
Rumah >Peranti teknologi >AI >Seseorang akhirnya menjelaskan keadaan semasa GPT! Ucapan terbaharu OpenAI menjadi tular, dan ia mestilah seorang genius yang dipilih sendiri oleh Musk
Seseorang akhirnya menjelaskan keadaan semasa GPT! Ucapan terbaharu OpenAI menjadi tular, dan ia mestilah seorang genius yang dipilih sendiri oleh Musk

- PHPzke hadapan
- 2023-05-31 16:23:411266semak imbas
Susulan keluaran Windows Copilot, populariti persidangan Microsoft Build telah dicetuskan oleh ucapan.
Bekas Pengarah AI Tesla Andrej Karpathy percaya dalam ucapannya bahawa pohon pemikiran serupa dengan Carian Pokok Monte Carlo (MCTS) AlphaGo
Alangkah hebatnya! Netizen menjerit: Ini adalah panduan paling terperinci dan menarik tentang cara menggunakan model bahasa besar dan model GPT-4!
Skor Claude adalah antara ChatGPT 3.5 dan ChatGPT 4.

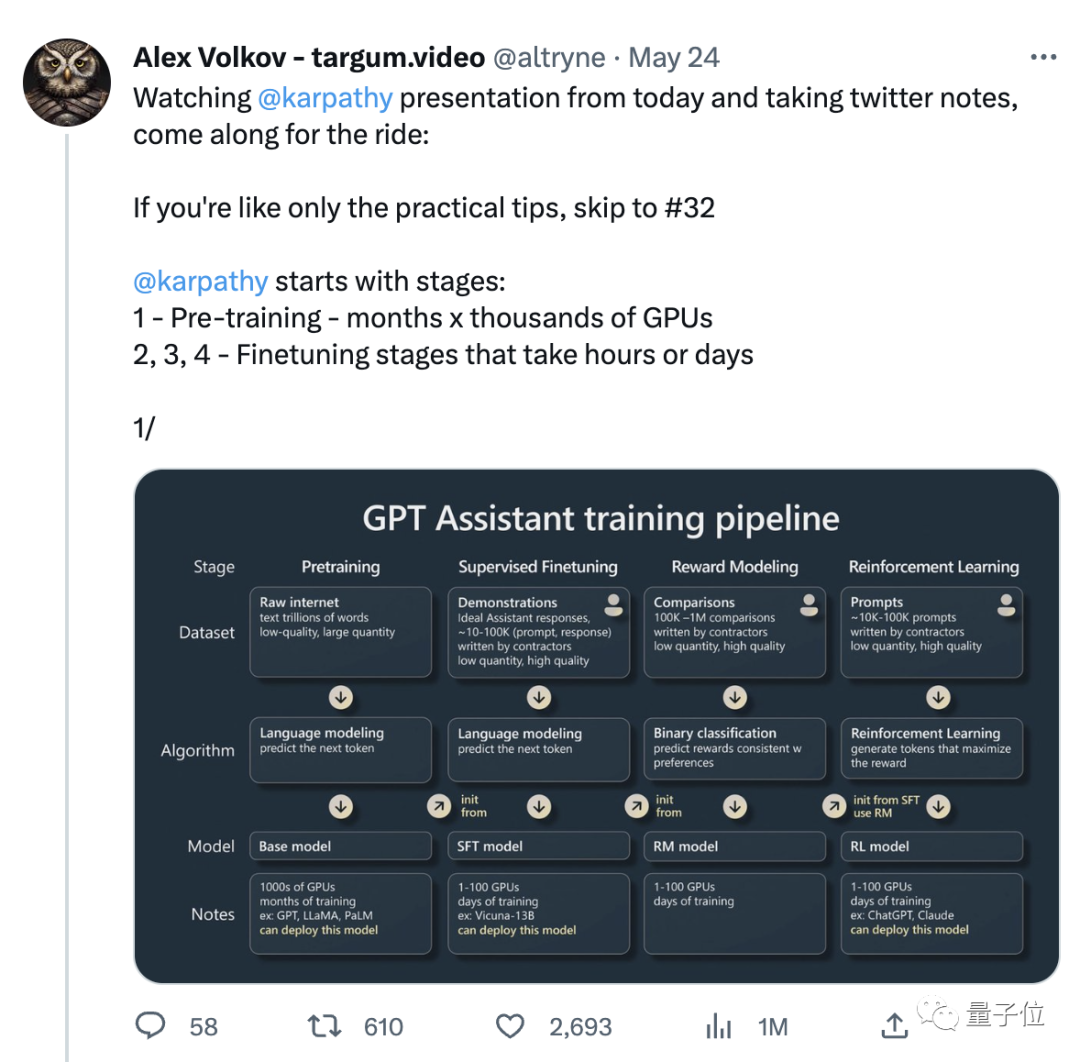
Bahagian pertama
, dia bercakap tentang cara melatih "Pembantu GPT".
