popular di Internet Reka bentuk enjin storan asasnya dan enjin perolehan data adalah sangat penting, khususnya, bentuk storan data Mysql dan reka bentuk indeksnya data keseluruhan prestasi Pengambilan Mysql.
Kami tahu bahawa fungsi indeks adalah untuk mendapatkan semula data dengan cepat, dan intipati perolehan pantas ialah struktur data. Melalui pemilihan struktur data yang berbeza, pelbagai data boleh diperoleh dengan cepat. Dalam pangkalan data, algoritma carian yang cekap adalah sangat penting, kerana sejumlah besar data disimpan dalam pangkalan data, dan indeks yang cekap dapat menjimatkan masa yang besar. Sebagai contoh, dalam jadual data berikut, jika Mysql tidak melaksanakan algoritma indeks, maka untuk mencari data dengan id=7, anda hanya boleh menggunakan traversal berurutan yang ganas untuk mencari data Untuk mencari data dengan id=7, anda perlu membandingkannya 7 kali Jika jadual ini menyimpan 10 juta keping data Untuk mencari data dengan id=1000W, ia akan dibandingkan 1000W kali ini.

1. Indeks Mysql pemilihan struktur data asas
Jadual cincang (Hash)
Jadual cincang ialah alat yang berkesan untuk mendapatkan semula data yang pantas.
Algoritma cincang: Juga dipanggil algoritma cincang, ia menukar sebarang nilai (kunci) kepada alamat kunci panjang tetap melalui fungsi cincang dan menggunakan alamat ini untuk mencipta struktur data bagi data tertentu.

Pertimbangkan pengguna jadual pangkalan data ini. Kami perlu mendapatkan semula data dengan id= 7. Sintaks SQL ialah:
select * from user where id=7;
Algoritma cincang mula-mula mengira alamat fizikal addr=hash(7)=4231 untuk menyimpan data dengan id=7, dan alamat fizikal yang dipetakan oleh 4231 ialah 0x77, dan 0x77 ialah tempat id=7 disimpan Alamat fizikal data Data yang sepadan dengan user_name='g' boleh didapati melalui alamat bebas ini. Ini ialah proses pengiraan yang digunakan oleh algoritma cincang untuk mendapatkan semula data dengan cepat.
Walau bagaimanapun, algoritma cincang mempunyai masalah perlanggaran data, iaitu fungsi cincang mungkin mengira hasil yang sama untuk kunci yang berbeza Contohnya, cincang(7) mungkin mengira hasil yang sama seperti cincang(199). Iaitu, kunci yang berbeza dipetakan kepada hasil yang sama. Ini adalah masalah perlanggaran. Cara biasa untuk menyelesaikan masalah perlanggaran ialah kaedah alamat rantai, yang menggunakan senarai terpaut untuk menyambungkan data yang berlanggar. Selepas mengira nilai cincang, anda juga perlu menyemak sama ada nilai cincang mempunyai perlanggaran dalam senarai terpaut data, dan jika ya, rentas hingga ke penghujung senarai terpaut sehingga anda menemui data yang sepadan dengan kunci sebenar.
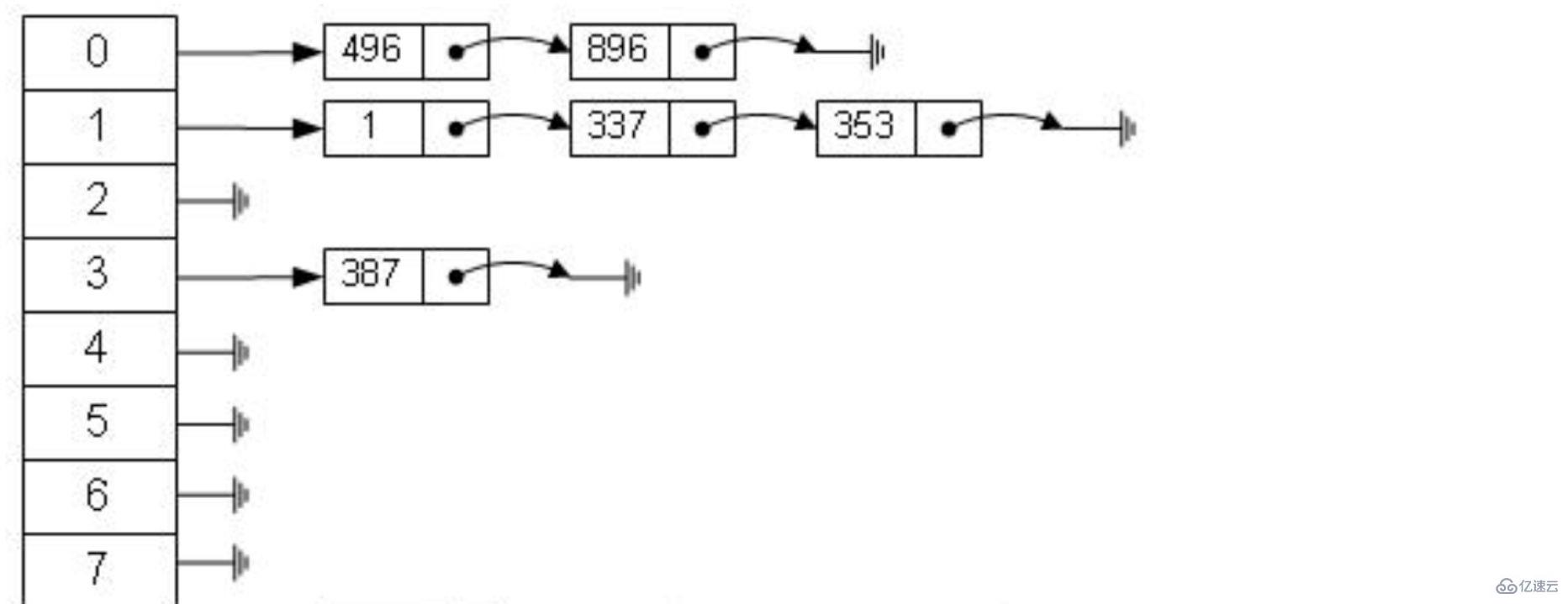