Karpathy terutamanya bercakap tentang empat peringkat latihan pembantu AI:

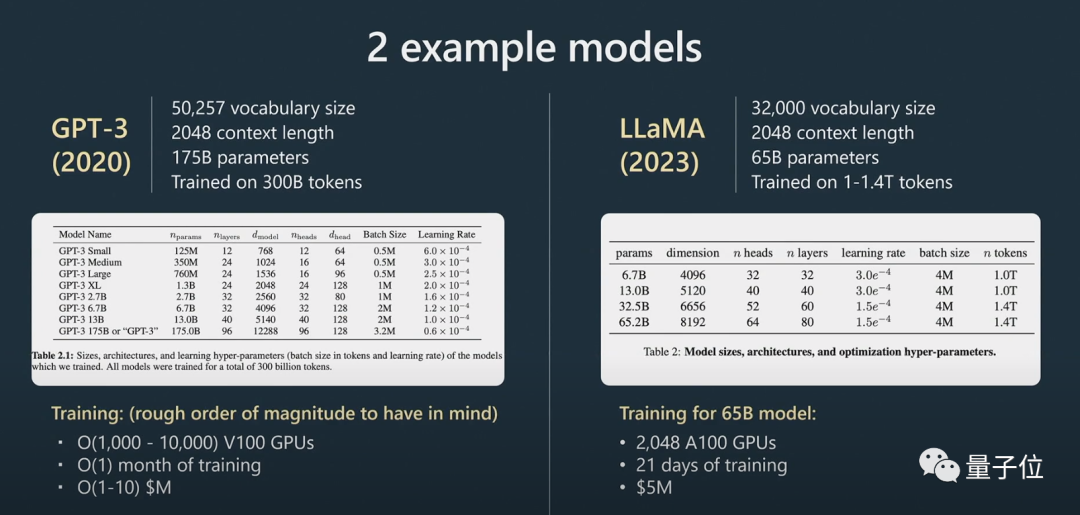
Menggunakan set data penyeliaan yang lebih kecil, memperhalusi model asas ini melalui pembelajaran terselia menghasilkan model pembantu
yang boleh menjawab soalan.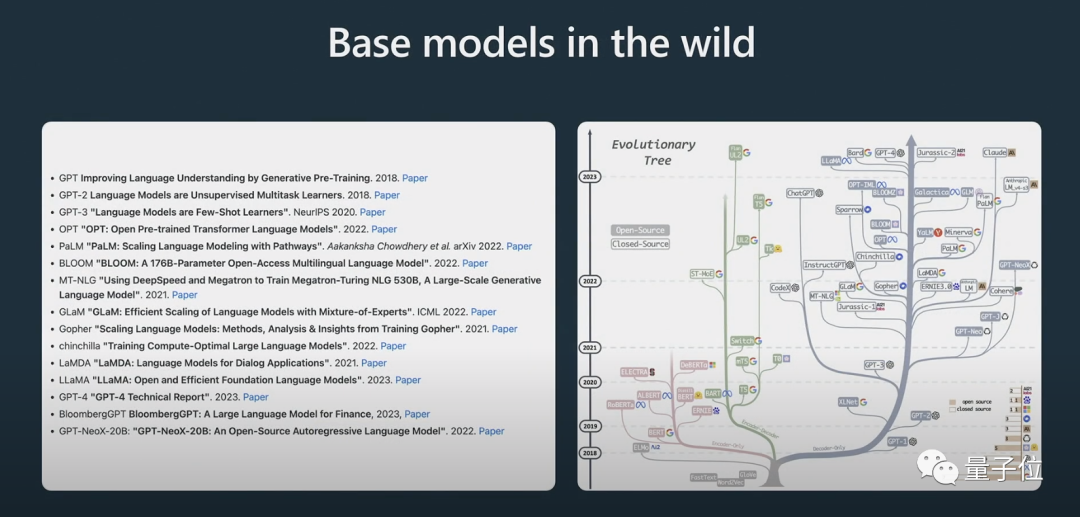
Perlu dinyatakan dengan jelas di sini bahawa model asas bukan model pembantu
. Walaupun model asas mempunyai keupayaan untuk menyelesaikan masalah, jawapan yang diberikannya tidak boleh dipercayai, manakala model pembantu boleh memberikan jawapan yang boleh dipercayai. Model pembantu diperhalusi diselia dilatih berdasarkan model asas, dan prestasinya dalam menjana balasan dan memahami struktur teks akan lebih baik daripada model asas. Pembelajaran pengukuhan ialah satu lagi proses utama apabila melatih model bahasa. Data beranotasi manual berkualiti tinggi digunakan dalam proses latihan dan fungsi kerugian dicipta dalam cara pemodelan ganjaran untuk meningkatkan prestasinya. Latihan pengukuhan boleh dicapai dengan meningkatkan kebarangkalian pemarkahan positif dan mengurangkan kebarangkalian pemarkahan negatif. Pertimbangan manusia adalah penting untuk menambah baik model AI apabila ia melibatkan tugas kreatif, dan model boleh dilatih dengan lebih berkesan dengan menggabungkan maklum balas manusia. Selepas pembelajaran pengukuhan dengan maklum