Daripada kerumitan masa algoritma Daripada analisis, kerumitan masa algoritma cincang ialah O(1), dan kelajuan perolehan adalah sangat pantas. Sebagai contoh, apabila mencari data dengan id=7, indeks cincang hanya perlu dikira sekali untuk mendapatkan data yang sepadan dan kelajuan perolehan adalah sangat pantas. Tetapi Mysql tidak menggunakan pencincangan sebagai algoritma asasnya. Mengapa ini?
Oleh kerana kaedah biasa untuk mendapatkan data ialah carian julat, seperti pernyataan SQL berikut:
select * from user where id \>3;
Untuk pernyataan di atas, perkara yang ingin kami lakukan ialah mencari data dengan id>3 , Ini ialah carian julat yang sangat tipikal. Jika anda menggunakan indeks yang dilaksanakan oleh algoritma cincang, bagaimana untuk melakukan carian julat? Idea mudah ialah mencari semua data sekaligus dan memuatkannya ke dalam memori, dan kemudian menapis data dalam julat sasaran dalam memori. Tetapi kaedah carian julat ini terlalu rumit dan tidak cekap sama sekali.
Oleh itu, walaupun indeks yang dilaksanakan menggunakan algoritma cincang boleh mendapatkan semula data dengan cepat, ia tidak dapat melakukan carian julat data yang cekap Oleh itu, indeks cincang tidak sesuai sebagai struktur data untuk indeks asas Mysql.
Pokok Carian Perduaan (BST)
Pokok carian binari ialah struktur data yang menyokong carian data pantas, seperti ditunjukkan dalam rajah di bawah:

Kerumitan masa bagi pokok carian binari ialah O(lgn Sebagai contoh, untuk struktur pokok binari di atas, kita perlu mengira dan membandingkan 3 kali untuk mendapatkannya Data dengan id=7 menjimatkan separuh masa berbanding dengan pertanyaan traversal langsung Dari perspektif kecekapan perolehan, nampaknya pencarian berkelajuan tinggi boleh dicapai. Di samping itu, bolehkah struktur pokok binari menyelesaikan fungsi carian julat yang tidak dapat disediakan oleh indeks cincang?
Jawapannya ya. Perhatikan gambar di atas. Nod daun pokok binari disusun mengikut urutan, dalam susunan menaik dari kiri ke kanan Jika kita perlu mencari data dengan id>5, maka kita boleh mengeluarkan nod dengan nod 6 dan ia. subtree kanan , carian julat agak mudah untuk dilaksanakan.
Tetapi pepohon carian binari biasa mempunyai kelemahan yang membawa maut: dalam kes yang melampau, ia akan merosot menjadi senarai pautan linear, carian binari juga akan merosot kepada carian traversal, kerumitan masa akan merosot kepada O(N), dan prestasi perolehan akan menurun secara mendadak. Sebagai contoh, dalam situasi berikut, pokok perduaan adalah sangat tidak seimbang dan telah merosot ke dalam senarai terpaut, dan kelajuan mendapatkan kembali sangat berkurangan. Pada masa ini, bilangan pengiraan yang diperlukan untuk mendapatkan semula data dengan id=7 telah menjadi 7.

Dalam pangkalan data, penambahan automatik data ialah bentuk yang sangat biasa Contohnya, kunci utama a jadual ialah id. Kunci utama biasanya meningkat secara automatik secara lalai Jika struktur data seperti pepohon binari digunakan sebagai indeks, masalah carian linear yang disebabkan oleh keadaan tidak seimbang yang diperkenalkan di atas pasti akan berlaku. Oleh itu, pepohon carian binari mudah mempunyai masalah penurunan prestasi perolehan yang disebabkan oleh ketidakseimbangan, dan tidak boleh digunakan secara langsung untuk melaksanakan indeks asas Mysql.
Pokok AVL dan pokok merah-hitam
Pokok carian binari mempunyai masalah ketidakseimbangan, jadi ulama mencadangkan untuk membuat pokok binari melalui putaran automatik dan pelarasan pokok nod Dengan sentiasa mengekalkan keadaan pada asasnya seimbang, anda boleh mengekalkan prestasi carian terbaik bagi pepohon carian binari. Pokok binari keadaan keseimbangan laras sendiri berdasarkan idea ini termasuk pokok AVL dan pokok merah-hitam.
Pertama sekali, mari kita perkenalkan secara ringkas pokok merah-hitam Ini adalah struktur pokok yang secara automatik menyesuaikan bentuk pokok, sebagai contoh, apabila pokok binari dalam keadaan tidak seimbang, pokok merah-hitam akan memusingkan nod kiri dan kanan secara automatik dan nod akan bertukar warna Melaraskan bentuk pokok untuk mengekalkan keadaan seimbang asas (kerumitan masa ialah O(logn)) memastikan kecekapan carian tidak akan berkurangan dengan ketara. Contohnya, jika nod data dimasukkan dalam tertib menaik dari 1 hingga 7, pokok carian binari biasa akan merosot menjadi senarai terpaut, tetapi pokok merah-hitam akan terus melaraskan bentuk pokok untuk mengekalkan keseimbangan asas, seperti yang ditunjukkan. dalam rajah di bawah. Bilangan nod yang hendak dibandingkan apabila mencari id=7 dalam pokok merah-hitam di bawah ialah 4, yang masih mengekalkan kecekapan carian yang baik bagi pokok binari.
Pokok merah-hitam mempunyai kecekapan carian purata yang baik, dan tiada situasi O(n) yang melampau Bolehkah pokok merah-hitam digunakan sebagai pelaksanaan indeks asas Mysql? Malah, pokok merah-hitam juga mempunyai beberapa masalah Lihat contoh di bawah.
Pokok merah-hitam memasukkan 1~7 nod secara berurutan, dan bilangan nod yang perlu dikira semasa mencari id=7 ialah 4.