balas manusia, model RLHF boleh diperolehi. Selepas model dilatih, langkah seterusnya ialah cara menggunakan model ini dengan berkesan untuk menyelesaikan masalah.Bagaimana untuk menggunakan model dengan lebih baik?
Dalam Bahagian 2, Karpathy membincangkan strategi yang mendorong, penalaan halus, ekosistem alat yang berkembang pesat dan pengembangan masa hadapan.
Karpathy memberikan satu lagi contoh khusus untuk menggambarkan:

Apabila menulis, kita perlu melakukan banyak aktiviti mental , termasuk mempertimbangkan sama ada ungkapan anda tepat. Untuk GPT, ini hanyalah urutan token yang ditandakan.
Dan prompt boleh mengimbangi jurang kognitif ini.
Karpathy menerangkan dengan lebih lanjut cara Rantai Pemikiran gesaan berfungsi.
Untuk masalah penaakulan, jika anda mahu Transformer berprestasi lebih baik dalam pemprosesan bahasa semula jadi, anda perlu membiarkannya memproses maklumat secara langkah demi langkah dan bukannya terus melemparkannya masalah yang sangat kompleks.
Jika anda memberikan beberapa contoh, ia akan meniru templat contoh ini dan hasil akhir akan menjadi lebih baik.

Model hanya boleh menjawab soalan dalam urutannya Jika kandungan yang dijananya salah, anda boleh menggesanya untuk Menjana semula.
Jika anda tidak memintanya menyemak, ia tidak akan menyemak sendiri.
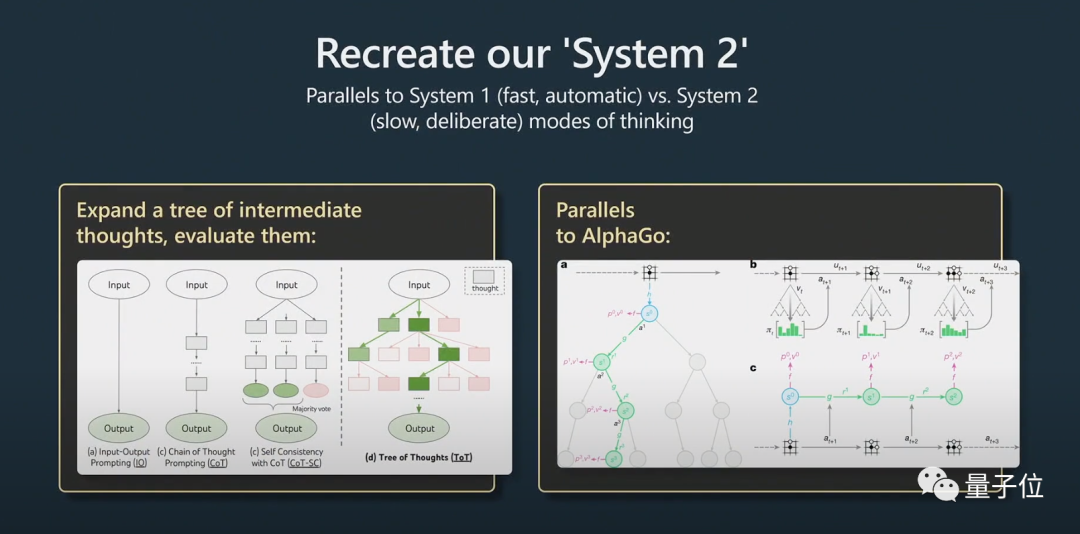
Ini melibatkan masalah System1 dan System2.