Pokok merah-hitam memasukkan 1~16 nod secara berurutan, dan bilangan nod yang perlu dibandingkan dengan cari id=16 ialah 6 kali . Perhatikan bentuk pokok ini. Adakah benar apabila data dimasukkan secara berurutan, bentuk pokok itu sentiasa berada dalam arah aliran "miring ke kanan"? Pada asasnya, pokok merah-hitam tidak menyelesaikan sepenuhnya pepohon carian perduaan Walaupun arah aliran "bersandar ke kanan" ini jauh lebih kecil daripada pepohon carian perduaan yang merosot menjadi senarai terpaut linear, operasi kenaikan automatik kunci utama asas dalam. pangkalan data, kunci utama biasanya Berjuta-juta dan berpuluh-puluh juta Jika pokok merah-hitam mempunyai masalah seperti ini, ia juga akan menggunakan sejumlah besar prestasi carian kami tidak boleh bertolak ansur dengan penantian yang tidak bermakna ini.

Sekarang pertimbangkan satu lagi pokok binari pengimbangan diri yang lebih ketat, pokok AVL. Oleh kerana pokok AVL ialah pokok binari yang benar-benar seimbang, ia menggunakan lebih banyak prestasi dalam melaraskan bentuk pokok binari.
Pokok AVL memasukkan 1~7 nod secara berurutan, dan bilangan perbandingan yang diperlukan untuk mencari nod dengan id=7 ialah 3.

Pokok AVL secara berurutan memasukkan 1~16 nod dan bilangan nod yang perlu dibandingkan untuk mencari id= 16 ialah 4. Dari segi kecekapan carian, kelajuan carian pokok AVL adalah lebih tinggi daripada pokok merah-hitam (pokok AVL ialah 4 perbandingan, pokok merah-hitam ialah 6 perbandingan). Jika dilihat dari bentuk pokok, pokok AVL tidak mempunyai masalah "condong yang betul" seperti pokok merah-hitam. Dalam erti kata lain, sejumlah besar sisipan berurutan tidak akan membawa kepada penurunan dalam prestasi pertanyaan, yang secara asasnya menyelesaikan masalah pokok merah-hitam.

Untuk meringkaskan kelebihan pokok AVL:
Prestasi carian yang baik (O(logn)), tiada situasi carian tidak cekap yang melampau.
boleh merealisasikan carian julat dan pengisihan data.
Nampaknya pokok AVL sangat bagus sebagai struktur data untuk carian data, tetapi pokok AVL tidak sesuai untuk struktur data indeks pangkalan data Mysql, kerana pertimbangkan masalah ini:
Hambatan data pertanyaan pangkalan data ialah cakera IO Jika kita menggunakan pepohon AVL, setiap nod pokok kita hanya boleh mengeluarkan data pada satu nod dan memuatkannya ke dalam memori dengan satu cakera IO Kemudian Sebagai contoh, untuk menanyakan data id=7, kita perlu melakukan cakera IO tiga kali, yang sangat memakan masa. Oleh itu, apabila mereka bentuk indeks pangkalan data, kita perlu terlebih dahulu mempertimbangkan cara mengurangkan bilangan IO cakera sebanyak mungkin.
Satu ciri cakera IO ialah masa yang diperlukan untuk membaca data 1B dan data 1KB dari cakera pada asasnya adalah sama Berdasarkan idea ini, kita boleh membaca seberapa banyak data yang mungkin pada nod pokok. Simpan data dengan cekap, dan muatkan lebih banyak data ke dalam memori dalam satu cakera IO Ini adalah prinsip reka bentuk B-tree dan B+ tree.
B-tree
B-tree berikut adalah terhad untuk menyimpan sehingga dua kekunci setiap nod. Jika nod mempunyai lebih daripada dua kekunci, ia akan berpecah secara automatik. Sebagai contoh, B-tree berikut menyimpan 7 data Anda hanya perlu menanyakan dua nod untuk mengetahui lokasi tertentu data dengan id=7 Iaitu, anda boleh menanyakan data yang ditentukan dengan dua IO cakera, yang lebih baik daripada pokok AVL.

Berikut ialah pokok B yang menyimpan 16 keping data Setiap nod juga menyimpan sehingga 2 kekunci. Pertanyaan Data dengan id=16 perlu disoal dan dibandingkan pada 4 nod, yang bermaksud 4 kali IO cakera. Nampaknya prestasi pertanyaan adalah sama dengan pepohon AVL.

Tetapi memandangkan masa yang digunakan oleh cakera IO untuk membaca satu keping data pada asasnya sama seperti membaca 100 keping data, kemudian pengoptimuman kami Idea ini boleh ditukar kepada: membaca sebanyak mungkin data ke dalam memori dalam satu cakera IO. Ini secara langsung dicerminkan dalam struktur pokok, iaitu kunci yang boleh disimpan oleh setiap nod boleh ditingkatkan dengan sewajarnya.
Apabila kami menetapkan had nombor kunci untuk satu nod kepada 6, untuk pokok B yang menyimpan 7 keping data, cakera IO yang diperlukan untuk menanyakan data dengan id=7 ialah 2 kali.

Pokok B yang menyimpan 16 keping data Menanyakan data dengan id=7 memerlukan 2 IO cakera. Berbanding dengan pokok AVL, bilangan IO cakera dikurangkan kepada separuh.

Jadi dari segi pemilihan struktur data indeks pangkalan data, B-tree adalah pilihan yang sangat baik . Ringkasnya, B-tree mempunyai kelebihan berikut apabila digunakan sebagai indeks pangkalan data:
Kelajuan mendapatkan semula yang sangat baik, kerumitan masa: Prestasi carian B- pokok adalah sama dengan O(h* logn), dengan h ialah ketinggian pokok, n ialah bilangan kata kunci dalam setiap nod; mempercepatkan pengambilan semula;
boleh menyokong carian julat.
Pokok B+
Apakah perbezaan antara pokok B dan pokok B+?
Pertama, B tree menyimpan data dalam satu nod, manakala B+ tree menyimpan indeks (alamat), jadi satu nod dalam B tree tidak boleh menyimpan banyak data, tetapi satu nod daripada pokok B+ boleh menyimpan banyak indeks, dan nod daun pokok B+ menyimpan semua data.
Kedua, Nod daun pokok B+ disambungkan secara bersiri dengan senarai terpaut dalam peringkat data untuk memudahkan carian julat.
 2. Pelaksanaan enjin Innodb dan enjin Myisam
2. Pelaksanaan enjin Innodb dan enjin Myisam Walaupun MyISAM mempunyai prestasi carian data yang sangat baik, ia tidak menyokong pemprosesan transaksi. Ciri terbesar Innodb ialah ia menyokong fungsi transaksi yang serasi dengan ACID dan ia menyokong kunci peringkat baris. Anda boleh menentukan enjin apabila Mysql mencipta jadual Contohnya, dalam contoh berikut, Myisam dan Innodb ditetapkan sebagai enjin data untuk jadual pengguna dan jadual pengguna2.



frm: pernyataan untuk mencipta jadual
idb: data + fail indeks dalam jadual
Myisam selepas mencipta jadual Fail yang dijana termasuk
frm: pernyataan untuk mencipta jadual
MYD: fail data dalam jadual (data myisam )
MYI: Fail indeks dalam jadual (indeks myisam)
Daripada fail yang dijana, nampaknya data asas dan indeks ini dua enjin Kaedah organisasi adalah berbeza Enjin MyISAM memisahkan data dan indeks, dan setiap orang mempunyai satu fail Ini dipanggil kaedah indeks tidak berkelompok dipanggil kaedah indeks berkelompok. Berikut akan menganalisis cara kedua-dua enjin ini bergantung pada struktur data pokok B+ untuk mengatur pelaksanaan enjin dari perspektif pelaksanaan asas.
Pelaksanaan asas enjin MyISAM (mod indeks bukan berkelompok)
MyISAM menggunakan mod indeks bukan berkelompok, iaitu data dan indeks jatuh kepada dua yang berbeza pada fail. Apabila MyISAM mencipta jadual, ia menggunakan kunci utama sebagai KEY untuk mencipta pokok indeks B+ utama Nod daun pokok menyimpan alamat fizikal data yang sepadan. Selepas kami mendapat alamat fizikal ini, kami boleh mencari terus rekod data tertentu dalam fail data MyISAM.