Pemenang Hadiah Nobel dalam bidang ekonomi Daniel Kahneman mencadangkan dalam "Berfikir Cepat dan Perlahan" bahawa sistem kognitif manusia terdiri daripada dua subsistem, Sistem1 dan Sistem2. System1 bergantung terutamanya pada intuisi, manakala System2 ialah sistem analisis logik.
Dalam istilah orang awam, System1 ialah proses yang cepat dan dijana secara automatik, manakala System2 ialah bahagian yang difikirkan dengan baik.
Ini juga disebut dalam makalah popular baru-baru ini "Pohon pemikiran".

Berfikiran bermakna bahawa bukannya hanya memberikan jawapan kepada soalan, ia lebih seperti gesaan yang digunakan dengan kod gam Python untuk menggabungkan banyak gesaan adalah bercantum bersama. Untuk menskalakan pembayang, model perlu mengekalkan berbilang pembayang dan melaksanakan algoritma carian pokok.
Karpathy percaya bahawa idea ini hampir sama dengan AlphaGo:
Apabila AlphaGo memainkan Go, ia perlu mempertimbangkan tempat untuk meletakkan bahagian seterusnya. Pada mulanya ia belajar dengan meniru manusia.
Selain itu, ia melaksanakan carian pokok Monte Carlo untuk mendapatkan hasil dengan pelbagai strategi berpotensi. Ia menilai banyak kemungkinan pergerakan dan mengekalkan hanya yang lebih baik. Saya rasa ini agak setara dengan AlphaGo.
Dalam hal ini, Karpathy turut menyebut AutoGPT:
Saya rasa kesan semasanya tidak begitu baik, dan saya tidak mengesyorkannya untuk aplikasi praktikal. Saya fikir kita mungkin boleh belajar daripada evolusinya dari semasa ke semasa.

Kedua, satu lagi helah kecil adalah untuk mendapatkan semula generasi yang dipertingkatkan (generasi yang dipertingkatkan semula) dan petua yang berkesan.
Kandungan konteks tetingkap ialah memori kerja transformer pada masa jalanan Jika anda boleh menambah maklumat berkaitan tugasan pada konteks, maka ia akan berfungsi dengan baik kerana ia boleh diakses dengan segera maklumat ini.
Ringkasnya, ini bermakna data yang berkaitan boleh diindeks supaya model boleh diakses dengan cekap.