Apabila kita menambah indeks pada medan, kita juga akan menjana pokok indeks untuk medan yang sepadan nod pokok indeks juga merekodkan alamat fizikal data yang sepadan, dan kemudian gunakan alamat fizikal ini untuk mencari rekod data tertentu dalam fail data.
Pelaksanaan asas enjin Innodb (kaedah indeks berkelompok)
InnoDB ialah kaedah indeks berkelompok, jadi data dan indeks disimpan dalam yang sama fail. Mula-mula, InnoDB akan mencipta pepohon indeks B+ berdasarkan ID kunci utama sebagai KEY, seperti yang ditunjukkan dalam rajah di bawah, dan nod daun pepohon B+ menyimpan data yang sepadan dengan ID kunci utama Sebagai contoh, apabila melaksanakan pernyataan pilih * dari info_pengguna di mana id=15, InnoDB Ia akan menanyakan pepohon indeks B+ ID kunci utama dan mencari nama_pengguna='Bob' yang sepadan.
InnoDB akan membina pepohon indeks ID kunci utama secara automatik apabila mencipta jadual. Inilah sebab mengapa Mysql memerlukan kunci utama ditentukan semasa membuat jadual. Bagaimanakah InnoDB membina pepohon indeks apabila kita menambah indeks pada medan dalam jadual? Sebagai contoh, jika kita ingin menambah indeks pada medan nama_pengguna, maka InnoDB akan mencipta pepohon indeks nama_pengguna B+ KUNCI nama_pengguna disimpan dalam nod, dan data yang disimpan dalam nod daun ialah KEY kunci utama. Ambil perhatian bahawa daun menyimpan kunci utama KEY! Selepas mendapat KEY kunci utama, InnoDB akan pergi ke pepohon indeks kunci utama untuk mencari data yang sepadan berdasarkan KEY kunci utama yang baru ditemui dalam pepohon indeks nama_pengguna.

Persoalannya, mengapa InnoDB hanya menyimpan data tertentu dalam nod daun pokok indeks kunci utama, tetapi tidak dalam yang lain pepohon indeks? Bagaimana dengan data khusus? Bagaimana jika kita perlu mencari kunci utama dahulu dan kemudian mencari data yang sepadan dalam pepohon indeks kunci utama?
Ia sebenarnya sangat mudah, kerana InnoDB perlu menjimatkan ruang storan . Mungkin terdapat banyak indeks dalam jadual InnoDB akan menghasilkan pepohon indeks untuk setiap medan yang diindeks Jika pepohon indeks setiap medan menyimpan data tertentu, maka fail data indeks jadual ini akan menjadi sangat besar (data Sangat berlebihan). Dari perspektif penjimatan ruang cakera, sebenarnya tidak perlu menyimpan data khusus dalam setiap pokok indeks medan Melalui langkah yang kelihatan "tidak perlu" ini, ruang cakera yang besar dijimatkan dengan mengorbankan prestasi pertanyaan yang kurang.
Apabila membandingkan ciri-ciri InnoDB dan MyISAM, disebutkan bahawa MyISAM mempunyai prestasi pertanyaan yang lebih baik Sebabnya juga boleh dilihat daripada reka bentuk fail data fail indeks di atas: MyISAM boleh mengesan alamat fizikal secara langsung selepas. mencari rekod data secara langsung, tetapi selepas InnoDB menanyakan nod daun, ia perlu menanya semula pokok indeks kunci utama untuk mencari data tertentu. Ini bermakna MyISAM boleh mencari data dalam satu langkah, tetapi InnoDB memerlukan dua langkah Sudah tentu, prestasi pertanyaan MyISAM lebih tinggi.
Atas ialah kandungan terperinci Apakah sebab mengapa indeks mysql pantas?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!