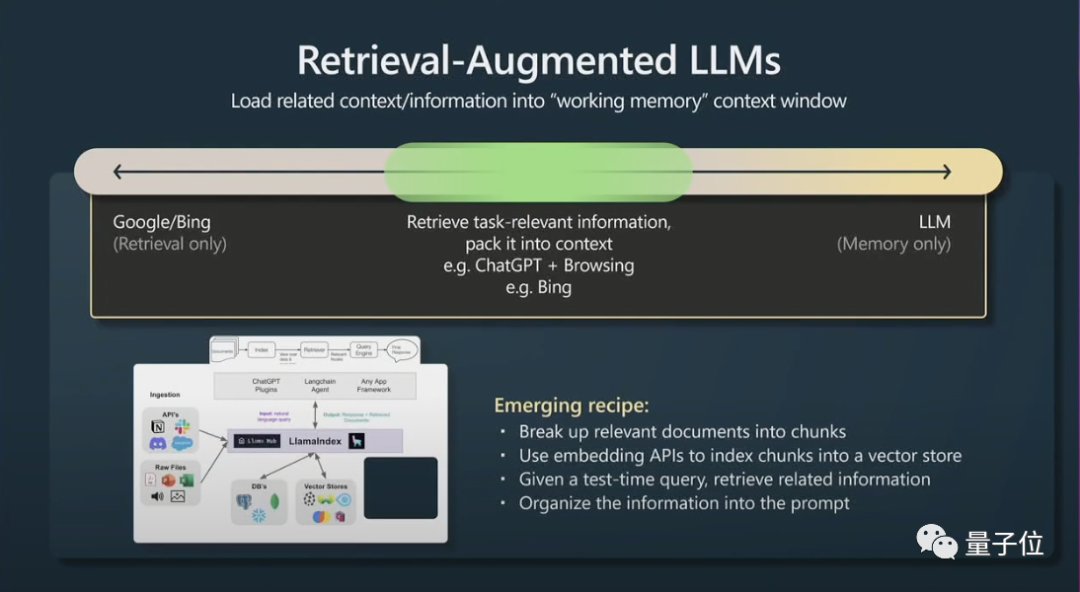
Transformer akan berprestasi lebih baik jika mereka turut mempunyai fail utama untuk dirujuk.
Akhirnya, Karpathy bercakap secara ringkas tentang dorongan kekangan dan penalaan halus dalam model bahasa besar.
Model bahasa yang besar boleh dipertingkatkan melalui pembayang kekangan dan penalaan halus. Kekangan memberi petunjuk menguatkuasakan templat dalam output model bahasa yang besar, manakala penalaan halus melaraskan pemberat model untuk meningkatkan prestasi.
Saya mengesyorkan menggunakan model bahasa yang besar dalam aplikasi berisiko rendah, sentiasa menggabungkannya dengan penyeliaan manusia, menganggapnya sebagai sumber inspirasi dan nasihat, dan mempertimbangkan copilot daripada menjadikannya bertindak secara autonomi sepenuhnya.
Mengenai Andrej Karpathy

Pekerjaan pertama selepas Dr. Andrej Karpathy tamat pengajian ialah belajar visi komputer di OpenAI .
Kemudian, Musk, salah seorang pengasas bersama OpenAI, jatuh cinta dengan Karpathy dan mengupahnya di Tesla. Musk dan OpenAI berselisih mengenai perkara itu, dan Musk akhirnya dikecualikan. Karpathy bertanggungjawab untuk Autopilot Tesla, FSD dan projek lain.
Pada Februari tahun ini, 7 bulan selepas meninggalkan Tesla, Karpathy menyertai OpenAI sekali lagi.
Baru-baru ini dia tweet bahawa dia kini sangat berminat dalam pembangunan ekosistem model bahasa besar sumber terbuka, yang sedikit seperti tanda-tanda letupan awal Kambrium.
Portal:
[1]https://www.youtube com /watch?v=xO73EUwSegU (video ucapan)
[2]https://arxiv.org/pdf/2305.10601.pdf (kertas "Pohon pemikiran")
Pautan rujukan:
[1]https://twitter.com/altryne/status/1661236778458832896
[2]https://www.reddit.com/r/MachineLearning/comments/13qrtek/n_state_of_gpt_by_andrej_karpathy_in_msbuild_2023/
>>
Atas ialah kandungan terperinci Seseorang akhirnya menjelaskan keadaan semasa GPT! Ucapan terbaharu OpenAI menjadi tular, dan ia mestilah seorang genius yang dipilih sendiri oleh Musk. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
Artikel berkaitan
Lihat lagi- Aliran teknologi untuk ditonton pada tahun 2023
- Cara Kecerdasan Buatan Membawa Kerja Baharu Setiap Hari kepada Pasukan Pusat Data
- Bolehkah kecerdasan buatan atau automasi menyelesaikan masalah kecekapan tenaga yang rendah dalam bangunan?
- Pengasas bersama OpenAI ditemu bual oleh Huang Renxun: Keupayaan penaakulan GPT-4 belum mencapai jangkaan
- Bing Microsoft mengatasi Google dalam trafik carian terima kasih kepada teknologi OpenAI